
基于ELMo-GCN 的核电领域命名实体识别
2023-01-12 11:49荆鑫王华峰刘潜峰罗嗣梧张凡
北京航空航天大学学报 2022年12期
荆鑫, 王华峰,,*, 刘潜峰, 罗嗣梧, 张凡
(1. 北方工业大学 信息学院, 北京 100144; 2. 北京航空航天大学 软件学院, 北京 100191;3. 清华大学 核能与新能源技术研究院, 北京 100084; 4. 太原理工大学 软件学院, 太原 030024)
新智能时代向工业5.0 新形态演进的进程已经全面启动[1]。 在《中国能源革命进展报告(2020)》中提出,要加速融合新一代信息技术与能源技术,推动多能互补智慧能源系统建设步伐[2]。 在这一进程中,需要对数十年核电发展所积累的信息进行处理、分析和管理,以达到提升工作效率、优化产业结构的目的。 因此,如何从海量的非结构化文本信息中提取到有用信息,是计算机智能技术在核电领域应用的难点。 这里便需要用到自然语言处理(natural language processing,NLP)技术对其文本数据进行语义理解和语义分析。
NLP 作为人工智能的子领域,是将人类交流所使用的语言通过某种算法转化为机器可以理解的机器语言的技术。 其中,命名实体识别(named entity recognition, NER)是NLP 中一个重要的文本预处理工具,其主要作用是识别出文本中表示命名实体(named entity, NE)的成分,并对其进行分类,故而也被称为命名实体识别和分类(named entity recognition and classification, NERC)。 而由于核电领域本身的特殊性,NER 任务缺乏相应的研究。
早期的命名实体任务主要针对以英语为主的印欧语系,该任务仅限于一个或多个严格指示词的实体,严格指示词包括专有名称及某些自然类术语,如生物物种和物质[3]。 随后,NER 任务转为一般意义上的“专有名称”,研究最多的就是“Person”、“Location”与“Organization” 3 种实体类型,这些类型统称为“Enamex”。 直到1995 年第六次信息理解会议(MCU)明确将“命名实体”定义为研究对象,此后NER 便成为一项单独的研究任务。 在定义这一任务时,研究人员发现某些命名实体是文本中的重要信息单元,这就诞生了命名实体最初的7 种实体类型:“Person”、“Organization”和“Location”,以及“Time”、“Date”、“Currency”、“Percentage”的数字表达式[4]。 在实验过程中,研究者们发现以上7 种实体类型无法满足研究需要,因此,结合实际添加了一系列细粒度实体子类型。 例如,Fleischman[5]与Lee 等[6]将“Location”划分为多个细粒度实体子类型:“City”、“State”、“Country” 等;Fleischman 与Hovy[7]将“Person” 的细粒度实体子类型划分为“Politician”、“Entertainer” 等;Bodenreider 和Zweigenbaum[8]将“Person”与“Drug”、“Disease”相结合进行命名实体分类。
目前,由于NER 技术在一些开放数据集中已经取得了很高的准确率,部分学术界学者认为NER 技术并不具备进一步的研究价值。 但是,在当前研究中,NER 研究面临着诸多问题需要解决:
1) 数据来源与处理问题。 核电相关的大部分资料(如检查报告、设计方案及日程安排等)均不能进行公开的研究,因此在数据来源的选择方面可参考内容少,数据范围小,在核能领域中的NER 技术研究更是稀缺。 同时在研究中,还需考虑如何有效地对核安全文本中的命名实体进行分类。
2) 文本类型对NER 任务有着很大的影响。诸如核电、生物医学领域的文本数据中,频繁出现的技术词汇、特定术语及其缩写、不完整句子等,直接导致网络模型无法像通用数据集一样构建全面合理的实体特征,神经模型的预测结果与通用数据集相差甚远[9]。
3) NER 研究中存在的具有挑战性的问题,如嵌套命名实体识别(nested named entity recognition,Nested NER)、歧义文本及标注语料数据老旧等[10]。 嵌套命名实体(nested named entity,Nested NE)是一种特殊形式的命名实体,即在一个命名实体的内部还存在一个或多个其他类型的命名实体,层次结构较为复杂,传统的基于序列标注的NER 网络模型不能很好地解决Nested NER 任务。
针对现今核电领域NER 研究面临的挑战,本文主要贡献如下:
1) 研究伊始面临的主要问题是缺乏数据集。考虑到核安全相关的大部分资料不能进行公开的研究,基于数据特征具有代表性和数据易于搜集2 个方面,本文以核反应堆相关基础理论作为基础文本数据。 在命名实体分类过程中,本文参考了核反应堆方面的相关研究,对现有文本数据进行分类,得到“专有名词类”、“冷却与冷却剂类”、“燃料与材料类”与“反应堆类”四大类。 此外,本文还通过BIO 数据标注方式对搜集到的文本数据进行标注,得到标记数据141 057 条。
