
面向主从区块链的多级索引构建方法
2024-03-23 08:04王俊陆张桂月杜立宽陈廷伟
计算机研究与发展 2024年3期
王俊陆 张桂月 杜立宽 李 素 陈廷伟
(辽宁大学信息学院 沈阳 110036)
区块链通过块链式数据结构存储并验证数据,辅以密码学[1-2]方法保证数据传输和访问的安全性,具有高可信[3]、可回溯、去中心化[4]等特点,能够很好地解决数据存储对第三方的信任问题[5].随着区块链技术的发展以及各行业数据规模的累计,传统的单链结构区块链系统已经无法满足愈发复杂的领域应用场景,主从区块链(master-slave blockchain,MSBC)结构,如星火链、COSMOS 等,开始受到领域专家学者的关注,并逐步在教育、医疗、安全[6]等领域广泛应用[7-10].主从区块链通常包括主链和从属链2 部分,分别由主区块和从属区块组成,每个主区块有且只有一个从属链.各个主区块和从属区块之间分别通过前一个主区块和从属区块的哈希值相连,主区块与从属链通过唯一的哈希值进行映射.
主从区块链结构可以应对复杂分类场景的应用.如金融领域中,采用主从区块链构建面向金融活动的企业区块链系统,主链中存储金融企业属性信息,对应的从属链存储其交易事件、金融活动等数据,通过区块链的共识机制[11-12]保证数据不可篡改.
随着领域数据规模的不断增大,主从区块链系统存在的查询效率低、溯源时间长等问题[13-14]愈发严重.而现有区块链索引方法多只适用于单一链结构,且查询效率和索引构建时间均较差.因此,如何针对主从区块链建立高效、可动态维护的索引结构,成为领域研究的热点和难点.
针对上述问题,本文提出一种面向主从区块链的多级索引构建方法(multi-level index construction method for master-slave blockchain,MSMLI).主要贡献有4 个方面:
1)综合节点负载、节点信用和网络质量构建权重矩阵,提出一种基于权重矩阵的区块链分片算法(weighted matrix-based blockchain sharding algorithm,WMBS),基于主链特征实现主从区块链结构的动态分片;
2)在此基础上,针对现有区块链索引不适用于主从链结构的问题,提出基于跳跃一致性哈希的主链索引构建算法(master chain index construction algorithm based on jump consistent Hash,JHMI),通过主链的节点关键值与索引槽位映射,实现主链信息的高效查询;
3)结合区块链的数据特点,提出基于改进布隆过滤器的从属链索引构建算法(construction algorithm for subordinate chain indexes based on improved Bloom filters,IBF),优化基于列的选择函数,并给出索引查询方法;
4)在不同约束条件和数据集上与现有方法进行对比实验,验证本文所提方法的有效性.
1 相关工作
目前,许多学者对于区块链的索引构建问题进行了深入研究,取得了一定研究成果.
文献[15]提出一种多维内存读取优化的索引方法Flood,通过联合优化索引结构和数据存储布局,自动适应特定的数据集和工作负载.但是该方法无法检测到查询分布何时发生了足够大的变化,需要定期评估当前布局的查询成本对不同的工作负载完全重建索引.文献[16] 提出一种基于B 级树的索引方法EBTree,支持对以太坊区块链数据的实时top-k、范围、等价搜索,但是该方法的索引节点均在Level DB 中单独存储,且查询效率受节点大小影响较大.文献[17] 提出一种单通道学习索引RS(radix spline)方法,可以在排序数据的单次传递中构建,且只需要2 个数据集,对大多数数据集友好,但是该方法会随着数据集的增长降低性能.文献[18]提出一种基于子链账户交易链的索引方法SCATC,将交易链划分为子链并在每个子链的最后一个区块的账户分支节点上添加哈希指针连接每个子链,通过指针将遍历交易链的查询模式转化为子链查询来减少计算开销,但是该方法仅对较长账户交易链的查询效率有所改善且只针对明文状态下的查询优化,无法保证数据隐私性.文献[19]提出一种用于大时间序列数据的可扩展分布式索引方法ChainLink,设计了一个2 层分布式索引结构,使用单通道签名对数据进行散列,利用分区级数据重组来实现查询操作,但是该方法需要在本地对数据重组,无法保障数据安全性.文献[20]提出一种基于中间层的可扩展学习索引模型Dabble,使用K-means 聚类算法,根据数据分布将数据集划分为K个区域并分别使用神经网络学习和训练,通过神经网络模型预测数据位置,但是该方法在数据集更新时需要重新训练模型,时效性较差,并且K值对模型的准确性影响较大.
