
面向嵌入式控制终端的水培生菜光调控目标值模型
2019-05-05 01:15完香蓓简丽蓉辛萍萍单慧勇
上海农业学报 2019年2期
完香蓓,简丽蓉,辛萍萍,单慧勇,胡 瑾
(西北农林科技大学机械与电子工程学院,杨凌 712100)
近年来,水培技术因具有营养均衡、可循环使用、无污染等优点,已成为设施栽培产业新的研究热点和发展趋势[1-2]。光是光合作用中反应能的唯一来源,是影响植物生长发育最重要的环境因子之一[3]。由于受到墙体材料的遮挡等因素的影响,设施水培生产中光照明显不足,因此面向水培种植的光环境调控将成为设施水培调控技术中新的研究热点。其中,光环境智能调控模型可实现不同条件下光饱和点的动态获取,为光环境高效调控提供依据,是整个调控系统的核心。水培种植根温动态调控相较于原有的土壤和基质种植形式,成本明显降低、可行性明显提高,而且水培中根温控制对植物光合作用有显著影响[4]。因此,如何在现有光调控的基础上,融合水培根温等多环境因素对光合速率的影响,研究面向嵌入式调控装备的水培蔬菜光环境优化调控模型,成为水培技术发展中的关键问题。
现有光环境调控模型研究主要集中在日光温室土培作物上。王智永等[5]通过设计多因子嵌套试验获得不同光量子通量密度、CO2浓度、温度组合条件下的光合速率值,利用支持向量机算法建立光合速率模型,设计基于连续蚁群寻优算法获取光饱和点并以其为调控目标,建立了全范围温度、CO2浓度下的光环境优化调控模型。胡瑾等[6]针对光温耦合条件下番茄光环境调控目标值难以快速、精确获取的问题,在光温嵌套光合速率试验结果基础上,提出了改进型鱼群算法的光温耦合寻优方法,对不同温度下光饱和点进行快速精准寻优,建立了番茄光环境调控目标值模型。但由于以土培作物为研究对象所建模型均未考虑根温对光饱和点影响,加之原有模型大多采用非线性回归方式拟合,在加入根温影响后模型必然会出现精确度显著下降、复杂度明显上升的问题,故采用原有方法构建的模型必然不能满足需求。随机森林算法是Leo Breiman提出的Bagging集成学习理论[7]与Tin Kam Ho 提出的随机子空间方法[8]相结合的一种监督学习算法。它利用bootsrap重抽样方法从原始样本中抽取多个样本并进行决策树建模,再通过组合多棵决策树的预测,由投票得出最终预测结果[9-10]。随机森林回归算法在一定的样本含量下,能够在高维数据中有效地分析具有交互作用和非线性关系的数据[11],满足处理根温、气温、CO2浓度与光饱和点数据样本的需求。且随机森林算法作为一种人工智能算法可以实现对多元数据的拟合,具有参数较少、预测准确率高、对异常值和噪声有很好的稳健性、可移植性好且不容易出现过拟合等优点。岳继博等[12]利用随机森林算法对冬小麦生物量进行了回归试验,探讨了利用随机森林算法估算冬小麦生物量的最佳方法。李健丽等[13]为监测小麦白粉病,基于随机森林算法建立模型,提高了大数据下的监测精度。但是模型中子树棵数、特征子集参数选取等仍存在问题。
本研究在已有光调控模型研究基础上,针对水培生菜设计多因子嵌套试验,建立面向嵌入式控制终端的光调控目标值模型,以期为面向嵌入式系统的光环境高效精准调控提供理论依据。
1 材料与方法
1.1 试验材料
试验于2016年9月15日—10月15日在西北农林科技大学北校机械与电子工程学院智能农业实验室进行。试验生菜品种为‘波士顿奶油生菜’。植株生长至4、5片真叶时移植于MD1400培养箱(荷兰sinder公司)内,进行正常的水培栽培管理。营养液采用华南农业大学叶菜配方A(包括浓缩液A、浓缩液B与徽肥。A液主要成分为四水硝酸钙、硝酸钾与硝酸铵,B液主要成分为磷酸二氢钾、硫酸钾、七水硫酸镁,A液与B液按照1∶200分别稀释后混合,再滴入1∶500浓度稀释的徽肥,混合而成水培营养液),不喷施任何农药和激素。随机选取健康、长势一致、苗龄一致的长至5、6片真叶的生菜幼苗进行试验。
1.2 试验方法
为避免作物午休效应影响,选取9:00—11:00和14:00—17:00两个时间段对植物的各项参数进行测量和获取。利用美国LI-COR公司生产的LI-6800便携式光合速率测试仪的不同子模块设定测量时所需要的各项环境参数。水培试验营养液温度设置为13℃、15℃、17℃、21℃、25℃、29℃共6个梯度;叶室温度控制模块设置为15℃、20℃、25℃、30℃共4个梯度;LED光源光强模块设置为700μmol(m2·s)、600μmol(m2·s)、550μmol(m2·s)、500μmol(m2·s)、400μmol(m2·s)、300μmol(m2·s)、100μmol(m2·s)、50μmol(m2·s)、20μmol(m2·s)、0 μmol(m2·s)共10个光子通量密度梯度;CO2浓度设置为400μmolmol、800μmolmol、1 200μmolmol共3个梯度。