
大数据时代背景下的现代语料库研制概览❋
2019-01-28 03:54卢植胡健广东外语外贸大学
外语与翻译 2018年4期
卢植 胡健 广东外语外贸大学
【提 要】大数据为语言研究带来了大量新型自然语料,但这些基于网络的非结构电子数据对于语料库研制而言既是机遇又是挑战。本文通过梳理语料库研制基本步骤,回顾现有研制软件和引介新技术工具,发现语料库研制当前呈现出三大趋势:研制工具上,单机软件转向网络应用;研制目的上,语料库研制与分析功能融合;研制应用上,语料库研制趋向大数据应用。
1.引言
伴随现代信息技术的更新迭代,数据数量越来越大,种类越来越多,复杂程度越来越高,“大数据”的概念应运而生。2001年分析师莱尼在《3-D数据管理》报告中首提“大数据”的3V特征,即数据即时处理的速度(Velocity)、数据格式的多样化(Variety)与数据量的规模(Volume)(Laney 2001)。麦肯锡(McKinsey)在报告《大数据:创新、竞争和生产力的下一个前沿》中将大数据定义为:数据规模超出常规数据库工具获取、存储、管理和分析能力的数据集(Manyika 2011)。
截至2011年,全球拥有互联网用户数已达到20亿;RFID标签在2005年的保有量仅有13亿,但是到2010年这个数字超过了300亿;2006年资本市场的数据比2003年增长了17.5倍;目前新浪微博上每天上传的微博数超过1亿条;Facebook每天处理10TB的数据(赵国栋、易欢欢、糜万军、鄂维南2013)。大量文本、图像、影像等数据的电子化和网络化,为单、多模态语料库的研制及相关应用提供了大量真实语料。然而,文本、图象、声音等作为非结构化数据,难以像在MS Excel中统计分析(王华树2016:3),人工复制粘贴无法应对海量语料以及社交媒体、电商信息、视频弹幕等新型网络自然语料等获取,因此语料库研制势必要求采用新的技术和工具应对语料的提取、加工等方面的挑战。
2.现代语料库概念及研制简述
语料一般指实际使用中真实出现过的语言材料。按字面意思,“语料库”(corpus)指存放语言材料的“仓库”。事实上,语料库不是伴随计算机出现而产生的现代概念。在计算机化以前,学者已经开始建立语料库,当时的语料库主要用于词汇索引、编撰词典、方言调查等,包括“为研究语法、编纂词典而采集的卡片引证库,为教学目的和编制词表而采集的书面文章库,以及为语言文化调查而采集的资料库”(王建新2005:21)。但早在中世纪,原始意义上的手工语料库出现得更早,甚至可以追溯到中世纪(杨惠中2002:46),从其在OED中的词典义变化:“身体——尸体——汇编,全集——(口语或书面语的)语料——语料库”(见王克非2012:8),可以看出人们对这一概念认识的变迁。其中,正是伴随计算机的迅猛发展,以计算机应用参与语料库研制为标志,语料库迈入计算机时代,进入现代语料库时期(邹煜2011)。
关于现代语料库的定义,中外学者(Sinclair 1991;McEnery&Wilson 1996;顾曰国 1998;Leech 2014等)的观点虽各有侧重,但具有一定共性,即现代意义的语料库是基于一定目的,以一定采集标准采集的具有一定规模和代表性的、可供机读的真实语料集合,而且语料库采集的是文本,而非词汇或孤立句子。