2 基于主从结构的区块链分片方法
为实现主从区块链结构的高效索引构建和查询处理,基于主链特征对整个主从区块链分片,并对各个分片赋予权重,据此构建整个主从区块链结构的分片权重矩阵;基于权重矩阵确定分片中的节点数目,为主链和从属区块链构建索引提供支撑.
2.1 权重矩阵构建
设主从区块链的节点数目为x,主从区块链分为y(y≪x)个分片,第i个分片为fi(i=0,1,…,y-1),各个分片权重为 ωi.分片权重由节点负载、节点信用、网络质量3 个维度的权重决定,其中节点信用和网络质量与分片权重呈正相关,节点负载与分片权重呈负相关,各项维度的权重由实验效果最佳的比例决定.在进行分片权重计算前,由于上述3 个维度的单位不统一,因此需进行归一化处理.节点负载的归一化公式为
节点信用和网络质量的归一化公式为
第i个分片的权重为 ωi,计算公式为
设2 维权重矩阵M的各个元素由分片权重组成,获得各个分片的权重后,使用各个分片权重 ωi构建2维权重矩阵Mp×q(其中p≤,q≤+1,p,q为整数).对于任意一个分片f,都有M[f/p][f%q]=ωf,矩阵中为空的元素置为0.
2.2 基于权重矩阵确定片内节点数目
基于2.1 节的权重矩阵,确定各个分片内的节点数目.首先,对矩阵中的分片权重进行线性归一化处理.其次,对归一化后的所有分片权重按照比例离散,设离散比例权重值区间为[1,Q].最终获得分片比例权重Q-1,即该分片将对应Q-1 个节点.
线性归一化后的分片权重的公式为
其中的ωmin为所有分片权重 ωi中的最小值,ωmax为最大值.
基于2.1 节的权重矩阵的构建过程,提出了一种基于权重矩阵的区块链分片算法WMBS,其通过跳跃搜索(jump search,JPS)算法快速进行区块链分片与节点的映射,实现了主从区块链结构的分片.WMBS 将节点关键值key、随机数r和权重矩阵作为输入,基于JPS 使节点与分片逐一映射.key在节点加入区块链时创立,为32 b 节点关键值,其由8 b 的分片地址码和24 b 的节点随机码组成,是节点的唯一标识;r是一个在[0,1]区间内均匀分布的随机数,由线性同余随机数发生器生成.WMBS 算法如算法1所示.
算法1.WMBS 算法.
算法2.JPS 算法.
3 多级索引构建方法
由于主从区块链结构的主链和从属链存储的数据规模和信息类型均不同,通过WMBS 算法分片后,本文提出一种面向主从区块链的多级索引构建方法(MSMLI),以满足主链和从属链的查询需求.多级索引构建示意图如图1 所示.

图1 多级索引构建示意图Fig.1 Multi-level index construction schematic
如图1 所示,在主链中,通过JHMI 建立1 级索引.在从属链中,引入IBF 建立2 级索引,2 级索引通过节点关键值进行关联.当查询发生时,首先在主链索引中检索节点关键值,得到查询结果后,基于该结果在从属链索引中通过节点关键值获得元素信息.
