
面向跨视角地理定位的感知特征融合网络
2024-03-03 11:21王嘉怡陈子洋袁小晨赵艮平
计算机工程与应用 2024年3期
王嘉怡,陈子洋,袁小晨,赵艮平
1.广东工业大学 计算机学院,广州 510006
2.澳门理工大学 应用科学学院,澳门 999078
近些年来,跨视角地理定位已成为机器人导航、自主驾驶和三维重建这些领域中的一个主要问题。从广义上讲,跨视角地理定位匹配任务可以分为两个子任务:无人机目标定位和无人机导航。无人机目标定位是指给定无人机视角图像,可以在卫星图库集中匹配同一位置的卫星视角图像。无人机导航是指给定一张卫星视角图像,可以在无人机图库集合中匹配同一位置的无人机视角图像。
在早期的研究中,许多算法[1]-5]试图优化特征匹配的精度来改善模型的目标定位性能,并在跨视角地理定位方面取得了初步进展。例如,Arandjelovic等人[1]提出了NetVLAD 来改进特征描述符的表示,这些描述符是对目标进行检索的关键。此外,Turner等人[6]利用(scaleinvariant feature Transform,SIFT)探索了多张量和超高分辨率之间的关系。与SIFT类似,Bansal等人[7]优化了尺度选择性自相似性描述符,以计算不同视角中每个点的特征距离。然而,这些方法很难解决地面和无人机图像之间视角急剧变化的挑战。具体来说,它们无法将视角不变的特征与固定模式或局部描述符相匹配。
为了解决上述问题,基于深度学习的跨视角地理定位方法[8]-13]即通过嵌入卷积神经网络(convolutional neural network,CNN)来提高匹配不同视角特征的能力。例如,Qi等人[9]和Vo等人[11]构建了混合架构来提高大规模检索任务的性能。特别是,他们认为探索方向或颜色的全局特征是让模型适应更多视角的关键。此外,Zhai等人[12]对并行网络进行了优化,可同时融合不同的信息视角。这种方式允许模型提取视觉表征和空间特征。尽管如此,上述方法只考虑了通过堆叠几个卷积块的多尺度特征,忽略了上下文信息。因此,一些研究者试图利用细粒度分类算法来解决多尺度的问题[14-17],旨在提取细粒度的特征来改善地理定位的上下文特征。比如,Ding 等人[15]揭示了跨视点匹配方法,以探索无人机和卫星视角之间的相似性。基于这种相似性,生成补丁对应关系并用于为全局上下文特征选择强大的补丁特征。此外,局部模块网络(local pattern network,LPN)[16]可以阐明选择强大的特征对于跨视角地理定位的重要性。总的来说,优化上下文特征已经成为提高目标匹配精度的主要思路,但上述方法仍然存在以下两个挑战。
首先,基于CNN 的网络只能挖掘出不同视角的部分特征,容易对目标建筑产生位置偏差,这种影响抑制了模型在提取目标特征时对目标的感知性能。其次,该网络对构建不同视角下的角度转换的相关性会有极大的危害性[17]。具体来说,不同视角的图像很容易让网络在定位目标的过程中把一些局部特征当成该目标的主要特征。
因此,在这项工作中提出了一个新颖的网络,即面向跨视角地理定位的感知特征融合网络(PFFNet),以全面解决上述挑战。其贡献可以概括为以下几点:
(1)为了捕捉极端的变化并在各视角之间建立语义关联,提出了面向跨视角地理定位的感知特征融合网络(PFFNet),在多个平台视角(无人机、卫星和街景)上进行地理位置的互相检索。
(2)为了解决固定接受野的限制而导致的对目标位置特征感知不足的问题,提出了CoA Block,从而实现目标尺度的自适应感受野。CoA Block 提高了网络在单一视角中感知目标位置特征的能力。
(3)为了缓解不同视角的局部区域影响,提出了SST Block 和RSCA Block。SST Block 将Transformer与卷积模块相结合,以增强不同位置的相关性。RSCA Block 通过通道洗牌去增强空间和不同通道的特征,以丰富视觉方向的相关性。
(4)与现有的跨视角图像匹配方法相比,提出的方法在University-1652数据集上取得了更好的性能,证明了它具有更强的鲁棒性和更好的检索精度。
