
基于点的代数连通强度与PCA的肿瘤分类研究
2015-11-17 10:23李安庆方国涛高振楠丁业兵
赤峰学院学报·自然科学版 2015年21期
李安庆,方国涛,高振楠,丁业兵
(安徽邮电职业学院,安徽 合肥 230031)
基于点的代数连通强度与PCA的肿瘤分类研究
李安庆,方国涛,高振楠,丁业兵
(安徽邮电职业学院,安徽合肥230031)
通过基因的表达水平来判别肿瘤的类别已成为后基因组时代的一个研究热点.针对肿瘤分类进行了相关研究,提出了一种新的分类方法.首先利用点的代数连通强度(the Algebraic Connectivity Strength of Point,ACSP)剔除受外界因素影响过大的基因数据并用修正的特征记分准则(Revised Feature Score Criterion,RFSC)判别进行计分排序,选取高计分的作为基因子集;接着运用主成分分析(the principal component analysis,PCA)提取主成分以消除基因间存在的相关性冗余信息,同时将基因子集映射到极低维的特征空间;最后利用支持向量机(the support vector machines,SVM)分类器进行分类.本文通过多个典型肿瘤基因数据集的实验,其结果验证了本文方法是有效的、可行的.
点的代数连通强度;特征记分准则;主成分分析;支持向量机
随着基因数据获取技术的进步,人类认识与分析肿瘤及其类型又有了新的途径和方法.针对传统肿瘤诊断与治疗的不足,如发现时间晚、治疗效果差等,于是人类不断探索新的途径.基于微阵列技术[1],使得同时大规模观察基因表达水平成为可能.如果能够从这些基因表达谱数据中挖掘出有用的信息,则对肿瘤医学起到巨大的推动作用.
至从1999年,文献[2]成功提出了以“信噪比”作为衡量基因类别信息量的一种手段进行区分急性白血病的2个亚型一来,面对“人类基因组”项目以后的产生的海量基因数据,如何挖掘出其中蕴含的有用信息是已经摆在广大学者面前的一道难题,针对基因表达谱数据样本少、维数高以及冗余信息多的特点,已有研究做了大量工作.Alizadeh等人在2000年利用聚类分析的方法发现了淋巴瘤的两种亚类型;在同时期,典型方法有人工神经网络法、贝叶斯法、SVM[2].由于理论知识的不断发展与计算能力的快速增强,挖掘基因表达谱数据的方法也得到了巨大进步.像Sigh D等人[3]基于前列腺癌数据集,结合了“Signal—Noise Ratio”和K近邻算法对其进行了识别分析;而文献[4]将稀疏非负矩阵分解方法引入到肿瘤领域中,对乳腺癌数据进行了双向聚类分析;阮晓钢等人提出了组合方法——CLUSTER_S2N的方法来分析肿瘤信息基因,并对急性白血病的类型进行了预测实验.然而,基于融合多种理论方法的肿瘤基因表达谱数据处理技术变得越来越流行,像信息熵概念与SVM结合的方法[6]对前列腺癌基因表达数据进行了有效识别.文献[7]融合了PCA与ICA方法去识别胃癌表达谱差异基因以促进结果的最终判别的准确度;文献[8]利用邻接矩阵分解基因表达谱数据,再运用PCA分析获取主分量的方法寻找结肠癌信息基因等.这些方法有效促进了基因数据挖掘研究的发展.
前期研究主要运用某种计分准则对每个基因含有的类别信息量进行衡量,选取排列靠前的、计分高的部分特征基因子作为后续处理的数据子集,但这些方法是基于类方差和类平均值的,因此易受污染的异常值影响,使之不能客观反映选取的基因的重要性,因此本文采用点的代数连通强度与PCA来对肿瘤基因进行识别和分类.首先利用ACSP方法剔除受外界因素影响过大的基因数据并用RFSC方法对剩下基因进行重要性计分,选取高计分的作为基因子集;接着运用PCA提取主成分以消除基因间存在的相关性冗余信息,同时将基因子集映射到极低维的特征空间;最后在SVM分类器上对三组典型数据集进行了分类实验.
