
基于注意力模块的移动设备多场景持续身份认证
2024-03-03 11:22金瑜瑶张晓梅王亚杰
计算机工程与应用 2024年3期
金瑜瑶,张晓梅,王亚杰
上海工程技术大学 电子电气工程学院,上海 201620
根据Data.ai最新报告表明[1],2021年全球移动设备使用量为3.8 万亿小时,可见,移动设备的需求量上升,也存储了更多的敏感和隐私数据,这些信息的丢失或者泄露必然会导致一定的安全隐患。为了保护这些私人数据不受未经授权的访问,移动设备目前都采用传统的显式认证方法(密码、PIN、面部识别[2]、指纹识别[3]),然而,这些方法很容易受到猜测、肩窥和伪造攻击[4-7],此外,用户只需在初次使用时进行认证,无法阻止通过初始认证的入侵者非法访问设备。为了克服这些问题,持续身份认证成为研究者关注的焦点,其通过后台采集用户生物行为数据,在用户初次访问移动设备后进行持续监控,以达到实时认证的目的,保障了系统的安全性。
目前大多数研究更多地关注单一信息源的交互模式,然而,随身携带移动设备已成为大部分用户的习惯,当用户转换多个场景使用移动设备时,认证系统的持续性就会受到限制,单个设备存储多个认证模型也会占用极大的资源。因此,本文考虑一种基于用户与移动设备交互间的移动模式(movement patterns,MP),通过用户特别的手部姿势和手部运动的微变化实现。由于个体间的行为特征[8-9]和生理特征均存在显著差异,用户的惯用姿势不同,会使用自己的方式来达到手持设备的稳定性和触摸屏幕的准确性;同时,手掌大小、手指长度[10]和年龄差异[10-11]也会影响操作时的手指力量、滑动位置和滑动长度;最后,设备的大小和重量不同也会对用户的操作造成影响。基于上述原因发现,特性的差异会影响用户的操作行为,从而导致独特的MP 特征,因此该特征能够识别合法用户和非法用户。此外,该特征不受限于特定操作场景均可提取,包括动态场景,如步行和跑步,也包括静态场景,如坐和站。
针对不同场景下数据差异大、特征提取繁琐、用户体验度差的问题,本文提出了一种由注意力模块和卷积神经网络融合(CNN-SACA)的深度学习模型。目前,卷积神经网络(convolutional neural network,CNN)凭借出色的特征提取能力被广泛应用在车辆检测[12]、情感分析[13]、视频编码[14]、医疗保健[15]等领域,既无需人工提取,也使得网络过拟合危险降低,故本文以CNN 为基础提取MP 特征进行持续身份认证。但是在多个场景转换过程中,用户的行为数据会产生偏移变化,导致简单的CNN会忽略关键特征,将合法用户在不同场景下的MP特征误认为非法行为特征。由于多样的注意力机制在融入不同网络时会产生较优结果,因此,本文融入了注意力模块来抑制多场景下有效信息的冗余部分,先按序通过空间和通道注意力子模块,再在多层卷积后进行反序分配权重,使模型自适应地关注预测中更重要的MP特征,从而加快模型的收敛速度。与仅基于CNN 的工作相比,该融合模型能将认证精度提高1.5 个百分点,并且运算复杂度不高,也适用于硬件资源有限的移动设备。而且目前没有其他工作将注意力机制应用于持续身份认证的深度学习方法。本文的主要贡献有三个方面:
(1)提出了一种基于移动模式的多场景持续身份认证方案,旨在集成动态场景和静态场景(即多场景)下的手部微运动特性,该MP特征通过用户的手部运动和手部姿势实现。通过大量实验评估,本文使用内置传感器的实时信息对行为特征MP进行建模,在多场景的情况下,能以较低的错误率验证用户身份。
(2)通过融合卷积神经网络和注意力机制,提出了一种新的深度学习模型CNN-SACA。该模型以特定的SACA 注意力模块结构,对预处理后的二维MP 特征进行不同权重分配,能够提高多场景下的身份认证精度。
(3)本文在公开数据集上实现并评估了该方案的认证性能。实验结果表明,该算法的准确率为99.6%,等错误率仅为1.32%,能有效提高用户在切换场景使用移动设备时的安全性和体验感。
1 相关工作