1 感知特征融合网络
本章介绍提出的感知特征融合网络(PFFNet),其中包括最为关键的分流上下文嵌入网络(SCENet)的结果阐述以及构建目标损失函数的过程。PFFNet可以捕捉极端的变化并在各视角之间建立语义关联,使得跨视角地理定位有较高的检索精度。SCENet 作为PFFNet 的骨干网络的工作流程,包含上下文聚合块(CoA Block)、分流语义交互模块(SST Block)和重组空间通道注意力块(RSCA Block),其中CoA Block 可以增强感知目标位置特征的能力,而SST Block 和RSCA Block 则进一步增强不同位置的相关性,极大地丰富了与目标位置的感知性。
所提出的PFFNet 包含三个分支,即分别为无人机视角分支、卫星视角分支和街道视角分支,整个网络结构如图1所示。首先,将不同的视角X1、X2和X3分别输入SCENet,并生成相应的中间特征,即FUAV、FSatellite和FStreet。此处,X1代表无人机视角图像,X2代表卫星视角图像,X3代表街景视角图像。其次,由LPN[16]将上述特征划分为若干个斑块,采用平均池化操作,得到2 048 个维度的特征向量GP,P∈{1,2,3,4}。最后,将三分支网络的特征向量传入分类器,生成701维的特征向量ZP,P∈{1,2,3,4}。此外,网络模型使用共享权重构建无人机视角和卫星视角分支的共享特征空间,以建立无人机和卫星视角之间的关系。

图1 PFFNet的架构Fig.1 Architecture of PFFNet
1.1 分流上下文嵌入网络
所提出的SCENet主要由CoA Block、SST Block和RSCA Block组成,其基础模型是ResNet50。SCENet的具体流程如图1 橙色区域所示,其中CoA Block 贯穿ResNet50的5个阶段,而SSTBlock和RSCA Block插在ResNet50的第3~5阶段。在ResNet50的Basic Block基础上,对Bottleneck Module 进行改进,先将CoA Block作为低级特征编码,主要在每个阶段中负责低级特征的提取和特征间的承接。其次SST Block和RSCA Block作高级编码,主要在每个阶段中负责增强上下文特征信息与语义信息特征的稠密性和丰富度。最后将低级特征编码和高级特征编码作进一步的特征融合替换了Bottleneck Module,下文将以无人机视角为例进行详细步骤说明。具体来说,输入图像X1通过CoA Block 生成特征图FU。同时,SST Block接收输入图像X1生成特征图F1和F2。接下来,将特征图FU、F1和F2整合到RSCA Block,得到输出特征FO。最后,得到中间特征FUAV。为了详细说明SCENet 的具体结构,将在1.1.1、1.1.2 和1.1.3 小节中描述CoA Block、SST Block和RSCA Block的具体细节。
1.1.1 上下文聚合块
搭建上下文聚合块的目的是通过丰富上下文信息来增强提取目标位置的能力,其结构如图2 所示。首先,输入图像X1由卷积模块以核大小进行编码3×3 生成特征图X。其次,将1×1卷积模块平滑后的特征图映射到64 通道的特征空间,得到特征X∈F(C×H×W)。在这里,将1×1卷积表示为Conv。此时X∈F(C×H×W)产生三个变量FK=Conv(X)、FV=Conv(X)和FQ=Conv(X)。其中,FK可以获得局部静态上下文信息。第三,对FK和FQ进行Concat 运算,通过两次1×1卷积运算生成注意矩阵FR。公式如下所示:

图2 CoA Block的架构Fig.2 Architecture of CoA Block
特别是,每个空间位置都可以响应相关的上下文信息融合FK和FQ。随后,对这个注意力矩阵FK和FR进行逐元素矩阵乘法,得到F*的全局特征。公式如下所示:
其中,⊗是局部矩阵乘法。接下来,将局部静态上下文信息FK与全局特征F*融合并生成输出F′。公式如下所示:
其中,⊕是逐元素相加。最后,F′通过通道数为256的1×1卷积,记为FU。
1.1.2 分流语义交互模块
搭建分流语义交互模块的思想是将多头注意力模块与深度点卷积相结合,可以构建特征空间中的位置相关性。SST Block的架构如图3所示。首先,将输入图像X1分成j个块,并进行线性投影,将每个块像一维向量一样展平,得到图像编码向量Vj,j∈{1,2,3,4}。其次,在不重叠的块序列中,创建了可学习的块序列来表示每个补丁的位置。随后,把它和位置嵌入Vj放在一起,聚合所有位置嵌入的全局上下文,并在嵌入模块中生成VE。

图3 SST Block的架构Fig.3 Architecture of SST Block
随后的流程可分为两部分进行介绍。第一部分是获取相关特征的语义信息并生成特征嵌入VE。第二部分是探索来自不同通道的上下文信息并输出特征图VS。
对于第一部分而言,特征嵌入VE通过归一化和多头注意力模块(multi-head attention),得到对应的输出编码向量VC。公式如下所示:
其中,Norm表示归一化,而Att是多头注意力模块。多头注意力模块是将相对编码与相对注意力图整合起来的,公式如下所示:
其中,Q、K和V分别为每组注意力得到的不同矩阵。E为编码矩阵,每个元素Ei,j表示qi到vj的关系,(EV)i将所有的向量和对应的向量聚合起来。为了防止梯度扩散的情况,进行了一个残差积分操作,即把输出编码向量VC加到输入编码向量VE中,生成输出特征图VCE。公式如下所示:
其中,⊕是逐元素相加。
对于第二部分而言,输出编码向量VCE分别通过depth-point(DP)模块和多层感知器(multilayer perceptron,MLP)。在DP 模块中,对输入特征VCE进分组卷积操作,每个分组只负责提取一个通道的特征。由于一个特征图仅被一个滤波器卷积,无法有效地利用不同通道在相同空间位置上的特征信息,因此加入了逐点卷积以整合每个通道的特征。逐点卷积主要是要1×1 卷积构成,负责将深度卷积的输出按通道投影到一个新的特征图上。此时,还将输入特征VCE映射到MLP以保留它们的高级表示。最后,在DP模块和MLP的输出之间执行元素相加操作,生成输出特征VD。公式如下所示:
此外,它被添加到VCE向量中以输出向量VS。公式如下所示:
将编码向量VS输入到全连接层进行非线性映射,最终得到特征图F1。此外,将SSTBlock设计为并行结构,以便最终输出表示为特征映射Fi,i∈{1,2}。与传统模型相比,该模块逐组提取空间特征,并从这些空间特征中探索每个通道的上下文信息。
1.1.3 重组空间通道注意力块
基于上述Blocks(CoA Block和SST Block)的输出结果进行融合,即是先收集CoA Block 的输出特征图FU和SST Block的输出特征图Fi,i∈{1,2}。然后,对特征图FU和Fi进行融合操作。之后,RSCA Block接收融合后的特征进行输出,具体过程如图4所示。这里分两部分描述这个块。第一部分是通道重组操作,而第二部分是通道压缩操作。

图4 RSCA Block的架构Fig.4 Architecture of RSCA Block
在第一部分,RSCA Block 接收由SST Block 生成的特征图Fi,i∈{1,2}。之后,对这些特征进行线性投影操作,将它们映射成一维向量。由于不同通道之间的数据可以连通,从而完成通道之间的信息融合,并且可以丰富视觉方向的相关性。因此采用通道重组操作。之后,将这些向量分为K组来表示信息的K个通道。公式如下所示:
其中,ψ是ReLU 函数。在经过几个线性层的映射后,通过通道重组操作得到不同子组FA和FB的特征,并将它们组合得到特征图FC。公式如下所示:
在第二部分,RSCA Block 接收了CoA Block 模块生成的特征图FU。此外,通过挤压(Squeeze)操作将大小为C×H×W的特征转换为C×1×1 的特征描述以获得全局描述。之后,通过两个全连接层和Sigmoid 激活函数增强通道特征,并生成映射到[0-1]的权重,从而融合所有特征FU。公式如下所示:
其中,G是融合操作,Fsq是挤压操作,Wa和Wb是两个全连接层。此外,其中r是用于减少参数数量和网络复杂度的缩放参数。通过Sigmoid激活映射权重FU后,通过逐元素相乘将原始特征与相应的权重相结合。公式如下所示:
其中,⊙是逐元素相乘。总的来说,利用逐元素相加来聚合起第一步FE和第二步FC的结果,最终得到输出特征FO。公式如下所示:
1.2 构建目标损失函数
对于输入图像X1在通过SCENet主干后得到中间特征FUAV。然后,将特征图FUAV拆分为四个环状的特征图FP。接下来对这些特征图进行平均池化操作,得到2 048维的特征向量GP,P∈{1,2,3,4}。公式如下所示:
多视角位置感知特征GP被输入分类器FC以获得目标建筑物的预测向量和预测地理标签。由于University-1652数据集包含701个目标建筑物,故将701个建筑物编号为701 个不同的索引,得到一个701 维的特征向量。公式如下:
因为卫星视角和无人机视角图像具有相似的模式,所以在卫星视角和无人机视角之间共享权重,然而对于街景视角而言是不共享权重的。它们的损失函数可以表示为:
其中,C是类别数,Wshare是卫星视角和无人机视角的共享权重。
总的来说,提出的网络首先是用三个视角联合训练的。然后,分别计算三个视角的损失函数。最后,它们加在一起作为最终Losstotal。网络总损失Losstotal提供了更好的权重初始化,并允许更具区分性的嵌入。网络的总损失函数可以表示为:
2 实验
2.1 数据集和评价指标
2.1.1 数据集
University-1652[14]是悉尼科技大学提出的一个新的地理定位数据集。与传统的地理定位数据集不同,它包含街景图像和卫星图像,同时添加了大量航拍无人机图像。与街景图像和卫星图像相比,无人机图像和卫星图像的视角更接近,大大降低了相互检索的难度。University-1652数据集主要包含来自72所大学的1 652座标志性建筑,没有重叠。这里,将训练集和测试集拆分如下,来自33 所大学的43 253 张图像作为训练集,而来自39所大学的96 362张图像作为测试集。该数据集可以评估为两个任务,即无人机目标定位(无人机→卫星)在Query_UAV 和Gallery_Satellite 中总共提供了38 556 张图像,而无人机导航(卫星→无人机)包含701 张Query_Satellite 和51 335 张Gallery_UAV,如表1所示。

表1 University-1652数据集统计Table 1 Statistics of University-1652 dataset单位:张
2.1.2 评价指标
参考相关方法[14]的评价标准,采用Recall@Top1%(R@1),Recall@K(R@K),AveragePrecision(AP)在实验中评估模型的性能。
2.2 实验设置
2.2.1 模型设置
在参数初始化方面,对分流上下文嵌入网络(SCENet)的分类器模块采用了kaiming 初始化[18],具体如表2 所示。此外,受迁移学习的启发,预训练的权重被用来初始化骨干的权重,以提高训练阶段的效率。在多头注意力结构中设置不同的头数来提高特征判别性。最后收集到每个尺度的特征图,它们的通道分别为64、256 和512。对于CoABlock 的层数设置,受ResNet50 的启发,在卷积层中堆叠了三个包含批量归一化和ReLU 的卷积模块。
2.2.2 实验阶段设置