3.1 基于跳跃一致性哈希的主链索引构建
基于主链存储的数据特点,本文引入跳跃一致性哈希算法,提出JHMI,实现主链索引的快速构建.首先,根据各主链分片上的节点数量确定索引的槽位数量;其次,根据主链存储数据的哈希值确定各个节点关键值;最后,输入节点关键值和索引槽位数量,输出主链索引.
当分片中节点数量发生变化时,节点在索引中发生跳跃变化,部分节点重新映射.设产生跳跃变化的哈希映射函数为ch(key,num_buckets),key为节点关键值,num_buckets为槽位数量,可得:1)num_buckets= 1 时,只有1 个槽位,所有key都映射到1 个槽位中,即ch(key,num_buckets) = 0,所有节点都划分在0 号槽位;2)num_buckets= 2 时,有1/2 的节点在ch(key,num_buckets) = 0,有K/ 2 个key重新映射即ch(key,num_buckets) = 1,跳跃到1 号槽位;3)当槽位数从n变为n+1 时,有n/(n+1) 的节点所在的槽位保持不变,即ch(key,num_buckets) =n-1,有1/(n+1)个key需要重新映射,即ch(key,num_buckets) =n.
设b为节点上一次跳变的结果,j为发生跳变前最后一次槽位扩充时槽位的数量,当分片内节点数量发生变化时,节点重新映射的示意图如图2 所示.

图2 节点重新映射图Fig.2 Diagram of node remapping
由图2 可知,对于任意的i∈[b+1,j-1],增加节点数量且没有发生跳变的概率为
在[0,1]区间取一个均匀分布的随机数r,由式(5)可得,当r<(b+1)/r时,节点就会跳变成j,则i的上界为(b+1)/r.由于对任意的i都有j≥i,则j=floor((b+1)/r).JHMI 算法如算法3 所示.
算法3.JHMI 算法.
输入:节点关键值key,槽位数量num_buckets和空主链索引s;
3.2 基于改进布隆过滤器的从属链索引构建
从属链存储的数据具有规模大、多源异构的特点,因此,在从属链索引构建过程中,本文重构布隆过滤器数据结构,提出IBF 算法.
首先构建基于改进布隆过滤器的从属链索引的数据结构为2 维数组A[p][q],其中p=2n(n为正整数),q中的数据长度为lq,设lq=32/64 b,其取值由CPU 中通用寄存器的缓存行长度决定,以减少内存访问,提高查询性能.设改进布隆过滤器的K个哈希函数为Hash(key),其中,key为节点关键值,设一个改进布隆过滤器中可以存储的元素长度为len,则len计算结果为
在完成索引数据结构构建后,将所有位点初始化为0,对每个主区块对应的从属链构建索引,具体有3 个步骤:
1)使用选择列的函数,先将元素映射到对应列,该元素将在对应列的位点;
2)通过K个哈希运算函数获得位点;
3)将对应位点置为1.
其中,步骤1 中的列选择函数产生了额外的计算开销,为降低计算开销,将优化哈希函数,从属链上存储的交易哈希值是交易经过SHA256 哈希函数运算得到的,因此优化步骤1 的选择列函数为以SHA256 哈希函数为基础,通过取模运算得到选择列的函数.步骤1 中的选择列函数可表示为
步骤2 中的K个哈希函数由K个按位与运算组成,可表示为
式(7)中的v为布隆过滤器中的元素,qv为进行列选择后获得的列号.在获得元素所在列后,确定该元素在构建和查询时都将被限制在对应列.式(8)中为在获得列号后在该列中通过K次式(8)的运算获得的行号,即对应位点,k′为在通用布隆过滤器中的数组长度.基于改进布隆过滤器的从属链索引构建算法如算法4 所示.
算法4.IBF_Construction 算法.
输入:从属链元素集合V′,元素v,改进布隆过滤器数组长度k和通用布隆过滤器数组长度k′;
输出:元素位点p和选择列q.
在构建完从属链的索引后,提出一种根据从属链上节点关键值和选择列函数的基于改进布隆过滤器的从属链索引查询算法,如算法5 所示.