语料采集之所以需基于一定采集标准或代表性,这是由于真实语料难以穷尽和实际获取难度。如果分析某位作家的小说语言特色,理想状态下是采集到其所有小说文本(而非书信、杂谈等题材作品),进而再进行分析;但问题在于,每时每刻世界都在产生大量真实语料,很多类型或文体的真实语料并不是如同某位作家的小说可以穷尽,现实情况往往是无法穷尽,同时也涉及到语料版权和实际采集难度,所以语料的采集就需按照一定采集标准,进行取样;最后,采集的语料一般是电子文本,如非电子文本,则要转化为计算机可读的电子文本,因为现代语料库研究及应用一般需借助计算机手段。
综上所述,随着计算机技术和语料库研究的深入,语料库建设也在不断深化。就时间跨度而言,王克非(2012:9)将语料库发展分为三个阶段:原始语料库(18世纪-20世纪初)、现代语料库(1950s-80s)和当代语料库(1990s-)。就语料而言,语料库建设其发展历程基本经历从纸质(卡片)到电子文本,从文本、音频图像(静态或动态)再到视频,换言之,存储方式也从单模态发展到多模态。故Knight认为,语料库建设在经历了手工采集(语料库1.0)——初步经过计算机处理(语料库2.0)——大规模数据采集与加工(语料库3.0)后,伴随现代计算机多媒体技术的发展,以及人们对语言活动本质认识的提升(见黄立鹤2015:1),即语料库建设进入多模态采集,即“语料库4.0”阶段。
3.语料库研制基本步骤及趋势
语料库研制之前需要根据研究目的考虑建库设计。语料库对于语言研究的意义在于,“通过语料库,我们可观察到之前未意识到的或仅仅隐约觉察到的语言模式”(Johansson 2007:1)。这也就意味着语料的容量一般较大,并非凡针对零星语料的研究都需要基于“语料库”,导致“语料”与“语料库”混为一谈。其次,套入语料检索软件,空得数据,无法解释,有“语料库”之名,无语料库之实。语料库是语料库研究的起点和核心,正如Kennedy(1998:60)所言:“语料库设计和编辑问题直接关系到基于某一语料库研究的有效性和可靠性”。
3.1 语料库研制基本步骤
在确定研究目的和语料库研制可行性后,语料库创建一般涉及语料采集、转写降噪、分词标注、对齐等步骤。以下按照这些步骤大致回顾并引介相关技术工具,但值得一提的是,这些语料加工操作如采用软件或网络应用自动处理,还需人工核对调整,以保持语料库及后续研究的有效性和可靠性。
3.1.1 语料采集
语料采集传统上通过人工采集。除了人工转写输入外,纸质语料可在扫描或拍照后,通过ABBYY FineReader等本地软件、smallpdf.com等在线网站、或者手机和平板等移动端上的全能扫描王之类的应用(APP),进行光学字符识别(ORC)转换为电子文本。
对于网络文本语料,很多语料可直接复制粘贴为纯文本。对于某些无法直接复制文字的页面,比如图片格式页面或者该页面设置为不可复制,有如下几种方法应对:使用ABBYY Screenshot Reader等识别软件框选所需文本内容再剪切到Word或txt文件中即可;通过将所需页面的网页保存为“网页,全部”,得到一个文件夹和网页,再用word打开所保存的网页,此时即可编辑或保存;打开其网页源代码后复制相关内容,但会连带复制较多无关信息;对于某些失效网页语料,可打开其网页快照,通过网络服务器缓存,复制相关语料。