1 点的代数连通强度
设有一完全图F,共有N个顶点,记V={v1,v2,…vN}为顶点集,其边集为E={eij|i,j∈{i,j∈1,2,…,N}},边eij被赋予相应权重wi,j,对其任意节点vi,计算与其相邻K个邻接节点的边权重之和,记Sum(vi)=则Sum(vi)记为vi点的代数连通强度(the Algebraic Connectivity Strength of Point,ACSP)[9].图中点的代数连通强度可以很好的反映图中某点与其他点的关联程度,所得到的信息可以反映图的基本特征信息.对于每一个基因gi,构建一个完全图,将该基因在同一类样本中的表达值作为图中的点,则gi对应一个点集:Valuei={value1i,value2i,…,valueNumi},其边权重定义如下:
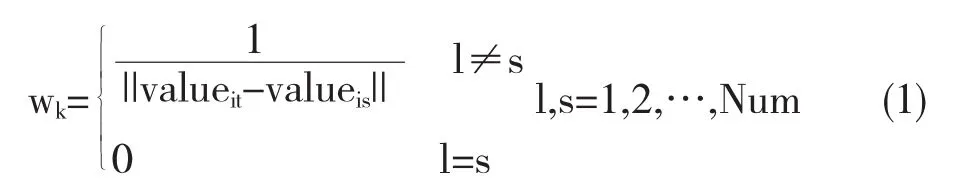
其中Num表示某一类的样本个数,当邻近点的数目K≈T×Num,这里T是一个参数且T∈[0,1].计算:
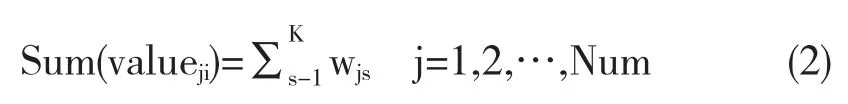
首先,确定最大值Sum(valueji)

然后将与Summax对应的valueji看做中心点.基因gi在同种类别中表达水平的均值和方差可以通过分析T×Num个相邻的valueji来获得(包括valueji).同样原理,基因在不同类别中表达水平的均值和方差也可以用相同方法得到.最后,基因gi利用修订的特征记分准则[14]进行计分.
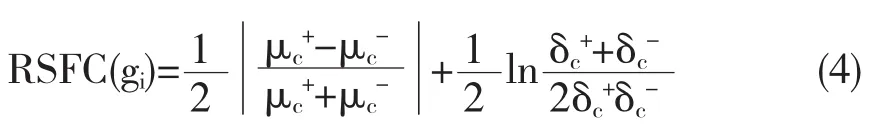
其中,RSFC(gi)值的大小反应了基因gi对样本数据集中“+”类和“-”类的辨别能力,μc+、μc-和δc+、δc-分别是“+”类和“-”类样本均值和方差.
2PCA
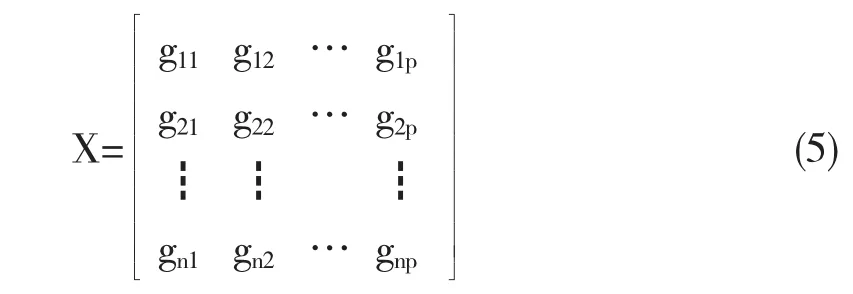
主成分分析(PCA),作为一种有效的线性数据压缩和降维的工具,其应用越来越广泛.其实质是确定原变量xj(j=1,2,…,p)在诸主成分zi(i=1,2,…,m)上的荷载lij,把原来多个变量划分为少数几个综合指标的一种统计分析方法.假定肿瘤样本经过上述ACSP和RFSC处理后维数降为p,即p个基因,则以样本为行,基因为列,构成一个n×p阶的数据矩阵X.现就PCA给出如下简要描述:
设g1,g2,…,gp为原变量指标,z1,z2,…,zm(m≤p)为新变量指标,满足式(6).

其中系数lij的确定原则为:1)zi与zj(i≠j;i,j=1,2,…,m)相互无关;2)z1是g1,g2,…,gp的一切线性组合中方差最大者;z2是与z1不相关的g1,g2,…,gp的所有线性组合中方差最大者;…;zm是与z1,z2,…,zm-1都不相关的g1,g2,…,gp的所有线性组合中方差最大者.则lij的计算为:
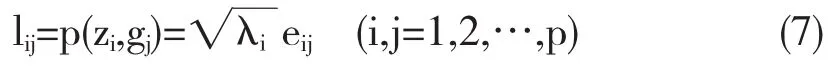
新变量指标z1,z2,…,zm分别称为原变量指标g1,g2,…,gp的第1,第2,…,第m主成分.一般取累计贡献率达80%以上的特征值为λ1,λ2,…,λm所对应的第1、第2、…、第m(m≤p)个主成分.