算法5.IBF_Query 算法.
输入:查询元素v,改进布隆过滤器中的元素V;
输出:判断结果.
4 实 验
本文实验环境为16 台4 TB 存储空间,128 GB RAM,16 核24 线程i9-12900KS CPU 的服务器集群,服务器之间通过高速局域网通信,每台服务器均部署Ubuntu 18.04 操作系统.实验采用2 个不同的数据集进行实验验证:数据集1 为公共以太坊网络中的前3 000 000 个区块,数据集1 中有15 362 853 笔交易;数据集2 为Lognormal 人工数据集,Lognormal 数据集按照对数正态分布,以均值为0、方差为2 的方式采样了500 万条不重复的数据.本节将从索引构建时间、查询时间、内存消耗3 个方面验证MSMLI 的高效性和低内存的优点.
4.1 分片权重比例选择
在分片准备阶段将通过服务器构建10 个分片,1 个服务器构建1 个节点并将节点分配到对应分片.分片中的节点容量设置为500 个节点.对比节点数目设为100,200,300,400 时,分片权重的3 个维度节点负载、节点信用、网络质量的比例分别设置为3∶3∶4,4∶3∶3,5∶2∶3 三种情况.实验结果如图3所示.
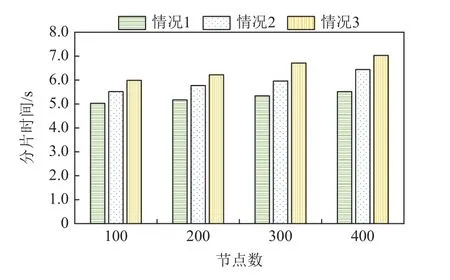
图3 分片权重比例Fig.3 Shard weight ratio
由图3 可知,在节点数量相同时,情况1 的实验效果最好,且随着节点负载维度的比例增大时,分片时间增加.随着节点数量的增多,情况2 和情况3 的时间明显增加,而情况1 的时间增幅不大,维持在5s左右.因此,本文将按照主区块链对区块链分片时节点负载、节点信用、网络质量的分片权重为3∶3∶4的比例进行.
4.2 索引构建时间对比
为在索引构建时间方面验证本文提出的MSMLI方法的高效性,将分别对比改进区块链结构的EBTree方法和引入神经网络的Dabble 模型方法.EBTree 方法中的内部节点的能力设置为128,叶节点的能力设置为 16.Dabble 模型中的K=100,MSMLI 方法的1 个分片中的节点数设置为100.在本节实验中,将分为3 种具体情况讨论.
如表1 所示,使用2 个不同规模的数据集将MSMLI 方法与EBTree,Dabble 这2 种方法进行索引构建时间对比.索引构建时间对比实验结果如图4、图5 所示.

Table 1 Index Construction Time Comparison表1 索引构建时间对比

图4 数据集1 上索引构建时间对比Fig.4 Index construction time comparison on dataset 1

图5 数据集2 上索引构建时间对比Fig.5 Index construction time comparison on dataset 2
由图4、图5 可知,随着数据量的增大,MSMLI方法与现有方法对比,在索引构建时间方面优化了约9.28%,其中Dabble 方法训练神经网络模型需要约15 s,因此,MSMLI 方法大大优于Dabble 方法.
4.3 查询时间对比
在本节实验中,首先将索引和数据加载进内存,为测试MSMLI 方法的查询性能,将使用不同规模数据集和查询条件对比查询响应时间.
4.3.1 大规模数据集查询响应时间对比
使用大规模数据集,数据集1 为公共以太坊网络中的前3 000 000 个区块.对比EBTree 方法和Dabble方法在主区块数目为50 万、100 万、150 万、200 万、250 万、300 万,从属区块数目为1 000 时的查询响应时间,实验结果如图6 所示.

