
基于深度注意力的融合全局和语义特征的图像描述模型*
2024-03-14 08:37及昕浩彭玉青
网络安全与数据管理 2024年2期
及昕浩,彭玉青
(河北工业大学 人工智能与数据科学学院,天津 300401)
0 引言
图像描述[1-2]是一种使用自然语言描述图像内容的任务,是一项涉及计算机视觉领域和自然语言处理领域的跨领域研究内容。目前大多数方法使用卷积神经网络(Convolutional Neural Network,CNN)编码图像以提取图像特征,然后使用Transformer网络结构来解析图像特征并生成描述语句。Pan等人[3]提出了X-Linear注意力块来捕获单或多模态之间的二阶相互作用,并将其集成到Transformer编码器和解码器中。Cornia等人[4]在Transformer编码器和解码器中设计了类似网格的连接,以利用编码器的低级和高级特征。多数研究者针对Transformer网络结构进行改进,没有关注CNN提取到的图像特征其对应的感受野是均匀的网格,难以明显地关注图像中对象内容信息的问题。此外Transformer模型中的注意力机制仅仅是隐式地计算单个区域和其他区域的相似性,无法捕捉长距离的关系。
为了解决以上问题,本文提出了融合全局和语义特征的图像描述模型。该模型构建语义信息提取器,用语义信息来表示图像中关键的对象内容。同时提出多元特征融合模块,结合全局和语义特征来更加准确地表示图像内容。此外,设计一种新的深度注意力机制来加强注意力机制的计算,增强图像特征与文本特征的交互,提高描述语句的准确性。
1 相关工作
基于深度学习的图像描述方法是研究的重要方向,这类方法主要经历了两个阶段。第一阶段采用编码器-解码器框架,使用CNN作为编码器,从图像中提取固定大小的网格特征来表示视觉信息,然后使用RNN或者LSTM作为解码器解析图像特征并生成描述语句。Anderson等[5]在此框架基础上利用目标检测技术从图像中提取实体目标来表示图像内容。第二阶段,由于Transformer在自然语言处理领域取得显著突破,研究者们将Transformer引入图像领域,许多基于Transformer改进的模型在图像描述效果上也有显著提升。Cornia[4]等人提出在图像编码阶段加入记忆向量,编码层和解码层以网状连接来利用低级和高级特征,显著提升了图像描述的效果。Guo等人[6]通过使用几何信息来增强区域级特征,然后将这些特征输入到Transformer模型中,取得了不错的结果。Li等人[7]利用图像场景图实现图像描述。从这些研究的成果来看,如何提取几何特征,如何加入更多形式的图像特征来更加准确地表示图像内容,使得模型更好地理解图像,进而生成更加准确而自然的描述语句,是一个值得深入研究的方向。
受文献[7]的工作启发,本文模型在场景图的基础上进一步提取语义信息并结合全图特征进行图像描述。具体工作如下:
(1)提出语义提取模块,对场景信息进行编码;
(2)提出多元特征融合模块,将全局特征和语义特征进行融合;
(3)提出深度自注意力机制,使图像特征和文本特征更好地交互。
2 总体框架
本文提出的模型分为两个部分:图像特征提取部分和预测描述语句生成部分。图1为该模型的结构图。在图像特征提取部分,图片经过ResNet101[8]网络获得全局特征,经过Faster R-CNN[9]检测得到图像中的对象、属性以及对象之间的关系信息,并经过语义信息提取模块进行语义提取,获得更高级的语义信息,全局特征和图像的语义信息经过多特征融合模块,输入到预测描述语句生成部分。在描述语句生成部分,图像特征经过编码器处理,编码后的图像特征和文本特征在基于深度注意力的解码器中进行交互,生成预测的描述语句。

