
一种基于鲸鱼优化算法的网络流量组合预测模型
2024-01-27 16:44李诗雅田中大
电脑知识与技术 2023年36期
李诗雅 田中大
摘要:现代网络流量的自相似性、周期性、混沌性、多尺度性和其他特性使得预测网络流量具有挑战性。因此,该文提出了一种基于鲸鱼优化算法(WOA)的变分模态分解(VMD),结合了随机配置网络(SCNs)对网络流量进行预测。首先,该文对网络流量数据集进行VMD分解,同时引入WOA对VMD分解中分解个数K和惩罚参数α进行优化。其次,利用SCNs模型对分解后得到的分量进行预测,最后,累加每个分量的预测结果,得出最终网络流量预测值。该组合预测模型(WOA-VMD-SCNs)旨在提高网络流量预测的准确性,对实际收集的网络流量数据进行预测,验证本文提出模型的有效性。
关键词:网络流量预测;鲸鱼优化算法;变分模态分解;随机配置网络;组合预测模型
中图分类号:TP273 文献标识码:A
文章编号:1009-3044(2023)36-0066-04
开放科学(资源服务)标识码(OSID)
0 引言
中国互联网信息中心于2023年3月发布《第51次中国互联网络发展状况统计报告》中提到,截至2022年12月,全国网民数量为10.67亿,比2021年12月增加了3 549万,达到75.6%的网络普及率[1]。此外,全年移动互联网接入流量达2 618亿GB。网民数量的增长带来网络流量的激增,随着智能手机的普及和大多数人使用流量数据的计划以及视频、游戏等各种大流量网络应用的快速发展,数据流量呈指数型增长,网络流量负荷急剧增加,网络拥塞时有发生,网络流量可以反映整个网络的运行状态和资源状况[2]。为了管理这种爆炸性增长,需要准确的网络流量预测来规划网络容量。在分配网络资源的过程中,传统的基于业务运行状况的资源配置方式由于缺少对未来业务运行状况的预测,极易造成网络拥塞和资源浪费。对网络流量进行精确的预测有助于运营商尽早对可能发生的拥塞做出反应,并在此之前对网络进行扩容、调整和优化[3]。在缺乏快速准确的网络流量预测模型的情况下,网络运营商将面临风险。因此,网络流量的建模和预测对于有效的网络流量管理是必要的。
成功预测网络流量的关键在于模型的选择和设计,目前有三种预测模型:线性、非线性和组合模型。大多数传统的线性时间序列预测模型由自回归模型、自回归移动平均模型和自回归综合移动平均模型组成,虽然这些方法的模型简单,计算复杂度低,处理速度快,但预测模型不可避免地会产生明显的预测误差。它们不能反映准确的网络服务的突发性和长期性的相关性,并且其参数的设置需要人工经验获得,仅限于短期流量数据。线性模型对实现精确预测具有挑战性。相比之下,非线性系列预测模型能有效地跟踪复杂的系统。非线性预测模型正在变得越来越广泛,如支持向量机(SVM)、灰色模型(GM)、神经网络和深度学习。SVM的预测精度在很大程度上取决于核参数,适合于小样本;GM的高预测精度只适合于具有稳固规律性的流量数据。神经网络具有良好的自组织和自学习能力,能够很好地描述网络流量数据的非线性特征。然而,神经网络训练过程中的输入节点数量、输出节点数量、网络层数量、每个层中的节点数量以及其他设置方法没有明确的理论基础,通常是基于经验来设置这些超参数。基于深度学习的回归预测模型的训练成本很高,这需要大量的训练样本和时间来达到令人满意的程度。上述线性或非线性模型均为单一预测模型,传统的线性和非线性模型不足以描述流量的多尺度特征,从而影响了预测的准确性。因此,当前的研究倾向于关注组合模型,而不是传统的线性和非线性模型。一般来说,组合预测模型包括两个以上的预测模型,并且可以组合一些分解算法或优化算法。总体而言,网络流量组合预测模型是一个值得深入研究的方向,具有一定的竞争力。
