
考虑错分代价的ADASVM-CSLINEX模型及应用
2024-03-03 11:22杨园园鲁统宇许文甫
计算机工程与应用 2024年3期
杨园园,鲁统宇,崔 俊,许文甫
中国计量大学 经济与管理学院,杭州 310018
现实生活中普遍存在着各种二分类问题,许多实际应用领域都能见到其身影,比如气象预警中的降雨预测[1]、垃圾邮件分类[2]、医疗诊断[3-4]、欺诈检测[5]、质量检测[6]、财务预警[7-8]、信用评分[9]、股票收益预测[10-11]等诸多领域。二分类问题应用的广泛性促使学者们不断探索更多性能优异的方法解决现实中存在的问题。
传统的用于解决二分类问题的方法有判别分析、逻辑回归等,但随着数据广度和深度的不断加深,传统分类算法已经很难满足从海量数据中进行深度信息提取的需求,随着大数据分析技术的迅速发展,机器学习算法逐渐成为数据分类和回归的主流工具。其中,比较经典的数据分类算法有K近邻[12]、决策树[4]、支持向量机[9]、朴素贝叶斯[13]、神经网络[3,10]等,各种机器学习算法也被广泛应用于不同的分类预测问题中。
相较于单一机器学习分类算法,集成算法能够捕捉更多有效信息,多数情况下能够显著提升预测模型的分类效果以及泛化能力。集成算法通过某种规则将多个学习器进行组合来完成学习任务,主要包括Bagging、Boosting 和Stacking 系列算法。Bagging 是从原始数据集中通过有放回采样得到多个新数据集,然后将某个学习算法分别作用于每个新数据集就得到了多个弱分类器,选择分类器投票结果中最多的类别作为最后的分类结果。随机森林是其代表性算法,Khaidem 等[14]使用随机森林分类器构建股票预测模型,结果显示了该模型在多个数据集上都具有较好的长期预测的准确性。不同于Bagging,Boosting是在每一次迭代过程中,都会根据弱分类器的分类结果对样本权重进行调整,使得先前被错误分类的样本的权重增加,然后基于调整后的样本权重训练下一个基分类器,最后将每次训练得到的弱分类器组合成一个强分类器。Boosting 算法中最流行的则是AdaBoost算法,Sun等[15]提出一种改进AdaBoost算法的多因素股票选择模型,并对上证A股进行了实证分析,结果显示所提模型表现出更好的分类性能。Stacking是一种分层模型集成框架,利用初始训练集训练出多个初级学习器,然后用初级学习器对测试集进行预测,将输出值作为下一阶段训练的输入值,用于训练次级学习器。罗泽南[16]利用Stacking方法将随机森林、梯度提升树、XGBoost 和神经网络多种机器学习模型进行集成,建立RGXB-Stacking模型,研究证明其回测效果明显优于其他单一模型。在这三类集成框架中,Boosting算法更加关注于错分样本,通过对错分样本权重的提升来提高模型的预测准确度,被较为广泛地应用于各种不同的分类预测问题。
