
基于质心的样本加权聚类算法
2011-01-10 03:36李志勇朱永缤
成都大学学报(自然科学版) 2011年2期
韦 相,李志勇,朱永缤
(红河学院计算机科学与技术系,云南蒙自 661100)
0 引 言
聚类分析在模式识别、图像处理、机器学习等领域有着广泛的应用,其也是数据挖掘的重要研究领域之一[1].目前,用于数据挖掘的聚类算法主要有4类:以 k-means算法为代表的分割聚类法,以BIRCH为代表的分层聚类法,以DBSCAN算法为代表的密度聚类法和STING为代表的网格聚类法[2-5].其中, BIRCH算法能够通过一遍扫描进行有效聚类,特别适合大规模的数据集,但该算法采用直径来控制聚类的边界,如果子簇非球形,则得不到较好的聚类效果;DBSCAN算法利用类的密度连通特性,可以快速地发现任意形状的簇,但它效率较低,无法进行动态聚类.本文在 k-means算法基础上提出了基于质心的样本加权的分割聚类算法,实验表明,该算法提高了聚类的精确度.
1 算法的具体描述
1.1 算法的基本思想
本文提出的聚类算法的基本思想是基于物质的质心及物质质心的运动定理.与 k-means聚类算法一样,本算法聚类的过程就是给每个样本寻找最近的质心(聚类中心),但与 k-means聚类算法不同,本算法中,质心不仅有位置信息,它还有质量,它的质量就是归入该聚类中心的样本的质量总和,当然,每个样本也有它自己的质量.聚类过程是给每个样本寻找最近的质心,当某个样本将归入某个质心时,该质心的质量就它原有的质量和新归入样本质量之和,同时该质心的位置也要根据物质质心的运动定理发生改变.某个样本原来属于某个质心,当它要离开该质心归入新质心时,原质心的质量及位置也发生相应的改变.
1.2 算法的定义
定义1 样本的特征:数据集的 n个d维样本(xi),i=1,2,…,n,样本的聚类特征CF有2个,CF =(mi,si),mi表示xi的质量,它是由xi的非空间属性决定,si表示xi的位置,由 xi的空间属性来表示.
定义2 聚类中心的特征:给定具有 n个样本的数据集(xi),i=1,2,…,n,子簇聚类中心的特征定义为2维CF=(M,S),M表示子簇的质量,它是属于这个子簇所有样本的质量总和;S表示子簇聚类中心的位置,它由属于这个子簇所有样本的质量和位置决定.

定义3 聚类中心的运动:给定具有 n个样本的数据集(xi),i=1,2,…,n,一个子簇含有n1个数据点,它的聚类中心特征是 CF=(M,S).
假定有一个新的数据点 y归入该子簇,那么该子簇的特征向量变化如下:

假定某个数据点原先属于这个子簇,现在要归入别的子簇,那这个子簇特征的变化如下:

1.3 算法的实现
本文提出的聚类算法其实现的基本步骤如下:

本算法和 k-means聚类算法的不同之处在于: k-means聚类算法在扫描完所有样本之后,才调整聚类中心,而本算法是扫描一个样本,就调整相关的聚类中心.本算法的具体描述如下:

1.4 样本的权重确定
1.4.1 使用非空间属性确定.
当对数据集中的样本没有任何先验知识时,可以直接定义每个样本的权重为1,这时,本算法的聚类效果 k-mean算法相似.本文提出确定样本权重的方法可根据一些先验知识,即2个样本的相异性的计算并不一定要依赖所有的属性,有些属性可以用来计算相似度,而有些属性则可从其他角度对聚类中心产生影响.
对给定具有 n个样本的d维数据集,(xi),i= 1,2,…,n,(包含d1个空间属性,可以用来计算相似度,d2个非空间属性,可以用来计算样本的权重),可以从相关领域专家那里获得每个非空间属性的权重wi,然后再按下式计算样本的权重,