得到以根温、气温、光量子通量密度、CO2浓度为自变量,净光合速率为因变量,容量为648的试验样本集。项目前期利用支持向量机-量子遗传算法进行光饱和点寻优,寻优模型决定系数为0.9454,得到以根温梯度为13℃、15℃、17℃、21℃、25℃、29℃、气温梯度为15℃、20℃、25℃、30℃,CO2浓度梯度为400μmolmol、800μmolmol、1 200μmolmol 嵌套下的107组光饱和点值。由图1可知,在生菜生长过程中,存在适宜的根温区间,过低或过高的根温均对光饱和点存在限制作用;随着气温升高,光饱和点值逐渐升高但增长速率逐渐减缓;CO2浓度增加使得光饱和点值得到提升。
综上所述,根温、气温、CO2浓度与光饱和点之间存在显著耦合关系,故基于随机森林算法构建模型更适宜。
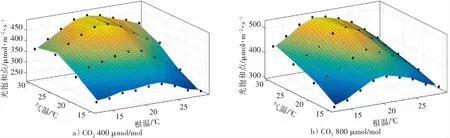
图1 光饱和点与根温、气温的关系图Fig.1 The relationship between light saturation point and root temperature and air temperature

图2 基于随机森林算法的建模过程Fig.2 Model construction flowchart with random forest algorithm
2 光调控目标值模型
采用Python scikit-learn 算法包集成方法中的Random Forest Regressor,以根温、气温、CO2浓度为输入,光饱和点为输出进行光饱和点预测模型的构建。模型构建过程主要分为训练集与测试集的选取、特征子集选择、最优决策树棵数选取、模型构建及验证。具体模型构建流程如图2所示。
2.1 训练集与测试集的选择
基于试验材料与方法部分所述的试验过程及结论,将试验所获取的数据进行分类,以根温、气温,CO2浓度为自变量,光饱和点为因变量的107组试验样本作为本模型的数据源。随机选取85组样本数据作为训练集,约占总样本数据的80%。剩余的22组样本数据作为测试集,约占总样本数据的20%。使用bootstrap抽样方法从训练集中随机产生k个子集θ1,θ2,…,θk,,构造对应的决策树{T(x,θ1)},{T(x,θ2)},…, {T(x,θk)}。
2.2 模型参数选取
由于random_state是随机数生成器,n_estimators参数及max_feature参数改变对模型预测结果的影响将被随机性掩盖。因此,在参数选择阶段,首先设定初始寻优范围为random_state∈[250,450]、n_estimators∈[25,500]、max_feature∈[1,2]进行网格预搜索,得到参数值为random_state为320、n_estimators∈[96,105]、max_feature为2时模型较优。再设定random_state为320,分析模型精度随max_feature和n_estimators参数变化趋势。将特征子集参数max_feature寻优范围设定为[1,2]、对数化处理后的子树棵数参数lg(n_estimators) 寻优范围为[1.982,2.021],选取lg(MSE)为模型评价指标作等高线图,结果如图3所示。

图3 训练样本均方差随参数变化情况图Fig.3 Variation of mean square error with model parameter for training sample
由图3可知,当max_feature为2时,对于所有n_estimators范围,模型评价指标lg(MSE)均比max_feature为1时好;在max_feature为2时,lg(n_estimators)∈[1.995,2.010]时,lg(MSE)≤1.3,模型精度较高。在此范围内重新进行网格搜索,结果为当参数值random_state为320、max_feature为2、n_estimators为101时,模型均方误差(MSE)为19.1498、平均绝对误差(MAE)为2.9396、决定系数r2为0.9973、程序运行时间t为0.1014 s,模型性能最优。
3 参数对模型性能影响分析
随机森林算法特征子集与子树棵数对模型回归性能具有显著影响[14]。通过分析上述参数在模型建立过程中的意义,对比选取不同参数时模型误差、决定系数及运行时间差异来综合分析不同参数对模型性能的影响。
3.1 特征子集影响分析