本文使用了VMD算法对网络流量数据进行分解,VMD算法可以降低复杂度高和非线性强的时间序列非平稳性,分解获得包含多个不同频率尺度且相对平稳的分量,适用于非平稳性的序列。首先,本文采用WOA优化VMD参数的方法,降低分解个数K和惩罚参数α对分解效果的影响。其次,利用SCNs模型对分解后的分量进行预测,SCNs具有良好的学习和泛化性能,对非线性映射具有良好的逼近能力,最后,累加每个分量的预测结果,得出最终网络流量预测值。
1 相关理论概述
1.1 VMD分解
VMD是一种新的自适应信号处理算法,该算法假设信号是由具有不同中心频率的调幅和调频信号的多个模态函数叠加而成。使用变分法最小化每个本征模态函数的估计带宽之和。将本征模态函数解调到相应的基带,最后提取本征模态函数和相应的中心頻率[4]。对于原始信号[ft],带约束的变分问题模型可以描述为
[minuK,ωKK∂tδ(t)+jπt*uK(t)e-jωKt22 s.t. KuK=f] (1)
式中[uK=u1,u2,…,uK]为各模态函数的K阶函数,[ωK=ω1,ω2,…,ωK]为各模态函数的中心频率;[δt]是脉冲函数。
为了找到上述约束问题的最优解,利用拉格朗日乘法算子λ将约束变分问题转化为无约束变分问题,如式(2)所示:
[LuK,ωK,λ=αK∂tδ(t)+jπt*uK(t)e-jωKt22+f(t)-KuK(t)22+λ(t),f(t)-KuK(t)] (2)
其中,[α]是次要惩罚因子。
利用乘子交替方向法求解方程(2),得到最优解。
VMD分解的主要步骤如下:
步骤1:初始化各模态函数和中心频率,给出[u1K]、[ω1K]和[λ1]。将各模态函数从时域变换到频域并设[n=0]。
步骤2:[uK]的更新公式为
[un+1K(ω)←f(ω)-i≠Kui(ω)+λ(ω)21+2αω-ωK2] (3)
其中,[uK(ω)],[f(ω)]和[λ(ω)]分别是[uK]、[ft]和[λ]的傅里叶变换。
步骤3:[ωK]的更新公式为
[ωn+1K←0∞ωuK(ω)2dω0∞uK(ω)2dω] (4)
步骤4:[λ]的更新公式为
[λn+1(ω)←λn(ω)+τf(ω)-Kun+1K(ω)] (5)
其中,τ为迭代因子。
步骤5:收敛精度[ε>0],迭代终止条件如下:
[Kun+1K-unK22unK22<ε] (6)
如果满足式(6)的条件,终止迭代,输出最终结果;否则,返回到步骤2继续迭代。
从VMD分解步骤可以看出,在分解信号之前需要确定分解次数K和惩罚参数α,因为K的数值直接影响信号序列的分解效果,K值偏大会造成信号过分解,K值偏小会造成欠分解,α的数值高会导致信息的损失,相反又会导致信息的冗余。因此,确定K和α的最佳参数是必要的。目前,确定K值的最常用方法是在不同的K值下观测中心频率。然而,这种方法存在一定的随机性,且不能确定惩罚参数α。因此,本文提出以包络熵的极小值为适应度函数的WOA算法优化VMD参数。包络熵反映了原始信号的稀疏特征,因此当IMF包含较多的噪声和较少的特征信息时,包络熵的值较高,反之,包络熵的值较低。