在二分类问题中,不可避免地会产生“实际为真预测为假”“实际为假预测为真”两类错误,多数情况下两类错误的代价是不同的。比如医疗诊断中将一个患者诊断为健康人的错分代价远远大于将一个健康人诊断为患者的代价[17];在银行贷款服务中将违约客户分类为正常用户的错分代价远远大于将正常用户分类为违约的代价[18];而在手机用户价值分类问题中高价值用户的错分代价也远远高于低价值用户的错分代价[19]。又例如,在量化投资领域关于股票涨跌的二分类预测中,两类预测错误所带来的损失是不一样的。对于以低价买入高价卖出作为基本投资策略的投资者而言,第一类错误(实际为涨预测为跌)是以投资者丧失一种潜在的收益为代价;而对于第二类错误(实际为跌预测为涨),投资者们将面临因预测错误而带来的资金的真正损失,后者的错分代价显然要大于前者。可见,这种错分代价不平衡问题在二分类预测中较为普遍,为了有效控制代价较高的一类分类错误,在进行模型构建的过程中有必要将错分代价这一问题考虑在内。
在二分类问题中,相关研究常常关注两类不平衡问题:一类是不同类样本错分代价不平衡问题[20],另一类是不同类样本数量不平衡问题[21]。本文讨论的是不同类样本错分代价不平衡问题,经典的用于解决错分代价不平衡的方法主要包括:一是通过重采样的方式改变原始数据集的分布,增大错分代价较大的样本数量,使原来对代价不敏感的分类算法在重构的新数据集上代价敏感的采样方法,如Zadrozny 等[22]提出的Costing 方法。二是通过对原始训练集中的样本赋予不同权重来实现代价敏感的Rescaling 方法。Ting 等[23]提出按错分代价的比例调整样本的权重来平衡数据集,再将数据集放入CART模型中训练,结果发现这种样本加权方法是有效的。三是通过调整分类器的决策阈值实现代价敏感。如Domingos[24]提出的MetaCost方法、凌晓峰等[25]提出的经验阈值调整算法(ETA)。四是通过修改具体的机器学习算法,直接将错分代价引入分类模型中实现代价敏感。具体有代价敏感决策树[26-27]、代价敏感KNN[28]、代价敏感逻辑回归[29]、代价敏感支持向量机[30-31]、代价敏感Boosting算法[32-33]等。代价敏感可以与许多机器学习分类算法结合,它们的处理方法有很大不同。如代价敏感决策树通过利用代价敏感信息修改决策树的分裂标准实现代价敏感,代价敏感KNN通过修改KNN算法中的距离加权投票函数实现代价敏感,代价敏感逻辑回归是将错分代价信息引入到逻辑回归目标函数实现代价敏感,代价敏感支持向量机可以通过在铰链损失函数中加入错分代价信息或者直接用其他具有代价敏感的损失函数替换铰链损失函数实现代价敏感、代价敏感Boosting 算法则可以通过修改权重更新方式实现代价敏感。采样方法改变了原始数据集的分布,可能会影响分类模型的分类性能。而通过调整分类器决策阈值的方式则对准确预测每个样本预测概率具有较高要求。相较而言,修改具体的机器学习算法通过将错分代价信息与各种机器学习分类算法结合就可以实现代价敏感,在近年来受到了广泛的欢迎。