以上人工采集优点在于采集准确,但缺点在于耗时费力。伴随网络成为语言生活的重要组成部分,众多语言新现象借助网络媒体从线上传播到线下,比如社交网站信息和电商平台信息,包括食宿评价、购物反馈、书评影评等,从而成为重要的海量自然语言语料,因此大规模语料采集开始逐渐采用网络爬虫技术。网络爬虫(Web Crawler,又称网络蜘蛛、网络机器人)是一种请求网站并提取数据的自动化程序,其基本原理是爬虫程序从若干初始网页的统一资源定位符(URL)开始,获得初始网页上的URL,在获取网页文字、图片、影像等内容的过程中,不断从当前页面上抽取新的URL放入队列,直到满足系统的一定停止条件,从而实现数据批量采集。王朝晖、余军(2016:18)曾介绍火车头采集器、网络矿工等数据采集软件,并以后者对阿里巴巴茶类商品和iHerb网站omega类商品进行语料采集、整理,制作双语对应语料库,极大提高了语料采集效率。
多模态语料的获取可依靠影音软件缓存,或通过流媒体嗅探软件和视频录制工具下载和录制。伴随网络娱乐化和视频社交化趋势,一种新型的视频分享网站应运而生——弹幕网站。不同于传统视频网站,视频观看者可在观看的同时评论,即将评论即时叠加在视频上。由于评论数量之多,密集程度有时掩盖整个视频画面,犹如军事上连续射击掩护或齐射式进攻,因此这种不是字幕但又类似字幕的评论被称之为“弹幕”(见图1)。弹幕不只是评论,更成为视频内容的一部分,观众观看视频,有时就是为了发表和阅读弹幕。因此作为动漫游戏文化(ACG)语言的重要载体和形式,弹幕自然也是一种新型的网络自然语料。
图1 视频弹幕截图
3.1.2 转写与降噪
语料转写主要针对多模态语料库研制,比如口译语料库研制中需要将录音或视频中的语音转写文字。传统上研究者采用人工听写,该方法虽然准确,但耗时耗力。伴随语音识别和语音合成技术的发展,相关的语音转换软件和应用程序已经能够自动识别和转换,可以在一定程度上辅助人工转写。其中,搜狗输入法、讯飞输入法等不少输入法软件已经兼容语音输入功能。鉴于其以相对较高的准确性和速度自动支持普通话、广东话和英语输入,在此以讯飞输入法为例简述两台设备之间语料转写,即一台设备播放音、视频,另一台设备记录转写。比如在电脑上播放音、视频文件之时,保持手机“讯飞输入法”语音输入状态,此时该输入法自动识别并转化为文字,最后通过微信或QQ社交软件或蓝牙将手机中的转写稿传输至电脑,再通过文本编辑软件处理。然而,由于现场录制的语音语料存在背景噪音以及停顿、犹豫、重复、修正、笑声等副语言信息(胡开宝2011:179),故软件转写后语料还需人工核实加工。
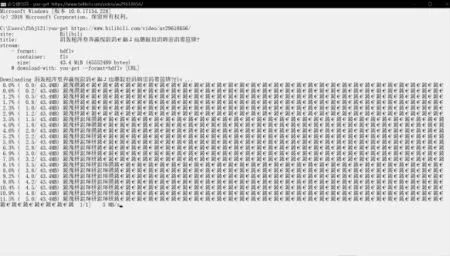
图2 命令提示符下You-Get安装与视频、弹幕下载
语料降噪是指消除语料中多余的字符或影响语料对齐的字符、公式、图表等,以提高语料库统计分析的效用(管新潮、陶友兰2017:20)。语料降噪常用软件包括 EditPlus3、EmEditor、Microsoft Word、文本整理器等。Microsoft Word通过通配符查找替换噪音标点或字符。另外,也可在Word录制宏或在通过国产文字编辑软件WPS通过自带宏处理“文字工具”,进行批量段落重排、删除多余空格或换行符等格式处理。