信号[α(i)(i=1,2,…,N)]的包络熵Ep由式(7)表达,其中,[φ(i)]为VMD分解的模态分量经过希尔伯特解调后的包络信号,[μ(i)]是[φ(i)]的归一化得到的概率分布序列,N为样本数,对[μ(i)]的熵值进行运算,就是包络熵Ep。
1.2 WOA算法
WOA是一种基于鲸鱼捕猎猎物行为提出的算法。在鲸鱼算法中,每只鲸鱼的位置代表一个可行的解决方案。该算法主要包括三个阶段:包围猎物、螺旋泡网觅食、搜索猎物。在一群鲸鱼的狩猎过程中,每只鲸鱼都有两种行为:一种是包围猎物,所有鲸鱼都向其他鲸鱼移动;另一个是气泡网,即鲸鱼以圆周运动,并喷出气泡驱赶猎物。在每一代中,鲸鱼都会随机选择这两种行为来捕猎。在鲸鱼围绕猎物的行为中,鲸鱼会随机选择这两种行为来完成狩猎。
1)包围猎物
在鲸鱼正式捕食前,需要估计猎物的位置,而鲸鱼的位置可以被视为要优化的问题的解决方案。当领头的鲸鱼确定猎物的位置时,通过鲸鱼与鲸鱼之间的信息传递,其他鲸鱼也会游到目标位置,然后不断更新位置。
[D=C⋅X∗(t)-X(t)] (8)
[X(t+1)=X∗(t)-A⋅D] (9)
其中,t表示当前迭代,[X∗(t)]表示t代鲸鱼确定的猎物的最佳位置矢量,[X(t)]表示其他鲸鱼种群的个体位置向量,D表示头鲸和猎物之间的关系,A和C是控制参数向量。
2)螺旋泡网摄食策略
鲸鱼捕食的另一种方式是首先估计猎物与自己的距离,然后慢慢接近猎物的位置。当到达猎物的位置时,会吐出螺旋状的气泡来诱捕猎物。
[D=X∗(t)-X(t)] (10)
[X(t+1)=D⋅ebl⋅cos(2πl)+X∗(t)] (11)
其中,[D']表示猎物到第[i]头鲸鱼的距离矢量参数,[b]表示螺旋常数,l是[-1,-2]的随机数。
由于鲸鱼正在捕食,围绕猎物和螺旋泡捕食这两种行为可以同时进行,两者发生的概率都为0.5,可以得到
[X(t+1)=X(t)∗-A⋅D, p<0.5D⋅ebl⋅cos(2πl)+X∗(t),p≥0.5](12)
其中,p是[0,1]的随机数。
除了气泡网方法,座头鲸还随机搜索猎物,擴大搜索范围,跳出局部最优状态。
3)搜索猎物
在WOA算法,每个参与捕猎的鲸是一个可行解X。在猎物搜寻阶段,依据鲸类捕食过程中的随机性,每只鲸类通过相互间的位置信息来更新下一代位置。通过随机搜索,可以获得较好的全局最优性。
[D=C⋅Xrand-X] (13)
[X(t+1)=Xrand-A⋅D] (14)
其中,[Xrand]是当前种群中随机鲸鱼的位置。
使用收敛因子A的绝对值选择更新位置的方式。当|A|<1时,鲸鱼进入环绕气泡模式以找到局部最优位置参数;当|A|≥1时,进入全局搜索以避免陷入局部最优。
WOA算法从一组随机解开始,在每次迭代中,鲸鱼根据它们选择的方式更新自己的位置。WOA具有全局优化的特点,并且可以自适应地改变灵敏度因子,使得WOA算法可以在包围猎物和捕食螺旋气泡网的两种状态之间轻松切换[5]。此外,WOA只有两个需要调整的内部参数,在实践中使用相对简单。同时,WOA算法可以在迭代过程中提供较高的收敛速度,避免陷入局部最优。
1.3 SCNs原理