图1 融合全局和语义特征的图像描述模型结构图
2.1 语义信息提取模块
为了解决传统CNN编码器在识别图像特征方面的局限性,本文加入对象信息来使模型关注图像中更为重要的区域。对象信息包括对象区域在图像中的位置、对象之间的关系等信息。经过研究分析,本文认为Faster R-CNN得到的对象信息只是低阶的对象信息特征,相较于经过ResNet 101网络提取的图像特征比较浅显,与图像特征并不在一个维度空间中,需要对对象和位置信息进行处理。因此本文提出语义信息提取模块,将较为浅显的对象信息——对象及对象之间的几何关系重新进行编码,学习各对象节点的上下文感知嵌入向量,提取出更丰富的高级语义信息,使对象信息映射到与全图特征一样的空间维度,如图2所示。

图2 语义特征提取模块结构图
给定一张图片,本文方法使用Faster R-CNN提取到图像的对象特征O={O1,O2,…,Oi}、对象属性A={a1,a2,…,am}和对象位置信息Oi=(xi,yi,wi,hi),对象之间的几何关系特征由式(1)计算获得:
(1)
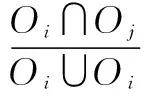

(2)
(3)
(4)
(5)
式中,φO、φA、φR是嵌入层,具体为Linear-FC-ReLU-Dropout层,[·,·]表示拼接操作,f(·)表示FC-ReLU-Dropout操作。
2.2 多元特征融合模块
对于整张图像来说,使用卷积神经网络可以提取到图像的全局信息和各种对象,获得较为准确的背景信息,而使用Faster R-CNN和语义信息提取模块对图像进行语义特征提取,可以得到更具体、更准确的对象内容和空间信息。基于此,本文在使用卷积神经网络对图像编码的基础上加入语义特征,提出一种结合全局信息和包含关键对象内容的语义特征的多特征融合模块,该模块负责融合图像的全局特征和语义特征,如图3所示。

图3 多元特征融合模块结构图
本文以与文献[8]中相同的方式提取图像的全局特征,用F表示。提取到的语义特征用G表示。为了能够获取准确的背景信息和局部的对象语义信息,全局特征和语义特征经过不同的卷积操作映射到统一空间维度,相加操作后得到特征H=(h1,h2,…,hm),以供图像特征选择全局信息和语义信息。为了更加充分地利用全局特征和语义特征,本文使用卷积操作对特征H进行处理得到特征S,使得全局特征和语义特征进行交互,可以有效地捕获全局上下文关系。为了实现对全局信息和语义信息的选取,特征S经过不同的卷积操作得到向量A和向量B,之后A与B进行Softmax操作分别得到全局特征的权重a和语义特征的权重b,最后经过卷积操作处理之后的全局特征和语义特征分别乘以对应的权重再相加得到多特征融合模块的输出,即表示图像内容的视觉特征V,具体过程如下:
H=fF(F)+fG(G)
(6)
S=Conv(H)
(7)
(8)
(9)
V=a·fF(F)+b·fG(G)
(10)
其中,fF和fG分别是对全局特征和语义特征进行卷积操作,fA和fB是对特征S进行不同的卷积操作。
为了更好地拟合特征,在得到视觉特征V之后,还要经过自注意力层、前反馈层和归一化处理,得到最终的图像特征X。
2.3 基于深度注意力的解码器
传统的注意力机制在图像文本交互时,需要对整个图像特征图进行注意力权重的计算,因此无法捕捉长距离的关系,基于此,本文提出基于深度注意力的解码器,如图4所示。

