
应用不同机器学习算法预测化学链中氧载体性能
2021-04-08 11:50阎永亮查健锐段伦博CLOUGHPeter
洁净煤技术 2021年2期
阎永亮,查健锐,,段伦博,CLOUGH Peter
(1.英国克兰菲尔德大学 能源与动力学院,贝德福德 MK43 0AL;2. 东南大学 能源热转换及其过程测控教育部重点实验室,江苏 南京 210096)
0 引 言
煤、生物质和天然气等碳基燃料燃烧是碳排放的重要组成部分,其燃烧产生的CO2亟待高效分离和存储。化学链燃烧和氧解偶化学链燃烧是最前沿的热电生产方法之一,可低成本和低能耗实现CO2分离。化学链反应在双流化床反应器中进行,氧气通过氧气载体从空气反应器输送到燃料反应器,烃类燃料被氧载体或氧载体释放的氧气氧化,生成CO2和水,之后氧载体在空气反应器中再生。
化学链技术发展的关键环节之一是根据成本、氧传递能力和循环稳定性选择合适的氧载体材料。相比纯金属氧化物和合成金属氧化物外,天然矿物和工业副产矿物由于廉价易得和较高活性而引起关注[1-3]。其中,锰基材料在高温下有向气相释放氧气的倾向,同时大量研究表明很多种类的锰矿石对不同气体燃料具有高反应活性,同时磨损率和成本较低,使其成为氧载体的潜在候选材料[4-5]。然而,这些矿物具有复杂多变且非均相的成分,且含有各种杂质,因此性能可能有很大差异。
机器学习是一种人工智能技术,通过统计方式提高模型计算性能,可分为有监督、无监督和强化学习。其中,经过学习启发的人工神经网络(ANN)在人脑行为研究中获得广泛应用,包括控制、机器人、模式识别、预测、医学、电力系统、制造、优化、信号处理和社会/心理科学等[6]。人工神经网络可作为一个黑箱,在给定一组输入数据后,从历史数据中学习并处理不同目的的任务,如预测、分类和模式识别[7]。
最近,有研究运用人工神经网络辅助碳捕集技术,该研究针对燃烧后胺基固碳反应的过程建模与控制[8-10]。也有研究者提出采用神经网络算法大规模筛选材料以辅助试验研究来开发新的钙循环化学链工艺。但机器学习算法目前还未广泛应用于化学链工艺的氧载体选材。