
英文普通人名汉译问题的模因学解读
2009-10-16 06:26路静任晓霏
疯狂英语·教师版 2009年4期
路 静 任晓霏
摘 要:英文普通人名汉译的混乱状况存在已久,一直得不到改善。本文从对“Levinson”和“Levenson”这两个英文人名多种汉译的定量分析入手,指出这是一种典型的模因现象,可以通过打造在保真度、多产性和长寿性三方面有突出表现的强势模因的方式实现人名汉译的统一化。
关键词:模因;模因学;英语普通人名;规范化
[中图分类号]H030
[文献标识码]A
[文章编号]1006-2831(2009)08-0097-6
Abstract: The Chinese transliteration of regular English person names has been in confusion for a long time and theres no sign of improvement. After a qualitative analysis of different translations for the two names of Levinson and Levenson, this paper tries to prove it is a typical phenomenon caused by memes, and suggests cultivating strong memes of striking fidelity, fecundity and longevity to standardize the name translation.
Key words: meme, memetics, regular English names, standardization
1. 引言
对外交流的增多需要对越来越多的外国人名,特别是英文人名进行翻译,然而我国当前人名汉译各自为政的现象十分严重,给学习、研究和查找带来了很多不便:语用学家S. C. Levinson是译成“利弗逊”、“莱文逊”、“莱文森”,还是“列文森”好呢?汉学家J. R. Levenson又该译成什么呢?针对上述问题,本文从模因的角度进行探讨,以期能对规范人名翻译起到推动作用。
本文首先对研究对象——普通人名的所指进行限定,之后简要介绍模因以及模因学,说明普通人名汉译可被看作模因现象,并以“Levinson”、“Levenson”两个英文名的多种汉译为例,指出英语人名翻译混乱的缘由,最后从模因的视角提出解决该问题的对策。
2. 普通人名的限定
英文人名的汉译可分为三种情况:一是文学艺术作品当中的人名汉译,二是非指称用法的英文人名(non-referential English names)汉译,三是本文要探讨的普通人名的汉译。
对于第一种情况,国内学界已有很多讨论,如许钧(1995:17-20)、张逵(2000:119-122)等,通常认为翻译时需考察文学艺术作品原作者的创作意图、时代背景、译入语文化等多方面因素,不能简单化处理。第二种非指称用法的英文人名汉译具有典型性特点。比如:“All shall be well, Jack shall have Jill.”(直译:一切都会好,杰克一定会找到基尔。意译:有情人终成眷属。)其中“Jack”和“Jill”是英语国家常见姓名,不具体指代某人,只是一个泛称,翻译时较容易处理。总体来讲,上述两种情况在人名翻译中所占比例很小,争议也相对较少,本文就不再分析。大多数的英语人名只是指代某人的一种符号,翻译时无需考虑命名的理据,本文将这类人名称作普通人名。人名汉译的混乱主要是普通人名汉译,因此本文将之限定为研究对象。目前国内对这类人名汉译的讨论多是采取大量列举一名多译实例、分类描述并提出改进方案的共时研究方式,如王金波(2003:62-64)、吕永进等(2004:372-383)。实际上,多种译名的产生也有其历史原因。本文将借助模因论的思想,结合共时和历时两种研究思路,探索当前译名混乱的问题。
