
改进FCENet的自然场景文本检测算法
2024-03-03 11:21廖俊玮刘翔宇周月霞曾凡智
计算机工程与应用 2024年3期
周 燕,廖俊玮,刘翔宇,周月霞,曾凡智
佛山科学技术学院 计算机系,广东 佛山 528000
自然场景文本检测在现实中具有广泛应用,如场景理解、智能导盲和自动驾驶等。近几年,基于深度学习的场景文本检测算法取得了很大的进步,这些方法总体上可以分为两类:基于回归的方法和基于分割的方法[1]。
基于回归的方法通常采用主流的目标检测器,如YOLO[2]和SSD[3]。这些方法可以直接预测文本实例的边界框坐标,从而摆脱复杂的后处理算法。EAST[4]和文献[5]将边界框坐标进行像素级回归,然后使用非极大值抑制对冗余框进行过滤。RRD[6]将文本检测分解为两个任务,分别使用旋转不变特征进行文本分类,使用旋转敏感特征进行文本定位。DMPNet[7]提出使用四边形滑动窗口作为默认锚点框来匹配多方向文本。然而,当面对不规则形状的文本时,由于点序列表示能力有限,其性能往往急剧下降。
基于分割的方法通常将文本检测视为两阶段任务,首先检测文本行片段,然后将这些片段组合成最终输出。PSENet[8]采用全卷积网络结构预测多尺度文本核,然后使用递进尺度扩展算法生成最终预测并区分相邻文本实例。SAE[9]通过学习文本像素到嵌入特征空间的映射,通过像素聚类得到输出掩码。DB[10]对文本区域阈值图和概率图进行预测,通过可微二值化操作生成近似二值图,骆文莉等人[11]、王延昭等人[12]基于DB[10]方法做了进一步改进。Zhu等人[13]提出了傅里叶空间嵌入方法FCENet,该网络预测了分类图和文本边框点的傅里叶特征向量,然后在对应区域上对向量进行傅里叶逆变换操作,从而在图像空间域中重建出文本轮廓。
然而,由于自然场景中文本的复杂性,基于分割方法的场景文本检测器[8-10,13]在一些具有挑战性的场景仍存在不足,例如CTW1500[14]数据集中图片背景复杂出现的误检(图1(b))、极端纵横比和字符间距过大出现的过度分割(图1(d))、弯曲文本检测准确性较差(图1(f))等问题(图1(a)、(c)、(e)为该图片对应的真值标注),因此基于分割方法的场景文本检测器性能仍有很大的改进空间。

图1 自然场景文本检测中存在的问题Fig.1 Problems in scene text detection
以上两类方法主要采用传统特征金字塔网络(FPN)做特征融合,骨干网络输出的每层特征表示和特征融合方式对检测效果有着重要作用。CBAM[15]结合通道和空间注意力增强了特征表示。ECANet[16]利用卷积块实现跨通道的特征交互,从而对特征进行增强。PANet[17]通过自顶向下和自底向上的特征融合网络,提高了检测性能。Dai等人[18]提出通过多尺度通道注意力模块对不同尺度特征进行权重分配,提高特征的融合效果。虽然基于分割的方法能够检测任意形状文本,但仍存在许多挑战。例如,由于场景文本图像背景的复杂性,使得网络对一些与文本区域纹理相似的区域非常敏感,从而导致文本误检;大尺度、极端纵横比文本的漏检问题;大间距文本的过度分割问题。相比于以上提到的相关工作,本文提出的方法结合了注意力特征融合模块和多尺度残差特征增强模块进一步提高了文本检测性能。