为了保障移动设备的安全性,早期利用机器学习算法[16-17]进行持续身份认证成为研究的热点,但是传统的机器学习算法在特征提取阶段不仅需要人工参与,还需要充足的操作经验。由于移动设备在操作过程中会发生位置变化,传感器自身也会产生噪声和异常信息,所以人工提取的行为特征在一定程度上会导致辨识度不佳,并且存在过拟合等问题,这都会影响身份认证的准确率。
近年来,深度学习技术特别是基于CNN 的身份认证技术因其强大的学习能力被广泛应用到持续身份认证领域[18-21]。芦效峰等人[18]结合卷积神经网络和循环神经网络(recurrent neural networks,RNN)对产生的击键数据进行特征提取,训练后的模型可以很好地体现个人击键模式,拥有较好的准确率,但是只使用了相同键盘输入的数据,并将行为限制在电脑端,无法实现移动设备的身份认证。Shiraga等人[19]提出了一种基于CNN的步态识别方法,引入步态能量图像(GEI)作为模型的输入,但是该方法必须拥有用户的步态轮廓,即需要额外的摄像设备才能实现身份识别。Matteo 等人[20]和Zhao等人[21]以CNN 为特征提取网络,通过智能手机的加速度和陀螺仪信号来表征用户独特的身份信息,但必须将智能手机绑定在用户裤子前袋或后腰处采集信息。然而,上述研究均未考虑到用户操作场景的转变以及与移动设备交互的便捷性,使用浅层的CNN 缺乏识别类间相似特征的能力,只能识别单一场景的特征,例如单独使用行走时的步态信息认证、使用坐姿状态下的击键数据认证等。此外,虽然Tang 等人[22]找到了包括走路、上下楼和坐、站、卧以及转换数据在内的多场景数据集,但该实验仍然限制传感器佩戴位置,并且使用繁琐的人工提取方法,用户无法真正实现与移动设备交互。
实际应用场景的复杂性对持续身份认证方法的有效性带来了挑战。王欣等人[23]在MobileNetv2网络中嵌入基于通道的注意力机制,王玲敏等人[24]将基于位置信息的通道注意力融入YOLOv5算法,Li等人[25]提出一种包含空间注意力模块的网络模型实现高光谱图像分类。由此可见,通道或是空间注意力模块融入不同网络后可以让模型从全局角度注意到关键目标,学习到目标更精细的特征,证明了改进网络的有效性。此外,杜先君等人[26]和许文鑫等人[27]在模拟电路故障诊断和列车闸片偏磨状态方面通过融入注意力机制CBAM改善了CNN无法自主分配关键特征的问题。该机制包括了通道和空间注意力,可以沿着两个独立的维度推断注意力特征,并且有研究表明CBAM[28]可以无缝集成到任何CNN体系结构中。但是杜先君等人和许文鑫等人也仅将卷积神经网络和注意力机制进行简单地串联组合,无法针对本文多场景特征进行自适应识别。受以上研究启发,本文提出一种将改进的空间注意力(spatial attention module,SAM)和通道注意力模块(channel attention module,CAM)融合嵌入到CNN中的多场景身份认证模型CNN-SACA,以克服芦效峰、Shiraga、Matteo、Zhao、Tang等[18-22]工作的不足。
所提的持续身份认证方案通过捕捉多场景下用户与移动设备间真正进行交互时产生的MP特征,从而进行持续身份认证。CNN-SACA模型将注意力模块按不同顺序融入到CNN 模型中,能够对不同场景下的类内特征进行增强,自动获取高相关性特征,并抑制其他低相关性特征,加强对多场景特征的检测能力,使用户与移动设备进行交互时,无需考虑场景变化问题,满足了安全性的同时又兼顾了用户体验度。
2 多场景持续身份认证方案
2.1 持续认证框架
为实现用户身份认证,本文构建基于深度学习和用户移动模式的身份认证框架,包括训练模型、身份认证、模型更新阶段,流程如图1所示。
身份认证的具体流程如下:
(1)训练模型阶段。先通过用户与移动设备进行交互,在两类场景(动态和静态)中收集传感器数据,本文选择的三种传感器是目前移动设备中常见的内置传感器,无需外部传感器的支持,并且分别提供不同维度的用户行为信息。加速度计记录用户较大的运动模式,如手臂姿势、走路姿势等;陀螺仪记录用户细微的运动模式,如握持设备姿势;磁力计记录方向信息,如设备旋转方向和角度。然后经过预处理,即特征转换,对收集到的所有数据进行数据预处理,通过异常值处理、小波去噪、平均映射得到所需的二维图像数据,再输入到网络中。最后进行模型训练,在训练过程中,调整不同的卷积神经网络(CNN)参数,以达到最优的效果。再在此基础上融入注意力模块,最终得到最优参数的CNN-SACA深度学习网络模型。
(2)身份认证阶段。在构建好模型后,当合法用户首次使用移动设备时,系统将持续不断地通过后台传感器实时采集场景行为数据,这部分数据不曾参加训练过程,再从原始信号中进行预处理,以生成MP特征向量,并输入已构造的CNN-SACA 模型进行用户认证,分析结果是否达到预期。
(3)模型更新阶段。考虑到用户行为会随着时间、年龄、习惯的变化而改变,那么特征的认证就会产生差异。当合法用户被错认为非法用户时,系统会提醒用户进行显示认证,若显示认证通过,系统则将错误拒绝的用户数据重新收集并训练新的模型,达到一定的持续更新认证模型的作用。
2.2 注意力模块
在其他应用中,注意力机制通常作为一个独立的模块嵌入到网络中,通过对频带、像素或通道进行不等量加权来细化特征图。本文受Woo等人[28]启发,将通道注意力机制模块(CAM)和改进后的空间注意力机制模块(SAM)以最佳组合方式应用于CNN的模型中。
通道注意力模块提取通道注意力的方式基本和SE-Net[29]类似,但增加了并行全局最大池化(global max pooling,GMP)的特征提取方式,可以取得更好的效果。如图2 所示,输入特征图为fn=(f1,f2,…,fn),n为提取到的特征图数,将特征图fn通过最大池化层和平均池化层进行并行池化输入,再分别经过多层感知器(multilayer perception,MLP),将MLP输出的两个特征向量进行加和操作并通过Sigmoid 激活函数得到结果向量,将该向量与原先的特征图fn相乘,得到新的特征图。CAM的过程可以表示为公式(1):
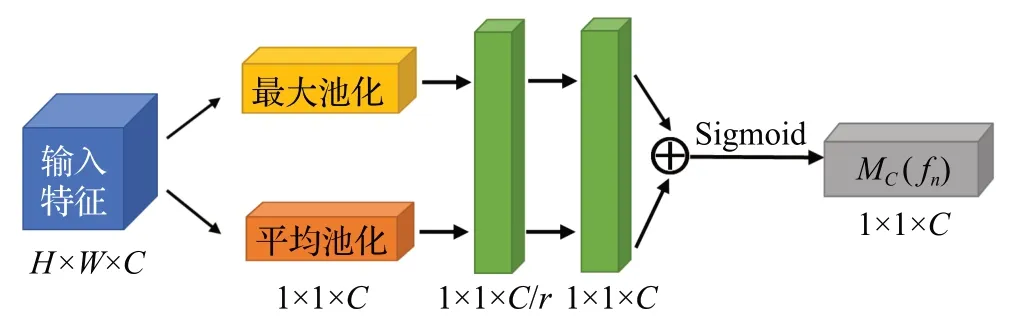
图2 通道注意力模块结构Fig.2 Structure of channel attention module
其中,σ表示sigmoid激活函数,Avg和Max表示平均池化和最大池化操作,W1∈RC×C/r和W0∈RC/r×C表示MLP 的共享权重,是经过平均池化和最大池化操作后的特征图。
空间注意力模块可以使神经网络更加关注移动模式特征中对分类起决定作用的像素区域而过滤无关紧要的信息。特征图输入到传统的SAM会进行基于通道维度的最大池化操作和平均池化操作,这种方式让压缩空间描述特征不够充分。为了获得空间上每个像素点的通道全局描述特征,本文在此基础上添加了一个大小为1 的卷积操作,对特征序列逐个压缩,充分表达第一特征图的关键MP信息。如图3所示,改进后的SAM首先通过最大池化、平均池化和1×1 的卷积操作,将它们拼接成具有三个通道的特征图,最后由单卷积核卷积降为空间权重为H×W×1 的特征图,并通过激活操作后与输入特征图相乘,从而生成最终的特征图。改进的空间注意力模块通过添加卷积操作更清晰地表达了特征图空间位置的详细权重,能有效提高对MP特征的辨别能力,其过程可以表示为公式(2):
其中,σ表示sigmoid激活函数,O表示卷积操作,表示经过均值池化、最大池化和卷积操作后的特征图。
2.3 CNN-SACA深度学习模型设计
由于浅层的CNN 对行为特征提取不充分,认证精度不高,深层的CNN虽然一定程度上提高了认证精度,但是运算复杂度更高、占用资源大,因此本文设计了一个包含五层卷积层的卷积神经网络,对MP特征生成的RGB 图进行特征挖掘,以改善模型对多场景转换下身份认证的准确率和检测速度。而所提出的CNN-SACA模型是对该CNN的有效改进。由于个体在不同场景下与移动设备交互时具有不同的表现,为了精准提取和训练MP 特征,进一步提高模型性能,本文设计并开发了CNN-SACA 深度学习网络模型,并加入线性修正单元和注意力模块,增加网络稀疏性,缓和过拟合,使得计算资源分配更加合理化。