1.4.2 使用样本密度确定权重.
在一些数据集中,当样本只有空间属性,而没有用于计算权重的非空间属性时,则可以用别的方法计算样本的权重.对那些处于稠密区域中的样本(即周围被更多样本包围),其必将对聚类中心产生更大的影响.对此,可采用点密码的思想:样本 p的Eps邻域密度,用N(p)表示,它表示在样本 p的Eps邻域的样本数目,用它作为样本 p的权重.
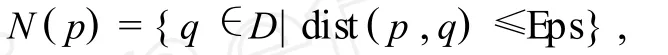
2 实 验
在实验中,我们将本文的算法和 k-means算法的聚类结果进行了比较.测试数据为 IRIS和Soybean-small数据(这2组测试数据都来自网站:http:// archive.ics.uci.edu,它们是用来进行聚类分析的标准数据集).IRIS有150个样本,分为3个子类,每类有50个样本,其中2个子类具有交叉的样本,很难对这些交叉样本进行准确的分类.
2.1 对IRIS数据的聚类结果
采用本文提出算法对IRIS数据的聚类结果见表1.采用 k-means算法对IRIS数据的聚类结果见表2.

表1 本文算法对IRIS的聚类结果

表2 k-means算法对IRIS的聚类结果
从表1、2可见,k-means算法把第2类的3个样本,错误的归入第3类,而把第3类14个样本错误的归入第2类,共有17个错分的样本,准确度是88.7%;而本文提出的算法总共有14个错分的样本,算法的准确度为90.7%.显然,本文的算法有效且具有更高的精确度.
2.2 对Soybean-small数据的聚类结果
Soybean-small数据具有47个样本,每个样本有35个属性,共分为4个子类,其中一个类包含17个样本,另外3个类各有10个样本.因为这些属性中有14个属性值是完全相同的,所以我们只使用另外21个属性进行聚类分析.本文算法的聚类结果见表3,用 k-means算法的聚类结果见表4.

表3 本文算法对Soybean-small数据的聚类结果

表4 k-means算法对Soybean-small数据的聚类结果
从表3、4可见,使用k-means算法,它错分了15个样本,准确度是66%;而本文的算法仅错分了12个样本,准确度是74.5%.同样,本文算法的聚类结果精度更优.
3 结 论
依据不同样本对聚类中心产生不同影响,我们提出了基于样本加权的聚类算法,并针对具体数据集,把样本属性分为空间属性和非空间属性,这样可以提高聚类算法的应用领域.实验表明,该算法比k-means聚类算法具有更高的精确度.下一步的研究方向为:一是引入模糊数学,实现模糊聚类,提高边界处理能力;二是把该算法应用于图像分割等领域.
[1]Han J,Kamber M,Tung A K H.Spatial Clustering Methods in Data Mining:A Survey[M].New Y ork:John Wiley,2001.
[2]Jain A K,Murty M N,Flynn1 P J.Data clustering:A review [J].ACM Computing Surveys,1999,31(3):1145-1149.
[3]Zhang T,Ramakrishnan R,Linvy M.Birch:an Efficient Data Clustering Method for very Large Databases[C]//Proceeding of ACM SIGMOD International Conference.New Y ork:ACM Press, 1996.
[4]Ester M,Kriegel H,Sander J,et al.A Density-based Algorithm for Discovering Clusters in Large Spatial Databases with Noise [C]//Proceeding of2nd International Conference on Knowledge Discovery and Data Mining.Portland,Oregon:ACM Press,1996.
[5]Wang W,YangJ,Myntz R.Sting:a Statistical Information Grid Approach to Spatial Data Mining[C]//Proceedings of the23International Conference on Very Large Databases Athens.New Y ork:ACM Press,1997.
猜你喜欢
汽车实用技术(2022年14期)2022-07-30
北京航空航天大学学报(2021年4期)2021-11-24
当代陕西(2020年17期)2020-10-28
铁道通信信号(2019年6期)2019-10-08
人大建设(2018年5期)2018-08-16
雷达学报(2017年6期)2017-03-26
互联网天地(2016年1期)2016-05-04
应用科技(2015年5期)2015-12-09
电子设计工程(2015年6期)2015-02-27
航天器工程(2014年5期)2014-03-11