3. 模因与英语普通人名汉译
模因是“meme”一词的汉译,是英国著名行为生态学家理查德·道金斯(Richard Dawkins)在《自私的基因》(《The Selfish Gene》)一书中创造的新词,原来还有拟子、幂姆、谜米等多种汉译形式,现在译法基本固定。道金斯将其界定为“文化传递的基本单位”,意在与生物进化的基本单位“基因(gene)相对应而较为方便地探讨人类文化进化的规律。20世纪末西方很多学者如理查德·布罗迪(Richard Brodie)、阿伦·林治(Aaron Lynch)、丹尼尔·丹尼特(Daniel Dennet)、苏珊·布莱克摩尔(Susan Blackmore)等都关注到了这一概念并将其丰富和发展,以解释宗教、哲学、心理学等方面问题,在西方学界掀起了模因学研究的热潮。国内的外语界也在本世纪初将其引入语言学领域,并在分析广告语、流行语等语言现象方面取得了可喜的成果(何自然,2005:54-64;王纯磊,2008:63-67)。
模因学(或模因论)的形成受益于达尔文的进化论,认为模因是与基因一样支持变异、选择和保持这一进化规则的复制因子,只是“基因是编码于DNA之中的生化信息,而谜米(模因)则是编码于人类大脑或诸如书籍、图画、桥梁、蒸汽火车等人工制品之中的文化信息。”(布莱克摩尔,2001:31)模因学强调基因能通过遗传得到较为准确的传递,而模因是依靠模仿得到复制传播。
英语人名进入汉语通常需要翻译,但翻译的结果却不尽相同,比如上文的“Levinson”就有诸多汉译形式,并且每种译法都有一定的受众复制模仿、传播使用。基于模因学的观点,“任何一个信息,只要它能够通过广义上称为‘模仿的过程而被‘复制,它 就 可 以 称 为 模 因。”(Blackmore, 1999: 66)因此,英文人名的每一种汉译形式都可以视为一种模因,可以从模因学这一崭新的角度进行分析。
4. 英语普通人名多种汉译模因并存的现状及症结
为了解“Levinson”、“Levenson”这两个英文名各种汉译模因的复制情况,笔者于2008年12月27日在谷歌(Google)和中国期刊网(CNKI)上进行了一系列检索。
首先只将两个英文名输入Google上搜索,发现有数十种译法,绝大多数译为“X文森”或“X文逊”;于是进一步限定,以“Levinson 文森”、“Levinson 文逊”和“Levenson 文森”、“Levenson 文逊”为检索词在Google上进行二次搜索,得到了“列文森”、“利文森”、“李文森”、“莱文森”、“里文逊”、“雷文逊”、“勒文逊”等近二十种汉译形式,多数来源于权威媒体。改换“英文+二次搜索的主要汉译形式”为检索词再次搜索以获取各汉译模因的具体复制量,分别统计得出表一:
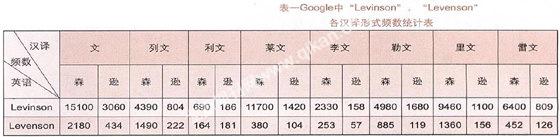
由表一可见,Google上对“Levinson”一姓最常见的翻译是“莱文森”,复制量超过万条,同时“里文森”、“雷文森”的汉译模因也在超过5000条数据中得到传播。对“Levenson”主要汉译模因的排序是:列文森>里文森>勒文森,各模因都在千条左右数据中复制传播。
同样,在CNKI上以“具体汉译形式+英文”(如“列文森Levinson”、“列文森 Levenson”)为检索词分别对各汉译模因的传播量进行全文精确跨库(中国期刊全文数据库、中国博士学位论文全文数据库、中国优秀硕士学位论文全文数据库、中国重要会议论文全文数据库)搜索,得出表二①、表三:
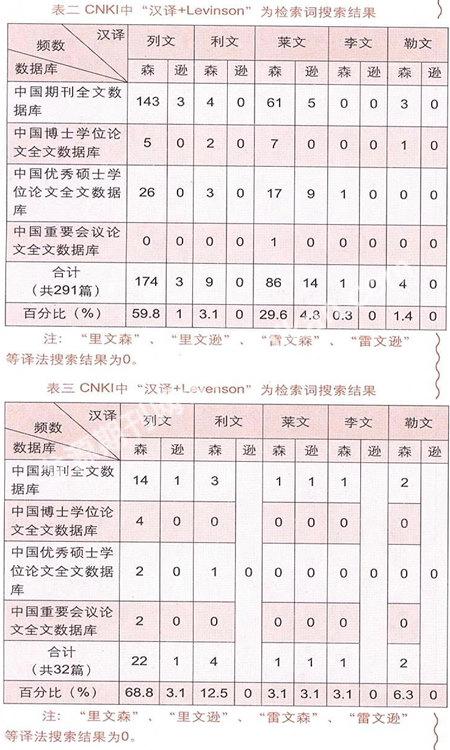