为减少了材料开发的时间和成本,可以尝试使用机器学习算法挖掘历史试验数据,并对其进行可行性评估,这将有助于获得优选的氧载体参数。对于复杂材料,通过传统表征手段获得的材料性质及参数是机器学习重要的数据来源。据此,本文运用不同的机器学习算法预测多组分锰基氧载体的化学链反应性能,对照已有试验数据,评估不同算法在该应用中的表现,针对化学链氧载体筛选这一科学问题寻找更有效的机器学习模式。
1 机器学习在氧载体中的应用
低成本、高活性的氧载体是决定化学链技术能否工业规模化应用的关键因素之一。过去20年,超过1 000多种氧载体材料在实验室热重、固定床和流化床模拟条件下进行测试与筛选。这些氧载体可分为单一(镍基、铁基、铜基和锰基)和复合(2种及以上不同金属氧载体)组分氧载体。此外,助剂和载体等惰性组分对氧载体的性能影响很大。除了开发高活性和耐磨损的氧载体以适应工业规模化需求外,寻求低成本氧载体,尤其利用廉价的天然矿石或可再生工业废弃物作为氧载体对于推广化学链技术应用有重要意义,将在煤或生物质化学链转化方面有明显优势。由于这类原料廉价,且具有足够的反应活性和机械强度,不会造成氧载体失活以及灰分与氧载体分离[11-14]。但其组成成分不同可能会对化学链反应产生很大影响。但在如此众多的材料中逐一筛选测试,将带来巨大的试验成本。
机器学习是一门结合计算机科学、统计学、数学与工程学的交叉学科。利用已知数据,在特定的算法指导下进行自动优化并改进模型,使之可以对新的输入值进行判断与预测。因此,提出一种新颖高效的筛选方法,结合已有氧载体试验数据,应用机器学习加速新氧载体材料的开发。前期研究[15]讨论了如何训练人工神经网络用于预测不同锰矿石在化学链反应的性能,结果显示神经网络对照试验数据的预测较为准确,但选择合适的算法与避免过度拟合具有一定难度,需要大量前期调试工作。因此本文尝试分别使用支持向量机和人工神经网络2种常用的机器学习算法建模,预测天然锰矿石作为氧载体的反应性能,并评估不同算法在该应用中的表现,针对化学链氧载体筛选这一科学问题寻找更有效的机器学习模式,具体工作流程如图1所示。
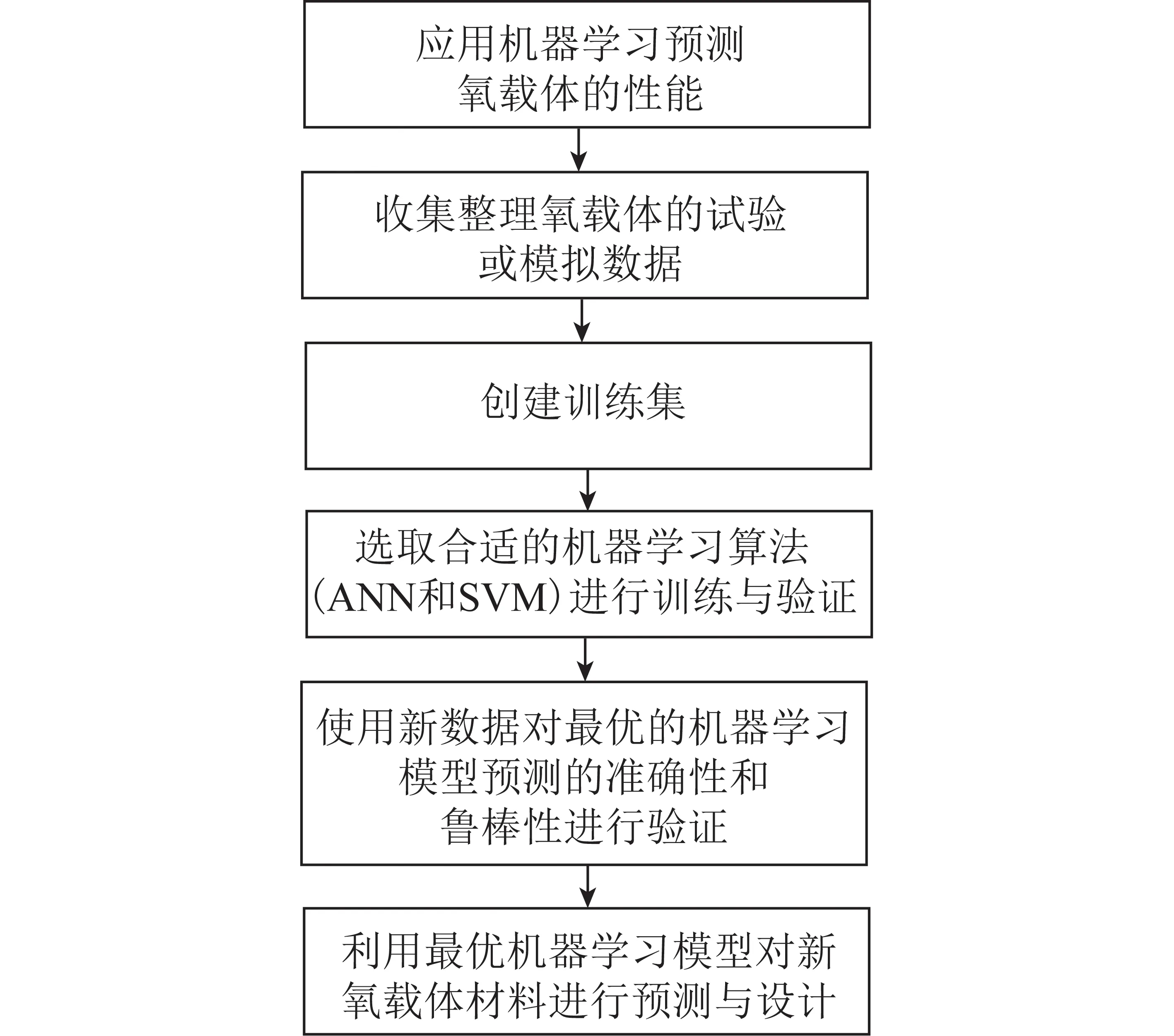
图1 应用机器学习预测氧载体性能的工作流程