Wang和Li于2017年提出了SCNs,区别于以往的随机权重神经网络,SCNs依赖于训练数据,通过有监督的方式,对隐参数进行自适应选取,并通过线性回归方法对其输出权值进行评价,从而确保网络具有良好的收敛性。其优点是有较好的稳定性和泛化能力,有足够的学习能力,有良好的快速数据建模潜力。
对于有L-1个隐藏节点的N个样本,SCN 的输出如公式(15)所示。
[fL-1(x)=j=1L-1βjgjwTjx+bj] (15)
此刻的网络误差如公式(16)所示。
[eL-1=f-fL-1=eL-1,1,…,eL-1,m] (16)
SCNs首先构建了一个小型的网络,然后通过添加隐藏节点,逐步构建了一个学习模型。该算法依赖于训练样本的自适应选取输入权值和偏置范围,并使用了监督机制。具体如公式(17)所示。
[eL-1,q,gL2⩾b2gδL,q,q=1,2,…,m] (17)
其中,[δL,q=1-r-μLeL-1,q2], [0<∥g∥<bg]并且[bg∈R+]。
使用最小二乘法计算隐藏层的输出权重矩阵,如公式(18)所示。
[β1,β2,…,βL=argminβf-Lj=1βjgj2] (18)
SCN的基本模型如公式(19)所示。
[fL=fL-1+βLgL] (19)
SCNs的构建过程不是用固定的体系结构训练模型,而是从一个小规模的网络开始,递增地添加隐藏节点,直到达到可接受的容差,然后用当前的学习器解决全局最小二乘问题,以找到输出权重。
2 仿真实验
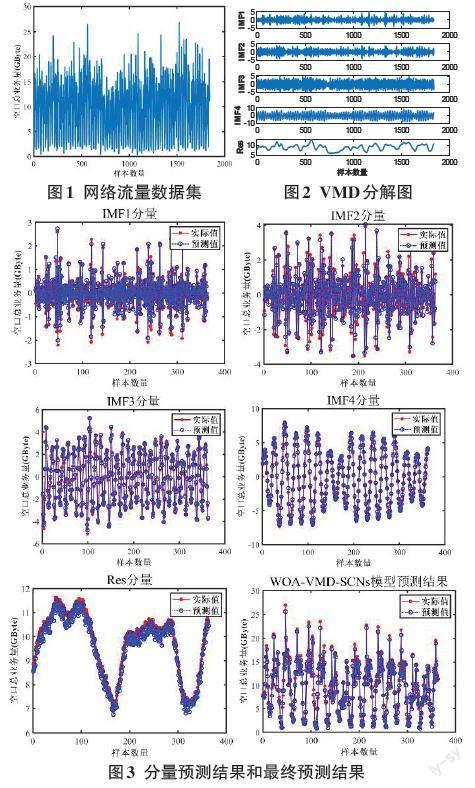
本文采用实际获得的网络流量数据集进行VMD分解,该数据集共收集了1 840组网络流量数据,所有数据均来自中国大连加工区内的大连开发区4G基站的每小时流量数据,数据收集期为2020年9月1日0:00至2020年11月16日15:00,采样时间间隔为1小时,每天24组,共76天,编号从1到1840。网络流量数据的可视化结果如图1所示。本文选择了1到1 472号的样本数据进行模型训练,1473到1 840号的样本数据用于模型验证。WOA基本参数设置情况为:种群数量设置为20,最大迭代次数设置为30,维度设置为2,适应度函数为包络熵,优化后的VMD最佳参数为K=5,α=100。VMD分解图如图2所示。利用相关系数可以有效分析IMF和Res分量与原始网络流量数据的相关性,通常相关系数小于0.1为虚假分量及噪声分量剔除标准。分解后的IMF分量和Res分量的相关系数分别为0.851,0.881,0.924,0.963和0.987。从中可以看出,每个分量与原始数据集的相关性都很高,证明了即使通过数据分解,原始网络流量数据仍具有较好的还原度,即每个分量仍然保留了原始数据的一些特征。通常,原始的网络流量序列由于各种因素而高度复杂。因此,本文利用VMD算法将复杂序列分解为几个简单的分量,所得到的分量具有比原始流量序列更简单的结构,VMD分解有效地减少了模型的复杂性,由分解结果可知,VMD分解出的高频成分变化趋势比较稳定,这对预测是有利的;低频分量虽然波动较大,但是这种误差是有限度的。由于最终预测值是各个分量预测值的累积,因此,VMD分解对预测的准确性具有重要意义。
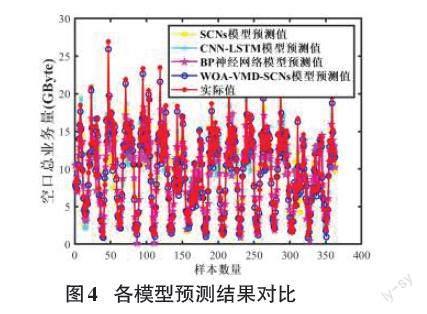