Woo 等人[28]提出了CBAM 注意力机制模型,按通道-空间注意力模块的标准串联组合可达到模型最优化,而在本文CNN 的结构中却表现不佳。CNN-Ⅴ模型在通过第一层卷积层后,由于卷积核尺寸和步长较大,卷积过程中对空间信息的描述较多;而在最后一层卷积时,模型已经包含混合的空间及通道信息。因此,本文设计的CNN-SACA深度学习模型结构如图4所示,Acc是加速度计,Gyro是陀螺仪,Mag是磁力计,本文提取该三个传感器的数据,将其组合成专属的MP特征作为模型的输入。首先在模型的第一层卷积后嵌入SAM 和CAM的串联组合,先对首次卷积后的MP特征图分配空间注意力权重,再调整跨通道间的特征像素点;而后将所获得的特征图按顺序投入到四个卷积层中,并对其进行快速抽象与汇总;最后在第五层卷积后按照标准模式依次嵌入CAM和SAM,对混合后的空间、通道MP特征信息进行调整,再经过Soft-max层完成对MP 特征的分类。实验表明,以Conv-SACA-Conv-CASA为网络结构的模型性能优于以标准串联结构嵌入的模型,能提高整个模型提取MP 特征的效率。本文提出基于卷积神经网络的注意力模块算法如算法1所示。

图4 CNN-SACA模型结构图Fig.4 Model structure of CNN-SACA
算法1 基于卷积神经网络的注意力模块算法
CNN-SACA 模型算法中D表示包含实例E={e1,e2,…,en}的数据集,要规范化数据,第一步是将原数据通过平均映射为D1,下一步是使用NumPy函数将数据转换为2D 矩阵D2。第三步是将三个传感器的数据转换成多重矩阵,使用重塑函数转换为图像F以三维的形式作为CNN-SACA 模型的输入。此外,在第一次池化后进一步转化为向量组V,作为注意力模块的输入,首先反序使用注意力模块计算特征权重WS1,再通过多层快速卷积调整信息,最后按序通过注意力模块接收该信息,分析数据序列之间的关联,这些输出的向量组与不同的权重分数WS3相乘,以预测目标标签L。该过程根据数据的特殊性为数据分配分数,改进了学习过程,有助于在持续身份认证过程中实现更高的精度。
3 实验结果与分析
3.1 数据来源
本文使用HMOG数据集研究本文移动设备持续认证方法。HMOG(hand movement,orientation,and grasp)数据集[30]。由威廉玛丽学院(The College of William and Mary Hereby)的相关工作人员和学生团队收集,使用加速计、陀螺仪和磁强计读数,以不引人注目地捕捉用户轻触屏幕时产生的细微手部微动作和方向模式,在本文中,称其为移动模式(MP)特征。该研究开发了一款数据采集工具,用于记录用户与手机交互调用的实时触摸数据、传感器数据和按键数据,记录了智能手机上两种场景数据(坐姿和行走)以及不同行为数据。该实验招募了100 名志愿者进行大规模数据收集。每位志愿者预计进行24次会话(8次阅读会话、8次写作会话和8次地图导航会话)这个数据集比任何现有的关于智能手机用户交互的公共数据集具有更多的模式和更大的规模。
3.2 数据预处理
Holger[31]发现HMOG 数据集存在一些问题。本文在使用和分析该数据集的过程中也发现了一些问题:(1)用户526 319和用户796 581只有23次会话的数据,而其他用户均是24次的会话数据;(2)数据文件夹名称与其包含的数据不一致;(3)每个用户采集到的数据数量分布以及采集时间不均等,有4人仅贡献了1.5 h的行为特征。这些问题将导致MP特征缺失,从而使认证结果出现偏差,因此在实验之前,将有缺失的用户数据直接删除,改正有微小错误的用户数据,将剩余有效的用户样本构成新的HMOG-N数据集。