本文是通过在AdaBoost-SVM的权重更新方程中引入了一种非对称线性指数(LINEX)损失函数来实现的不同类样本的错分代价。该损失函数最先是由Varian[34]提出的,与对称损失函数相比,LINEX 损失函数对低错分代价的样本进行线性级惩罚,对高错分代价的样本进行指数级惩罚。Ma 等[35]、Fu 等[36]利用LINEX 损失函数的这种特性对支持向量机模型进行修改实现了代价敏感学习。
股票涨跌预测是金融领域中一个重要的二分类问题,然而由于股票市场复杂多变的特性,投资者很难从中挖掘出有效的市场信息,这也就使得股票的预测极具挑战性,本文以股票的涨跌预测作为应用研究问题来构建一种新的二分类模型。此外,在股票涨跌预测中,因子的时效性是一个重要因素,有些因子在某一期内有效,在下一期内可能失效,所以整个过程应该要动态地筛选因子,去除无效因子,引入有效因子,从而保证每一期的因子都是最有效的[37]。
综上所述,当不同类样本的误分代价不相等或者差异较大时,基于总体准确率的传统数据挖掘方法已经不再适用,而具有代价敏感的学习算法则可以被用来解决此类问题。本文以股票未来的涨跌作为预测目标,选择Lasso-Logistic 算法动态筛选每一期的重要因子,在AdaBoost-SVM中引入LINEX损失函数,根据样本是否错分以及正负类样本的不同错分代价更新样本权重,最终构建一个考虑错分代价的集成选股模型。
1 模型介绍
支持向量机(SVM)是机器学习中经典的分类模型方法,其通过核函数可以将原本线性不可分问题转化成线性可分问题,其次它还具有很好的泛化能力,一定程度上可以避免模型过拟合。AdaBoost 是一种经典的集成算法,它根据前一个弱分类器的分类结果更新样本的权重,之后将更新过权重的样本点传送到下一个弱分类器进行训练,最后将每次训练得到的弱分类器组合成一个强分类器,该强分类器比弱分类器能够获得更高的准确率。鉴于SVM 和AdaBoost 良好的分类性能,所以本文构建基于LINEX损失函数的代价敏感AdaBoost-SVM集成算法,并应用于多因子选股模型。相较于以往的研究,本文考虑了股票涨跌预测中的错分代价问题,并且通过引入了LINEX损失函数对负类样本进行指数级惩罚、对正类样本进行线性级惩罚。
1.1 支持向量机
SVM算法的思想就是利用某些支持向量所构成的“超平面”,将不同类别的样本点进行划分。无论样本点是线性可分的还是非线性可分的,都可以利用“超平面”将样本点分割开来。对于非线性可分的样本点,需要借助核函数技术将低维线性不可分的空间转换成高维线性可分的空间,以此实现线性可分的操作。
本文选用非线性的SVM,假设原始空间中的一组样本点的集合为,其中xi∈Rk,yi∈{-1,1}。对于任意原始空间中的样本点xi、xj,通过核函数将原始低维空间样本映射到更高维空间中,从而使线性不可分问题转化为线性可分问题。在此基础上引入松弛因子ξi(ξi≥0)和惩罚系数C(C >0),由于ξi在推导过程中被抵消,最后得到的目标函数可以表示为:
SVM 中核函数的选择多样,其中径向基核函数是一种指数函数,它可以把原始样本点映射到高维空间中,同时也比较常用,所以本文选择使用径向基核函数。径向基函数的表达式为:
1.2 AdaBoost-SVM算法