2 材料和方法
2.1 氧载体的训练集
训练集决定了监督机器学习能否产生一个最优模型,从而准确预测新输入数据。应根据实际应用决定机器学习模型的输入(特征)和输出(目标)。本文收集了文献[16-17]的19种世界各地天然锰矿在小型流化床中的释氧特性数据,及其与甲烷和合成气(50% H2+50% CO)反应转化为CO2产气率作为反应特性的数据来训练优化机器学习模型。除锰之外,这些锰矿石还包括Fe、Si、Ca和Mg等元素,对氧载体的化学链反应有潜在影响。因此,在此工作中锰矿石的元素组成、物理性质(磨损率、破碎强度和比表面积)以及试验条件(如床温)等14个参数被确定为训练集中的输入值。锰矿石的释氧特性以及与甲烷和合成气(50% H2和 50% CO)反应特性的试验数据作为输出值。其中,75%随机选取的数据用于训练集的训练,剩下各15%随机选取的数据分别用来验证和测试。然后,应用新建立的训练集结合不同机器学习算法寻求建立最优预测模型。此模型可以根据新的输入值快速预测新氧载体的释氧特性以及与不同燃料的反应特性。为了验证最优模型对于新输入值预测的准确性和鲁棒性,训练集中锰矿石与合成气在850 ℃反应下测得的试验数据被标记为隐藏数据用来验证。
2.2 机器学习算法
2.2.1支持向量机(SVM)
支持向量机(Support vector machine,SVM)是由Vapnik率先提出的一种基于统计学习理论的机器学习方法,适用于分类问题和预测回归问题。尤其在解决少数据、过度拟合、非线性和维数灾难等方面优势突出。基本思路是,通过构建决策边界区分不同类别的坐标。超平面边界的回归方程为
y=f(x)=wTx+b,
(1)
其中,x和y分别为输入值(空间)和目标值;w、b分别为超平面法向量和截距。分类时,使离超平面最近的某坐标距离值最大需优化约束,即
(2)
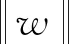
|f(xi)-yi≤ε|。
(3)
MATLAB软件Regression Learner工具箱内包含的支持向量机算法被用来开发此工作中机器学习预测模型。具体步骤为:将训练集导入 Regression Learner中,标记出模型的输入值与输出值。选择支持向量机算法进行训练,选出最优预测模型。