本文使用了加速度计、陀螺仪和磁力计三个传感器的数据。通过对原数据的观察可知,首先,每个用户在操作过程中会产生异常噪声,这种出现在高频或低频的运动伪影,如图5(a)所示,这是用户在Accelerometer 中x轴的一段数据,可以看到在实线框内的第19 750个数据点左右出现了异常噪声,对于这部分异常数据段直接剔除,而虚线框内的数据则是正常操作智能手机后产生的数据,如图5(b)所示。本文利用小波去噪对数据进行滤波处理,保证在消除噪声的同时,最大可能地保留原始数据信号形状、宽度等分布特征,如图5(b)中,滤波前的数据是原始数据,而经过小波去噪后,数据波形就会变得平滑,并且保留了用户与智能手机进行交互动作时产生的有效数据。可以看到,每200个数据点之间至少有一个交互动作产生。

图5 某用户加速度计x 轴的数据Fig.5 Data from x-axis of one user’s accelerometer
现阶段大部分的深度学习方法都建立在卷积神经网络的基础上,由于其能在一定程度上实现对信息的区域感知和权重分享,因此在图像识别领域中得到了广泛运用。然而,HMOG数据集所获取的数据是一维信号,为了充分发挥CNN的优点和最大限度地发挥注意力模块的作用,本文将不同场景下的三个传感器数据转化为二维RGB 图像。在输入到深度学习模型之前,先将处理过后的传感器数据进行平均映射,使其成为0~255范围内的像素点,再将其排列组合成数据块,最后转成一定量的具有MP特征的RGB图像,如图6所示。

图6 MP特征图像Fig.6 MP feature image
在训练时,选取除去合法用户外的其余用户的MP特征图作为反例数据。每个用户按照8∶1∶1 的比例获得训练集、测试集和验证集,为了保持反例数据的有效性,则从其他所有用户的数据集中分别等量抽取所需图像数,加入到该用户的False数据子集中,形成新的用户数据集。
3.3 CNN模型参数设计
模型实验选择Adam优化器,损失函数为分类交叉熵损失函数,batch_size 为32,学习率为0.000 06。本文选用以下常用评价指标对实验各个环节进行评估,分别是准确率(Accuracy)、召回率(Recall)、F1 分数(F1-socre)、错误拒绝率(FRR)、错误接受率(FAR)、等错误率(EER)、AUC值。
3.3.1 CNN模型选择
为了选择在多场景下表现更好的网络模型,实验中设计了多种不同参数的卷积神经网络分别对用户多场景下的MP特征进行分类认证,使用新数据集HMOG-N进行测试。表1 显示了不同参数结构的CNN 模型在对静态场景和动态场景下训练后,其所需的训练时间和验证集所能达到的准确率。

表1 单场景下不同CNN模型的准确率和训练时间对比Table 1 Comparison of accuracy and training time of different CNN models in single scenario
由表1可知,本文设计的多种参数结构的CNN模型在准确率方面都取得了不错的结果,纵向对比,在静态场景下身份认证的准确率均在96%以上,动态场景下的准确率略低于静态场景,但也都在93%以上;横向对比,在单场景下,卷积层为5层的CNN耗费的训练时间虽然比有些浅层的模型长,但在准确率方面都表现得更好,且不同的卷积核大小和卷积核个数对结果并没有很大的影响。对于更深层的模型来说,单场景下的准确率有所下降,仅个别动态场景达到了较高准确率,但训练时间花费太多,效率较差。
此外,本文使用分类交叉熵损失函数来计算算法的损失值,从而评估单场景下不同网络的性能,图7 显示了其收敛情况。图7(a)是各模型在单场景-坐姿下的损失值,图7(b)是各模型在单场景-步行下的损失值。由图7(a)、(b)所示,在相同超参数下,模型Ⅴ、模型Ⅵ在单场景下的损失值明显低于包含3层、4层以及6层卷积层的模型,并在同层数的模型中收敛更快、更平稳。

图7 不同CNN模型的损失值Fig.7 Loss values for different CNN models