在训练阶段,将图像大小调整为256×256,并执行图像增强策略,即随机填充、随机裁剪和随机翻转,以提高模型的鲁棒性。这些策略可以使模型检索到不同视角的目标。之后,输入的图像被分割成16×16的非重叠图像。此外,这些带有位置嵌入的图像斑块被用来初始化斑块标记的参数。遵循类似于小样本学习的策略,采用实例损失监督。在训练阶段,实例损失设置为0.001。特别是,损失函数的学习率在每20 个epochs 中都适用于降级。对于优化器,采用随机梯度下降法,动量为0.9,权重衰减为0.000 5。在测试阶段,University-1652中的查询和验证的图像被均匀地调整为256×256,并生成一个特征矩阵。利用欧氏距离来计算查询图像和验证图像之间的相似度。随后,根据它们的分数排名来检索查询结果。提出的模型是基于Pytorch 的框架,所有实验都是在NvidiaGTX2080TiGPU上进行的。
2.3 对比实验
提出的PFFNet 在University-1652 数据集上进行了评估,与先进的方法进行比较,包括Contrastive Loss[17]、Triplet Loss[19]、Soft Margin Triplet Loss[20]、Instance Loss[14]、LCM[15]和LPN[16],所有的结果如表3所示。在表3中,分别比较了两个任务的性能,即无人机目标定位和无人机导航。第一个任务的目的是测试提取上下文信息的能力。第二个任务的目的是测试模型对不同视角的敏感程度。

表3 PFFNet与最先进的方法比较Table 3 Comparison of PFFNet with state-of-the-art methods 单位:%
在无人机目标定位任务(无人机→卫星)中,提出的方法实现了76.97%的R@1和81.17%的AP。相比之下,采用骨干网ResNet50的LPN[16]只能达到75.93%的R@1和79.14%的AP。在这里,LPN 是一种块级别特征提取的策略,构建了三个分支网络和一个块级别的集合模块。从骨干结构的角度来看,与LPN的骨干网络不同,提出的SCENet骨干网络包含了CoA Block、SST Block和RSCA Block。这些模块可以提升提取上下文信息的能力,并产生了判别性的特征,可以让模型挖掘更突出的特征来代表主要目标。相比之下,基于ResNet 作为骨干网络的LPN仅仅整合局部特征,这很容易将模型的注意力集中在局部区域,如建筑物的角落等,而忽略了整体的轮廓。因此,提出的模型相对于LPN 而言R@1提高1.04个百分点,AP提高2.03个百分点。
在无人机导航任务(卫星→无人机)中,提出的方法达到87.94%的R@1和76.64%的AP。此外,LCM[15]达到79.89%的R@1和65.38%的AP。在这里,对于检索损失函数来说,同时考虑数据分布的不同观点比测量每张图片的相似度更有效。实例损失在每个分支中都嵌入了一个额外的线性层,以探索隐含的数据分布,并提供更好的权重初始化,让模型产生更多的鉴别性嵌入。因此,Instance Loss的R@1精度比Triplet Loss高约4.91个百分点。
2.4 消融实验
2.4.1 所提出模块的效果
为了展示提出网络每个部分的效果,这里将网络的每个部分拆分并构建了四组实验来比较它们的性能。这些部分包括基础模型、CoA Block、SST Block和RSCA Block,如表4所示。在无人机目标定位任务(无人机→卫星)中,嵌入CoA Block 可以比基础模型的R@1提升4.96个百分点,AP提升5.22个百分点。然后,将SST Block 堆叠到上述结构中,R@1 和AP 分别提升了2.37和3.02个百分点。接下来,将上述提及的三个模块所输出的结果(CoA Block、SST Block 和RSCA Block)聚合到基础模型并构造到SCENet,SCENet 达到69.55%的R@1 和74.99%的AP,即R@1 高于基础模型8.62个百分点和AP高于基础模型9.68个百分点。在无人机导航任务(卫星→无人机)中,提出的方法比基础模型在R@1 提高了6.36 个百分点和AP 提高了7.62 个百分点。上述实验结果证明提出的三个Block是有效可行的,提出的方法可以提高网络的性能。
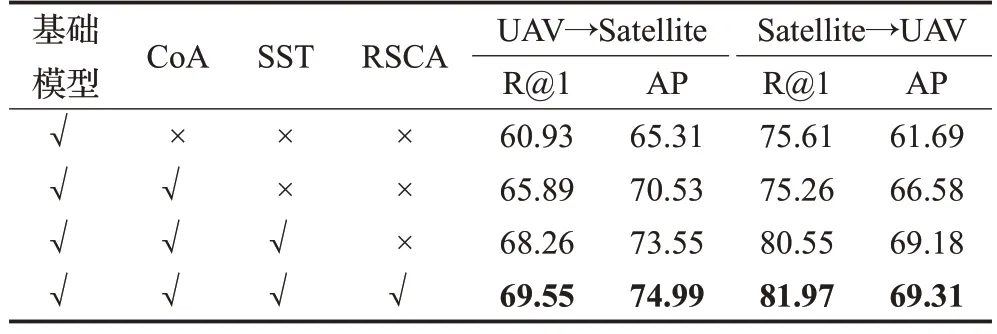