图4 基于深度注意力的解码器
为了缓解无法捕捉长距离关系的问题,首先对图像特征X先进行一次线性操作得到K,长距离的特征之间可以相互获得关系信息。文本特征T经过掩码自注意力和线性操作得到Q。之后图像特征K与文本特征Q进行点积操作,此时图像特征与文本特征进行了对齐,得到图像特征的注意力值,与文本相对应的图像区域注意力值越高,与文本不相关的图像特征注意力值就越低,最后注意力值与图像特征V进行相乘,此时注意力值高对应的图像区域就是图像中最主要的信息,可以进而生成更加准确的描述语句。注意力的计算公式如下:
(11)
式中,Q是文本特征,K和X都是图像特征,Q,K和X在同一维度,d是其维度。
图像特征与文本特征交互之后经过Softmax操作,全连接层和前反馈层得到最终的描述语句。
3 实验与分析
3.1 数据集和评价指标
本文设计的模型使用Microsoft COCO数据集进行训练,该数据集有123 287张图片,每张图片有对应的5句英文描述,在实验过程中,使用Karpathy方法对数据集进行划分。在文本处理阶段,将训练集中对应的描述语句单词均转化为小写形式,在建立单词库时,用特殊字符“UNK”来标记替换词库中出现次数少于等于5的单词。在验证和测试阶段生成描述语句时,设置预测描述语句最多生成16个单词。
本文采用在图像描述工作中被广泛应用的BLEU、ROUGE、METEOR和CIDEr评估指标来评估生成语句的质量。
3.2 实验结果与分析
3.2.1 消融实验
为验证本文提出的语义提取模块、多特征融合模块以及使用深度注意力机制对模型的影响程度,设置4组消融实验进行分析,表1展示了消融实验结果。其中Base表示基线模型,是本文所实现的M2-Transformer模型。DA表示使用基于深度注意力机制的解码器来对齐视觉和文本特征并生成描述语句的模型。Sem表示在M2-Transformer模型的基础上加入使用语义提取模块所提取到的语义特征,全局特征和语义特征相加来表示图像特征的图像描述模型。Sem-Fus是加入语义特征之后,使用融合模块来将全局特征和语义特征进行融合操作来表示图像特征然后输入到M2-Transformer模型中。Final为本文最终的模型。
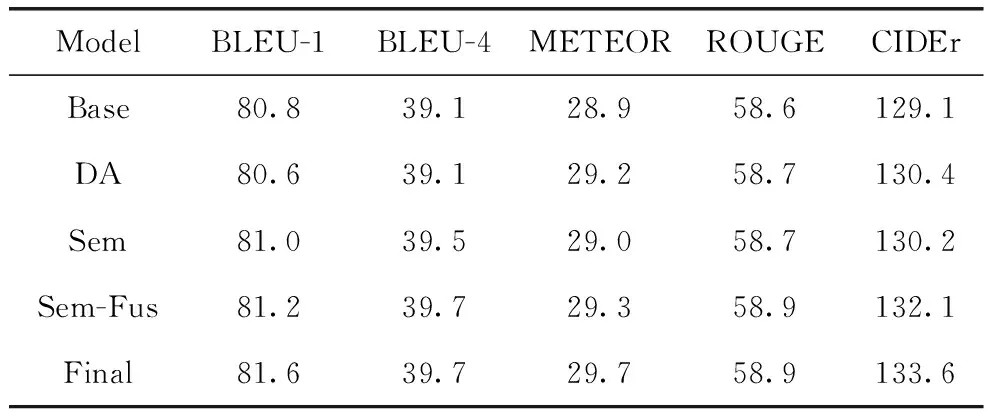
表1 消融实验结果
由表1可见,本文所提的模型相比于其他模型达到最佳,说明所提方法是有效的。具体来说,DA相较于基线模型在METEOR、ROUGE和CIDEr分数上有了显著提升,说明基于深度注意力的解码器能更好地对齐图像和文本特征,生成更加准确的描述语句。加入语义特征的Sem模型在BLEU分数上明显高于基线模型,说明生成的描述语句与标签的N元数组个数明显增多,生成单词的准确率提高。在加入语义特征的基础上,使用多特征融合模块的Sem-Fus模型比只加入语义特征的Sem模型在分数上有了明显的提升,可以说明多特征融合模块可以很好地融合全局特征与语义特征,使得模型可以更加准确地建模背景信息和图像中关键的对象内容信息。
3.2.2 验证语义提取模块有效性
为了验证语义提取模块的有效性,设置了两组对比实验,如表2所示,第一组实验使用GCN网络对对象节点进行处理,可以感知上下文节点,从中提取语义信息;第二组就是本文的语义特征提取模块,在感知上下文节点的同时,进一步提取语义特征。

