
基于Spark平台的异常流量实时检测
2024-01-27 16:44阎红灿王小雨刘盈
电脑知识与技术 2023年36期
阎红灿 王小雨 刘盈

摘要:传统的流量检测方法在大规模、大流量网络环境下不能满足对异常流量检测的准确性和实时性要求,基于此,该文构建了一个基于spark平台的分布式流量实时检测模型。该模型使用LibPcap、Flume、SparkStreaming实现分布式流量采集、上传和实时计算,以满足大流量场景下实时性需求;通过CNN网络提取流量载荷内容特征和双向流量统计特征,基于Stacking算法进行模型融合,提高了检测准确性;使用CIC-IDS-2018数据集对该模型进行了测试。实验结果表明,该模型能够满足大流量环境下异常流量检测的准确性和实时性要求。
关键词:SparkStreaming;分布式流量检测;CNN;Stacking;模型融合
中图分类号:TP393 文献标识码:A
文章编号:1009-3044(2023)36-0062-04
开放科学(资源服务)标识码(OSID)
0 引言
随着网络技术的发展,针对互联网的攻击手段愈来多样化,其所带来的威胁也在不断提升,对流量进行异常检测也越显必要。当前的入侵检测模型主要有基于统计分析的检测方法[1-3],对流量特征进行统计分析并建立特征庫,通过对比特征库的方式来识别异常流量;基于分类的检测方法[4-7],通过训练分类器来识别正常和异常流量;基于聚类的检测方法[8-11],通过相似度和聚类将流量数据聚合成不同的类来达到流量检测的目的,属于无监督学习算法。
无论是基于统计、分类还是聚类的检测方法,都需要提取好流量的特征才能进行下一步工作,因此需要解决大量数据处理的问题。作为一个分布式计算平台,Spark具有高性能、低延迟、可扩展等特性[12],非常适合处理大量流量数据,而且基于机器学习的流量检测方法具有准确率高、扩展性强等特点。本文将二者结合起来,设计一个异常检测模型可满足海量流量环境下对准确率和实时性的要求。
1 相关知识概述
1.1 处理大流量数据相关技术
1)Spark
Spark是一个基于内存的并行计算框架[13],其核心组件有分布式图计算框架GraphX、结构化数据查询模块SparkSql、实时流计算引擎SparkStreaming[14]、机器学习模块MLib。其中,SparkStreaming 是为了解决大数据环境下的实时计算而诞生的,它引入了DStream作为抽象数据表示,存储的是伴随着时间窗口变化的数据序列,支持对数据流通过map、join、reduce、window等函数进行复杂的实时计算,为异常检测模型提供了流量清洗和实时计算的功能。
2)Flume
Flume是一个基于数据流的分布式日志采集、聚合和传输系统[15],具有高可用、高可靠等特点。Agent是Flume的核心组件,包括Source、Sink、Channel三个部分。Source用来收集数据并将数据序列化成Event,之后Channel将经过序列化的数据Event进行缓存,再由Sink将数据发送到目的地。每一个Flume采集服务由许多Agent串联形成,在异常检测模型中扮演流量采集和上传的角色。
3)Kafka
Kafka是一个基于发布-订阅的分布式消息服务[16],支持实时数据处理。Kafka包含Producer、Topic、Partition、Consumer等组件,Produce将数据发布到Topic,Consumer根据Topic从broker中读取数据。由于Kafka使用了磁盘顺序读写、零拷贝、批量压缩等技术,使其能够实现每秒几十万的超高吞吐量,适合大数据环境下的实时流处理,在异常检测模型中被用来缓存流量数据。