光调控目标值模型中需要考虑的特征有根温、气温、CO2浓度3项。为了使模型不被随机性影响,此处设定随机数生成器random_state为整数320。当训练101棵决策树时,设定不同特征子集,得到结果如表1所示。

表1 不同特征子集评价指标对比
由表1可以看出,不同特征子集的选择对于回归模型性能影响很大,max_feature为2时模型性能明显更优,而该参数对模型运行时间没有影响。通过网格搜索、参考Brieman及多个文献对于回归问题的max_feature参数选取建议[15],选取max_feature参数为2,即不重复地随机从特征集中选取2个特征,使用选定的特征对决策树节点进行划分,结果表明此时模型性能最优。基于以上训练决策树,每棵树都会产生对应的预测值。而单棵决策树的预测通过因变量的观测值Yi(i=1,2,…,n)的加权平均得到[16],即:
(1)
其中,ωi(x)为每个观测值Yi∈(1,2,…,n)的权重。
3.2 子树棵数影响分析
随机森林算法将所有决策树预测的平均值作为最终预测结果,因此决策树的数量对模型回归性能具有很大影响。其中,Random Forest Regressor中的n_estimators参数指定决策树数目。对不同决策树棵数分别进行光调控目标值模型构建,计算模型均方误差(MSE)、平均绝对误差(MAE)、决定系数r2及程序运行时间t并进行分析比较。选取随机数生成器random_state为整数320,当max_feature参数为2时,选取子树棵树为101时所建模型性能最优(表2)。

表2 不同棵数评价指标对比
图4可知,随机森林算法模型受决策树棵数影响较明显,均方误差(MSE)、平均绝对误差(MAE)随着棵数增加先降低后逐渐趋于平稳。同时,决定系数r2随子树棵数增加而增加后趋于平稳。random_state设定不同可能导致不同结果,但决策树棵数增加将导致模型更加复杂,使得模型时间、空间开销增加。
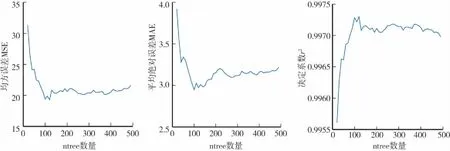
图4 不同棵数模型结果对比Fig.4 Comparsion for different n_estimators on model performance
3.3 模型验证
利用2.1节剩余22组试验样本作为测试集进行模型精度验证。按图1步骤完成光饱和点预测建模并验证,结果如图5所示。
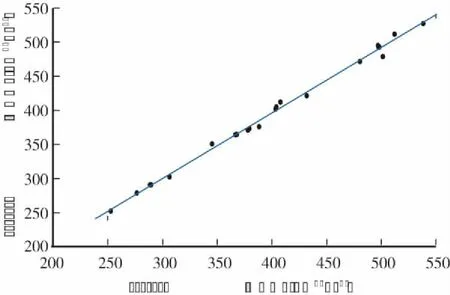
图5 光调控目标值模型验证Fig.5 Verification of the light environment regulation target model
基于随机森林算法的光调控目标值模型测试集拟合公式为:
f(x)=0.9617x+11.59
(2)
其中,决定系数为 0.9955,拟合直线斜率为0.9617,纵轴截距为11.59,均方根误差为5.677,平均绝对误差为5.3475,运行时间为0.0990s。表明光饱和实测值与预测值相关性高,模型泛化能力强,模型具有较高的预测精度。综上所述,基于随机森林算法的光调控目标值模型可实现不同环境参数下光饱和精准预测。
4 结论
水培作物生长过程中根温对光合作用存在显著影响,在已有光调控的基础上,本研究设计多因子嵌套试验方案,获得以根温、气温、CO2浓度为自变量,光饱和点为因变量的试验样本集。项目前期利用支持向量机-量子遗传算法获取不同环境因子下的光饱和点,以此为基础提出了一种基于随机森林算法的面向嵌入式控制终端可高精度移植的光调控目标值模型。
具体结论如下:(1)在建模过程中,为获得更好的模型效果,本研究通过网格搜索方法获得随机数生成器、特征子集及子树棵树的最优组合为[320,2,101]。通过分析不同参数对模型回归性能的影响,获知特征子集和子树棵数的选择对模型精度具有较大影响,前者对程序运行时间无影响,但后者随着子树棵数的增加,程序运行时间增加。(2)模型验证结果表明,模型预测值与实测值相关系数为0.9955,平均绝对误差为5.3475。采用随机森林算法进行水培作物光调控目标值模型构建精度较高,为面向嵌入式系统的模型高精度移植提供了一种有效方案。
猜你喜欢
少儿科学周刊·儿童版(2022年12期)2022-07-09
少儿科学周刊·少年版(2022年12期)2022-07-08
学校教育研究(2021年21期)2021-05-24
电子产品世界(2021年6期)2021-02-10
电子产品世界(2021年5期)2021-02-09
学校教育研究(2021年23期)2021-01-02
电子制作(2018年16期)2018-09-26
大陆桥视野·下(2017年1期)2017-03-09
科学与财富(2016年32期)2017-03-04
电子制作(2017年24期)2017-02-02