3.1.3 分词与标注
语料降噪整理后一般需语料分词和词性标注。所谓分词(tokenization)是指将一连串的字符转换成相互分离,容易识别的形符(token)的过程(梁茂成、李文中、许家金2011:45)。由于英文基本是以空格划分的单词为单位,其分词较为简便(即以空格划分),而中文字与字和词与词之间并没有明显的区分标记,而目前语料库软件基本都是针对西方拼音文字,因此首先需要分词处理,以便后续中文检索分析。对于英文分词,主要是删减单词之间多余空格或增加必要空格,可依靠Microsoft Word和WPS软件的拼写检查和替换以及录入宏,或者通过文本整理器进行处理。
外语研究中的分词处理主要应用张华平研制NLPIR汉语分词系统(又名ICTCLAS),实现便捷分词、词频统计、词性标注、关键词提取等操作,但该系统的单机版和网页演示版分别存在试用期限和单次处理字数上限(3000字)。事实上,分词与标注早也是自然语言处理(Natural Language Processing)的基础工作之一,因此大量NLP的工具或模块,比如jieba、THULAC、SnowNLP、pynlpir、CoreNLP、pyLTP中文分词模块,可为外语研究中语料库研制提供便利。不过,这些基于java、python等编程语言的分词工具模块一般没有用户视窗界面,需要输入代码进行操作,因此存在一定难度。不过,国内研究人员仍在不断开发本地单机语料处理软件,比如Laurence Anthony开发的SegmentAnt,可进行中文、英文、日文分词,内置jieba等分词及POS赋码引擎;北京外国语大学语料库语言学团队(FLERIC)研制的BFSU Stanford POS Tagger是斯坦福大学自动标注软件Stanford POS Tagger的图形界面。通过这两款软件,用户无需在命令行中输入命令和参数就可对语料进行标注处理,从而降低原软件的操作难度。在语料库研制中,语料标注需确定一套统一标注体系。在英文词性标注方面,兰卡斯特大学推出了英文词性集CLAWS5和CLAWS7,并提供CLAWS WWW tagger在线标注;在中文词性标注方面,有中科院(ICTPOS)、北大(PKU)、中传(CUC)等各种中文词性标注集,各标注集在词性划分略有不同,切分颗粒度上又分粗、细度,需根据研究目的进行选择。其中教育部语言文字应用研究所计算语言学研究室下属“语料库在线”网站、国家语言资源监测与研究有声媒体中心可提供在线汉语分词和词性自动标注。
对于多模态语料库建设,由于涉及到录音录像转写,当前主要借助Anvil、ELAN等主流多模态建库工具。其中尤为值得一提的是多模态转写标注软件 ELAN(EUDICO Linguistic Annotator)。该软件支持多种音视频格式,具有转写模式、同步模式、标注模式和分割模式四种不同的工作模式,支持父层与子层等级式的多层次标注,用户可自行设定标注的内容和标签,此外该软件还具有强大的检索功能(刘剑、胡开宝2015:80)。当前基于ELAN的语料库建设、应用和语言研究大致包括三类:汉语方言多媒体语料库研制及其应用(李斌2012)、中国手语语料库建设(吕会华、刘辉2014)和应用语言学研究的多模态分析(王立非、文艳2008)。
