
基于深层图卷积网络与注意力的漏洞检测方法
2024-03-03 11:22张旭升杨丰玉
计算机工程与应用 2024年3期
肖 鹏,张旭升,杨丰玉,郑 巍
南昌航空大学 软件学院,南昌 330063
随着软件的复杂化和密集化的加剧,软件漏洞已成为软件安全的主要威胁[1]。由于产生软件漏洞的原因多样,如设计错误、编码不规范、测试不足等,导致检测和修复这些复杂、隐秘且多样的漏洞成为一个挑战。为使软件远离漏洞的困扰,人们提出漏洞检测方法,通过漏洞检测,帮助人们在软件设计、编码等工作中识别潜在风险,确定审查重心,以及指导软件测试或调试工作有效开展,达到提高软件安全与降低维护成本的目的[2]。
近年来,随着人工智能技术快速发展,深度学习在漏洞数据挖掘和特征识别中显现出了巨大潜能[3-4],并受到广大学者的重视。基于深度学习的程序漏洞检测方法成为当前漏洞检测领域的一个研究热点。该方法通过收集历史程序源代码与漏洞信息组成样本数据,采用深度学习算法在已有样本数据上训练漏洞检测模型,以捕获存在漏洞风险与其程序特征之间的关联,实现对漏洞风险的量化预估[5]。当前,基于深度学习算法识别代码片段中的语句、语法及语义特征进行程序漏洞检测是一种主流研究方法[6-7]。从采取的特征性质上主要划分为两类:(1)基于token 特征,将代码视作由一系列的符号和词汇构成的序列,利用自然语言处理领域的方法训练深度学习模型。如Li等[7]将程序切片转换成token序列后利用双向长短期记忆网络(long short-term memory,LSTM)训练模型。Fan等[8]使用循环神经网络(recurrent neural network,RNN)结合注意力机对从源代码的抽象语法树(abstract syntax tree,AST)中提取节点信息获得token 序列。Ray 等[9]通过计算token 序列的交叉熵来判别代码的“异味”。(2)基于图结构特征,采用图神经网络从源代码生成的控制依赖图、数据依赖图以及抽象语法树中提取结构特征来构建漏洞检测模型。Cheng等[10]根据程序的控制流信息提取程序切片,使用图卷积神经网络(graph convolutional networks,GCN)构建用于识别与控制流相关的漏洞检测模型。Cao 等[11]在控制依赖和数据依赖关系基础上,融合函数间调用关系提取程序切片,并提出一种对流信息敏感的图神经网络模型FS-GNN(flow-sensitive graph neural network),能够有效检测出与内存相关的漏洞。Sikic 等[12]使用源程序的抽象语法树作为图结构,使用GCN 训练深度学习模型来检测程序是否有缺陷。Xu 等[13]使用bug 程序修复前后的源代码构建抽象语法树,根据树的编辑距离对抽象语法树进行剪枝获得与程序缺陷相关的子树,采用图神经网络从子树中提取结构特征,同时结合源程序的注释、修复记录等文本特征来训练缺陷预测模型。段旭等[14]将程序转换成包含语义特征信息的代码属性图,编码得到图的特征向量后使用双向LSTM 和注意力机制训练漏洞检测模型。