表二、表三说明,学界对“Levinson”最常见的汉译是“列文森”,占总数的59.8%,其次是“莱文森”,占29.6%。对“Levenson”这一姓氏最常见的汉译也是“列文森”,占68.8%,其次是“利文森”,仅占12.5%。学界对两者的汉译形式少于Google上搜索到的形式,但仍有多种译法并存。
从模因论的角度观察,语言模因的复制和传播有基因型的“内容相同形式各异”和表现型的“形式相同内容各异”两种方式(何自然,2005:58)。表一至表三统计的“Levinson”与“Levenson”多种汉译的情况显然属于基因型的模因。然而,如果是描述一些实意表达的传播,比如像理发馆、发廊、美发中心等随时代发展传播复制的同指异构的表述,基因型模因会丰富我们的词汇和文化,反映社会、人类意识的变迁,表现在人名的汉译中却只会引起指代的混乱。
实际上,英语人名各种汉译模因并存的局面与英汉两种语言的差异是分不开的。对比两种语言可知,英语属于拼音式的屈折语,汉语主要是以表意为主的词根语,截然不同的语言系统使得我国在引入西方人名时主要采用记录读音的音译法。据陈福康(2000),我国对他族人名进行翻译采用音译可追溯到春秋时期,之后的佛经翻译、科技翻译兴盛时期直至改革开放以来的当代社会,音译始终是外来语转换的主要手段。然而音译的实际操作十分复杂,卡特福德(Catford, J. C.)在《翻译的语言学理论》中提到确立音译体系的过程原则上包括以下三个步骤:(1)用源语音位单位代替源语字母,这是把书面媒介转变成口头媒介的标准的写作过程;(2)把源语的音位单位译成译语的音位单位;(3)把译语的音位单位变成译语字母或其他字形单位(1991:78)。此外卡特福德还在书中特别补充,对于汉语这类表意文字,音译除以上三步外还有一个转写过程。这样,英语人名汉译首先是要根据英语的发音规律确定人名的读音,再将其与汉语的音位对照(只能是大体对应,因为汉英语言的音位有一定差异),拼出之后还要转换成汉字。很明显,这里的每一步都需要一定的专业知识,转换中的任何一处出现差异都会带来不同的译法。再加上汉语是有声调的,各声调对应诸多汉字形式,即使前面各步操作相同,最后的译字也会出现差异。Francis Heylighen教授曾指出模因复制需经过同化(Assimilation)、记忆(Retention)、表达(Expression)、传播(Transmission)四个阶段,只有那些能引起受众注意,易于被理解接受的模因才能同化受体得到进一步记忆、表达和传播(1992: 77-84)。音译的观念历经一千多年历史早已成为一种强势模因植根于人们心中,但音译的具体操作由于上述的复杂性,并没有像音译概念本身那样同化译者而得到广泛的模仿,现实迫使人名汉译要参照更为便捷、通用的方式。
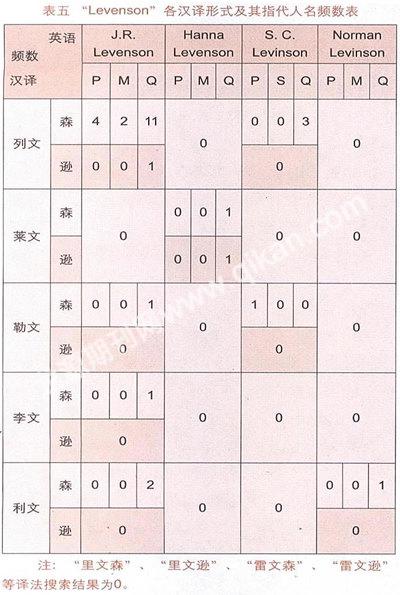
笔者对表二、表三搜索到的含“Levinson”、“Levenson”及其汉译的各篇文章作了进一步排查,并按各库文章出现的确切人名进行汇总,得出表四、表五:
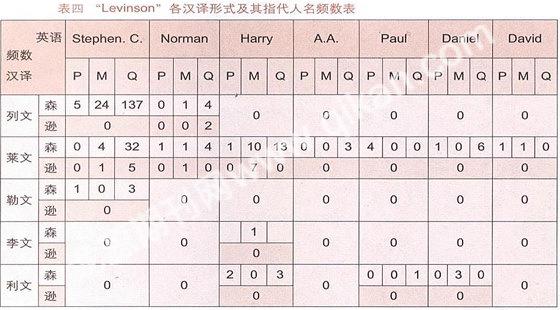
注 1. P代表博士论文;M代表优秀硕士论文;Q代表期刊和会议论文,下同。
2. “里文森”、“里文逊”、“雷文森”、“雷文逊”等译法搜索结果为0。
3. 其中“列文森”译法有2篇,“列文逊”译法有1篇。但都不确定具体指称,未计入表中。
表四表明,对于语言学家 Stephen C. Levinson的汉译有4种,最常见的汉译是“列文森”166篇,之后是“莱文森”36篇,“莱文逊”6篇和“勒文森”4篇;对于数学家Norman Levinson的姓氏汉译有4种:“列文森”、“列文逊”、“莱文森”和“莱文逊”,分别为5篇、2篇、6篇、1篇。对于心理学家Harry Levinson的汉译有4种:最常见的是“莱文森”24篇,之后是“莱文逊”7篇、“利文森”5篇、“李文森”1篇;对于地质学家A. A. Levinson、媒介哲学家Paul Levinson、研究成人教育等问题的心理学家Daniel Levinson以及交通规划和交通工程专家David Levinson的姓氏,在期刊网上汉译的样本较少,作了翻译的都倾向于“莱文森”的译法。