图6 大规模数据集索引查询时间对比Fig.6 Index query time comparison of large-scale dataset
由图6 可知,在大规模数据集上MSMLI 方法与现有方法对比,在索引构建时间方面优化了约13.44%,区块数量增大时EBTree 方法优势更明显.
4.3.2 小规模数据集查询响应时间对比
使用小规模数据集,数据集2 为Lognormal 人工数据集,其中具有500 万条数据,总大小约24 MB.对比EBTree 方法和Dabble 方法在主区块存储10 万、20万、30 万、40 万、50 万条数据,以及从属区块存储1 000条数据时的查询响应时间,实验结果如图7 所示.
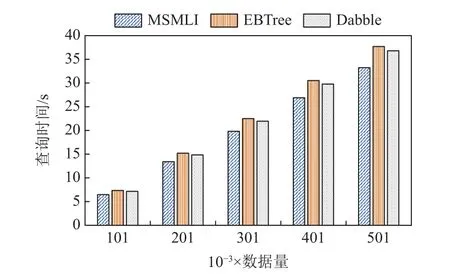
图7 小规模数据集索引查询时间对比Fig.7 Index query time comparison of small-scale dataset
由图7 可知,在小规模数据集上MSMLI 方法与现有方法对比,在查询时间方面优化了约10.71%.实验结果表明MSMLI 方法在数据量大时查询性能更好.
4.4 内存消耗对比
MSMLI 方法在分片阶段构建的权重矩阵几乎不占用内存,主链基于跳跃一致性哈希算法构建索引,跳跃一致性哈希对比经典的一致性哈希几乎没有额外内存消耗.因此MSMLI 方法中的内存开销主要考虑从属区块链的索引构建.IBF 的假阳性设置为0.013 7,lq=64b.EBTree 方法改写区块链结构,内存消耗主要为区块数据.MSMLI 方法与Dabble 方法的对比实验结果如表2 所示.

Table 2 Memory Consumption Comparison表2 内存消耗对比
由表2 可知,Lognormal 数据集占用内存24 MB;Dabble 方法占用内存4 KB;对于MSMLI 方法,IBF 在保证假阳性可允许范围内仍仅占用内存约2.048 KB,即使将IBF 与BF 在相同假阳性要求下仍能保持相同数量级.
5 结 论
随着区块链技术的广泛应用,传统单链结构已逐渐无法满足日益增长的领域数据存储需求,主从区块链开始广泛应用于金融、教育、安全等领域.针对现有主从区块链系统查询效率低、溯源时间长的问题,本文提出一种面向主从区块链的多级索引构建方法(MSMLI).该方法首先将整个主从区块链结构按照主链将结构进行分片,并采用权重矩阵提高分片可维护性,为索引构建提供支持;在此基础上,针对主链和从属链数据规模不同的特征,提出基于跳跃一致性哈希的索引构建方法(JHMI),以及基于改进布隆过滤器的从属链索引构建方法(IBF),提高主从区块链查询效率.实验结果表明,本文提出的MSMLI 方法对比现有方法,在构建时间、查询效率、内存占用方面具有很大优势,为主从区块链的快速检索提供了一条有效途径.
作者贡献声明:王俊陆提出了算法思路和实验方案;张桂月负责完成实验并撰写论文;杜立宽参与了审稿专家提出的关于查询实验部分的修改工作并补充了重要的参考文献;李素参与了审稿专家提出的关于文章具体内容上的修改工作,补充了文章框架和内容;陈廷伟提出指导意见并修改论文.
猜你喜欢
词学(2022年1期)2022-10-27
数学物理学报(2020年5期)2020-11-26
广东通信技术(2020年10期)2020-10-26
中国计算机报(2019年26期)2019-08-27
火控雷达技术(2018年4期)2019-01-15
制造技术与机床(2017年6期)2018-01-19
中学生数理化·高二版(2017年2期)2017-04-19
中学化学(2016年12期)2017-02-05
电测与仪表(2016年24期)2016-04-12
探测与控制学报(2015年4期)2015-12-15