针对复杂背景的误检、文本过度分割和弯曲文本检测不准确的问题,本文提出一种改进FCENet[13](Fourier contour embedding network)的场景文本检测算法,主要贡献如下:
(1)针对复杂背景的误检问题,本文提出多尺度残差特征增强模块(multi-scale residual feature augmentation,MRFA),增强特征金字塔结构自上而下的高层语义信息流动,充分利用骨干网络高层语义信息,能有效实现不同尺度特征图文本特征的交互,减少误检。
(2)针对极端纵横比文本和大字符间距文本的过度分割问题和弯曲文本检测精确性不佳问题,提出多尺度通道注意力特征融合模块(multi-scale attention feature fusion module,MSAFF),更好地融合语义和尺度不一致的特征,从而使拥有不同感受野的特征能更精准地融合,避免文本过度分割,提高弯曲文本的检测能力。
(3)在多方向场景文本数据集(ICDAR2015[19])以及弯曲场景文本数据集(CTW1500[14]、Total-Text[20])上的实验证明本文方法的有效性。
1 改进FCENet的自然场景文本检测算法
针对相关工作中基于分割的方法存在的问题,本文提出了一种改进FCENet[13]的场景文本检测算法,改进点主要包括在原网络的骨干网络顶层引入多尺度残差特征增强模块以及采用多尺度注意力特征融合模块代替原特征金字塔的侧向连接融合方式。
网络整体架构如图2 所示,主要由三个部分组成,即骨干网络、特征增强与融合网络、傅里叶轮廓嵌入及后处理模块。本文骨干网络采用包含DCN[21]模块的ResNet50,其中C1~C5为ResNet50 网络每一层的输出特征,本文中选择ResNet50输出的C3、C4、C5层特征与特征金字塔网络结合,分别对应骨干网络提取的大、中、小三种不同尺度特征,通过特征金字塔网络进行融合可以在基本不增加原有模型计算量的情况下提高多尺度目标检测性能;其中C5顶层特征的其中一个分支送入多尺度残差特征增强模块,减少因特征通道数减少造成的信息损失,改善顶层特征表示;并将C3、C4层特征送入多尺度注意力特征融合模块与相邻层特征进行融合,更好地融合语义和尺度不一致的两层特征,从而使拥有不同感受野的特征能更精准地融合。最后,特征增强与融合网络输出三个不同尺度特征图N3、N4、N5,送入傅里叶轮廓嵌入及后处理模块,该模块中的分类分支和回归分支共享一个检测头,分别生成像素分类图和对应傅里叶特征向量,通过逆傅里叶变换(inverse Fourier transformation,IFT)和非极大值抑制生成文本检测结果。

图2 本文算法整体框架图Fig.2 Overall framework of proposed algorithm
本文通过引入多尺度残差特征增强模块对顶层特征进行增强,为特征金字塔网络提供更多的空间上下文信息;同时采用多尺度注意力特征融合模块更好地融合不同特征层中语义和尺度不一致的特征,丰富了不同层级特征的空间上下文和全局信息。通过以上两个模块的引入,整体网络能够有效提高特征表示,减少信息损失,提高文本检测的性能。
1.1 多尺度残差特征增强模块