表五说明期刊网含有“Levenson”及其汉译的文章只涉及两个人物,一是美国著名汉学家J. R. Levenson,二是临床心理学者Hanna Levenson博士。对于前者,最常见汉译是“列文森”17篇,此外“利文森”2篇、“列文逊”1篇、“勒文森”1篇、“李文森”1篇;对于后者,只有两篇文章提到,一篇译为“莱文森”,一篇译成“莱文逊”。另外虽还有三篇文章译为“列文森”,一篇译为“利文森”,但谈论的却是S. C. Levinson和Norman Levinson,文中系将“Levinson”写为“Levenson”的笔误,故未计入在内。
分析表四、表五可知,对于同样的英文姓氏,不同领域、专业的译者有自己倾向的汉译。要查明某种汉译模因大量复制的缘由需要细化到具体人名汉译模因的历时传播过程。
以语言学家S. C. Levinson 的两种汉译情况为例,根据CNKI的数据和学校图书馆的相关书目搜索得出最早将其译为汉语的是《国外社会科学文摘》1984年09期题目为《语用学分析实例》的文章,该文直接署名“列文森、谢天蔚”。随后的1987年,何自然教授在相关文章中也使用了此译法。1993年开始,徐盛桓教授在诸多核心期刊上发表了一系列很有影响的古典格赖斯理论与新格赖斯语用机制的(S.C. Levinson是其中重要人物)评论性文章,采用的还是“列文森”的译法。此后,这一译法被稳步增长的文章所使用。1995年张惠民主编、世界图书出版公司出版的《语言逻辑辞典》中收录了“列文森”会话原则,而期刊网中“莱文森”的译法是直到1997年一次学术年会论文集中才首次出现的。
笔者对汉学家J. R. Levenson的名字进行了类似查找,发现期刊网最早使用“列文森”汉译的是1983年01期《国外社会科学文摘》中的文章,作者是美国戴维斯加州大学历史教授刘广京。图书中较早使用该译法的是同年中国现代文学研究丛刊中的一篇译作,之后这一译法被更多的人使用。1992年夏林根、于喜元主编的《中美关系辞典》和1993年张岱年主编的《孔子大辞典》都收录了“列文森”词条;图书中使用“勒文森”译法最有影响的是1986年刘伟译的Levenson所著《梁启超与中国近代思想》,近期论文中如出现该译法,多是在参考文献中引用了该书;“李文森”译法仅见于1998年柯文著陶飞亚译的《20世纪晚期中西之间的知识交流》一文;“利文森”译法仅见于1979年赫·杜毕尔和潘子立的《评<辩证法的幻想>》和1990年德利克、张广勇的《现代中国社会变革与历史》两篇译作,图书和辞典中未查到相关译法。
Blackmore在《模因机器》(The Meme Machine)中指出,模因得到复制传播可通过两种方式:对结果的复制(copy-the-product)和对指令信息的复制(copy-the-instructions)。将“S. C. Levinson”、“J. R. Levenson”大量译为“列文森”的情况说明人们对英语人名的汉译并没有参照译音表、译音规则等指令信息,而是对前人所译结果进行简单的复制。追溯中国网络发展史可知,互联网在中国正式落户是1994年,而中国期刊网(CNKI)是1999年才正式开通的,以往的学者在做研究的时候还是主要依赖图书、词典,期刊等纸质媒体,那些出现较早,来自权威学者、优秀杂志的译法自然易于引起人们注意和因袭,从而得到更大的复制量,形成一种强劲之势影响后来者。