2.2.2人工神经网络(ANN)
人工神经网络(Artificial neural network,ANN)是一种通过数学模型来模拟大脑神经元结构和功能的机器学习方法,被广泛用于回归、分类和模式识别。ANN一般由输入层、隐藏层、输出层以及每层的神经元构成。输入数据由输入层的神经元接收,通过调整神经元的权重和阈值,在激活函数的处理下,将输出值传递到隐藏层的神经元,然后在单层或多层隐藏层神经元中逐级传递后最终到达输出层给出预测结果。单层神经网络的信号传导过程描述为
(4)
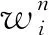
(5)
本文采用前馈神经网络作为机器学习模型,优化前馈神经网路模型需要对网络拓扑结构,即隐藏层的层数以及每层的神经元个数进行测试分析。一般情况下,单层或双层前置神经网络可以满足绝大部分的回归预测分析。因此,开发了不同脚本比较单层和双层前置神经网络在不同神经元下的表现,选出最佳前馈神经网路预测模型。
2.2.3预测性能评价
支持向量机和人工神经网络的预测表现通过均方根误差(RMSE)、平均绝对误差(MAE)以及决定系数(R2)来评价。
(6)
(7)
(8)
式中,ti为输出值。
3 结果与讨论
3.1 SVM与ANN预测结果及鲁棒性
SVM和ANN预测不同锰矿石在化学链条件下释氧特性和甲烷/合成气反应的表现见表1、2。其中SVM模型对释氧特性预测的准确率最低,但在预测甲烷/合成气反应中有较高准确性。
与SVM模型相比,ANN可以同时产生3个预测参数,无需和SVM模型一样建立3个针对不同预测参数的模型。但ANN需要对隐藏层数及神经元个数进行验证,选出表现性能最好的ANN模型。分别对单隐藏层(ANN1)和双隐藏层(ANN2)以及神经元节点1~50网络进行对比,选出最优ANN模型来预测不同氧载体的性能。
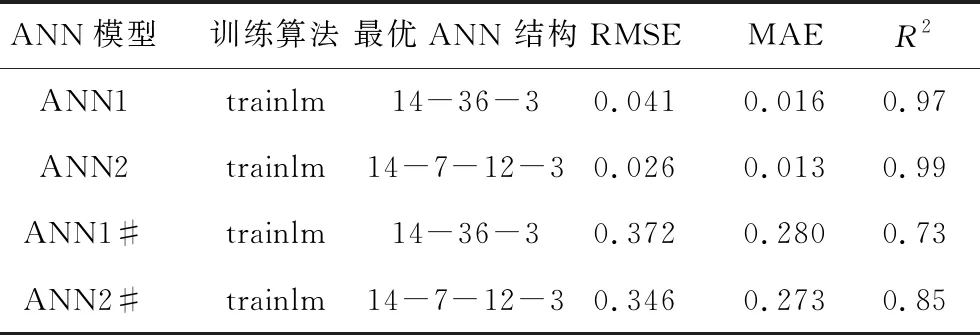
表1 SVM模型预测表现
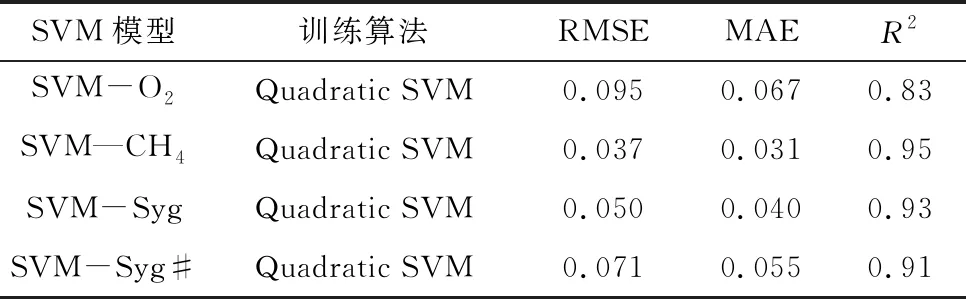