图结构特征相比token 序列特征在表征上更具优势[15],但已有的研究仍存在以下两个问题:(1)基于程序依赖图的代码结构在程序空间的上下文结构表征方面较弱;(2)所使用的图神经网络模型(如GCN)没有考虑过平滑问题,导致只能使用有限数量的隐层,无法学习更高阶的信息。
针对上述问题,本文提出一种基于改进图神经网络的程序漏洞检测方法。首先在程序依赖关系图基础上,融合顺序关系图(order relationship graph,ORG),进一步完善程序切片图结构表示,令代码语句具备感知其上下文信息;在图节点嵌入阶段基于代码语句的抽象语法树生成保留代码语句抽象语法结构特征的嵌入向量;最后使用深层图卷积网络并结合图注意力机制,提出一种新的图神经网络模型GCNIIAT(graph convolutional network II with attention),该模型能够更加有效地识别程序切片的图结构特征与漏洞的关联。本文在软件保证引用数据集(software assurance reference dataset,SARD)进行实例验证,结果表明,PSG-GCNIIAT的漏洞检测性能优于目前主流的深度学习算法模型,证明了PSG-GCNIIAT能够有效地提升程序漏洞检测的能力。
1 相关概念
1.1 程序切片
程序切片是分析漏洞问题的一个关键技术,广泛应用在漏洞检测、故障定位等领域。在程序调试过程中分析不可能出现错误的代码是没有意义的,删除程序中不重要的语句,使注意力集中在程序中可能包含漏洞的部分,可以极大减轻测试人员的工作负担。程序切片可以通过分析程序的数据流和控制流来分解程序,剔除与敏感操作无关语句,从而减少冗余信息。
程序切片技术的基本思路为:将程序点P和变量集合V作为切片标准,提取源程序中与切片标准存在关联的代码语句集合从而构成程序切片。一个程序切片由那些与切片标准相关的语句组成,是可执行的程序子集[16]。
1.2 图神经网络
图神经网络(graph neural network,GNN)[17]是使用神经网络来学习图结构数据的深层嵌入模型,由于能够克服浅层网络嵌入方法的缺陷而受到广泛关注。GNN 采用信息传递神经网络(message passing neural network,MPNN)[18]架构,包含信息传递和读出两个阶段,信息传递阶段使用信息函数Mt和节点更新函数Ut来更新节点的隐藏状态ht。然后在读出阶段使用一个读出函数R来计算整个图的表示。
GNN 在图结构数据上的效果十分显著,导致GNN研究火热,近年来出现了许多GNN的变体,如图卷积神经网络GCN[19],图注意力神经网络(graph attention neural networks,GAT)[20]等。
2 程序漏洞检测方法
2.1 整体流程
本文以程序切片作为分析对象进行漏洞检测研究。程序切片粒度漏洞检测是一种细粒度检测方法,相比于函数、类,它能提供更为精准的故障定位能力。同时,程序切片比单行语句包含更丰富的信息,由于剔除了程序中无关代码,其代码本身具有明显的结构特征性。程序漏洞检测流程如图1所示。

图1 漏洞检测流程Fig.1 Vulnerability detection procedure