AdaBoost 算法是基于前一轮的分类结果对样本点设置不同的权重,对于预测正确的样本,在下一轮迭代中减小它的权重,对于预测错误的样本,在下一轮迭代中则增加它的权重,接着对权重更新后的样本进行新一轮的迭代,在新一轮迭代中,基分类器会更加关注权重大的错分类样本,最后将训练得到的弱分类器组合成一个强分类器。AdaBoost-SVM 算法是AdaBoost 算法与SVM算法两者的集成[38],是将SVM作为AdaBoost框架中的基分类器进行循环迭代,其权重更新机制不发生改变。
1.3 考虑错分代价的ADASVM-CSLINEX算法
1.3.1 LINEX损失函数
LINEX损失函数首先被Varian[34]提出,其表达式为:
其中,a是一个非0 的超参数,它确定了LINEX 的陡峭程度。图1显示了不同a值下的LINEX损失函数,可以看出,a的绝对值越大,图形就越陡峭;当a<0 时,函数左边比右边更陡峭,表示负类样本比正类样本受到更重的惩罚,当x趋于负无穷大的过程中,L(x)呈指数级增长,当x趋于正无穷大的过程中,L(x)呈线性增长;当a>0 时情况则相反。
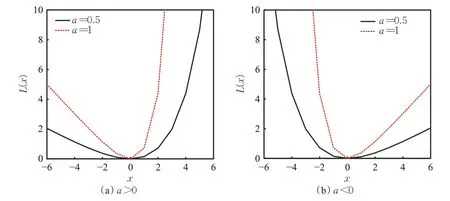
图1 不同a 值下的LINEX损失函数Fig.1 LINEX loss function at different a values
1.3.2 CSLINEX损失函数
其中,a为LINEX损失函数的参数。以CSL(yi)=exp(ayi)-ayi-1(a<0)为例,当正类样本被错分时,其受到的惩罚为线性惩罚;当负类样本被错分时,其受到的惩罚为指数惩罚,此时负类样本被错分所受到的惩罚要大于正类样本;如图1 中的(b)所示,当a的绝对值越大时,相应类别下的样本受到的惩罚也更重。当a>0 时,情况则完全相反。由于本文重点关注的是负类样本分类的准确率,所以后文只研究a<0 时的情况。
1.3.3 ADASVM-CSLINEX算法
ADASVM-CSLINEX 算法以SVM 为基分类器,它同时兼具AdaBoost 和CSLINEX 的优点,一方面在基分类器迭代过程中根据样本是否被错分重新更新样本权重,另一方面在每一次迭代中根据不同类样本错分代价的不同更新权重。初始平均样本权重和样本权重更新函数见式(5)、(6)。
在上述公式中,U是总的迭代次数,m为训练集的样本量,a<0,yi为真实值,fu(xi)为预测值,W1为初始样本权重分布,表示经过第u次迭代后的样本权重,为第u+1次迭代后的样本权重。为权重惩罚方向,若样本分类正确,取1,在下一轮迭代中其样本权重会减小;若样本分类错误,则取−1,在下一轮迭代中其样本权重会增加。针对yi=1/fu(xi)=-1的情况,其权重更新公式为exp(αuexp(a)-a-1);针对yi=-1/fu(xi)=1 的情况,其权重更新公式为exp(αuexp(-a)-(-a)-1),由图1(b)可知,同一a值下,后者的样本权重高于前者。αu是AdaBoost集成的第u个基分类器的投票权重,由公式(7)可知,其大小由第u个基分类器的误差率eu所决定。