表2 ANN模型预测表现
由表1、2可知,ANN2的预测性能高于ANN1。且ANN1和ANN2对于训练集的预测能力都强于SVM模型的预测,但这只能作为评价机器学习性能的指标之一。因为ANN在小样本训练中可能存在过度拟合的问题,即能够预测已知训练集的数据,但对训练集之外的新输入值存在较差的预测能力。因此,利用不在训练集中的锰矿石与合成气在850 ℃ 反应条件下测得的试验数据为新输入值用来验证最优SVM和ANN模型的准确性和鲁棒性。
训练后的SVM与ANN模型对新输入值(19种锰矿石与合成气在850 °C的反应特性数据)的预测如图2和3所示(误差棒代表置信区间,γ表示与某物质反应,下同)。可知SVM模型对新输入值的预测准确性和鲁棒性更好。其均方根误差、平均误差和决定系数分别为0.071、0.055和0.910,远高于单层隐藏层ANN模型的0.372、0.280、0.730。由此证明ANN模型再次运行过程中有一定的过度拟合,对新输入值的预测准确性和鲁棒性不高。但增加ANN模型的隐藏层层数和神经元节点时,会提高ANN模型对新输入值的预测表现。
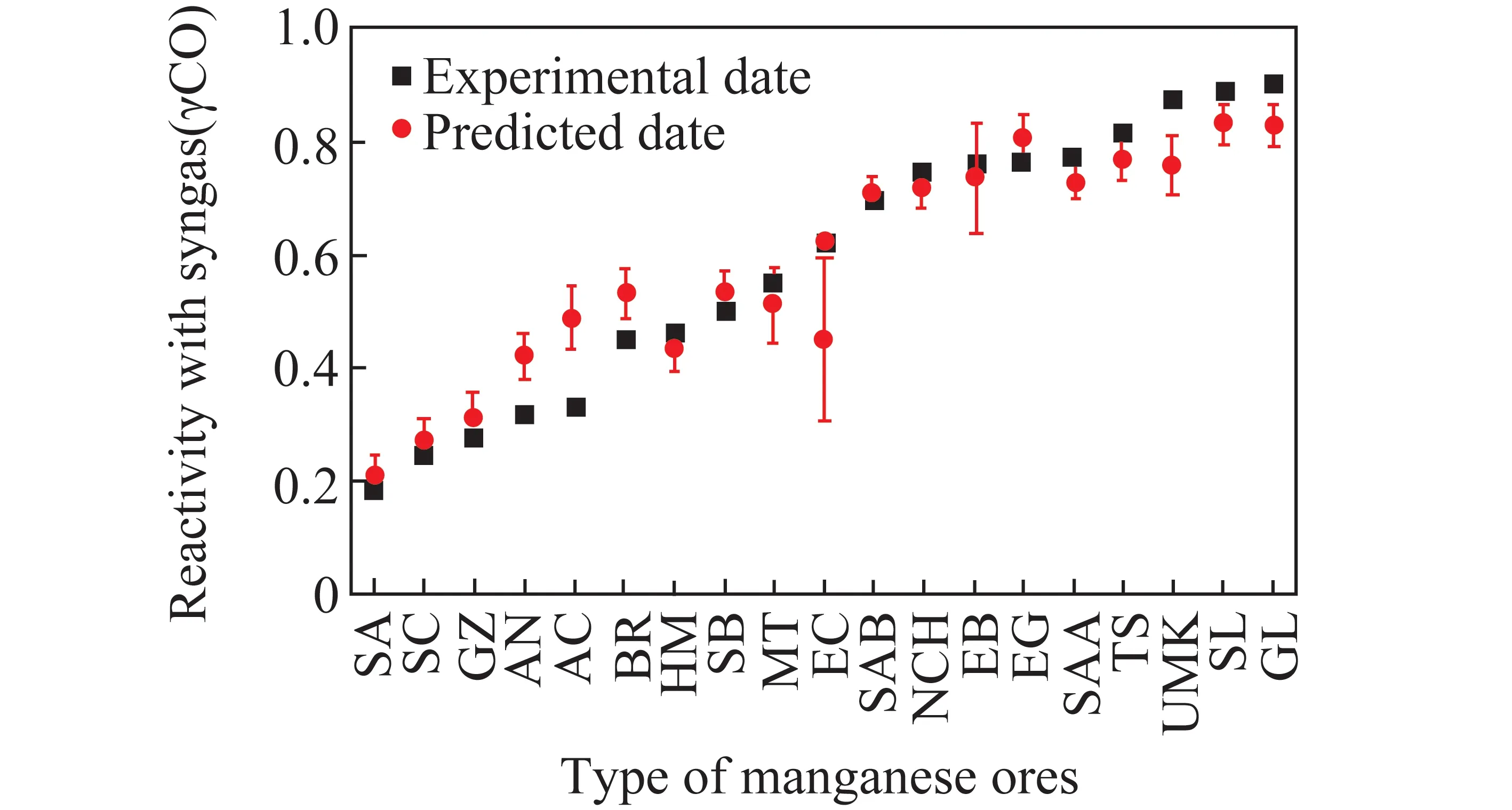
图2 最优SVM模型对新输入值的预测
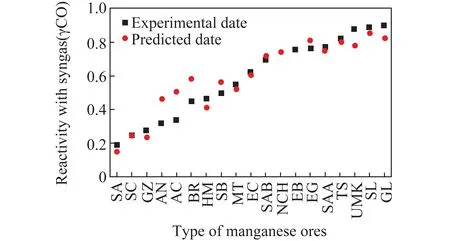
图3 最优ANN模型(14-36-3)对新输入值的预测
3.2 灵敏度分析
经过训练的SVM与ANN模型不仅可以预测不同锰矿石的释氧特性,以及预测与甲烷/合成气的反应特性,还可以通过灵敏度分析来衡量输入参数变化对预测结果的影响,这将为修饰或改性天然锰矿石、合成高性能氧载体提供有用信息。在3.1节中,训练的SVM模型对新输入值的预测有更好的准确率和鲁棒性,因此在灵敏度分析中,分别改变TS锰矿石的Fe含量、Mn含量以及BET比表面积(±30%相对于TS锰矿石的原始值),利用训练过的支持向量机模型来预测修改后的TS锰矿石的氧载体性能。