首先将源代码转化为AST进行程序语法分析,基于切片标准的控制依赖和数据依赖关系提取的代码片段,并构造程序切片的程序依赖图。然后在此基础上构造顺序关系图,增强感知代码语句上下文信息的能力。其次,在进行模型训练前需要进一步采用节点嵌入的方法对程序切片的图结构表示进行向量化。最后,采用基于图的深度学习方法训练漏洞检测模型,本文使用深层图卷积网络GCNII[21]作为基础学习架构,结合图注意力机制构建GCNIIAT 模型,作为漏洞检测模型对待检测的程序切片进行漏洞检测。
2.2 程序切片图结构表示
程序切片的图结构表示通常使用控制依赖关系图和数据依赖关系图[22],控制依赖关系图描述了程序语句之间的执行关系,通常与逻辑控制语句(包含if else、for、while、switch、case等关键字)有关;数据依赖关系图描述了程序中变量的定义与使用关系。
使用开源工具Joern 对源程序进行解析,获得源程序的控制依赖关、数据依赖关系信息,构建程序依赖关系图PDG。选择敏感函数调用作为切片标准进行切片,得到描述程序切片PDG,切片包含的代码语句集合称为code gadget[6]。为了丰富程序切片的图结构特征信息,本文提出一种新的图结构表示顺序关系ORG,ORG 描述代码行语句在code gadget 中的顺序关系,建立节点之间的顺序关系能够提升模型在感知code gadget在上下文环境中的特征信息。ORG的构建采用滑动窗口机制,根据code gadget 中的代码行位置信息进行顺序移动,过程如图2所示。

图2 ORG提取过程Fig.2 ORG create procedure
算法1 描述了ORG 构建的过程。算法的输入是程序切片的行号集合LOCs 和上下文窗口大小window_size。对代码行号集合LOCs进行排序,然后在LOCs上使用滑动窗口机制划出设定大小的窗口,对窗口内的行号构建表示顺序关系的边。
算法1构造顺序关系图ORG_create
得到程序切片的ORG 后,与程序依赖图PDG 组成程序切片图(program slice graph,PSG),以此丰富程序切片的结构信息,达到系统化表征程序切片的目的。
2.3 图结构表示规范化
程序切片的图结构表示不能直接作为图神经网络的输入,需要规范为标准输入数据才能被学习模型用于检测模型的构建。图结构表示的规范分为图节点特征向量化与构造描述PSG 的邻接矩阵两部分。通过图节点嵌入方法,将图节点特征映射到向量空间,达到图节点信息向量化表示的目的,边邻接矩阵则通过PSG的边来构建。
(1)图节点特征向量化
本文使用InferCode[23]生成PSG 节点代码行的初始特征向量。由于程序中的变量名可由程序员自定义,这会导致在生成代码行特征向量时引入噪声。为了解决这一问题,采用统一的符号表示对源程序包含的变量名词汇进行符号化,以减少由程序变量的个性化命名所带来的噪声,更好地保留原始的代码语义。对于自定义的变量名,使用VAR_number 来表示,对于自定义的函数名使用FUN_number来表示,number用变量名和函数名在代码中出现的先后来计数表示。