2) 针对Nested NER 问题,本文在现有研究的基础上,提出了结合动态、张量的图卷积神经网络模型(graph convolutional neural network model with dynamic tensor, DTGCN),模型中加入了句子处理器,通过提取句中的动态张量并计算的方式,获取上下文信息,同时使用Self-Attention 模型学习句子中实体之间的依赖关系,获取句子的内部结构信息。 之后经由GCN 网络,利用核电语料中实体的内部关系与相邻关系,完成核电命名实体的细粒度识别,进而处理Nested NER 问题。
3) 构建校正模块进行后处理,基于命名实体类型的特征制定规则,并使用该规则对网络预测结果中的实体类型正确而边界判断错误的情况进行校正,以提高模型的容错率。
1 相关理论与方法
研究人员在NER 工作中已经取得了一定的进展。 Goller 和Kucher[11]使用循环神经网络(recurrent neural network, RNN),使模型可以变长输入且具有长期记忆,但由于RNN 结构本身的缺陷,存在梯度消失和梯度爆炸的问题。Hammerton[12]首次将长短记忆网络(long shortterm memory, LSTM)应用于NER,LSTM 网络中使用遗忘门、记忆门结合的方式,成功避免了梯度消失和梯度爆炸问题。 2015 年,Huang 等[13]在LSTM 的基础上,使用BiLSTM + CRF 模型,正向LSTM 获取“过去特征”,反向LSTM 获取“未来特征”,由此对上下文信息作出进一步发掘。Peters 等[14]利用双层LSTM,提出基于语言模型的上下文相关的词向量表示(embeddings from language model, ELMo),得到的ELMo 词向量具有更深层次的语义表征,但由于LSTM 本身的结构约束,一旦输入语句序列过长,模型的学习能力将大幅下降。
2014 年,Sutskever 等[15]在研究过程中首次引入Attention 机制。 2017 年,Vaswani 等[16]提出了Transformer 结构,通过Self-Attention 计算词与词之间的关系权重,使每个词都有全局的语义信息。 2019 年,Devlin 等[17]提出了基于Transformer的双向编码器(bidirectional encoder representation from Transformer, BERT) 模 型。 BERT 在11 项NLP 任务中表现优异,在其他网络模型最优指标的基础上有了新的突破。 不过,BERT 模型依然存在一定缺陷:①数据总量要求高,若总量不够,则最终训练效果较差;②运算量大,BERT 中的BERT-Base 模型参数为1.1 亿,BERT-Large 模型的参数更是达到3.4 亿,计算量大,所需成本高。
在NER 研究中,Nested NE 广泛存在于多种语料之中。 例如,以蛋白质和DNA 等实体类型标记的GENIA 语料库[18],Nested NE 占全部命名实体的17%;西班牙语和加泰罗尼亚语报纸的AnCora 语料库中[19],Nested NE 占50%左右;在ACE-2004 中,42% 的句子包含Nested NE,Nested NE占比达47%[20]。
对于Nested NE 的研究一直在进行。 Finkel和Manning[21]提出了一种基于条件随机场(conditional random field, CRF)的分区解析器,将句子作为解析树,句中单词和每个事宜相对应的短语作为解析树的叶子,该解析树还将词性包含其中,以此共同对实体和词性进行建模;Alex 等[22]提出将多模型级联的方式,分别为多组实体提供训练。此外,Lu 和Dan[23]提出了一种基于超图的模型来解决Nested NER 问题,通过输入给定的字符序列,获取内部所有的实体指代关系,计算得出分数最高的输出路径;Xia[24]提出了多粒度NER 模型来解决Nested NER 问题,该模型分为检测器和分类器2 部分,检测器负责检测所有可能的实体位置,分类器则将检测到的实体进行分类;Luo 和Zhao[25]结合LSTM 与GCN,将LSTM 部分作为最外层实体信息提取工具,再由GCN 结合实体关系图抽取实体信息。
2 结构模型
如图1 所示,DTGCN 模型主要分为2 部分,即外部模块(OuterModule)和内部模块(InnerModule),分别学习外层实体信息和内部实体信息。 核电语料集中的实体(Word)和语句(Sentence)分别进入外部模块的字处理器(Word Processor)和句子处理器(Sentence Processor)。 字处理器负责提取单个字的信息及输入语句中字与字之间的关系,主要使用BiLSTM 网络;句子处理器是以整个句子的层面进行信息提取,主要通过生成动态张量的方式,得到命名实体在不同语义环境下不同的张量特征,以此增加网络对实体上下文信息的提取能力;通过Self-Attention 模块获取实体之间的相关度信息。