为了测试所设计模型在多场景下的身份认证性能,将混合后的多场景数据集输入到网络中。表2 是在多场景下不同结构的CNN 进行身份认证的准确率、召回率和F1 分数。图8 是多种模型分别在单场景和多场景下的准确率对比,可以看到,模型Ⅴ、模型Ⅷ和模型Ⅸ在输入多场景数据后,准确率得到了提升,而其他模型的准确率反而有所下降。由表2可知,较为深层的模型能更好地表达多场景下的MP 特征,相较于模型Ⅷ和模型Ⅸ,模型Ⅴ的召回率和F1-score 最高,达到了98%和0.98,证明模型Ⅴ能更好地识别多场景下的数据类型。综上所述,本文选择模型Ⅴ作为本文深度学习模型基础。
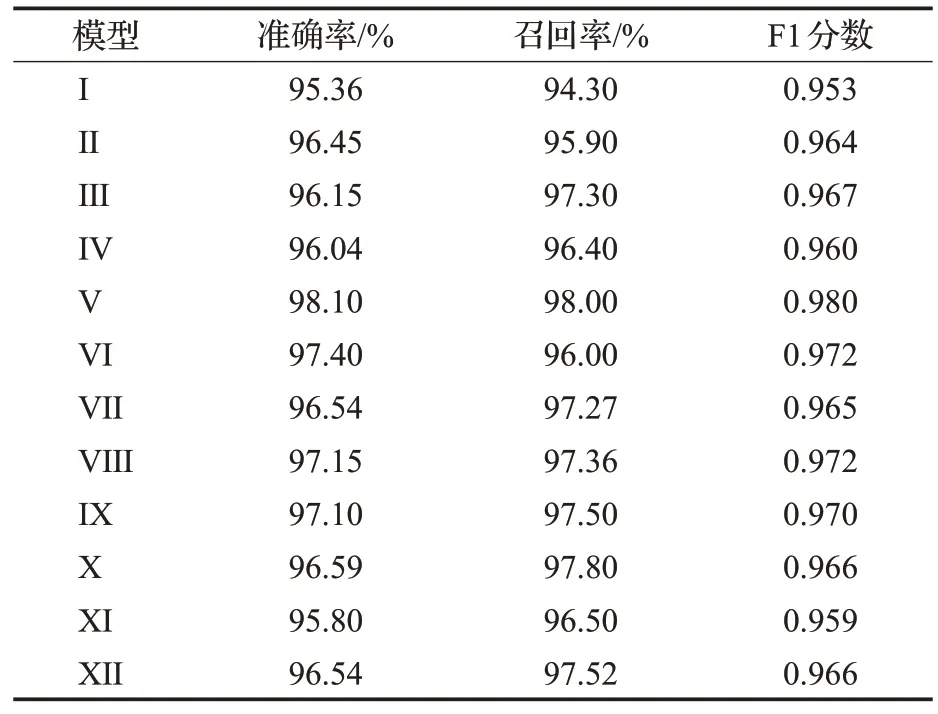
表2 多场景下不同模型的准确率、召回率和F1分数Table 2 Accuracy,Recall and F1 score of different models in multiple scenarios
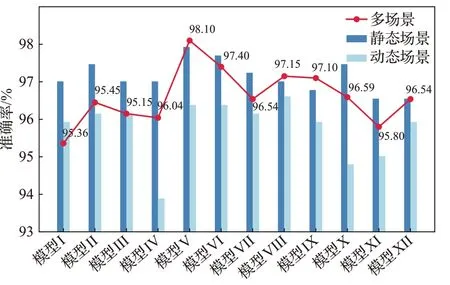
图8 单场景和多场景下的认证准确率对比Fig.8 Comparison of authentication accuracy in single and multiple scenarios
3.3.2 超参数比较
超参数的设置会对网络带来不一样的影响,本小节将改变参数bs(batch_size)和lr(学习率)验证其对静态场景和动态场景性能的影响。保持其他参数不变的同时,将bs从8 以2 的幂次方逐渐调整到256,将lr从0.01调整到0.000 001。结果如图9所示,虚线代表的是准确率曲线,实线代表训练时间变化。图9(a)中,随着bs的增加,两种场景的性能也随之增加,认证准确率在bs=32 达到极值,而后开始降低,模型泛化性下降。动态场景的准确率在bs=256 时得到细微提升,但还是低于bs=32 时的最佳值,且训练时间显著增加,这会耗费更多的计算资源。对于参数lr来说,在0.01 时损失值就急剧上升,导致模型无法完成正常训练,出现准确率极低的现象。随着lr逐渐减缓,如图9(b)所示,两种场景的认证准确率都在lr=0.000 06 时获得优势,而后又逐渐降低。另一方面,训练时间在两种场景中上下波动较大,但综合来说,模型性能在lr=0.000 06时能达到最优。
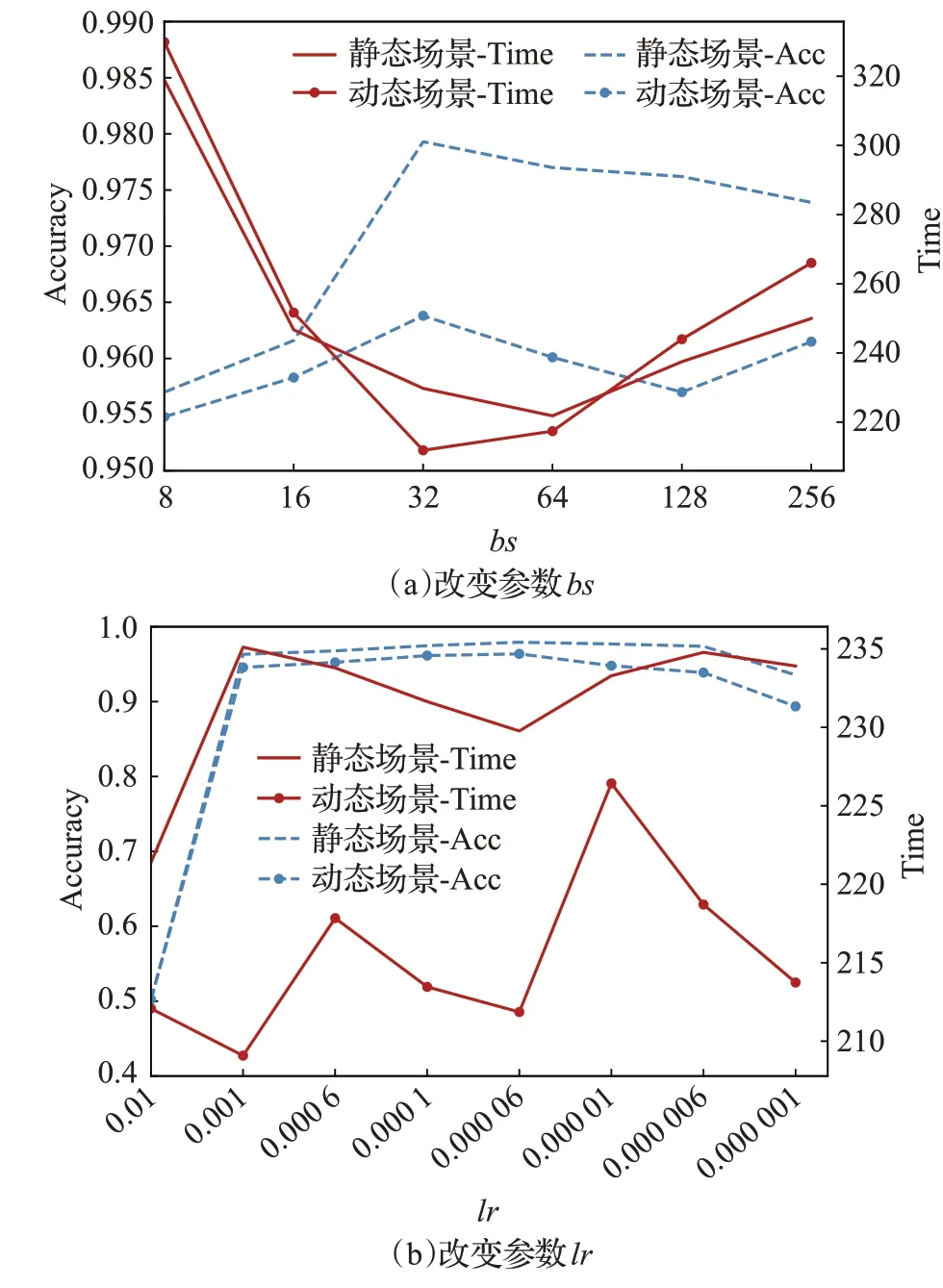
图9 超参数比较Fig.9 Hyperparameter comparison
3.4 融入注意力模块的模型对比
注意力机制模拟了人类的视觉,它能够聚焦某些特定特征而不是整片区域,从而滤除大部分噪声数据,提取有效信息。考虑到本文设计的CNN模型各方面的性能,选取模型Ⅴ融合注意力模块进行实验,以测试模型的认证准确性。由表3可知,在五层CNN模型中融入注意力模块,并改变其排列方式可以得到不同的准确率。本文所设计的CNN-SACA模型,即在模型Ⅴ第一层卷积层后按序通过改进的空间注意力子模块和通道注意力子模块,再在第五层卷积层后按反序输入注意力模块时,能达到最高的准确率99.6%。因此,本文模型采用的顺序融合方式优于其他模型的组合方式,更能关注到多场景下的MP特征,达到高准确率的身份识别。

表3 注意力模块不同融合方式的认证准确率Table 3 Authentication accuracy of different fusion methods of attention module
3.5 实验结果综合分析
3.5.1 多场景认证性能评估
本小节对CNN-SACA 模型在单场景和多场景下的认证性能以及不同行为下的认证性能进行评估。图10 给出了CNN-SACA模型分别在静态场景,动态场景以及多场景下性能评估。可以看到,所提出的CNNSACA 模型在单个场景下的准确率表现不错,能达到98.1%(静态场景)和97.7%(动态场景)的准确率,但是多场景下的认证准确率更高,能达到99.6%的准确率,由图10(b)可知,ROC 曲线表现也更好,多场景下的AUC值为0.997。结果表明,CNN-SACA模型具有强大的特征提取能力,能够对不同用户的MP特征进行准确地识别,验证了本模型在多场景下进行身份认证的可行性。