3 实验
3.1实验流程
实验数据为白血病、结肠癌和前列腺癌三组典型基因表达谱数据集,其中白血病数据包含52个样本——急性淋巴性白血病(ALL):24和急性粒性白血病(AML):28,每个样本含基因12564个;而结肠癌数据的正常样本数和癌症样本数分别为22个和40个,含2000个基因;前列腺癌数据共102个样本,其中有50个正常样本和52个癌症样本,含12600个基因(URL:http://www.broad.mit.edu/cgibin/caner/datasets.cgi).由于基因表达谱数据普遍为小样本数据,故本文基于留一法进行实验,即循环抽取所有样本的每一个作为测试样本,剩下样本作为训练样本进行实验.
综上所述,实验具体步骤如下:
1)利用ACSP(经多次试验,选取T=0.8),获取更加客观的基因表达水平;
2)在第1步的基础上,运用RFSC对所有基因进行重要性记分并按降序排列;
3)通过RFSC记分准则选取特征基因子集,基于PCA降维,对该子集进行主成分提取;
4)最后在三组公开的数据集上,利用SVM分类器对其进行了肿瘤类型与分析.
3.2实验结果与分析
首先以结肠癌为例进行了实验分析,通过ACSP使得结肠癌数据集中的正常样本类和癌症样本类中客观的基因表达值得到保留.图中显示了通过ACSP方法后利用RFSC算法获取最高分值的基因在所有样本中的表达水平(No.1168,即基因表达谱数据中列号,行表示样本,列表示基因),与之对比的没有经过ACSP处理的.

ACSP+RFSC获取的最高分基因(a)与RFSC选取的基因(b)
通过ACSP+RFSC算法获取的最高分基因No.1168,除了正常样本类和结肠癌样本类中几个异常表达之外,基本能够体现该基因在不同类中具有不同的表达值,且类间表达水平间距较大;而仅用RFSC获取的最高基因No.1439,其表达水平围绕归一化后的0值波动,类间表达值接近,表明该基因区别不同类的能力较差.因此本文方法能够更加客观地、有效地获取具有分类能力的基因.
4 结论
本文提出了结合点的代数连通强度和PCA的基因肿瘤识别方法,通过三组具有代表性数据集的实验本文方法能够有效识别不同肿瘤类型.由于PCA对噪声数据敏感,而ACSP方法能够获取更加客观的表达值并对噪声进行抑制,从而使得PCA降维更加有效,所以本文方法在识别过程中能够得到较高的识别率.
PCA降维属于线性降维,然而基因表达谱数据的高维性使之具有非线性特征,因此基于非线性降维与ACSP方法的结合也将值得进一步研究.
〔1〕杨春梅,万柏坤,梁慧嫒,等.DNA微阵列技术及其在生物医学中的应用[J].国外医学.生物医学工程分册,2002,25(5):203-206.
〔2〕王晶,周旷.基于支持向量机的肿瘤基因识别[J].计算机与数字工程,2011,9(39):3-6.
〔3〕Singh D,Febbo P G,Ross K,et al.Gene expression correlates of clinical prostate cancer behavior[J].Cancer Cell,2002,1(2):203-209.
〔4〕孔薇,王娟,牟晓阳.基于改进稀疏非负矩阵分解方法的乳腺癌微阵列表达数据分析[J].安徽医科大学学报,2013,48(7):725-729.
〔5〕阮晓钢,晁浩.肿瘤识别过程中特征基因的选取[J].控制工程,2007,14(4):373-380.
〔6〕庄振华,王年,李学俊,等.癌症基因表达数据的熵度量分类方法 [J].安徽大学学报,2010,34(2):73-76.
〔7〕陈战雷,李博宇,李益,等.结合主成分与独立成分分析识别胃癌相关差异表达基因的方法研究[J].生物医学工程学杂志,2013,30(5):915-918.
〔8〕陈乐,王年,苏亮亮,等.基于邻接谱主分量分析的肿瘤分类方法[J].安徽大学学报(自然科学版),2011,35(4):86-91.
〔9〕Wang N,Su L L,Tang J,et al.Informative gene selection using the Algebraic Connectivity Strength of Point and Scoring Criteria[J].Chinese Science Bulletin,2013,58(6):657-661.
〔10〕李颖新,阮晓钢,基于支持向量机的肿瘤分类特征基因选取[J].计算机研究与发展,2005,42(10):1796-1801.
TP18
A
1673-260X(2015)11-0032-03
安徽省高校优秀青年人才基金重点项目(2013SQRL121ZD)
猜你喜欢
车主之友(2022年4期)2022-08-27
逻辑学研究(2021年3期)2021-09-29
河北理科教学研究(2021年4期)2021-04-19
数学年刊A辑(中文版)(2021年4期)2021-02-12
科学(2020年1期)2020-08-24
海峡姐妹(2019年12期)2020-01-14
云南教育·中学教师(2019年5期)2019-08-13
电子制作(2019年9期)2019-05-30
火控雷达技术(2016年1期)2016-02-06
天津护理(2015年4期)2015-11-10