完成对程序切片的符号化后,使用InferCode 生成代码行语句的向量表示。InferCode 是一种自监督学习算法,训练过程不需要样本的标签,它可以将任意大小的代码块编码为一个固定长度的向量。InferCode 借鉴了Doc2Vec 的思想,将代码块对应的AST 视为文档,AST的子树视为文档中的单词,通过AST预测其子树来训练一个可以将代码块进行编码的编码器。
对于给定的代码块集合,InferCode 生成对应的AST 集合{T1,T2,…,Tn},Ti的子树集合为{…Tij…},其核心是最大化子树Tij在Ti上下文中出现的概率和Pi,Pi的计算如公式(1)所示:
InferCode 使用基于树的卷积神经网络(tree-based convolutional neural network,TBCNN)来获得AST 节点初始编码向量。通过卷积前向传播进行特征提取和融合,使用注意力机制生成AST子树编码向量,最后使用softmax 计算所生成AST 子树编码向量与AST 编码向量的交叉熵,经反向传播更新TBCNN的权重参数,最终完成训练的TBCNN模型作为代码表征的编码器可用于各种下游任务。
(2)构建边邻接矩阵
构建邻接矩阵Apsg表示PSG的节点关系。PSG包含PDG和ORG两种类型的边集合Epdg和Eorg,通过遍历程序切片的PSG,可得:
完成上述两步得到代码行语句的特征向量和描述PSG的邻接矩阵即为图结构表示规范化的结果,二者组成GCNIIAT模型的标准输入数据。
2.4 GCNIIAT
GCN能够有效地检测出程序漏洞,然而文献[21]指出GCN 存在过平滑问题导致只能使用有限数量的隐层,这会限制GCN学习更高阶信息的能力。另一方面,程序漏洞检测存在类间差异小的问题,即某些存在漏洞的程序切片与不存在漏洞的程序切片的差异非常小,而注意力机制可以在关键特征上赋予更多的注意力权重,从而指导模型根据关键的细微差异进行分类。因此本文提出GCNIIAT 方法,使用深度图卷积网络GCNII 结合图注意力机制进一步来提升图节点特征的表征与漏洞检测的准确度。
GCNIIAT 首先通过GCNII 层和图注意力层来学习节点特征的表征,随后在卷积层使用卷积和池化对节点特征进行筛选,最后通过多层感知机训练检测模型,完成漏洞检测任务。
2.4.1 GCNII层
GCNII 采用了ResNet[24]的残差学习思想,在传统GCN 中引入了初始残差连接和恒等映射。GCNII 层使用公式(3)来学习获得节点的表示向量:
对于输入节点特征X,GCNII 首先经过全连接层得到H(0),以此作为初始残差按比例连接到后面的其他层,确保节点的最终表征都包含节点初始特征信息。然后类比ResNet 中的恒等映射,将单位矩阵I按比例加到权重矩阵Θ上,随着层数增加,比例系数β不断减小,表明当层数越深时越接近恒等变换。
2.4.2 图注意力层
注意力机制核心是根据输入数据自适应地关注相关性高的特征而忽略相性低的特征[25],图注意力层的输入是程序切片图结构中顶点初始特征向量的集合X={x1,x2,…,xm},xi∈Rd,以及描述顶点之间关系的邻接矩阵A。输出的是新的顶点特征向量集合H′=,d′表示新的维度。在分配注意力时只分配给顶点i的相邻顶集合Ni上,此时注意力相关系数aij由公式(4)计算得到:
总之,在科学哲学家所构建的科学理论中,苏佩斯作为理论模型的首创者,不遗余力地对科学理论进行数学化的研究,萨普与范·弗拉森则将经验知识赋予模型之中,史纳德等人将这两种观点加以融合,建立了一个比较完整的理论体系,并最终走向成熟。
其中,aT是前馈神经网络参数,W是被所有hi共享的权值矩阵,LeakyReLU是激活函数,[Wxi||Wxj]是对顶点i和顶点j的特征向量进行拼接。
为了使模型训练过程更加稳定,本文使用多头注意力机制,对K个独立的注意力机制计算结果求均值,最终可得到hi′:
表示第k阶的注意力机制的注意力系数归一化的结果,Wk表示第k阶的注意力机制的权值矩阵。
2.4.3 卷积层
经过GCNII 层和图注意力层分别得节点特征集合H和H′,在卷积层通过卷积运算与池化操作,对节点信息进行筛选,进一步减小特征的空间大小,避免模型训练过程中出现过拟合。具体过程如下:
式(6)表示使用MaxPool来筛选卷积窗口内最重要的特征,式(7)和(8)分别表示对节点特征做卷积运算,其中为图注意力层获得的节点特征,表示对图注意力层获得的节点特征与GCNII 层获得的节点特征进行拼接,卷积的层数为l。最终得到,然后将二者输入多层感知机MLP,对结果计算点积并求均值,通过SigMoid函数实现最终的程序漏洞结果预测,如式(9)所示:
在训练完检测模型后,可用于对目标程序切片数据进行漏洞检测。
3 实验研究
3.1 实验设置
实验使用的源代码数据来自于软件保证参考数据集SARD,包含多种常见漏洞类型的源程序,是目前信息安全领域广泛用于漏洞分析研究的一个基准数据集,已被广泛应用于安全缺陷领域的研究工作,并且该数据集提供了真实且详细地漏洞信息,可以定位漏洞发生的位置,从而为提取的程序切片设置漏洞标签。本文选择SARD 中最为常见的10 种漏洞类型的程序数据集作为实现对象,如表1所示。实验过程将对每类数据集划分为训练数据集和测试数据集,比例分别为80%和20%。

表1 漏洞数据集Table 1 Vulnerability dataset
实验选择近几年提出基于深度学习的程序漏洞检测模型作为比较对象,分析它们在漏洞检测任务上的性能表现。比较方法为:采用双向长短期记忆神经网络Bi-LSTM 对切片tokens 学习的VulDeePecker,图卷积神经网络GCN,基于门控循环单元的消息传播模型——门控图神经网络(gated graph neural network,GGNN),以及本文提出的GCNIIAT。
VulDeePecker 模型的Word2vec 词向量模型中单词向量维度为100,最小词频为1,迭代次数为10。
使用切片的平均词汇数量作为上限,不足的情况使用0 向量补齐。VulDeePecker 中的BiLSTM 模型使用3层隐层,每层300个隐含节点,Dropout方法的节点保留概率为0.5,批处理大小为64。