具体的ADASVM-CSLINEX算法如下:
输入:初始训练集D={(xi,yi)}(i=1,2,…,m),m为训练集的样本量。
(2)对于u=1,2,…,U
①根据权重分布Wu从其训练集D中选择一个训练数据子集Du;
②在训练数据子集Du上训练一个基分类器SVM u,表示为fu(x);
③计算基分类器SVM u在Du上的分类错误率eu;
④如果eu≥0.5,保持u的值不变并返回到步骤①,否则继续步骤⑤;
2 研究设计
2.1 数据来源与样本选取
本文选取2011 年1 月到2020 年12 月沪深300 指数所有成分股为研究样本,数据为月度频率,由于财务指标仅有季度数据,用季度数据进行月度填充[39],数据均来自于Wind 数据库。在实际训练中,运用滑窗技术将样本数据分为训练集和测试集,将窗口长度设置为13个月,前12个月作为训练集,后1个月作为测试集,之后依次向前滑动1个月进行下一个窗口的预测。
由于数据量庞大,不可避免地会有数据缺失、量纲不统一等问题出现,所以在建模之前先进行数据预处理,否则会严重影响模型的预测效果和结果的可靠性。本文的数据预处理如下:
缺失值处理:(1)某只股票在第t月收盘价数据存在缺失,则剔除该股票在月份t上的所有数据;(2)若某只股票因子值的缺失值比例大于等于30%则进行删除处理,对缺失值比例不超过30%的样本使用随机森林算法进行填充。最终,确定了70个指标和296只成分股。
标准化处理:为消除因子量纲不一致的现象,对所有指标数据进行标准化处理。
本文研究的响应变量y为月度收益率涨跌,若上涨取1,若下跌取−1,y的取值由月度收益率R=ln(Pt/Pt-1)确定,其中,Pt为当月收盘价,Pt-1为前一月收盘价。
2.2 初始因子池的构建
在前人研究的基础上,本文选取了每股指标、偿付能力因子、营运能力因子、成长因子、盈利因子、价值因子、行情指标以及技术指标来构建初始因子池。初始因子池的指标构成见表1。

表1 初始因子池Table 1 Initial factor pool
2.3 变量筛选
随着时间的推移,不断地会有新数据流入,基于历史数据筛选出的重要因子在下一期中可能失去作用,因此,整个过程需要动态地选择因子,从而保证每一期的因子都是最有效的。该部分使用Lasso-Logistic 回归算法动态筛选因子。
Lasso回归是一种缩减性估计,通过添加L1正则的惩罚项将一些不重要的回归系数直接缩减到0,从而降低模型的复杂度,实现变量筛选的功能。同时它也不受自变量多重共线性的影响,当出现较为相关的多个变量时它会选择其中的一个,而将其余变量的系数压缩为0,非常适用于变量筛选。由于对股票进行预测的因变量是二元离散变量,线性回归模型已经不再适用,所以使用Lasso-Logistic 回归模型。Lasso-Logistic 回归模型是在求解Logistic回归的参数估计时加入对参数的惩罚项来达到变量选择的目的。假设有一个包含m条股票数据观测值的数据集,其中xi={xi1,xi2,…,xiK},yi∈{-1,1}。其估计值表示如下式:
由图2可知,运用Lasso-Logistic模型分别对每一期训练集进行变量筛选,每个训练集中重要因子的数量是不同的,说明了某些因子在某一期内与因变量相关性较强,而在下一期相关性可能就减弱。为了使所选因子尽可能地反映出因变量的真实信息,需要对每一个训练集重新进行特征因子的筛选。图3 显示了每个特征因子的重要程度水平,从图中可以看出一些因子被选择的频率很高,而一些因子被选择的频率却很低,虽然股票池中有70个初始因子,但因子的重要性却有很大差异,足以可见动态筛选因子的必要性。
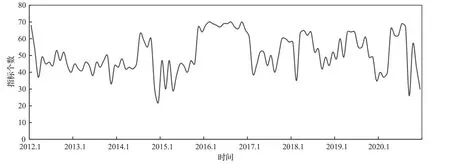
图2 各测试集选择的特征变量个数Fig.2 Number of feature variables selected for each test set
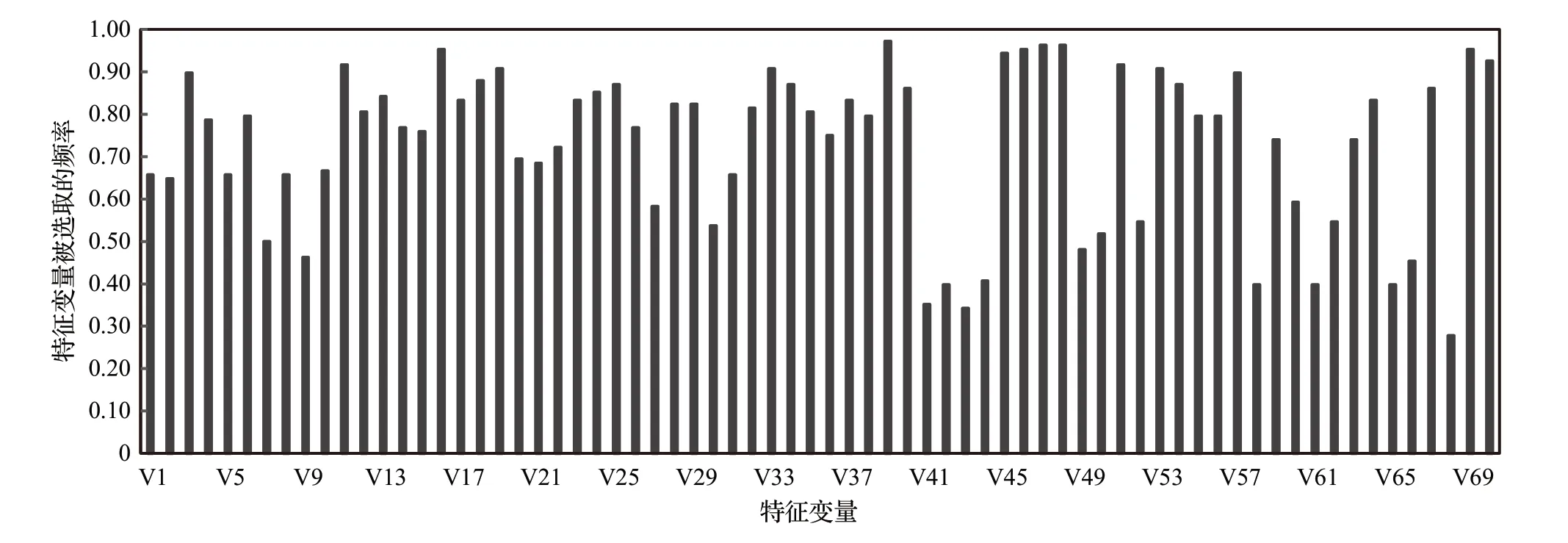
图3 特征变量被选择的频率分布图Fig.3 Frequency distribution of selected feature variable
2.4 模型的评价指标
在考虑错分代价的情况下,以总体分类准确率作为评价标准不能反映模型的真实预测性能,所以本文选用ACC、TPR、TNR、Precision、G 值以及AUC 等多个指标同时衡量各模型的预测效果。ACC是模型的整体准确率;TPR 是正类样本的准确率;TNR 是负类样本的准确率;G值是TNR和TPR的几何平均数,是一个同时衡量正例准确率与负例准确率的综合指标。AUC是ROC曲线下的面积,ROC使用两个指标值进行绘制,其中横轴为1−TNR,为负类错判率,纵轴为TPR,为正类准确率。模型各评价指标根据表2所示的混淆矩阵计算得到,具体计算公式见式(10)~(14):
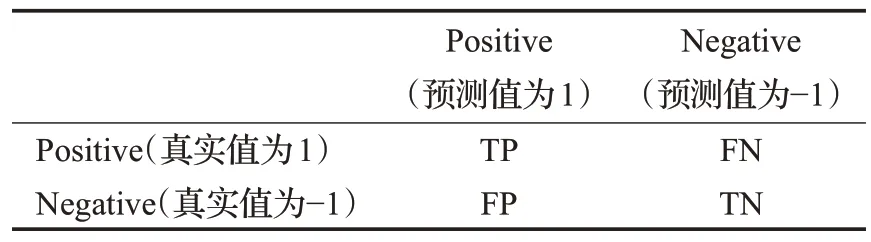
表2 混淆矩阵Table 2 Confusion matrix
3 实证研究
3.1 选股模型的构建
在模型ADASVM-CSLINEX中,由于有108个测试集,如果考虑过多的超参数并对其在训练集上进行交叉验证和网格搜索,会耗费大量时间,所以针对基分类器SVM 中的超参数,在单一的SVM 模型、AdaBoost-SVM 模型以及ADASVM-CSLINEX 模型中所涉及到的关于SVM 的超参数均取默认值。对AdaBoost 框架中的迭代次数U 进行网格搜索,综合考虑模型的预测效果与运行速度,选取U为20。各模型试验结果见表3和表4。
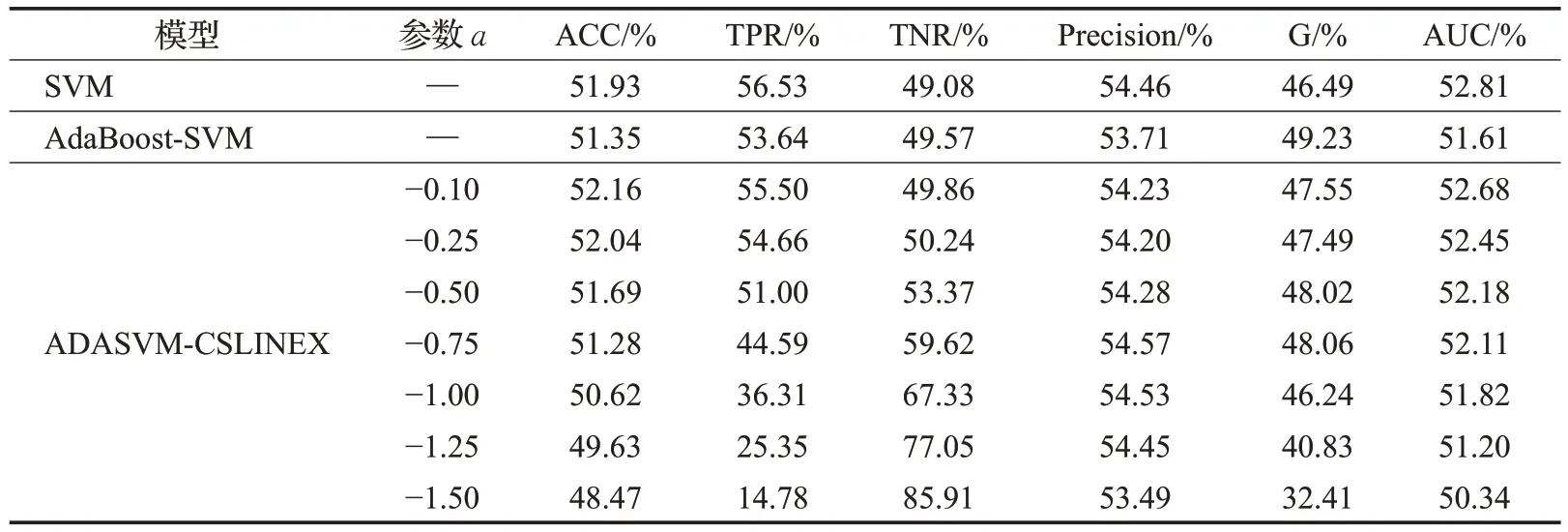
表3 各模型混淆矩阵结果Table 3 Confusion matrix results of each model
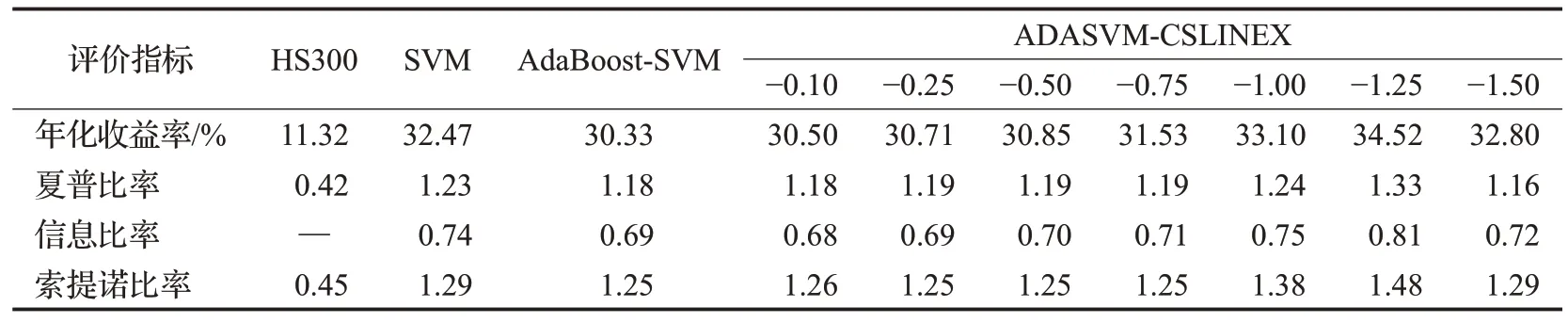
表4 各模型投资绩效表现Table 4 Investment performance of each model