1.2 模型融合应用的机器学习算法
1)支持向量机
支持向量机是一种有监督的学习算法,其基本思想就是让支持向量到超平面的距离最大化。使用核函数来解决非线性问题,通过求解对偶拉格朗日函数来进行优化,其最后的决策函数如:
[y=signi=1mj=1mαiαjyiyjkxi,xj+b] (1)
其中,
2)逻辑回归
逻辑回归是一个基于概率的分类算法,常被应用于二分类问题,也可以被扩展多分类模型,其在线性回归的基础上加入了Sigmoid函数,使最终的预测值落于[0,1]区间,从而达到分类的目的。Sigmoid 函数如下:
[fx=11+e-x] (2)
3)随机森林
随机森林是利用bagging策略将多个决策树组合进行分类预测的一种算法单一预测效果准确率可能不高,通过多棵不相关的决策树组成一个随机森林,当需要对新样本预测时,让每个决策树都进行预测,然后通过投票加权的机制,选出最终的预测结果,达到提高预测准确度的效果。
4)决策树
决策树是一种树形结构的监督学习算法[17],其叶子节点代表一种预测结果,中间节点代表一种决策,构建算法有C4.5、ID3、CART三种。本文采用CART算法去构建决策树。CART算法使用二叉树去构建决策树,使用最小基尼系数去进行特征选择。基尼系数公式如下:
[GiniD=1-k=1KCkD2] (3)
[GiniD|A=D1DGiniD1+D2DGiniD2] (4)
其中,|D|表示数据集D的数据总量,D1和D2则表示子样本集。
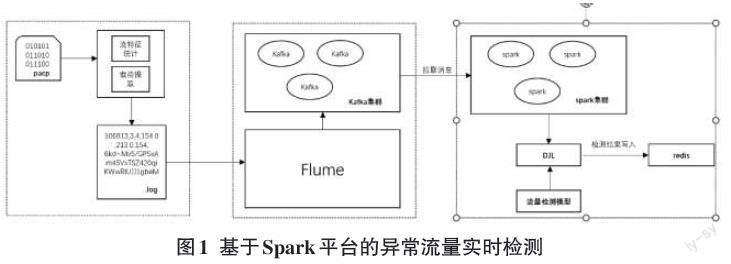
2 基于Spark的异常流量检测框架
本文提出的基于Spark的检测框架共分为网络流量获取与流量特征提取、流量日志的传输、流量实时检测三个部分。
1)网络流量获取與流量特征提取
通过LibPcap去监听网卡,实时生成Pcap格式数据包,通过CICflowmeter提取流量的数据流统计特征和载荷内容,按当前日期(年-月-日)生成日志文件。
2)流量日志的传输
通过Flume,将日志文件上传到Kafka消息队列中。
3)流量实时检测
SparkStreaming[18]与Kafka集群对接,将获取流量数据载入生产DStream并进行预处理,通过DJL(DJL是一个开源的、无关引擎的Java深度学习框架,提供了一个统一的调用接口,可以用来部署各种深度学习和机器学习模型)去调用训练好的检测模型预测流量,最终将检测结果存储到redis集群中。
3 基于Spark的分布式异常流量检测模型
3.1 数据集特征提取及预处理
数据集选用CIC-IDS-2018[19],该数据集类似实际的攻击数据,包含了最新的常规攻击流量,其数据采集于周一至五。其中,周一为正常流量,周二至周五的上午和下午分别采集了暴力FTP、DOS、Heartbleed、Web攻击、渗透、僵尸网络、DDoS攻击。
对CIC-IDS-2017数据集中共计48G的Pcap文件,使用CICflowmeter提取83个流量特征和流量前784字节有效载荷。将载荷经过Base64编码和流量特征一起写入csv文件中。通过Spark框架去加载和预处理提取好的csv文件,由于数据中存在少量的Nan和Infiniti的脏数据,因此删除包含脏数据的向量。提取的数据集攻击类型及数量如下表1所示。