3.1.4 对齐
语料对齐针对对应或翻译语料库,需要根据研究目的或假设,对语料在词、句、段或语块等层级进行对齐。常用语料对齐软件包括Paraconc等专门语料软件以及CAT软件中附带的对齐工具,比如 SDL Trados的 WinAlign、ABBYY Aligner和雪人CAT的对齐工具等。然而,云技术的发展和翻译实践的云平台化促使翻译和语料处理趋向于在线进行,比如Tmxmall公有云平台便推出了其免费在线对齐服务。该在线对齐可以实现单/双文档对齐,涉及中文、英语在内的46种语言,2070种语言对,自动识别“一对多”、“多对一”、“多对多”句子对应关系,极大地提高对齐效率和准确度,并支持多种主流格式的导入和导出。
不过,在句子层面对齐中,由于译者翻译中可能或多或少作出一定调整,从而出现原文多句合译为一句译文或原文一句分译为多句译文的情况,尽管当前对齐工具能在一定程度上自动应对“一对多”或“多对一”的情况,但仍需在使用软件对齐之中或之后人工介入调整相关句段。
3.2 语料库研制趋势
完成建库后,接下来就是对语料库进行检索、统计和分析。语料库建立和分析传统上是在本地计算机进行,故这一阶段使用的主流语料库工具属于第三代语料库分析工具,其中以WordSmith、AntConc、MonoConc、Xaira和 PowerConc等为代表,索引分析、词频表、主题词是这些工具的几大核心功能(许家金、贾云龙2013;许家金、吴良平2014:10)。但在大数据时代下,得益于网络技术的突飞猛进,语料库研制与分析的网络化程度越发深入,因此语料库研制当前呈现三大趋势:研制工具上,单机软件转向网络应用;研制目的上,语料库研制与分析功能融合;研制应用上,语料库研制趋向大数据应用化。
3.2.1 单机软件转向网络应用
对于语料库单机软件的开发,一种是开发全新的语料处理软件,另一种则是为已有软件设计图形界面,比如上文所提到的Ant系列软件与BFSU系列语料库软件及工具。然而,尽管新型单机软件不断降低语料库研制的门槛,但鉴于本地电脑的硬盘空间和处理能力有限,而语料库建库容量越来越大,分析越发复杂,大量语料需要直接从网络获取或上传保存到网络,单机软件(本地)转向网站应用(网络化)的趋势已经出现,在工具上为语料库研制提供更多选择(简介见表1)。
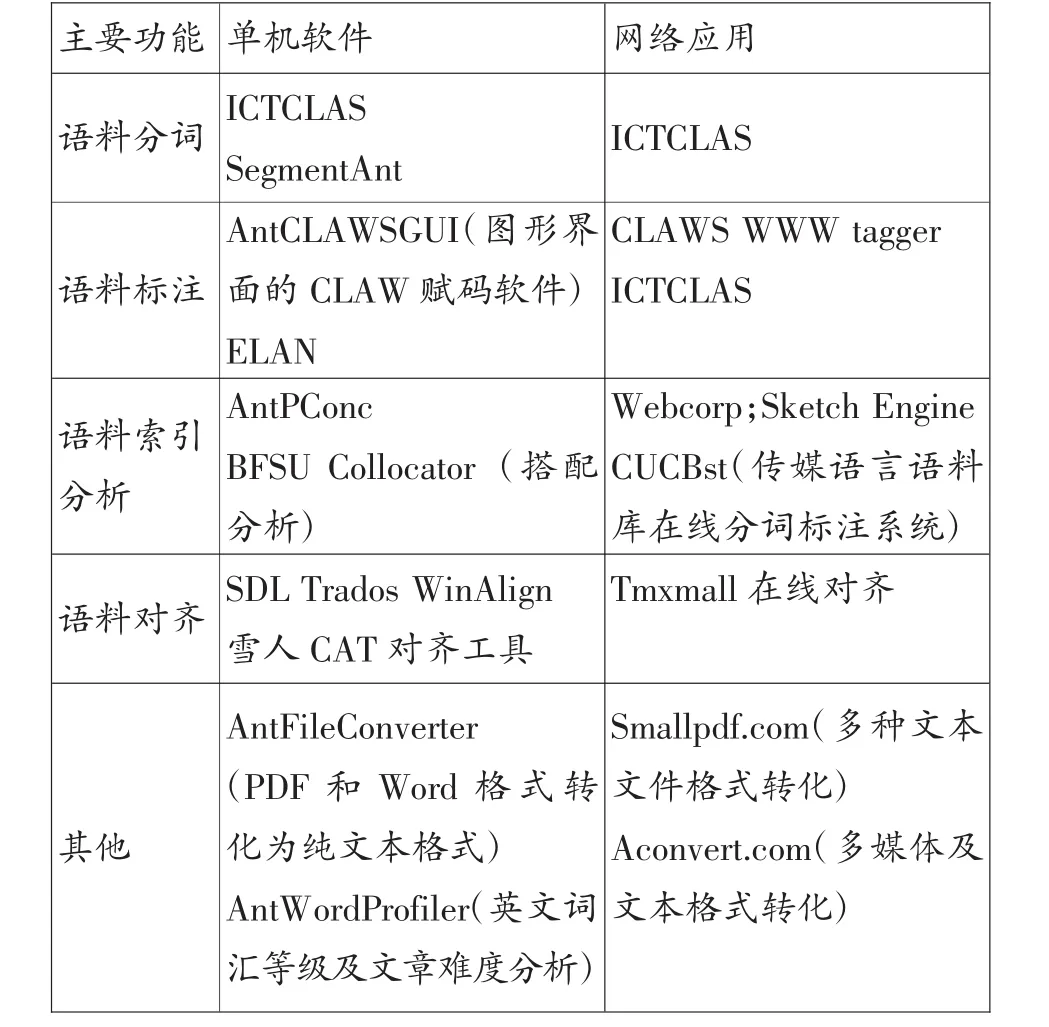
表1 语料处理单机软件与网络应用列举
3.2.2 语料库研制与分析功能融合
作为单机软件转向网络应用的成果,Sketch Engine、Webcorp、BNCweb、CQPweb 等基于网络的第四代语料库分析工具已逐步兴起,具备词表生成、索引分析、词语搭配计算、主题词分析等当前主流单机版语料库工具的几乎所有功能(许家金、吴良平2014:10),同时实现语料库研制与分析功能融合。比如Sketch Engine,研究人员可自行上传语料或调用搭配其已有子库,再借助其统计工具自动分析,或者通过输入数个种子词(Seed word),自动在网络上获取还有数个种子词的URL,再对所获URL进行文本内容提取,从而建立语料库。无独有偶,NLPIR汉语分词系统提供网页URL页面信息获取,只需输入需提取网页的网址,该演示系统就自行获取页面文字,随后可进行语料处理。