研究表明缺乏上下文信息的指导会造成误报,FCENet[13]中采用的特征金字塔网络仅通过1×1 卷积减少通道数,骨干网络输出的最高层语义特征C5在减少通道数后直接自上而下传递,由于减少了特征通道而遭受信息损失,导致网络未能完全利用骨干网络提取的高层特征。因此本文方法在骨干网络ResNet顶层特征输出C5中新增一个MRFA残差分支,通过该残差分支对原始特征进行增强,并将多样的空间上下文信息与原始分支结合,改善C5特征表示。
MRFA 模块如图3 所示,首先将C5层作为输入,通过三个并行分支分别进行不同比例的自适应池化操作,产生三个不同尺度的上下文特征图(Wk×Hk,k=1,2,3)。然后每个上下文特征图通过1×1 卷积操作将特征图的通道数降至256。最后,通过双线性插值将它们上采样到原输入特征图尺度上进行后续融合。

图3 多尺度残差特征增强模块Fig.3 Multi-scale residual feature enhancement module
MRFA模块的计算过程如式(1)所示:
由于双线性插值可能会带来混叠效应,因此不能简单地对特征进行求和,本文利用自适应空间融合模块来自适应地组合三个上下文特征,而不是简单地进行求和。自适应空间融合模块首先将三个上采样后得到的特征进行拼接,依次通过1×1卷积、3×3卷积、Sigmoid操作去自适应地学习到每个特征对应的空间权重图,利用该权重图与对应特征进行聚合,通过该方法可以自适应地组合这些上下文特征,得到具有多尺度上下文信息的特征图。
1.2 多尺度注意力特征融合
在各种特征金字塔结构中,不同层次的特征往往采用简单的求和或拼接操作来进行特征融合,这样的特征融合方式容易丢失部分不同层级特征的空间和全局信息。为了更好地融合语义和尺度不一致的特征,本文提出了多尺度通道注意力模块,该模块解决了融合不同尺度给出的特征时出现的问题,使拥有不同感受野的特征能更精准地融合,丰富了不同层级特征的空间上下文和全局信息。多尺度注意力特征融合模块如图4 所示。多尺度注意力特征融合过程如公式(2)所示:

图4 多尺度注意力特征融合模块Fig.4 Multi-scale attention feature fusion module
其中,X代表底层特征,Y代表高层特征,MSRA 模块使用尺度不同的两个分支来提取通道注意力权重。其中一个分支先使用全局平均池化操作然后使用逐点卷积提取局部特征的通道注意力权重,另一个分支直接使用逐点卷积提取局部特征的通道注意力权重。MSCA(X⊎Y)表示注意力模块MSCA生成的通道注意力权重值,实线表示权重MSCA(X⊎Y)与底层特征X进行融合,虚线表示权重(1-MSCA(X⊎Y))与高层特征Y进行融合,并将融合后的两个特征相加,得到最后的融合特征Z。
MSCA模块的计算过程如式(3)所示:
其中,L(X⊎Y)计算过程如式(4)所示:
1.3 傅里叶轮廓嵌入及后处理模块
任意形状文本检测的挑战在于如何对形状复杂多变的文本实例进行建模,通过傅里叶变换将文本实例轮廓在傅里叶域进行建模可以精确地拟合极其复杂的形状,因此通过傅里叶轮廓嵌入(Fourier contour embedding,FCE)的方式可以更好地对自然场景中高度弯曲文本进行建模,高效且具有非常好的鲁棒性,无需复杂后处理步骤。对任意封闭轮廓曲线,可将封闭曲线的参数方程嵌入到复数域,如式(5)所示:
轮廓曲线上的点可表示为(x(t),y(t)),f(t)通过点采样和傅里叶变换可得到傅里叶系数ck,如式(6)所示:
其中,N为点采样的次数,k为频率,c0表示该文本实例轮廓的中心点位置,通过将傅里叶系数ck拆分为实部和虚部,则轮廓可通过固定长度为2(2k+1)的实数向量进行表示。
该部分处理流程如图2 中傅里叶轮廓嵌入及后处理模块部分所示,经过特征增强与融合网络输出的特征N5、N4、N3分别在分类和回归两个分支上进行预测。其中,分类分支预测文本区域图和文本中心图,然后对文本区域图和文本中心图的每个像素对应相乘,得到文本像素分类图;回归分支预测每个文本像素对应的傅里叶时域特征向量,基于傅里叶时域特征向量通过逆傅里叶变换(IFT)重建文本轮廓,结合分类分支得到的文本分类得分图,通过非极大值抑制(NMS)获得最后文本检测结果。
1.4 标签生成和损失函数
对于分类任务,本文采用Textdragon[22]的方法对文本进行收缩,得到文本中心区域(text center region,TCR)掩码,收缩因子为0.3,如图5(来源于文献[13])中的绿色区域。

图5 傅里叶轮廓嵌入示例Fig.5 Illustration of fourier contour embedding
对于回归任务,本文通过傅里叶轮廓嵌入方法计算真实文本轮廓的傅里叶特征向量c,同一文本实例中的不同像素共享相同的傅里叶特征向量(c0除外)。
因此本文方法的总体损失函数可表示为式(7):
其中,Lcls和Lreg分别为分类分支和回归分支的损失,λ为分类分支和回归分支的平衡系数,本文λ设为1。
分类分支损失Lcls由两部分组成,如式(8)所示:
Ltr和Ltcr分别为文本区域(text region,TR)和文本中心区域(TCR)的交叉熵损失。为解决样本不平衡问题,Ltr采用OHEM[23]方法,负样本与正样本的比例为3∶1。
对于回归损失Lreg,可表示为式(9):
其中,l1为smooth-l1损失,F-1为逆傅里叶变换,T为文本区域像素索引集合,和分别为文本真值对应的傅里叶特征向量和对像素i预测的傅里叶特征向量。N′表示文本轮廓上的采样点数,本文设置为50。
2 实验与结果分析
为验证本文所提出算法的可行性和有效性,分别在三个国际基准数据集上进行了消融实验、性能分析和对比实验,采用文本检测的主流评价指标准确率P、召回率R和F值来评估算法性能。
2.1 数据集和实验环境
本文实验中使用的数据集如下:
CTW1500[14]:由1 000 张训练图片和500 张测试图片组成的多语言弯曲场景文本数据集,每个文本区域为14个点标注的多边形,能充分描述弯曲文本的形状。
ICDAR2015[19]:由1 000 张训练图片和500 张测试图片组成的纯英文场景文本数据集,该数据集中每个文本区域的标签是四边形标注。
Total-Text[20]:由1 255 张训练图片和300 张测试图片组成的场景文本数据集,包含水平、多方向和弯曲等多种不同文本方向。
本文实验中训练及测试的平台为1×NVIDIA RTX 3090,CUDA11.1,Ubuntu18.04,网络模型基于Pytorch1.8搭建。在训练过程中采用随机裁剪、随机旋转、随机水平翻转、颜色抖动和对比度抖动五种数据增强方法来增强训练数据,最后将每张图像大小调整为800×800。训练每批次大小设置为8,网络训练优化采用随机梯度下降(SGD)算法,权值衰减为0.001,动量衰减为0.9,初始学习率设置为0.001,在每个数据集上均进行了1 500个epoch 的训练。图6 为本文算法在CTW1500 数据集上进行训练的损失曲线和F值曲线。从图中可以看出,随着训练epoch 的增加损失逐渐下降,F 值逐渐提高,在1 400个epoch之后逐渐收敛。