图1 DTGCN 网络模型Fig.1 DTGCN network model
内部模块使用GCN 将实体与实体间的关系建模(其中Adjacency Graph Model 和Entity Graph Model 部分分别对外部实体和内部实体进行处理),通过迭代其传播信息,学习内部实体特征。GCN 将其学习到的信息输入到CRF 模块,对预测结果进行分类。 通过校正模块(Corrected Module)对预测结果中实体类型正确而边界判断错误的情况进行校正。
2.1 数 据
由于目前没有开放的核电数据集,笔者手动构建了一个语料集用于研究。 本文数据来自于核反应堆相关基础理论分析[26-27],对实体分为4 类:“专有名词类”(NOU)、“冷却与冷却剂类”(COO)、“燃料与材料类”(FUE)与“反应堆类”(REA)。
由图2 和表1 可知,核电语料集共8 023 句141 057 字,所用汉字1 384 个,其中专有名词类实体684 个,所用汉字407 字,114 字无嵌套关系,占28%;燃料与材料类实体207 个,所用汉字197 字,54 字无嵌套关系,占27%;冷却与冷却剂类实体1 365个,所用汉字491 字,146 字无嵌套关系,占30%;反应堆类实体251 个,所用汉字232字,37 字无嵌套关系,占16%。 此外,表1 还统计了每个实体的数量及实体的出现频率,出现频率统计了对应类型实体出现的总次数,便于从数据方面对不同网络模型中实体分类结果进行分析。