图4为最优支持向量机模型对不同铁含量、锰含量以及BET比表面积的TS锰矿石作为氧载体的预测。可知,TS锰矿石的释氧特性与锰矿石中Fe含量和BET无关,其随着Mn含量的升高而提高。TS锰矿石与甲烷以及合成气的反应性基本不随Fe含量和BET比表面而变化,与甲烷的反应性随Mn含量的升高而降低。这些趋势是建立在训练的支持向量机模型预测上,可能与最终试验数值有些不同。但此方法能很好地节约试验筛选锰矿石作为氧载体的时间,对候选材料进行初步预测筛选。
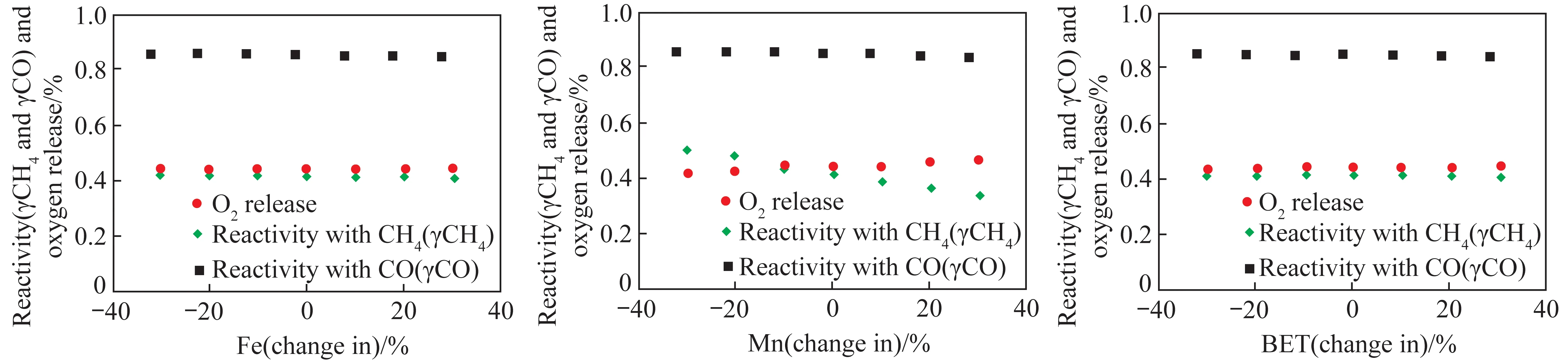
图4 最优SVM模型对不同Fe含量、Mn含量以及BET比表面积的TS锰矿石作为氧载体的预测
本文通过锰矿石作为氧载体,利用监督机器学习的回归性分析,成功阐述了利用已有试验数据结合机器学习算法能够实现对氧载体性能的预测。此方法不仅可以应用于锰矿石为主的氧载体,还可以应用于其他以金属氧化物为主的氧载体材料,从而加快开发高效低成本的氧载体。
4 结 论
1)探索了不同机器学习方法在开发氧载体材料的应用潜力,以19种不同锰矿石在化学链反应的试验数据为训练集,利用训练集训练人工神经网络和支持向量机模型,预测不同锰矿石在小型流化床中的释氧特性,以及与甲烷/合成气的反应特性。
2)2种机器学习模型对训练集的数据都有较高的预测准确率。其中人工神经网络的预测表现要高于支持向量机。但对新输入值预测方面,支持向量机模型的准确性和鲁棒性更好。隐藏层层数及神经元节点对神经网络模型的预测准确率有很大影响。通过比较不同结构模型的预测表面,最终筛选出最优的神经网络模型。此外,还进行了灵敏度分析以确定关键参数。
猜你喜欢
矿山安全信息(2022年14期)2022-11-24
分子催化(2022年1期)2022-11-02
空间科学学报(2020年4期)2020-04-22
中国金属通报(2020年20期)2020-03-27
中国特种设备安全(2019年5期)2019-07-16
电子制作(2019年10期)2019-06-17
测控技术(2018年9期)2018-11-25
报刊荟萃(上)(2017年6期)2017-06-19
河北地质(2016年2期)2016-03-20
华东理工大学学报(自然科学版)(2015年5期)2015-02-27