表3展示了SCNs模型预测的IMF和Res分量的预测结果,将各分量的预测结果叠加整合得到了最终网络流量预测结果。为了验证本文提出模型的有效性,分别与SCNs模型、CNN-LSTM模型和BP神经网络模型的预测结果进行对比。
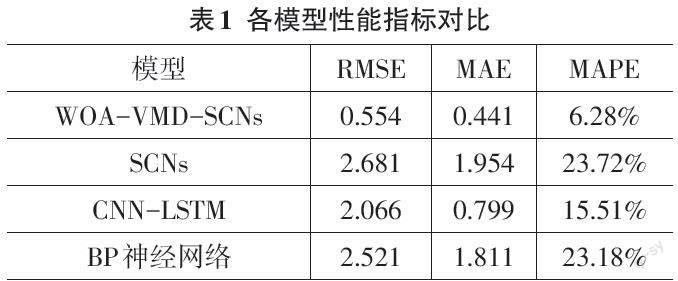
表1展示了各模型的性能指标,通过比较性能指标得出,与SCNs模型相比,基于WOA-VMD-SCNs预测模型的RMSE、MAE、MAPE指数分别下降了79.33%、77.43%、73.52%;与CNN-LSTM模型相比,本文提出的模型的RMSE、MAE、MAPE指数分别下降了73.18%、44.81%、59.51%;与BP神經网络模型相比,本文提出的预测模型的RMSE、MAE、MAPE指数分别下降了78.02%、75.64%、72.91%;从图4可以看出,与其他模型相比,本文所提出的模型表现良好,预测结果与实际验证数据基本吻合,所提出的模型能够精确地捕捉数据的模式。综上所述,基于WOA-VMD-SCNs预测模型显示出了良好的拟合效果和较低的预测误差。
3 结论
根据网络流量的特征,本文提出了一种WOA-VMD-SCNs的网络流量组合预测模型。其优势为:1)VMD通过独立选择模式分解的数量,分解的分量更具规则性,同时过滤掉噪声,提高了噪声鲁棒性,使后续的模型预测性能得到显著提高。2)引入WOA算法获得VMD分解的最佳参数。3)SCNs避免了局部极小值的存在,具有良好的泛化性能和显著的表示能力。与深度神经网络相比,SCNs具有更低的训练复杂度和更快的学习速度。
参考文献:
[1] 中国互联网络信息中心.第51次中国互联网络发展状况统计报告[R].北京:CNNIC,2023.
[2] SUN X C, WEI B, GAO J H, et al. Spatio-Temporal Cellular Network Traffic Prediction Using Multi-Task Deep Learning for AI-Enabled 6G[J]. Journal of BeiJing Institute of Technology, 2022, 31(5): 441-453.
[3] SELVI K T,THAMILSELVAN R.An intelligent traffic prediction framework for 5G network using SDN and fusion learning[J].Peer-to-Peer Networking and Applications,2022,15(1):751-767.
[4] XIONG B R,MENG X Y,XIONG G,et al.Multi-branch wind power prediction based on optimized variational mode decomposition[J].Energy Reports,2022,8:11181-11191.
[5] SAMANTARAY S,SAHOO A.Prediction of suspended sediment concentration using hybrid SVM-WOA approaches[J].Geocarto International,2022,37(19):5609-5635.
【通联编辑:代影】