图6 训练损失曲线和F值曲线Fig.6 Training loss curve and F-measure curve
测试过程中,对图像大小调整如下:
CTW1500:将图像的短边调整为640,如果图像长边大于1 280,则长边调整为1 280。
Total-Text:将图像的短边调整为960,如果图像的长边大于1 280,则将其调整为1 280。
ICDAR2015:将长边调整到2 020,并保持原方向。
2.2 消融实验
在1.1节中介绍了多尺度残差特征增强模块来改善骨干网络的顶层特征表示。本文在CTW1500数据集上进行了实验,以验证哪一组α取值最适合本文的多尺度残差特征增强模块。根据自然场景文本的尺度特性,本文共设置了五组不同的α取值进行实验,实验结果如表1 所示,可以发现当α1、α2、α3分别设定为0.1、0.2、0.3时,在CTW1500数据集上准确率、召回率、F值均取得了最好的性能指标。因此,在本文中的后续实验均应用该组α值作为不同比例的自适应池化操作。
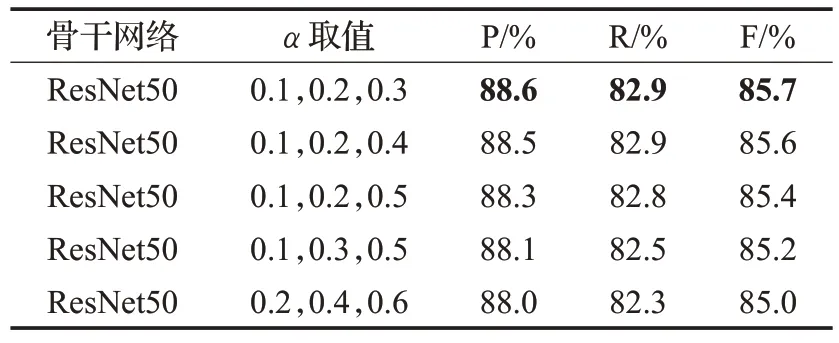
表1 MRFA模块不同α 取值的实验结果Table 1 Experimental results of MRFA module with different values of α
为验证本文提出的多尺度注意力特征融合与多尺度残差特征增强模块的有效性,本文分别在ICDAR2015、CTW1500、Total-Text 数据集上进行了各个模块相关的消融实验。其中骨干网络均使用添加了可变形卷积(DCN[21])的ResNet50 网络,与其他的方法不同,本文方法的实验均没有经过SynthText[24]和MLT[25]大规模数据集的预训练。表2 列出了CTW1500、Total-Text 和ICDAR2015数据集的消融实验结果,其中第1行为原模型FCENet的实验结果。
从表2 第2 行可以看出,通过加入MRFA 模块,在CTW1500 数据集上,与原模型FCENet[13]相比准确率和F 值分别提升了1 和0.6 个百分点;在Total-Text 数据集上准确率、召回率和F 值分别提升了0.3、0.2 和0.3 个百分点;在ICDAR2015 数据集上,准确率、召回率、F 值分别提升了0.1、0.6 和0.3 个百分点;消融实验结果表明,MRFA 模块通过三种不同比例的自适应池化提取了多样的上下文信息,作为残差分支能够减少特征金字塔中最高层特征的信息丢失,增强了顶层特征表示,可以提高文本像素的分类能力,减少误检现象的产生,从而使检测准确率P得到提升,代表综合性能的F值也同步提高。