图2 核电语料中嵌套命名实体比例Fig.2 Proportion of nested named entities in nuclear power corpus
综上,核电语料集中Nested NE 占总实体的68%,远高于GENIA[18]、AnCora[19]、ACE-2004[20]等语料库中Nested NE 所占比例,因而进行NER研究的难度也更高。
核电语料通过BIO 实现对序列数据的联合标注,如表1 所示,其中,“B-”表示命名实体中的第1 个字,“I-”表示命名实体中间字和结尾字,“O”表示非实体字符,核电语料实体标注示例如图3 所示。
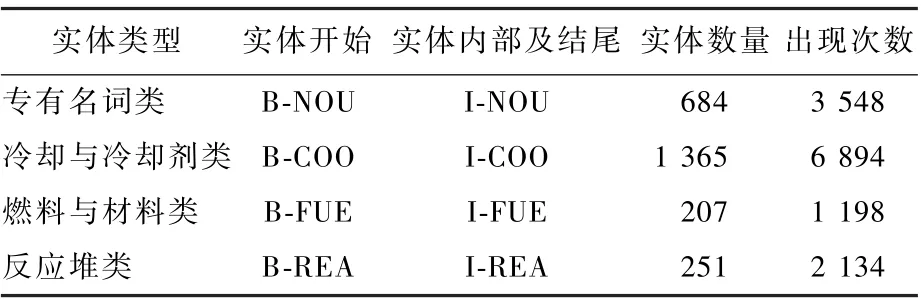
表1 核电语料实体标注方法及实体数量和出现频率Table 1 Nuclear power corpus labeling methodology,count, and frequency of appearance
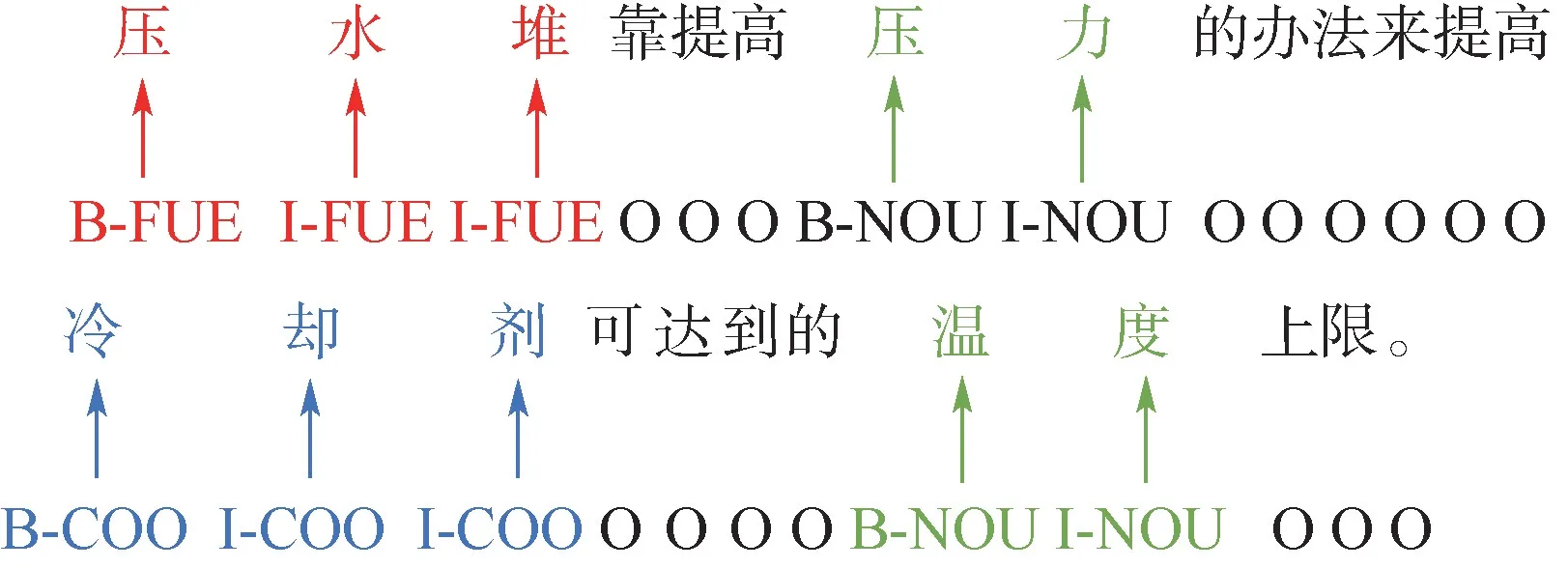
图3 核电语料命名实体标注示例Fig.3 Example of nuclear power corpus named entity labeling
2.2 字处理器
文字中存在着的隐藏信息往往隐含在上下文中,体现在字与字之间的前后关系上。 因此,本文模型使用BiLSTM 作为字处理器,提取单个字的信息及输入语句内字与字之间的关系。
给定一个包含N个字符的输入语句T=(t1,t2,…,tN),对每个字符tk(1≤k≤N)进行字嵌入后表示为:xk=[wk],wk为预训练获得的字嵌入模型。
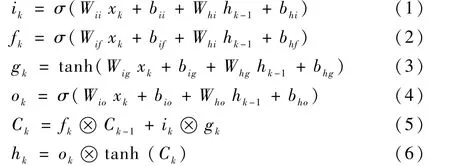
如图4 所示,结合式(1) ~式(6),W和b为LSTM 的参数,W为权重向量,b为偏置向量,σ为激活函数,⊗表示正交,ik、fk和ok分别代表k时刻的输入门、遗忘门和输出门,Ck、hk和gk分别表示LSTM 中的细胞状态、隐藏状态和新状态。xk经过BiLSTM 的输出得到k时刻字符的隐藏状态hk(其中包含前向隐藏状态和后向隐藏状态):