对图结构学习算法GCN、GGNN、GCNIIAT,在节点嵌入阶段使用InferCode 生成代码语句的嵌入向量,嵌入向量维度为100。GCN 与GGNN 算法的以传统PDG作为程序切片图结构进行训练,GCNIIAT 使用融合ORG 后的PSG 作为程序切片图结构进行训练,其中ORG窗口为4。GCNIIAT在图嵌入阶段的GCNII层,设置输入和输出的特征维度都为100,隐层数量为5;图注意力层的数量为3;池化过程卷积层层数为2。训练过程使用批量训练方式,每批128个样本。
实验使用四个常用评价指标:准确率、精准率、召回率和F值,来评估实验的结果,计算公式如下所示:
公式中的TP指的是被分类器正确标记为有缺陷的样本数量,FN指的是把有缺陷样本标记为无缺陷的数量,FP指的是被分类器标记为有缺陷的无缺陷样本数量,TN指的是被分类器正确标记为无缺陷的样本数量。
3.2 实验结果分析
考虑训练中的随机因素会对深度学习算法的输出结果产生较大影响,实验中对每个算法使用训练数据集经多轮迭代训练使模型性能达到稳定后应用在测试数据集上。实验结果如表2所示。
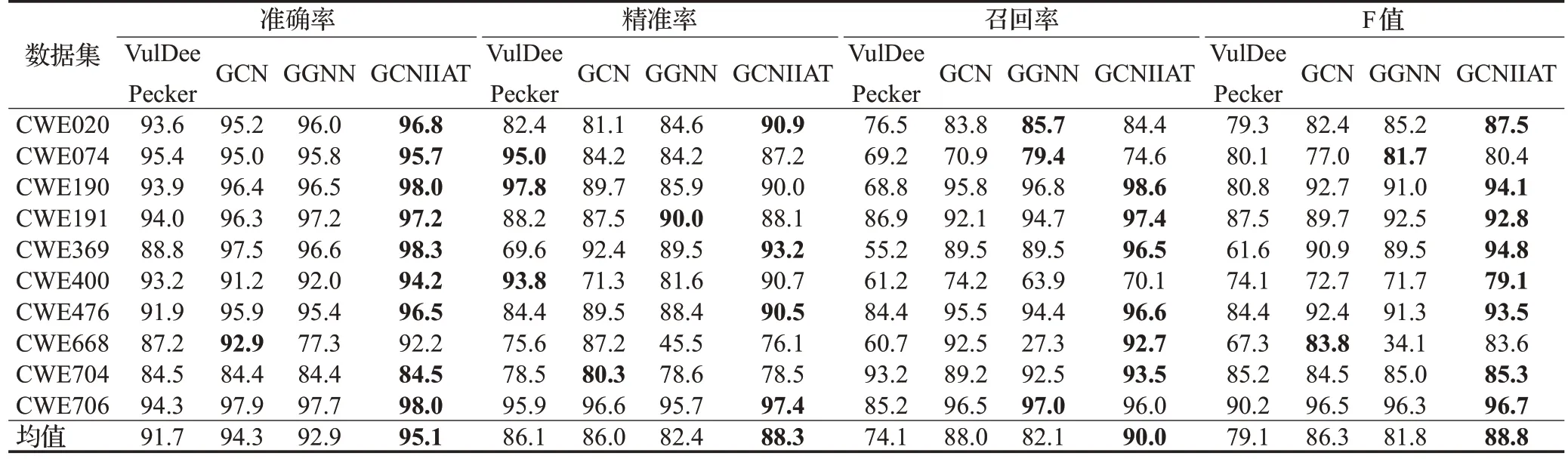
表2 各数据集评价指标Table 2 Evaluation metrics of each dataset 单位:%
观察每组实验对象中表现最好的数值(表中加粗)可以看出,在所有10个实验数据集中,GCNIIAT的准确率有9 次获得最佳表现,F 值在其中8 个数据集获得最高值,在非最好数据时与最佳数据的差距也比较小。这表明本文提出的GCNIIAT在不同数据集对象上应用均能取得较好的漏洞检测表现。
对比基于token特征的VulDeePecker模型和基于图结构特征的模型GCN、GGNN、GCNIIAT的数据,可以发现基于图结构的模型的检测结果均好于VulDeePecker,证明采用图结构描述程序切片比采用token方法能够获得更好的漏洞检测效果。程序切片本身是基于控制依赖和数据依赖进行切割的程序片段,程序切片的属性特征更适合用图结构表征。
从统计的角度观测平均值分析算法的综合性能发现,GCNIIAT的准确率、精准率、召回率和F值指标的平均数分别达到95.1%、88.3%、90%和88.8%,在所有算法中平均值的指标均为最好。主要指标准确率和F值,比其他模型均有明显的提升。综合来看,GCNIIAT在所有算法中的表现无疑是出色的。如果采用平均值来量化衡量性能的提升,以比对其他算法的指标平均值作为衡量基准,本文提出GCNIIAT 算法在准确率指标上提升2.33%,F值上有7.48%的提升。
本文在传统的PDG 上融合ORG,为了验证它是否比传统的PDG 更具有表征能力,进行对比实验比较GCNIIAT 单独使顺序关系图ORG、单独使用程序依赖图PDG和使用程序切片图PSG三种情况下的F值,设置ORG窗口为4,实验结果如图3所示。

图3 不同图结构的F值Fig.3 F-measure of different graph structures
从实验结果可以看出同时使用PDG 和ORG 时,F值普遍得到提升。程序漏洞的发生往往与其所处的上下文有关,代码行所处的上下文由其与之前和之后一定范围内的代码块体现出来,对于一个程序切片,PDG能提供控制流和数据流的信息,而ORG 能进一步丰富代码行所处的上下文信息。