从表2 第3 行可以看出,通过加入MSAFF 模块,在CTW1500数据集上与原模型FCENet[13]采用的特征金字塔侧向连接的典型方法相比,准确率、召回率和F 值分别提升了0.7、0.1和0.7个百分点;在Total-Text数据集上准确率、召回率和F 值分别提升了0.1、0.7 和0.3 个百分点;在ICDAR2015 数据集上,准确率和F 值分别提升了0.7和0.2个百分点;消融实验结果证明,MSAFF模块通过尺度不同的两个分支提取全局特征与局部特征的通道注意力权重,在加强不同尺度文本特征的同时弱化非文本特征,更好地融合上下两层语义和尺度不一致的特征,使拥有不同感受野的特征能更精准地融合,避免文本过度分割,提高弯曲文本和大字符间距文本的定位能力,使准确率P 在三个数据集上均得到提升;同时也减少了漏检现象,在两个弯曲文本数据集上召回率R也均有所提升,代表综合性能的F值也同步提高。
从表2第4行可以看出,通过整合MRFA和MSAFF模块,在CTW1500 数据集上,与原模型FCENet[13]相比准确率、召回率和F 值分别提升了1.1、0.3 和1.1 个百分点;在Total-Text数据集上准确率、召回率和F值分别提升了0.9、0.5 和0.7 个百分点;在ICDAR2015 数据集上,准确率、召回率和F 值分别提升了0.5、0.8 和0.7 个百分点;消融实验结果证明了通过结合两个模块,整体网络能够有效提高特征表示,减少信息损失,进一步提升自然场景文本检测的效果,减少了复杂背景和类文本图案的误检现象,提升了弯曲文本和大字符间距文本检测的鲁棒性,同时减少了过度分割问题的产生,三个性能指标均比原模型有显著提升。
本文算法模型的参数量和计算量为分别为30.56 MB和37.62 GB,相对于原模型FCENet[13]分别增加了1.63 MB和0.71 GB,虽然参数和计算量有小幅增加,但有效提升了自然场景文本检测的效果,在三个数据集上的性能指标均有较大提升。在CTW1500 数据集训练1 500 个epoch 耗时约40 h,在该数据集的500 张测试集图片上进行测试,FPS达到了8.3,基本能够满足实时性场合的要求。
2.3 与其他方法的对比
本文分别在多语言弯曲文本数据集CTW1500 和Total-Text 以及多方向长文本数据集ICDAR2015 上将本文方法的性能指标与近年来的主流算法进行了对比分析。
从表3 可以看出,在多语言弯曲文本数据集CTW1500上,本文方法在准确率P和F值上均优于现有方法,其中F值指标达到了86.2%,相比于针对弯曲文本检测的流行算法DRRG[26]、ContourNet[27]、FAN[28]分别提升了1.8、2.3、1.3个百分点,相比于当前效果最好的算法DBNet++[29]提高了0.9个百分点。
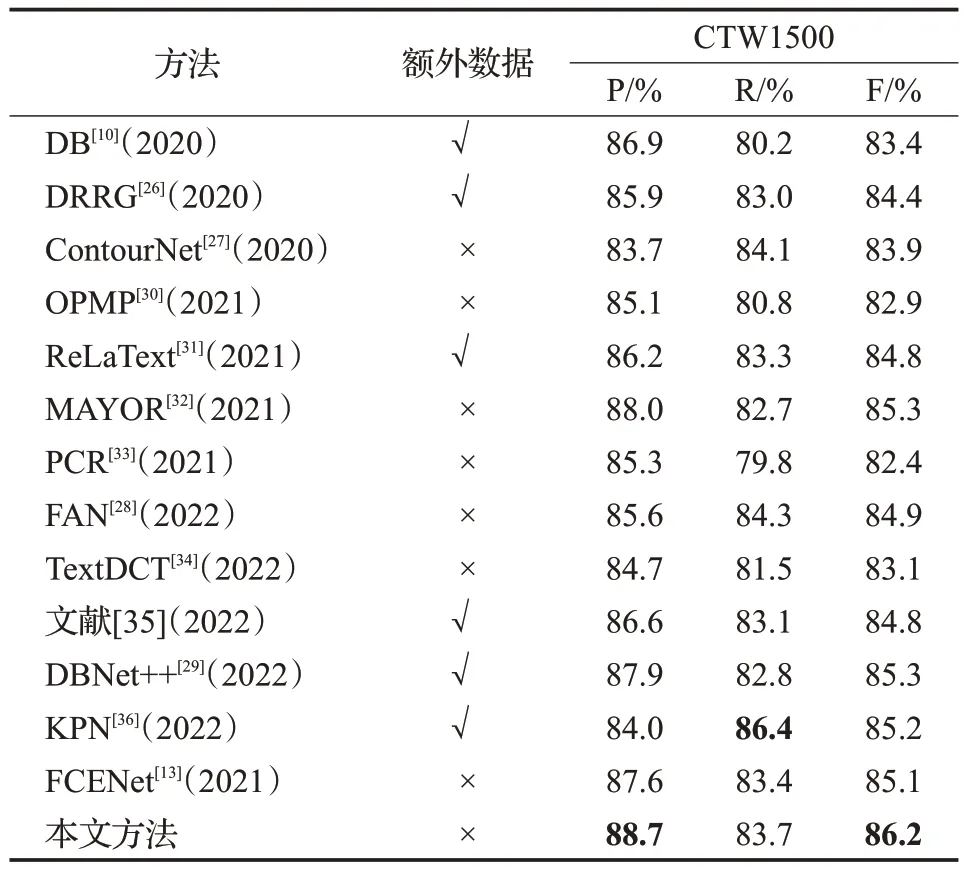
表3 CTW1500数据集上相关方法的比较Table 3 Performance comparison on CTW1500 dataset
从表4 可以看出,在多语言弯曲文本数据集Total-Text 上,本文方法在准确率P 和F 值上同样优于现有方法,其中F值指标达到了86.5%,相比于针对弯曲文本检测的流行算法DRRG[27]、ContourNet[27]、FAN[28]分别提升了0.8、1.1、1.7 个百分点,相比于当前效果最好的算法DBNet++[29]提高了0.5个百分点。

表4 Total-Text数据集与相关方法比较Table 4 Performance comparison on Total-Text dataset