图4 LSTM 结构Fig.4 Structure of LSTM

因此,字符信息xk通过字处理器后得到LSTM输出特征αLSTM∈RN×dl(dl为BiLSTM 隐藏层大小):

2.3 句子处理器
同样的词在不同的语境条件下,表达含义有所不同。 传统的Word2Vec 或Glove 方式生成的词向量模型是固定的,这显然不符合实际语境的使用情况。 基于此,模型中使用ELMo[14]作为句子处理器,生成动态张量,使实体在不同语境下生成不同的特征张量,以获取更加丰富的上下文信息。
对于输入语句T= (t1,t2,…,tN),前向语言模型通过(t1,t2,…,tk-1)条件下tk(1 <k<N)的概率建模计算整个序列的概率:

后向语言模型也是同理:

综上,最大似然函数为

式中:θx为字符向量的参数;θs为Softmax 层的参数。
ELMo 是BiLSTM 的中间层表示任务的特定组合,对于每一个xk,一个L层双向语言模型可以得到2L+1 个结果。

而在通常情况下,查找字符向量的方法仅为查找表中的字符提供一层表示。

式中:ELMok为字符tk的ELMo 词向量;u为Softmax 的正则化权重;γ为缩放因子,允许任务模型缩放整个ELMo 向量。
ELMo 模型输出含有上下文信息的结果αELMo:

2.4 自注意力模块
对上下文字信息建模的方式一般是将所有字符表示形式连接起来或取平均值,但是当存在许多不相关的上下文词汇信息时,这一方式的结果并不理想。 为了选取高度相关的上下信息,采用Sself-Attention 模型[16]来获取上下文与实体之间的关联性。

式中:Q、K、V三个矩阵来自同一输入;dk为Q和K向量的维度。
Self-Attention 计算后可得
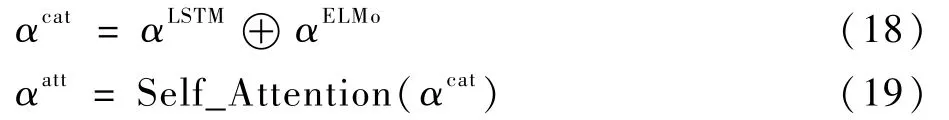
式中:αcat为将αLSTM与αELMo的拼接结果;⊕表示将2 个特征进行拼接;αatt为Self-Attention 模型输出的含有实体间相关程度的信息。
2.5 条件随机场
LSTM 等模型得出的结果是字符对应各个类型的分数,最高分数对应的类型便是预测结果。然而这样的分类方式忽略了字符对应于其他类型的分数,经常会预测出一些非合法实体类型情况(如“B-ORG I-PER”)。
CRF 是给定一组输入序列条件下另一组输出序列的条件概率分布模型[28]。 通过CRF 加入一些约束来保证最终预测结果的正确性,这些约束可以在训练数据的过程中被CRF 自动学习。CRF 的最终得分是通过计算转移特征概率和状态特征概率实现的。 目前,CRF 已经广泛应用于诸多NER 模型(如文献[29-31])。
输入特征向量为α=(α1,α2,…,αN),其对应的标签序列(tag)为Y={y1,y2,…,yN},定义分数为

式中:Ayi,yi+1为转移矩阵,表示从标签yi到标签yi+1的传输得分;Pαi,yi为经过LSTM 编码后的αi字符的yi标签的得分。
CRF 定义了在所有可能的标签序列Y上的条件概率p()为
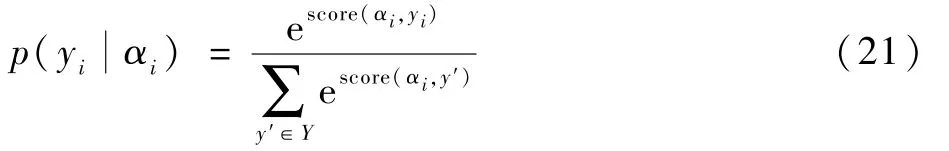
训练过程中,使用最大条件似然估计方法,选择使对数似然L最大化的参数,并使用一阶Viterbi 算法在输入序列上找到得分最高的标签序列,求解最优路径:

2.6 图卷积神经网络
区别于日常的图片,本文的“图”是一种数据格式,可以用于表示各种具有抽象意义的拓扑关系网络,如通信网络、蛋白分子网络、社交网络等,图中的节点表示网络中的个体,边表示个体间的连接关系。 传统的卷积主要针对欧氏数据空间,而在非欧氏数据空间无法保持“平移不变性”。 为了提取和挖掘非欧氏数据空间的有效空间关系进行建模学习,Kipf 和Welling[32]引入了GCN。
在GCN 中,每个图都可以定义为G= (Z,E),Z为节点(字)的集合,S为边(关系)的集合。图中第l层输出特征H(l)计算如下:
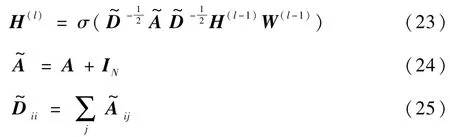
式中:第l层网络的输入为∈(初始输入为H(0)=X),N为图中节点数量(即句子长度),每个节点使用D维特征向量表示;为添加了自连接的邻接矩阵,A为邻接矩阵,IN为单位矩阵;为 度 矩 阵;W(l-1)∈RD×D为 待 训 练 参 数;σ为激活函数。
本文中,在这一基础上加入偏置,可以得图特征为
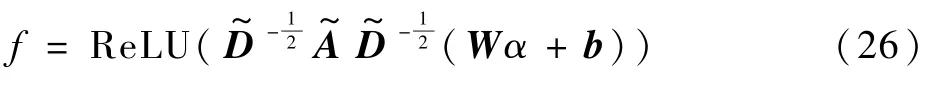
式中:W为权重,b为偏置,均为可训练参数;α为输入GCN 网络的实体特征;ReLU 为非线性激活函数。
本文中,G1和G2分别为对于实体的实体相邻图和关系图的图网络(见图5 和图6)。G2中,对于从外部模块中提取的实体中的所有节点,在任意2 个节点eij=(vi,vj)之间添加边,start≤i<j≤end,其中包含最外层实体信息;G1中,主要是对于句子中相邻实体字符,从左到右添加一个有向边,从而可以利用局部上下文信息。


图5 G1 实体相邻图Fig.5 Entity adjacent graph (G1)

图6 G2 实体关系图Fig.6 Entity relationship graph (G2)
通过GCN 获取图特征F={f1,f2,…,fN}后,可以求得内层的实体得分M∈RN×N×L:

式中:W1,W2∈,W3∈Rdf×L,L为实体类型数量;Mij∈RL表示范围的类型概率从ti开始到tj结束。 对于内部实体,将字符(ti,tj)中的真实实体定义为,ti为起点,tj为终点。 计算交叉熵(cross entropy)得
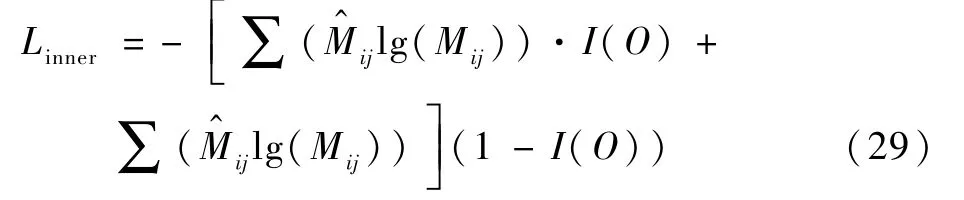
式中:I(O)用来区分非实体“O”和其他实体类型的损失,定义如下:

对于外层实体,采用CRF 计算损失,CRFX为外部模块获取的最外层实体损失,CRFXnew为经过GCN 提取后的最外层实体损失:

模型预测最外层实体和内部实体,损失定义为

式中:λ1为外部模块和内部模块损失之间的权重。
2.7 实体校正模块
校正模块属于后处理内容。 神经网络最后的输出结果一般为字符对应各个类型的分数。 由于模型预测的部分结果并不准确,即使经过CRF 处理,也依然会出现一些实体类型正确而边界判断错误的情况。 假设网络经过一系列运算后,最终得到的是一个m×n的向量,m为当前输入模型的句子长度,n为实体类型数量,则该m×n的向量是模型对这一语句每个字所属类型的评分,最高评分所在列的索引就是模型预测的实体类型。
实际预测结果中,会出现一些实体类型正确而边界判断错误的情况。 以图7 中“轻水堆”为例,预测结果为“9 9 9”(对应标签为“I-REA I-REA I-REA”),对照表2,该实体属于“反应堆类”,实体类型判断正确,但“轻水堆”的实际类型应该是“8 9 9”(对应标签为“B-REA I-REA IREA”)。

表2 实体类型编号对照Table 2 Table of entity type number

图7 核电语料实体类型对比Fig.7 Comparison of nuclear power corpus entity types
3 实验结果与分析
3.1 实验参数设置
实验中,随机划分60% 的语料作为训练集,20%作为测试集,20% 作为开发集。 字向量维度为50 维,迭代次数epoch 为50 次,梯度下降学习率为0.000 1,学习率衰减因子为0.8,使用Adam优化算法加快收敛速度,以交叉熵计算模型损失函数。
3.2 实验指标

模型评价采用准确率P、召回率R和F1值作为评价指标,其中F1值综合了准确率和召回率,可以体现模型的均衡性,各项指标计算公式为进行比较。 结果表明,本文模型在各项指标均优于其他模型。 与本文模型相比,常用的LSTM 模型[12]对于Nested NER 预测效果差,无法对文中的实体进行准确识别;BiFlaG[25]的侧重点偏向于实体间的关系,忽略了句子中上下文信息的提取;BiLSTM +CRF[13]对Nested NER 所占比例大的语料中命名实体的分词能力有限,无法获取实体与实体之间的关系;MGNER 模型[24]中预测实体后,根据实体内部关系进行细粒度判断,这样的判断方式更加适用于英文。
总的来看,本文模型相较MGNER,P提高6.31%,R提高7.6%,F1提高6.95%;相较BiFlaG,P提高9.52%,R提高8.51%,F1提高9.02%,网络各方面性能均优于其他网络。
表4 对BiFlaG 模型和MGNER 模型在核电数据集中的4 种分类进行了详细比较。 从结果来看,3 个模型对“专有名词类”(NOU)的识别准确率最高,而“燃料与材料类”(FUE)识别准确率较差。 从数据的角度分析这一情况,在“专有名词类”实体中,Nested NER 在文本中的词频较低,因而在训练过程中对网络判断造成的干扰不大,结果正确率普遍较高;“燃料与材料类”的实体识别效果不佳,是由于该类命名实体在文本中,数量及出现频率都低于其他3 类,直接导致在神经网络训练过程中,神经网络对该类命名实体类型判断出现误判,导致准确率较低。