图10 CNN-SACA模型在不同场景下的性能Fig.10 Performance of CNN-SACA model in different scenarios
此外,针对多场景下不同行为特征的差异对CNNSACA 模型性能的影响,本文对数据集中的三种行为(reading、writing、map)进行分类。如图11所示,不限场景的情况下,三种行为的身份认证准确率可以达到97.5%以上,特别地在writing 行为下,准确率能达到99%以上,说明用户在输入文本时产生的MP 特征具有更强地辨识性,也证明了本文所设计的模型在不同行为下仍具有较高的认证准确率。

图11 CNN-SACA模型在不同行为下的准确率曲线Fig.11 Accuracy curves of CNN-SACA model under different behaviours
3.5.2 CNN-Ⅴ与CNN-SACA对比分析
本小节将进一步对所提出的两种深度学习网络模型进行实验分析。单独的CNN 和CNN-SACA 在单场景和多场景下各自的ROC曲线如图12、图13所示。由图可知,六种情况下的AUC值均在0.97以上,说明提出的MP特征具有很强的辨识性,可以有效地鉴别出合法用户或非法用户。而当单场景的真正率未达到0.6、多场景的真正率未达到0.8时,真正率都快速提升,变化较为一致,说明两种模型响应迅速,但在达到0.6 和0.8 以上时,CNN模型的真正率开始变化缓慢,表明其误差分类逐渐增加,模型性能开始变差,不如融合了注意力模块的CNN-SACA 模型。由此证明,无论是单场景还是多场景条件,CNN-SACA 模型的性能均比CNN 模型好,此外,CNN-SACA 的AUC 值也都高于单独的CNN模型,多场景下几乎达到1,证明了该模型的有效性和优越性。

图12 CNN-Ⅴ与CNN-SACA模型在单场景下的ROC曲线Fig.12 ROC curves of CNN-Ⅴand CNN-SACA models in single scenario

图13 CNN-Ⅴ与CNN-SACA模型在多场景下的ROC曲线Fig.13 ROC curves of CNN-Ⅴand CNN-SACA models in multiple scenarios
同时,如图14所示,本文通过计算认证结果的错误接受率FAR、错误拒绝率FRR、等错误率EER证明,在多场景的验证下,本文设计的单独的CNN 模型可以达到不错的认证结果,FAR 为3.54%,FRR 为1.76%,EER 为2.65%,而融合了注意力模块的CNN-SACA 模型三项指标均低于单独的CNN,且EER 降至1.32%。综上所述,相比于单独的CNN,所提CNN-SACA模型能更好地识别多场景下的MP特征,达到更好的认证效率。

图14 CNN-Ⅴ与CNN-SACA模型的FAR、FRR、EER对比Fig.14 Comparison of FAR,FRR and EER for CNN-Ⅴand CNN-SACA models
3.5.3 与其他算法的对比分析
本小节将证明所提出的CNN-SACA模型的有效性和合理性,表4 将本文算法与SVM、RF、CNN-Ⅴ、CNNLSTM、VGGNet、ResNet 和CNN-SE 进行了性能比较。实验结果表明,SVM与RF在验证集上的认证准确率明显比其他深度学习算法低,可见未通过手动选择特征的机器学习方法在认证准确率方面效果不佳。而在不同的深度学习算法中,本文所使用的MP特征基本能在多场景下达到准确认证的结果,准确率可达到97%以上,并且认证时间只需在2 s以内。而本文模型在验证集上的准确率可达99.6%,比CNN-V 模型提高了1.5 个百分点,证明模型泛化能力强,能较好地识别多场景下的MP特征。