从表3 与表4 的对比实验结果可知,即便本文方法未经过大规模数据集的预训练,本文方法仍在多语言弯曲文本数据集CTW1500、Total-Text 取得了最为先进的性能指标,充分证明了本文方法在自然场景文本检测上的鲁棒性,相较于同样基于分割的方法DB[10]、DBNet++[29]、FAN[28],本文方法能够减少复杂背景的误检及过度分割问题的产生,并提高了弯曲文本的检测与定位能力。
在多方向长文本数据集ICDAR2015上的对比实验结果如表5所示,由于该数据集中的图片为行人佩戴的谷歌眼镜所拍,存在抖动和漂移失真现象,导致数据集中的图片较为模糊,对模型的训练造成一定的困难。本文方法在未经过大规模数据集预训练的情况下仍取得了与当前性能最佳的方法具有竞争力的性能指标,相较于原始方法FCENet[13]准确率、召回率和F值分别提升了0.5、0.8 和0.7 个百分点,证明了本文方法在多方向长文本数据集中同样具有较好的检测性能。
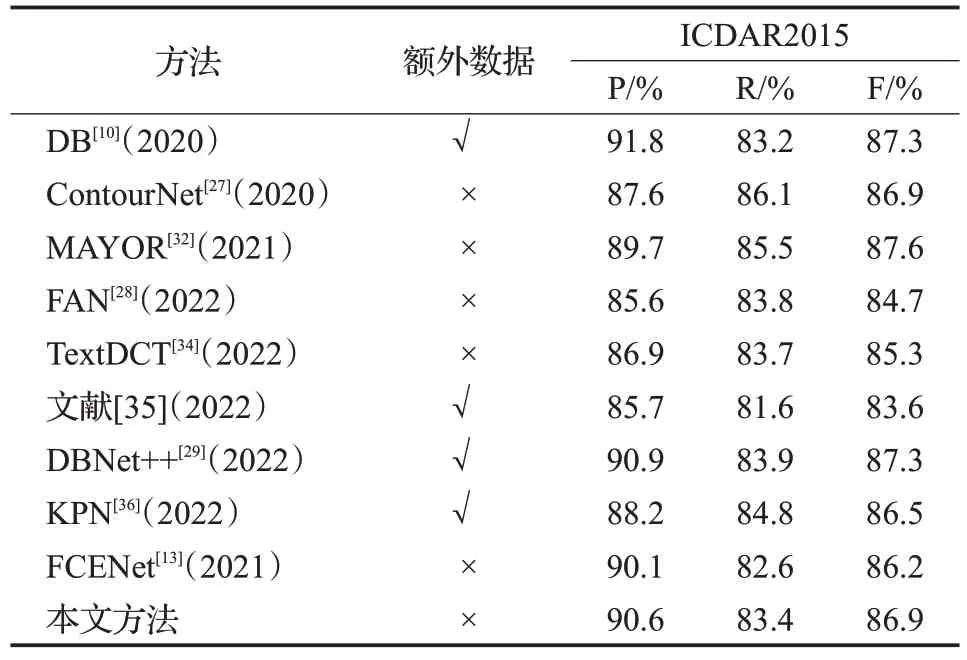
表5 ICDAR2015数据集与相关方法比较Table 5 Performance comparison on ICDAR2015 dataset
为更直观展示本文方法的文本检测效果,图7通过可视化的方式展示了本文方法和对比算法FCENet[13]在CTW1500数据集部分测试集图片的测试结果。真值标注图中蓝色边界框为文本标注框。从图7(a)、(b)可以看出,本文方法能够有效减少复杂背景干扰造成的误检问题;从图7(b)可以看出,本文方法能够避免大字符间距文本实例的过度分割;从图7(c)可以看出,本文方法能够准确地检测弯曲幅度较大的弯曲文本;从图7(d)可以看出,本文方法对于竖直排列的文本也具有很好的检测效果,鲁棒性更强。以上四组图片中分别存在着不同尺度以及弯曲文本,本文算法均能准确地进行检测,证明了算法对不同尺度以及弯曲文本检测等方面的优势。

图7 CTW1500数据集可视化对比结果分析Fig.7 Analysis of visual comparison result on CTW1500 dataset
3 结束语
针对场景背景复杂、大字符间距、文本形状弯曲多变所造成的文本检测难题,本文提出了一种改进FCENet的场景文本检测算法。其中MRFA模块增强特征金字塔结构自上而下的高层语义信息流动,充分利用骨干网络高层语义信息,提高文本像素的分类能力,减少误检现象发生;MSAFF 模块使语义和尺度不一致的特征更精准地融合,提高了不同尺度文本的定位能力,减少了过度分割现象的产生,并提高了弯曲文本检测的准确率。通过在三个国际基准数据集上的实验及对比分析,证明了本文方法的有效性。后续工作将针对模糊图片的文本检测及模型的轻量化设计进一步展开研究,提升本文模型检测的准确性和速度。
猜你喜欢
内蒙古民族大学学报(社会科学版)(2020年2期)2020-11-06
数学年刊A辑(中文版)(2020年2期)2020-07-25
数学物理学报(2019年6期)2020-01-13
数学物理学报(2019年2期)2019-05-10
测控技术(2018年7期)2018-12-09
数学物理学报(2017年5期)2017-11-23
太空探索(2016年5期)2016-07-12
舰船科学技术(2016年1期)2016-02-27
电测与仪表(2015年5期)2015-04-09
时代英语·高三(2014年5期)2014-08-26