由表3可知,就不同参数a下的ADASVM-CSLINEX模型而言,由于模型对y=-1 的样本进行指数级惩罚,对y=1 的样本进行线性级惩罚,从而使模型对负例样本预测准确率增加,所以模型的TNR值会变大,并且随着a的绝对值的增加,惩罚力度越来越大,模型的TNR值也越来越大,由于TNR 的增加是以TPR 的减小为代价,所以模型的TPR越来越小,TPR和TNR的差值也就越来越大。但一味地提高负类样本的准确率会导致正类样本的准确率变得很小,从而使整个模型失去预测作用。当a取−1.5,此时的TPR 为14.78%,若a继续取更小的值(如−1.75),经计算其TPR为个位数,模型已经失去预测的意义,所以这里a只取到−1.5。从表3 可以看出,在a从−0.1 到−1.5 的变化过程中,模型的TPR 在逐渐减小,TNR 在逐渐增加,ACC 有轻微降低的趋势、Precision、AUC基本无太大变化,由于TPR和TNR在反向变动,当两者的取值越接近,G值越大,所以G值经历了先增后减的过程。
与SVM、AdaBoost-SVM相比,ADASVM-CSLINEX在几乎相同水平的ACC、Precision、AUC值下,可以通过改变参数a的大小对负类样本进行不同程度的惩罚,从而使模型更关注负类样本的预测准确率,这是SVM、AdaBoost-SVM所不能实现的。
3.2 选股模型绩效评估
本文分别对SVM、AdaBoost-SVM、ADASVMCSLINEX三种模型在股票市场上的量化投资能力进行实证检验。本文的交易策略为:月初买入预测上涨的股票,卖出预测下跌的股票,对于本月预测为涨的股票,每次每种股票只买入一股,若下月持续上涨,则继续持有;若下月预测为跌,则将其卖出,以收盘价作为买卖价格,按月进行调仓,不考虑交易费用。股票的涨跌信号根据模型对各个月份的预测值来确定。表4 展示了从2012年1月至2020年12月,基于三种机器学习算法构建的投资组合策略绩效与基准(买入并持有HS300 指数)的对比结果。无风险利率为一年期银行定期存款利率1.5%。
从表4可以看出,三种机器学习模型的年化收益率、夏普比率、信息比率、索提诺比率均高于基准。随着a的绝对值的增加,ADASVM-CSLINEX模型的四种评价指标均经历了先增加后减小的过程,a为−1.25 时模型的投资表现最好。当a的绝对值较小时,其部分指标不如SVM、AdaBoost-SVM,随着a的绝对值的增加,模型表现得越来越好,当a为−1.5 时,模型的各项指标有轻微下降的趋势,这也呼应了前文所提到的不能一味地提高负类样本的准确率而不关注正类样本的准确率,从而使模型的性能变差。总的来说,相较于SVM、AdaBoost-SVM,选择合适的a值会使ADASVM-CSLINEX 模型获得较好的投资绩效。在实际操作中,可以进一步利用网格搜索算法在训练集上对a进行最优值的搜索,将AUC的均值最大作为评价标准来选择最优模型。