由于提取的流量特征中包含不同的量纲和数量集,所以对提取流量特征进行了均值方差归一化处理。公式如下:
[x*=x-μδ] (5)
其中,μ为所有样本数据的均值,σ为所有样本数据的标准差。
3.2 基于CNN网络载荷特征和流统计特征融合
CNN是一种为处理多维数据特别设计的前馈神经网络[20],通常由卷积层、全连接层三部分组成。
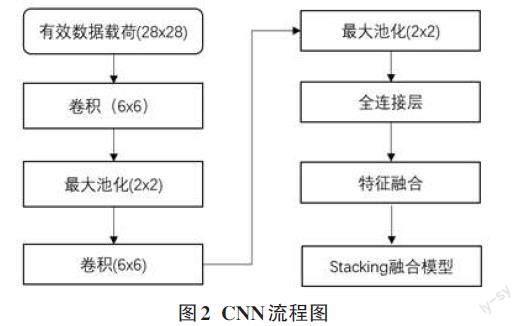
本方案提出的检测模型的输入有两个,分别为83维的流量统计特征和784字节的有效载荷内容。将784字节的有效载荷内容看作成28×28的数字矩阵输入CNN网络生成载荷空间特征,然后再与流量统计特征融合生成融合特征向量。其流程如图2所示。
1)将784字节的有效载荷处理28×28图像矩阵。
2)卷积层使用4×4的卷积核,步长取1,对输入的载荷矩阵做卷积运算,得到相应的特征图,然后再使用RELU函数对特征图进行处理。
3)将池化层窗口大小设置为2×2,步长设置为1,降维激活层得到特征图。
4)将得到的72维有效载荷特征与统计特征进行融合处理,然后使用融合特征训练分类模型。
3.3 Stacking集成学习检测模型
模型训练的目的是稳定并且在各个方面都表现良好的模型,但现实中的情况往往不理想。如果使用单一的机器学习算法对融合特征数据进行训练,由于每个机器学习算法有各自优缺点,可能会得到一个在某些方面比较有良好效果的弱分类模型。集成学习原理是训练多个单一模型,然后再通过一个策略将其组合起来,即便其中存在某个弱分类器,也能通过其他分类器将其错误预测结果纠正回来。
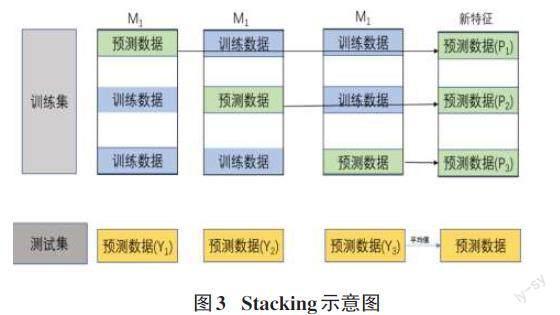
本文使用Stacking[21]集成策略训练分类模型。Stacking集成策略的原理是使用数据集分别训练基学习器,然后将数据集输入训练好的基学习器中得到次级训练数据集。最后,再将得到的次级训练数据集输入次级学习器中,得到最终的分类模型。但这样得到的次级训练数据集往往会出现过拟合现象,因此,常常会使用K折交叉验证的方法来防止出现过拟合现象。本文中设计的Stacking算法使用了3折交叉验证的方法,其流程如图3所示,将训练数据集均匀划分成3份,每次取两份训练数据集输入基学习器进行训练,将剩余的一份预测数据输入训练好的模型中得到新的预测数据Pi ,同时对测试数据进行预测,将其结果记为Yi,依此重复3次,将得到的Pi堆叠得到新的特征值记为P,得到的Yi进行加权平均得到新的测试集Y。如果拥有N个基分类器,可以得到N个Y和P,然后将P1,P2,…,Pn按照列进行拼接得到一个N列的训练数据矩阵,将Y1,Y2,…,Yn按照列进行拼接得到一个N列的测试数据矩阵,使用次级分类器对新的训练集和测试集进行训练和预测,最终得到预测结果。
本文使用的基学习器为支持向量机、SVM、随机森林,次级学习器选择了逻辑回归,使用的数据为流统计特征和载荷特征融合后的数据集,并使用Python中的Sklearn库去训练模型,相关算法如下。
[基于3折交叉验证的Stacking算法 输入:训练数据集[D={x1,y1,x2,y2,x3,y3}];初级学习器C1,C2,C3,次级学习器C。
输出:[Hx=h'h1x,h2x,h3x]
[1.for i=1,2,3 do]
[2. hi=CiD]
[3.end for]
[4.D'=∅]
[5.for i=1,2,3 do]
[6. for j=1,2,3 do]
[7. pij=hjxi]
[8. end for]