表2 语义提取模块的有效性验证
实验结果表明,语义特征提取模块能够更好地提取图像中的语义信息,更加准确地表示图像内容。
3.2.3 验证多元特征融合模块有效性
为了验证多元特征融合模块的有效性,本文在使用语义特征提取模块提取语义特征,并与全局特征进行融合的图像描述模型基础上,又做了一组实验,对语义特征和全局特征各添加了一个可学习的参数α1和α2(α1和α2经过Softmax化),实验结果表明,使用本文提出的多特征融合模块可以很好地将全局特征和语义特征进行融合,使得模型可以更加准确地建模背景信息和图像中关键的对象内容信息。实验结果如表3所示。
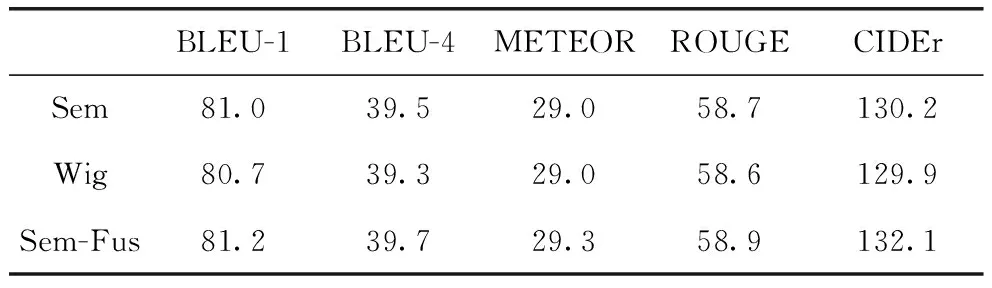
表3 多特征融合模块的有效性验证
3.2.4 对比实验
表4为本文方法与其他图像描述方法的比较,其中Up-Down[3]首先从预训练的对象检测器中提取区域特征,然后通过注意机制选择这些特征来生成描述语句;GCN-LSTM[10]和SGAE[11](Scene Graph Auto-Encoder)利用Graph CNN来捕获图像中的语义信息和关系信息,以提高描述语句的质量;ORT[12](Object Relation Transformer)对区域特征之间的空间关系进行建模;VSUA[5]使用图像语义和几何图,利用单词和不同类别的图节点对齐实现图像描述;M2[4](Meshed-Memory transformer)构造用于解码的网状连接网络结构;AST[13]使用自适应门控机制来调整视觉和语义信息之间的注意力。由表4可见,本文模型相比其他模型在各项指标上均达最优。

表4 与现有的方法比较
4 结论
本文分析了现有图像描述研究中的特征提取方法,根据全局特征和局部特征的优缺点,提出了多特征融合模块,该方法能有效地融合全局特征和语义特征。实验结果表明,经过语义提取模块的语义信息能够提高模型对图像内容的关注,同时深度注意力机制也能很好地对齐视觉与文本,生成更准确的描述语句。
猜你喜欢
数学物理学报(2022年4期)2022-08-22
数学物理学报(2022年2期)2022-04-26
小雪花·成长指南(2022年1期)2022-04-09
新世纪智能(语文备考)(2020年4期)2020-07-25
金桥(2018年4期)2018-09-26
传媒评论(2017年3期)2017-06-13
第二课堂(课外活动版)(2016年2期)2016-10-21
中国卫生(2014年5期)2014-11-10
语文知识(2014年4期)2014-02-28
小雪花·初中高分作文(2009年8期)2009-11-16