图4展示了ADASVM-CSLINEX(a=−1.25)、SVM、AdaBoost-SVM以及买入并持有策略的累计收益率随时间变化的曲线图,从图中可以看出所有机器学习算法的累计收益率均高于买入并持有策略,ADASVM-CSLINEX算法最高,SVM 算法次之,两者均高于AdaBoost-SVM算法。总体来看,ADASVM-CSLINEX算法可以通过对负类样本的错分代价进行控制,从而在一定程度上减少亏损和增加收益,保证策略取得稳定的收益。
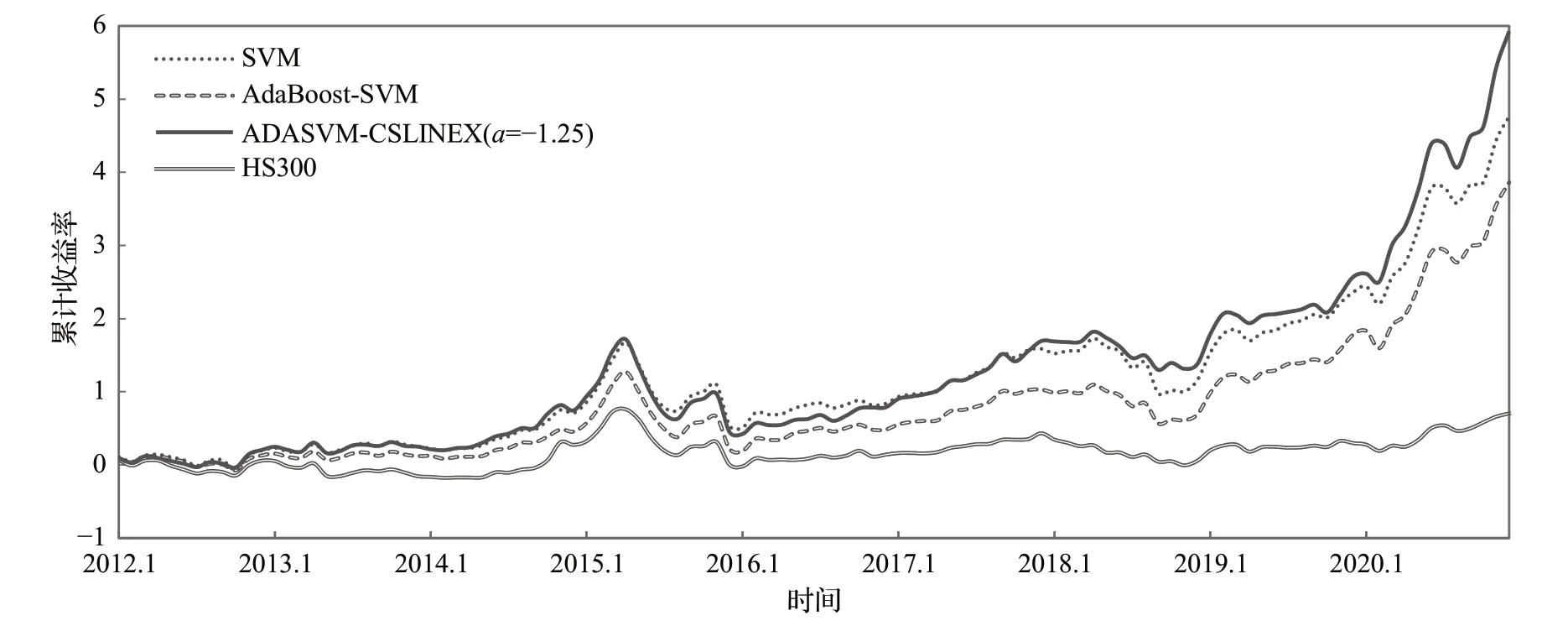
图4 各算法累计收益率曲线图Fig.4 Cumulative yield curve plot for each algorithm
4 结束语
当前对量化选股的研究很少考虑到股票预测中两类错误的问题,本文通过将LINEX 损失函数引入AdaBoost-SVM 集成算法的权重更新方程中,构建考虑错分代价的ADASVM-CSLINEX 股票预测模型。利用Lasso-Logistic模型动态的筛选因子,将其作为选股模型的输入变量。通过对比SVM、AdaBoost-SVM算法在沪深300 指数成分股涨跌预测中的实证结果,发现可以通过改变a值的大小控制对负类样本的惩罚力度。根据模型涨跌信号构建投资组合,结果发现ADASVMCSLINEX 模型在收益能力以及综合能力方面表现更优。本文得出以下结论:第一,通过将LINEX损失函数引入AdaBoost-SVM 中可以实现对错误分类的负类样本进行指数级惩罚而对错误分类的正类样本进行线性级惩罚,从而解决不同类样本间的错分代价问题。第二,恰当地选择a值会使根据ADASVM-CSLINEX选股模型构建的投资策略获得更高的投资绩效。
本文的创新点是通过将具有非对称的LINEX损失函数引入AdaBoost框架,提出了一种ADASVM-CSLINEX算法来解决股票预测中的错分代价问题。在本文中,由于负类样本的错分代价大于正类样本,通过令a为负值实现了对负类样本更大的惩罚;若在其他问题中,正类样本的错分代价大于负类样本,则令a为正值就可以实现对正类样本更大的惩罚;并且当a的绝对值越大时,算法对样本的惩罚力度也越大。总的来说,该算法操作简便,仅通过控制参数a的大小和正负就可以实现对不同类样本不同力度的惩罚;该算法应用广泛,不仅对诸如疾病诊断、垃圾邮件过滤、信用评级等错分代价不平衡问题具有良好的分类效果,还可以用来解决不同类样本数量不平衡问题,由于少数类样本更难被准确分类,通过赋予少数类样本更大的惩罚,从而提高少数类样本在总体中的重要性,可以使该类问题得到有效解决。
猜你喜欢
当代陕西(2020年17期)2020-10-28
人大建设(2018年5期)2018-08-16
电子测试(2018年1期)2018-04-18
海峡姐妹(2017年12期)2018-01-31
电信科学(2017年6期)2017-07-01
作文与考试·初中版(2017年12期)2017-04-19
光学精密工程(2016年4期)2016-11-07
光学精密工程(2016年3期)2016-11-07
中学生(2015年12期)2015-03-01
电测与仪表(2014年15期)2014-04-04