表4 分类结果对比Table 4 Comparison of classification results %
式中:TP 为正类预测为正类数;TN 为负类预测为负类数;FP 为负类预测为正类数(误报);FN 为正类预测为负类数(漏报)。
3.3 实验结果比较
表3 将本文模型与其他模型在核电数据集中
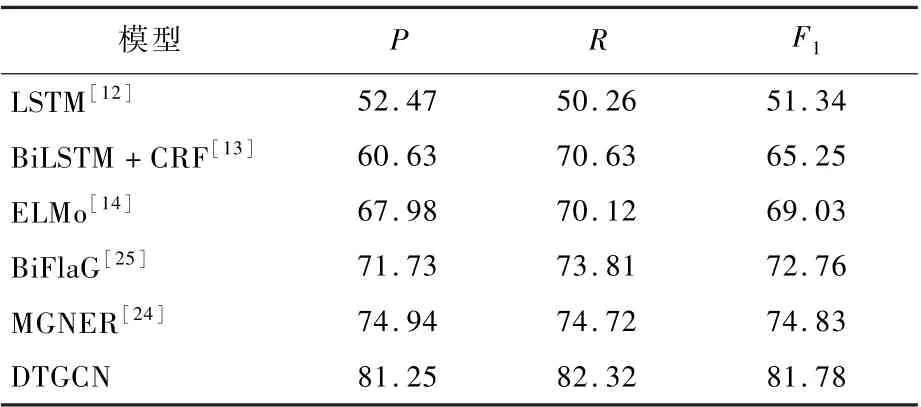
表3 模型实验结果对比Table 3 Comparison of model experimental results%
3.4 消融实验
本文使用ELMo 从句子的角度获取实体信息,用Self-Attention 获取实体与句中其他实体的依赖关系,校正模块则将模型预测结果中实体类型正确而边界判断错误的情况进行校正。 本节进行消融实验验证其有效性。 表5 中,“①”指本文模型本身;“②”指Self-Attention,不含ELMo与校正模块;“③”指ELMo,不含Self-Attention 与校正模块;“④” 指校正模块,不含Self-Attention 与ELMo;“⑤”指Self-Attention 与校正模块;“⑥”指校正模块与ELMo;“⑦”指Self-Attention 与ELMo。总的来看,自注意力模块对网络的准确率P提高为1.03%;ELMo 对网络准确率P提高为1.81%;校正模块对网络准确率P提高为2.96%。
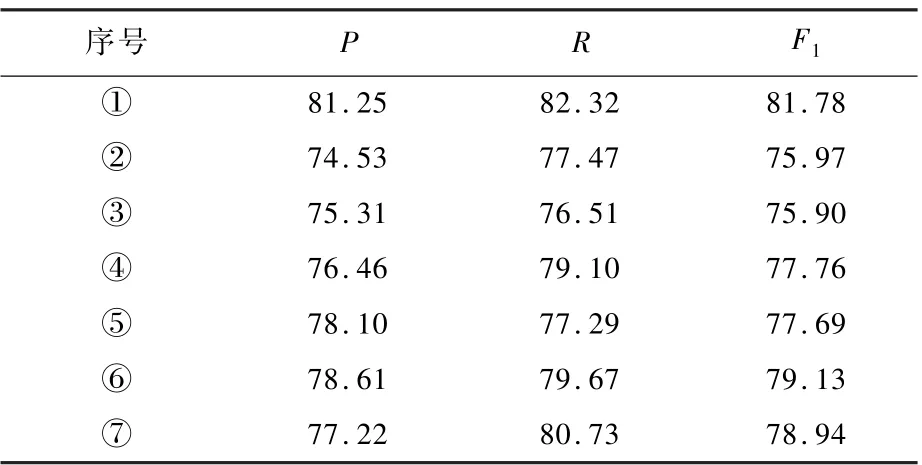
表5 消融实验结果Table 5 Experimental results of ablation %
4 结 论
1) 本文完成了数据搜集工作,其主要来源是反应堆热工分析与反应堆物理分析,这些数据在很大程度上可以代表核安全文本的数据特征,且不涉密、资料多,是理想的研究对象。
2) 完成了数据的分类工作,主要分为“专有名词类”、“冷却与冷却剂类”、“燃料与材料类”与“反应堆类”四大类。 “冷却与冷却剂类”实体数量最多,有1 365 个,“燃料与材料类”实体数量最少,仅207 个。 同时完成了语料的标注工作,标注数据8 023 句141 057 条。
3) 通过对比实验,验证多个网络在当前数据集中的性能。 结合研究中遇到的嵌套命名实体问题,在现有研究的基础上进行改进,得到DTGCN网络。 网络中包含外部模块和内部模块,2 个模块分别学习外部实体信息和内部实体信息,结合规则判定的方法对实体类型正确而边界判断错误的预测结果进行校正。 实验结果表明,本文模型对于嵌套命名实体的识别效果优于其他模型,在准确率与召回率指标上提升显著,如较BiFlaG 模型,准确率提高9.52%,召回率提高8.51%,F1值提高9.02%。
猜你喜欢
通信技术(2021年12期)2022-01-25
中国核电(2021年3期)2021-08-13
中国核电(2021年3期)2021-08-13
中学生数理化(高中版.高考理化)(2021年2期)2021-03-19
中国核电(2020年2期)2020-06-24
计算机应用与软件(2018年9期)2018-09-26
东方女性(2018年3期)2018-04-16
散文诗(2017年17期)2018-01-31
中国核电(2017年1期)2017-05-17
外语教学理论与实践(2014年2期)2014-06-21