同样体现人名汉译模因依赖对结果进行复制的还有表一至表五中Google和CNKI搜索到的大量“X文逊”形式的译例。著名学者刘宓庆在其著作《文体与翻译》中曾提到英语音译应注意一些问题,其中之一就是“英语发音应以国际音标(JlPA)为准,汉语发音应以标准汉语拼音为准。”(1998:127)“Levinson”、“Levinson”中的“son”如果按国际音标应读为/sEn/,按汉语普通话发音译成“森”,译成“逊”显然是在模仿对“Robinson(鲁滨逊)”、“Jefferson(杰弗逊)”等为人熟知的特定人物的翻译。
“易于被模仿的行为构成成功的谜米(模因),而难以被模仿的行为则否”(布莱克摩尔,2001:100)。翻译名字时,若仅对已有汉译结果进行模仿,易于记忆、易于生成的自然得到了大量的复制。但由于缺乏音译过程的规范环节,译名结果会在传播中因为一些人为因素而发生变化,形成多种变体。尤其是当今互联网大规模普及,网络文字、信息的随意性更为人名汉译模因变化开辟了土壤,Google统计的译法多于在CNKI上查到的就说明了这一点。
实际上,为方便音译的操作,我国国家语言文字部门和许多专家已做了一些规范工作。现已出版的针对人名翻译较重要的参考资料有新华社译名室编辑的《英语姓名译名手册》(以下简称手册,1984-2004年已修订四版)、在各语言手册基础上整理的《世界人名翻译大辞典》(2007)、外研社的《英语姓名辞典》(2001)以及针对上述资料查不到的、专名制定的、可借以转换的《英汉译音表》(以下简称译音表)。在上述资料中查找“Levinson”和“Levenson”的译法发现外研社的词典没收录该词条,《世界人名翻译大辞典》和四个版本的《手册》都将“Levinson”一姓译为“莱文森”,将“Levenson”一姓译为“利文森”。由此可见,如果广大译者参照这些资料的译名结果,译名应是统一的,而如今译名混乱的原因之一应是这些既成的规范资料并未被多数人熟知或不方便获取,人们还是习惯于对自己知道的译法进行简单复制。
5. 利用模因学知识推动姓名汉译统一化
从上文对“Levinson”、“Levenson”多种汉译形式的共时和历时分析可知,译者对现有译名参考资料了解不足,英语人名通过音译转换成汉字过程复杂使得人们在人名音译时不去推敲音译的过程,只是对他人译名结果进行简单复制,造成了译名的混乱。从严格意义上说,不同语言之间的译名并没有正确和错误之分,只有通用和非通用的译法。模因学认为每种模因在传播、进化过程中都要经历巨大的选择压力,只有极少数的模因会在竞争中保留下来,为更多人采纳、接受。英语人名的各种汉译作为模因也要经历这样的竞争过程,当某些汉译模因在激烈的竞争胜出时,译名结果就会趋向统一。因此,要改善英语人名汉译的混乱、规范译法,就需尝试打造在传播中可以从多种模因竞争中更早胜出的强势模因。
据道金斯(1976),强势模因应该是那些适应自己生存环境并且在保真度(fidelity)、多产性(fecundity)和长寿性(longevity)三方面都有突出表现的复制因子。因此,打造人名汉译的强化模因可尝试以下方法:
第一,加强特定人名汉译模因传播中的保真度。增加模因保真度有两个原则,第一个原则是从模拟系统向数字系统转换,第二个原则是从对结果的拷贝向对指令信息的拷贝的转换(布莱克摩尔,2001:388)。就原则一,可以请数字系统转换方面的专家同语言学家配合,将英语发音规律与英汉语音对照规律存入计算机并确立音译用字规范,由数字系统控制整个译名过程。如果这一方法得以实现,将有效排除复杂的音译转换过程的干扰,确保译名结果的统一。针对原则二,应该加强音译方法的普及。笔者查找图书馆内翻译类图书发现,翻译教材中提及人名翻译时多会简单提到“名从主人”、“约定俗成”、音译等观念,但很少有书中明确音译的具体操作。译者对音译的具体步骤不了解,很容易在译名时各自行事,也没有意识到译名是复杂又专业的工作,有必要参考权威机构根据译名过程制定的规范性资料。对此可以通过教师在翻译课程中专门讲授、图书资料中加强音译过程的举例介绍等方式改善这一局面。