3.2.3 语料库研制趋向大数据应用化
在语言服务行业,应用大数据技术包括但不限于以下几个方面:基于大数据可视化分析、基于大数据的预测、基于大数据的商业交易(王华树2016:3),其中基于大数据的可视化分析和商业交易可与语料库建设及研究结合。
所谓大数据可视化分析指对大量抽象数据进行视觉表现,使读者直观地把握数据的空间分布模式、趋势、相关性等描述和推断统计信息,而这些统计信息可能会在其他呈现方式下难以被发现,基于词频分析的词云(word cloud)就是数据可视化的经典代表之一。我们相信,未来的语料库研制的关注点不但只在于建库或分析,也将更多关注于分析结果的呈现方式,不应满足于索引定位(concor-dance plot)等机械式描述,而是以一种更为人性化的方式呈现多模态数据的统计信息和数据之间的互动。
大数据交易包括如语料库或翻译记忆库交易以及多语种数据处理服务。作为一种狭义的语言资源(陈章太2008:10),语料库在语言研究中不仅具有学术价值,而且在自然语言处理中具有词典编纂、机器翻译、软件开发等商业价值,故其成品及研制过程中各个环节亦可为大数据交易提供商机。语料库研制的主体将分为研究者自行研发或邀请专人研制,抑或把语料清洗、标注、对齐等工作分工外包,比如Tmxmall现已推出人工对齐服务。
4.结论
大数据时代下,各种新型网络自然语料不断涌现,有利于扩展语料库研制及研究的边界,同时,随着网络技术和自然语言处理技术的进步,各种自然语言处理软件的图形界面化、网络应用普及和第四代语料库分析工具的逐步兴起,均有利于降低语料处理和语料库建设的难度。然而,语料库研制在取样、标注等基础标准暂未统一,比如对于汉语分词,不同的标注结果将影响后续研究的信度和效度。同时,单、多模态的语料采集、用于汉语翻译语言分析的检索和统计工具还不够丰富,尤其是缺少特别适合汉语语言分析的工具(秦洪武、李婵、王玉 2014:66-67)。
因此,为应对以上挑战,外语专业研究人员必须提高自身语料库研制技术,而采用Python、R等编程语言进行文本处理已是大势所趋,或将成为未来语料库研制、翻译技术乃至翻译研究的亮点。已有学者出版相关著作,探索如何在语料库的教与学及其应用、语料库科研中习得Python能力(管新潮2018)。相信随着语料库研制技术的发展,研究人员会在语料采集、分词、深度标注、分析、可视化等方面提高语料库研制的水平,助力语言研究分享大数据时代的数据红利。
猜你喜欢
通信技术(2021年12期)2022-01-25
校园英语·月末(2021年13期)2021-03-15
天津外国语大学学报(2020年1期)2020-03-25
智富时代(2019年6期)2019-07-24
智富时代(2019年6期)2019-07-24
语言与翻译(2015年4期)2015-07-18
民族古籍研究(2014年0期)2014-10-27
外语教学理论与实践(2014年2期)2014-06-21
外语教学理论与实践(2014年4期)2014-06-13