[9.D'=D'∪pi1,pi2,…,pij,yi]
[10.end for]
[11.h'=CD'] ]
4 實验结果
4.1 实验环境
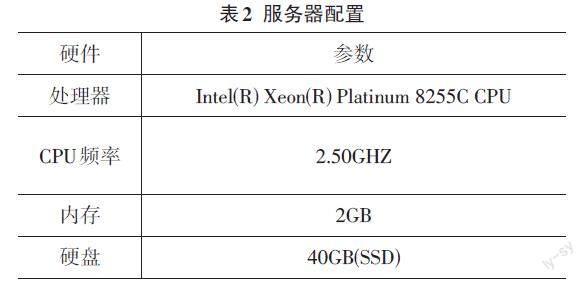
实验环节使用了3台Linux 服务器搭建分布式系统框架,单台服务器的配置如表2所示。
4.2 评价指标
结果测试使用召回率(Recall)、F1值、准确率(Accuracy)、精确率(Precision)对模型进行评估。其公式分别为:
[Recall=TPTP+FN] (6)
[F1=2×Precision×RecallPrecision+Recall] (7)
[Precision=TPTP+FP] (8)
其中,TP代表模型正确预测为正的正样本,FN代表模型错误预测为负的正样本,FP代表模型错误的预测为正的负样本,TN代表被模型正确的预测为负的负样本。
4.3 实验结果与分析
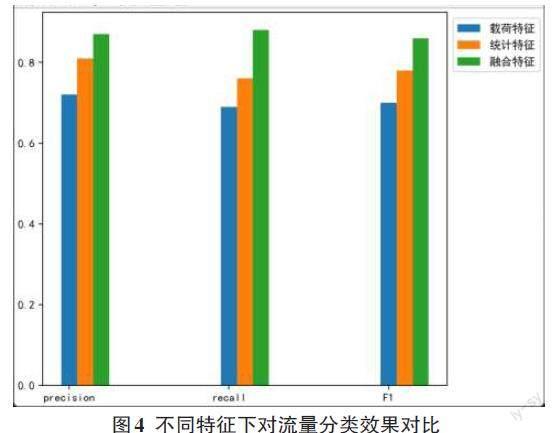
1)特征融合前后对比
选取20%的样本集作为测试集,80%样本作为训练集进行训练,同时把流量统计特征和内容载荷特征分成两个特征子集,并设置3组实验对照,分别为只使用统计特征、只使用载荷特征和使用融合的统计特征和载荷特征,其目的是证明融合特征要比单一特征的分类效果更好,其结果如图4所示。
实验结果表明,融合特征下,对流量识别的效果要优于未经融合的特征,其精确率达到了87.7%。
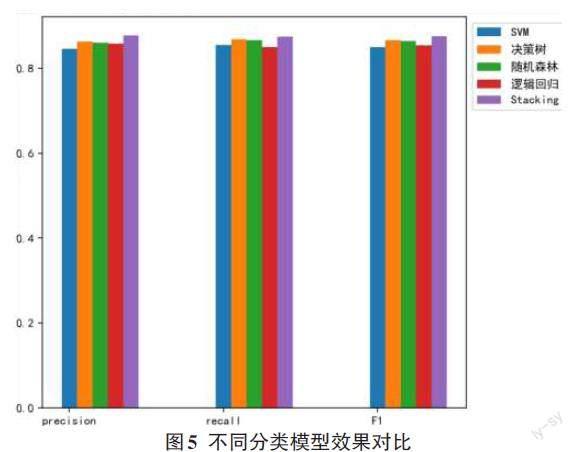
2)模型分类对比
文章对支持向量机、决策数、随机森林、逻辑回归和Stacking融合模型的分类效果进行了对比,其目的是验证Stacking模型的分类效果要优于其他单一分类模型,其结果如图5所示。
实验结果表明,Stacking融合模型的分类效果要优于其他单一模型。
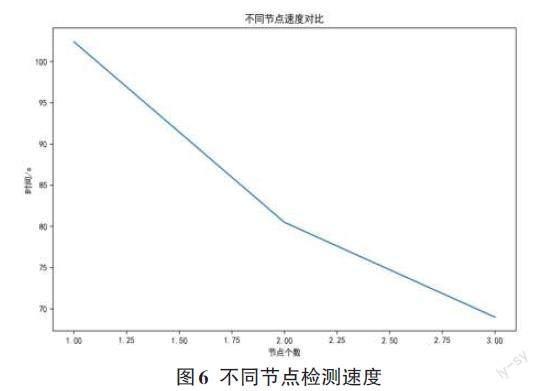
4.4 检测速度分析
为了测试检测框架在分布式集群上的速度,分别测试了在1、2、3个节点下检测1GB流量数据所需要的时间。可以看出,随着节点的增加,检测速度越来越快,可以得出分布式架构可以通过增加机器的方式来提高系统的吞吐量和速度,具有很好的扩展性。
5 结束语
本文利用CICflowmeter工具提取了CIC-IDS-2017数据集的流量统计特征和有效载荷,通过CNN网络提取有效载荷数据特征,并融合流量统计特征训练了流量异常检测模型。为了应对海量数据情形,文章结合了Spark、Kafka等大数据中间件处理流量数据和部署模型。最后通过实验测试,证明了检测模型的实时性和准确性。
该检测框架还有许多问题,例如如何进一步提升模型的预测准确度,如何优化Kafka集群获取更高的吞吐量,如何优化Spark集群进一步提升计算能力,这些问题还有待解决。
参考文献:
[1] DESFORGES M J,JACOB P J,COOPER J E.Applications of probability density estimation to the detection of abnormal conditions in engineering[J].Proceedings of the Institution of Mechanical Engineers,Part C:Journal of Mechanical Engineering Science,1998,212(8):687-703.