表4 提出模块的消融效果Table 4 Ablation effect of proposed Blocks 单位:%
2.4.2 不同骨干网络的影响
为了验证骨干网络的效果,使用提出的骨干网络SCENet替换了其他网络,如表5所示。从检索性能的角度来看,ResNet50 的R@1 在无人机目标定位任务中优于ResNeXt50。随后,ResNet50 的R@1 在无人机导航任务中超过了Wide ResNeXt的R@1。此外,CoTNet50在无人机目标定位任务中的表现比ResNet50的R@1高出5.91个百分点,AP高出5.72个百分点,而在无人机导航任务中取得76.07%的R@1和67.51%的AP。在这里,CoTNet50 改进了ResNet50,并整合了几个注意力模块以增强上下文信息。与CoTNet50 相比,提出的方法在无人机→卫星任务中R@1提高了2.9个百分点和AP提高了3.77 个百分点,在卫星→无人机任务中R@1 提高了5.9个百分点和AP提高了1.8个百分点。与CoTNet50不同的是,提出的骨干SECNet 不仅整合了变换器结构来探索位置感知特征,而且还通过嵌入SCENet 的RSCA Block来挖掘潜在的空间特征。

表5 不同骨干网络的消融效果Table 5 Ablation effect of different backbone 单位:%
2.5 定性结果分析
为了更加直观地对比PFFNet与基础模型之间的性能差异,利用热力图可视化方式来解释这种差异,具体情况如图5所示University-1652数据集中的卫星视角和无人机视角的热力图。从图中可以观察到,卫星视角和无人机视角在基础模型中,网络只感知到了目标位置中心的一小部分区域,无法覆盖整体的目标位置。但是所提出的PFFNet 方法中,比基础模型方法激活了更多目标位置周围的上下文信息,覆盖范围广,并产生了辨别性的特征。PFFNet 在不同形状、不同高度的目标建筑中均有优良的效果。

图5 基础模型和PFFNet的热力图对比Fig.5 Comparison of heatmaps of base model and PFFNet
此外,还展示了University-1652数据集上的无人机目标定位和无人机导航任务的检索结果,如图6(a)所示。对此观察到,图6(a)中的第二排位置显示的目标位置在Top-1中没有正确匹配,这表明检索是困难的。在无人机导航任务中,给定一个卫星视角图像,从无人机视角库中检索出前五张相似的图像,图6(b)所示,所提出的方法可以准确无误地找到所有对应位置的图像。综上所述,验证提出的方法取得了正确的结果,并证明模型是有效可行的。

图6 PFFNet的定性图像检索结果Fig.6 Qualitative image retrieval results from PFFNet
3 结束语
本篇论文提出了面向跨视角地理定位的感知特征融合网络(PFFNet),专注于学习位置感知的特征并在每个视角之间建立语义关联,SCENet 骨干网络为特征空间提供了丰富的上下文信息。实验表明,提出的方法在跨视角地理定位任务中表现良好,并实现了很好的稳健性。特别是,提出的方法比其他CNN 的网络产生的位置感知特征更准确。可以证明,感知特征融合网络可以在跨视角地理定位的基准中达到先进的性能。
在未来,将专注于提取更具辨识度的位置感知特征,探索更强大的模型,并将该方法扩展到跨视角地理定位中。
猜你喜欢
军民两用技术与产品(2021年10期)2021-11-25
北京航空航天大学学报(2021年9期)2021-11-02
导航定位与授时(2020年5期)2020-09-23
铁道通信信号(2020年9期)2020-02-06
科学家(2019年3期)2019-08-18
电子制作(2019年11期)2019-07-04
北京航空航天大学学报(2018年1期)2018-04-20
知识经济·中国直销(2018年3期)2018-04-12
科学与财富(2016年28期)2016-10-14
学习月刊(2015年1期)2015-07-11