表4 不同算法的准确率和单次训练时间Table 4 Accuracy and single training time of different algorithms
为了进一步研究融入注意力模块对网络复杂度的影响,表5分别从模型的参数量、浮点运算数GFLOPs等三个方面来评估该四种深度学习模型的复杂度。本文方法融入两层注意力模块后,使模型参数量比原设计的CNN 模型降低了4×106,加快了模型收敛;而在运算复杂度方面也仅升高了0.3,但是相较于加了长短时记忆网络的卷积神经网络、深层的VGG 和ResNet 来说分别缩小了0.4、12.6 和1.3,说明在硬件资源有限的情况下,本文方法也能满足部署模型的要求;此外,VGG和ResNet网络在MemR+W 方面比本文模型分别增加了近12 倍和4 倍。而融合了SE 注意力机制的CNN-SE 模型与本文模型在复杂度方面基本相当,但是在公开数据集上的准确率却远不及本文模型。综上所述,更深层的网络以及单通道的注意力模型并不适用于MP特征的提取,而本文方法兼顾了模型运算复杂度与认证准确率。
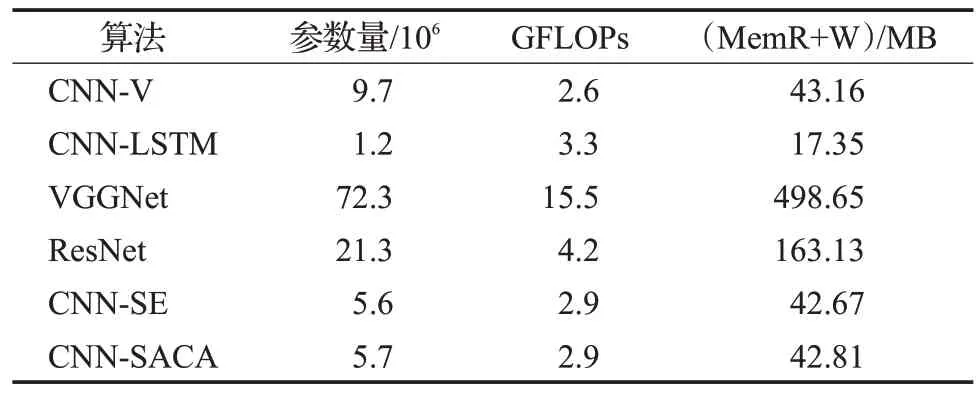
表5 不同算法的复杂度比较Table 5 Comparison of complexity of different algorithms
3.5.4 与其他相关研究对比
本节通过与其他采用同一数据集的不同类型的模型进行比较,以检验本文研究模型的优越性和有效性。表6 为各个网络模型的性能评价结果。在文献[32]中,作者利用Scaled Manhattan 分类器,使EER 达到7.16%(步行)和10.05%(坐着),而本文在多场景下的EER 仅为1.32%。文献[33]使用Siamese CNN 提取特征,再通过支持向量机进行分类,其实验准确率达到了97.8%。将本文所设计的CNN 模型与Siamese CNN+SVM 相比,准确率会有0.3 个百分点的提升,而在融合了CNN和注意力模块的情况下,认证准确率会再次提高1.5 个百分点。文献[34]利用HMM(隐马尔可夫模型)使FAR达到5.13%,FRR达到6.74%,而本文的FAR仅为1.99%,FRR 仅为1.32%。文献[35]在KRR-TRBF6 分类器下,Sensor CA 系统的中位等错误率最低为3.0%;文献[36]使用OCSVM,使EER 达到4.66%,而在本文中,CNNSACA 模型的EER 仅为1.32%。以上分析表明,基于CNN-SACA和移动模式特征的持续身份认证方法能达到更高的认证准确率,EER也达到了最优。

表6 相关工作对比Table 6 Comparison of related work
4 结束语
本文提出基于移动模式特征和深度学习的持续身份认证方法,采集移动设备多场景下的加速度传感器、陀螺仪传感器、磁场传感器数据,利用这些数据生成独特的MP 特征,并通过CNN-SACA 模型进行训练,实现在多场景下对用户身份的持续认证。实验结果表明,无论与单场景特征身份认证,还是单独的CNN模型相比,该方法可有效阻止非法访问者入侵移动设备,认证准确率更高。但是目前工作仍有部分情况未考虑到,例如同一用户可能持有多个移动设备,在切换设备使用时会产生误差。在今后的工作中,将优化本文多场景模型并应用在跨设备上。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
中国交通信息化(2018年5期)2018-08-21
时代英语·高二(2017年4期)2017-08-11
传媒评论(2017年3期)2017-06-13
第二课堂(课外活动版)(2016年2期)2016-10-21
公民与法治(2016年22期)2016-05-17
小猕猴智力画刊(2015年4期)2015-04-28