第二,提高权威机构规范译名的多产性。目前英语人名普遍的一名多译现象足见译名问题还未引起人们普遍关注,现有的规范译名资料也未得到广泛的流通,需要在提高其多产性方面加大力度。职能机关应加大译名统一的宣传力度,编辑部门要加强文章人名音译的把关,同时也可以借助网络普及。相对于传统媒介,网络使用方便、获取信息迅速并能大范围传播,只是目前缺乏监管、随意性强。可以尝试由专业人员将英语姓名词典、手册中的人名修订补充存入数据库,由各专业的专家对本学科一些约定俗成的人名译法建立专业索引库,两库并用,旧名旧译,新名参照数据库进行查找,同时将其推广,使其成为同网络搜索引擎类似的一种专项在线译名工具,既能方便普通译者,又可规范译名结果。
第三,扩大保存通用译名的纸质工具和数字化工具的范围,确保通用译法的长寿性。目前规范化的人名汉译结果只能从上文提到的几种专业资料中找到,普通词典、书籍中很少收录,普通译者获悉这些资料的机会很少。可以通过在英语的主要教材中附录译音表或标注其他参考资料,在普通英汉辞典等常用工具书中给出主要姓氏列表等方式,扩大通用译名的收录范围、促进对通用译名结果的保存量,引发更多人对译名问题的关注,提高通用译名其自身的可记忆性。
总之,在英语普通人名汉译时一名多译的情况是典型的模因现象,通过培植在保真度、多产性和长寿性三方面达到最佳均衡的强势模因的方式可有效缓解当前译名的混乱现象,推动译名的统一。
参考文献
Blackmore, S. The Meme Machine[M]. Oxford: Oxford University Press, 1999: 66.
Dawkins, R. The Selfish Gene[M]. New York: OUP, 1976.
Heylighen, F. Selfish memes and the evolution of cooperation[J]. Journal of Ideas, 1992(2):77-84.
陈福康. 中国译学理论史稿(修订本)[M]. 上海:上海外语教育出版社,2000.
何自然. 语言中的模因[J]. 语言科学,2005(6):54-64.
卡特福德. 翻译的语言学理论[M]. 穆雷译. 北京:旅游教育出版社,1991:78.
刘宓庆. 文体与翻译[M]. 北京:中国对外翻译出版公司,1998:127.
吕永进. 郑承萍. 外国人名、地名翻译中的汉字应用问题[A]. 第三届全国语言文字应用学术研讨会论文集[C]. 2004:372-383.
苏珊·布莱克摩尔. 谜米机器[M]. 高申春,吴友军,许波译. 长春:吉林人民出版社,2001:31,100,388.
王纯磊. 模因研究评介[J]. 集美大学学报(哲学社会科学版),2008(3):63-67.
王金波. 谈国内翻译研究中的译名问题[J]. 中国翻译,2003(3):62-64.
许钧. 小说翻译中人名地名的处理[J]. 外语与翻译,1995(3):17-20.
张逵. 英汉文学作品人名的意蕴及翻译[J]. 山西师大学报(社会科学版),2000(1):119-122.
猜你喜欢
中国典型病例大全(2022年11期)2022-05-13
中国药学药品知识仓库(2022年7期)2022-05-10
中国典型病例大全(2022年13期)2022-05-10
中国典型病例大全(2022年9期)2022-04-19
医学概论(2021年18期)2021-01-21
校园英语·中旬(2016年8期)2016-07-09
教书育人·高教论坛(2014年7期)2014-08-27
教书育人·高教论坛(2014年1期)2014-02-26
新闻界(2009年4期)2009-09-30
教学与管理(理论版)(2009年8期)2009-09-23