[2] SOULE A,SALAMATIAN K,TAFT N.Combining filtering and statistical methods for anomaly detection[C]//Proceedings of the 5th ACM SIGCOMM conference on Internet measurement - IMC '05.October 19-21,2005.Berkeley,California.ACM,2005:31.
[3] PASCOAL C,DE OLIVEIRA M R,VALADAS R,et al.Robust feature selection and robust PCA for Internet traffic anomaly detection[C]//2012 Proceedings IEEE INFOCOM.Orlando,FL,USA.IEEE,2012:1755-1763.
[4] SANTOS DA SILVA A,WICKBOLDT J A,GRANVILLE L Z,et al.ATLANTIC:a framework for anomaly traffic detection,classification,and mitigation in SDN[C]//NOMS 2016 - 2016 IEEE/IFIP Network Operations and Management Symposium.Istanbul,Turkey.IEEE,2016:27-35.
[5] 李泽一,王攀.基于代价敏感度的改进型K近邻异常流量检测算法[J].南京邮电大学学报(自然科学版),2022,42(2):85-92.
[6] 郑黎明,邹鹏,贾焰,等.基于多维熵序列分类的骨干网上流量异常检测[J].中国通信,2012,9(7):108-120.
[7] 庄政茂,陈兴蜀,邵国林,等.一种时间相关性的异常流量检测模型[J].山东大学学报(理学版),2017,52(3):68-73.
[8] SATOH A,NAKAMURA Y,IKENAGA T.A flow-based detection method for stealthy dictionary attacks against Secure Shell[J].Journal of Information Security and Applications,2015,21:31-41.
[9] 宗文泽,吴永明,徐计,等.基于DTW-kmedoids算法的时间序列数据异常检测[J].组合机床与自动化加工技术,2022(5):120-124,128.
[10] 史小艳,陈松灿.基于单簇聚类的非对齐多视图异常检测算法[J].中国科学:信息科学,2021,51(12):2037-2052.
[11] 吴英友,胡刚义,唐静,等.基于两阶段聚类的设备状态异常检测方法[J].舰船科学技术,2021,43(15):163-168.
[12] ALEXEEV B,CAHILL J,MIXON D G.Full spark frames[J].Journal of Fourier Analysis and Applications,2012,18(6):1167-1194.
[13] ZHANG Z H,LIU Z F,LU J F,et al.The sintering mechanism in spark plasma sintering - Proof of the occurrence of spark discharge[J].Scripta Materialia,2014,81:56-59.
[14] ZAHARIA M,XIN R S,WENDELL P,et al.Apache spark[J].Communications of the ACM,2016,59(11):56-65.
[15] BALAANAND M,KARTHIKEYAN N,KARTHIK S.Envisioning social media information for big data using big vision schemes in wireless environment[J].Wireless Personal Communications,2019,109(2):777-796.
[16] NOGHABI S A,PARAMASIVAM K,PAN Y,et al.Samza[J].Proceedings of the VLDB Endowment,2017,10(12):1634-1645.
[17] LASHKARI A H,DRAPER-GIL G,MAMUN M,et al.Characterization of Tor Traffic using Time based Features C].ICISSp,2017: 253-262.
[18] GIL J A,SENDYK M.Spark model for pulsar radiation modulation patterns[J].The Astrophysical Journal,2000,541(1):351-366.
[19] 杭夢鑫,陈伟,张仁杰.基于改进的一维卷积神经网络的异常流量检测[J].计算机应用,2021,41(2):433-440.
[20] JI S W,XU W,YANG M,et al.3D convolutional neural networks for human action recognition[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2013,35(1):221-231.
[21] 李颖之,李曼,董平,等.基于集成学习的多类型应用层DDoS攻击检测方法[J/OL].计算机应用,2022:1-9.(2022-04-19).https://kns.cnki.net/kcms/detail/51.1307.TP.20220416.0837.00
【通联编辑:代影】
猜你喜欢
黄河之声(2022年10期)2022-09-27
玩具世界(2022年2期)2022-06-15
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
房地产导刊(2021年8期)2021-10-13
数学小灵通(1-2年级)(2021年4期)2021-06-09
中学生数理化·七年级数学人教版(2019年4期)2019-05-20
中学生数理化·七年级数学人教版(2018年6期)2018-06-26
自动化博览(2014年12期)2014-02-28