PSG-GCNIIAT提升漏洞检测性能的一个主要原因在于该方法在表征程序切片的图结构中引入了ORG,使算法在感知程序切片结构时不再只考虑控制依赖关系和数据依赖关系,而是对切片中语句的前后上下文依赖关系也会关注。需要注意的是,ORG的提取使用了滑动窗口机制,采用不同大小的窗口对构建ORG 数据是有影响。窗口过小可能达不到预期提升的效果,太大会使模型参数增加,存在过拟合风险。因此,本文进一步对窗口大小参数进行分析。设置窗口大小的取值范围是2到6,观察不同数据集的F值,实验结果如表3所示。
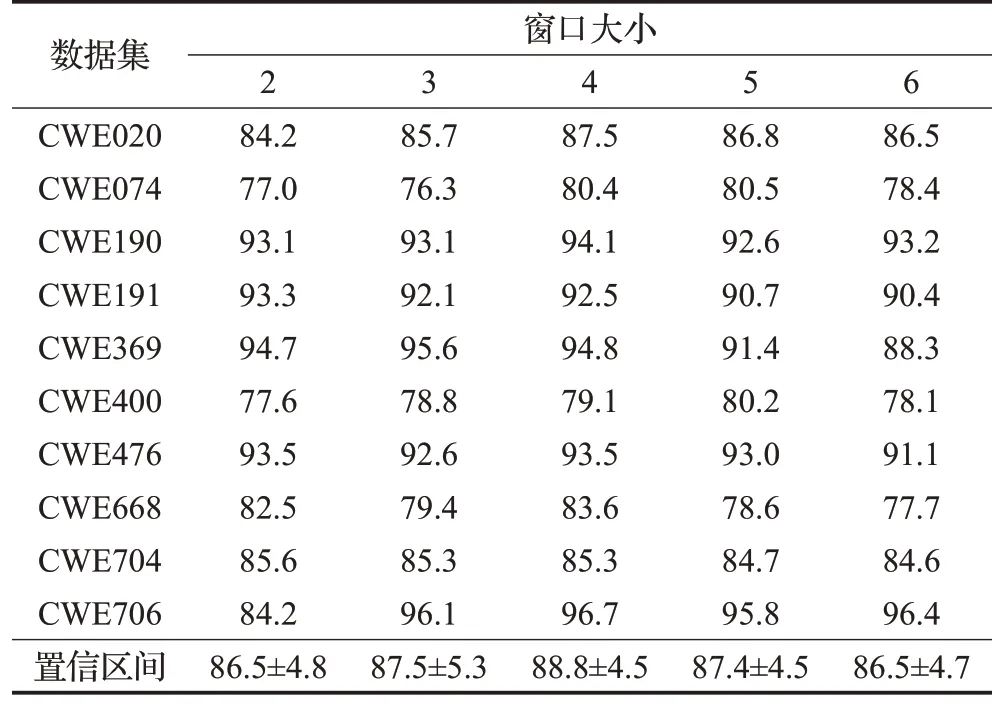
表3 不同窗口的F值Table 3 F-measure of different window size 单位:%
从实验结果观察窗口变化对不同数据集的影响,可以发现不同数据集受窗口变化的影响不尽相同。其中CWE020、CWE190、CWE476、CWE706 当窗口为4 时效果最好,CWE074、CWE369和CWE668受窗口影响的波动较大,而CWE020、CWE190 和CWE704 受窗口的影响较小,结果较稳定。可以看出,不同数据集的最佳窗口大小是有区别的。
从整体上看,窗口大小为4的时候,95%置信区间为88.8%±4.5%,比其他窗口大小的数据均要优异。其次,窗口为3 和5 时,模型表现略低。窗口大小从2 变化到6,F值的数据趋势为先增后降。
4 结束语
本文提出一种基于深层图卷积网络与图注意的程序漏洞检测方法PSG-GCNIIAT,该方法在传统程序依赖图的基础上融合顺序关系图作为程序切片的图结构PSG,并使用InferCode 生成图节点代码行的嵌入向量。此外,将GCNII 与图注意力机制相结合,有效地提升了漏洞检测模型的学习能力。本文选择SARD 中10个常见程序漏洞数据集进行实验,对PSG-GCNIIAT有效性进行了验证。实验结果表明,与近年来提出主要深度学习算法VulDeePecker、GCN、GGNN相比,PSG-GCNIIAT在准确率指标与F值指标上具有显著优势,F值提升7.48%。综合来看,PSG-GCNIIAT是一种性能表现优异的程序切片粒度的漏洞检测方法,出色的性能将为其为下游任务提供巨大的应用潜力,如为故障定位提供先验知识。
本文对程序切片图结构表示的图节点特征向量嵌入有待进一步完善,特别是复杂的语法结构特征体现方面需要强化。如何从多个维度对程序切片代码行语句进行嵌入,并进行有效地聚合,获取信息更全面和系统的图结构表征方法仍需要进一步研究。
猜你喜欢
今日农业(2022年13期)2022-09-15
动漫星空(2018年11期)2018-10-26
动漫星空(2018年2期)2018-10-26
动漫星空(2018年9期)2018-10-26
动漫星空(2018年5期)2018-10-26
电信科学(2016年11期)2016-11-23
中国卫生(2016年5期)2016-11-12
儿童时代(2016年6期)2016-09-14
中国组织化学与细胞化学杂志(2016年3期)2016-02-27
中国卫生(2015年12期)2015-11-10
