
科技论文学术影响力的多属性描述研究
2012-08-31 11:45郭强,赵瑾
图书馆理论与实践 2012年7期
●郭 强,赵 瑾
(1.郑州大学 信息管理系,郑州 450001;2.中国人民解放军炮兵学院 军事运筹教研室,合肥 230031)
在对科技论文进行描述与评价的过程中,需要建立相关的指标或指标体系来对论文的某种侧面特征或是其整体特性进行衡量,由此来获得科技论文相关性质的近似表征或度量,如论文的学术影响力、研究内容的创新性与前沿性等。由于论文的被引次数具有相对较高的可靠性、客观性,同时引文数据的获取具有其便捷性,使得论文的被引次数成为较为基本的描述指标有了其理论及实际基础,从而能够建立基于论文被引次数的复合指标,如期刊的影响因子以及作者的h指数等。本文希望在被引次数及其复合指标的基础上考虑论文的下载次数,并由此来进一步探讨相应的论文影响力的多属性描述,从而考察在论文被引次数的基础上纳入下载次数对于评价指标体系差异性以及全面性的影响,进而也能够利用所得到的指标体系对h指数以及影响因子等进行考察,一方面可以对相关的复合指标进行多属性的探讨,另一方面也可以对这种多属性描述的可行性进行考察以及对其有效性进行检验。
1 论文影响力描述指标的选取
科技论文多属性描述的已有研究侧重于论文的学术质量、论文的学术影响力评价指标体系的建立与应用,具体内容涉及对指标体系的合理性、可靠性、可用性的考察;对指标权重的确定,以及对所建指标体系的实践检验等。其中论文的被引次数以及论文所属期刊的影响因子往往会成为指标体系构建的基础,究其原因是由于利用被引次数对学术质量或是影响力进行描述具有其客观性,同时经验考察的结果往往会显示,期刊的影响因子与论文的学术水平以及论文的影响力等也具有较高的正相关性。
以被引次数与影响因子为基础能够构造出相关的评价指标,用以反映论文质量及其影响力的不同侧面特征。在这个过程中,为了尽可能满足描述体系的全面性,是否也需要考虑以文献的被引情况作为判断依据的描述指标,如是否存在能够作为对论文影响力以及重要性的侧面反映,而该类指标及其取值并不完全或者是直接建立于该论文的被引情况上的。
除了考虑综合指标体系的构建外,针对论文质量或者是其影响力的复合指标由于往往不涉及指标权重的确定过程,所以能够带来描述体系中的计算量的减少,如论文引证系数建立在论文被引情况与期刊影响力之间关系的考察基础上。考虑到论文的自引以及不同学科相互之间的差异,直接使用被引次数与影响因子进行描述可能会带来与论文实际影响力的偏差,由此需要对被引次数以及期刊的影响因子进行修正或是优化,并将修正后的论文被引情况与期刊的影响因子相乘来建立论文实际影响力的表征,[1]再如利用影响因子分数平均值来对论文进行评价时则是侧重于不同学科之间论文质量或是影响力的可比性。[2]
1.1 必要性考察
如果仅对论文影响力的多属性描述进行考察,从直观上,文献的被引用情况能够体现出该文献所具有的学术影响力,同时经验考察与同行评议的结果也均能表明文献的被引次数与其影响力之间的显著相关,尽管这种相关性是建立在统计意义的基础上,但是并不妨碍利用被引频次对文献的影响力进行表征的合理性,而这种合理性也是引文分析具有可行性的基础。但是如果所考察的论文均具有相近的被引次数,并且各论文所属期刊的影响因子等期刊影响力指标值也能够较为接近,那么这些论文具有相似的影响力是否也会是必然。如果不是,那么是否意味着在利用被引情况对文献影响力进行描述的基础上还存在着其它的论文影响力评价指标,毕竟从直观上综述性论文与一般的研究论文在满足被引情况与所属期刊影响力较为相近的情况下,两类论文的影响力是否也能够较为相近至少并不显然。其次,论文的被引情况与影响力之间的高度正相关也意味着在统计意义上前者对论文影响力的变化行为能够进行相当部分的解释。另外,作者在其研究过程中往往并非是将其所阅读或者是所使用过的文献全部列入到论文的参考文献当中,那么可以假设在所有可能被引用的文献当中最终被作者引用的文献应当具有某种最优性,然而对于在研究过程中使用但是未获得最终引用的文献的影响力应该如何来描述,或者说未被引用的文献的学术影响力并没有完全反映到该类文献的被引次数当中。因此,对于文献被使用但未被引用的情况在目前较难获取的情况下,能否考虑将文献的下载次数作为对文献影响力的侧面表征。毕竟从直观上论文的下载次数能够与该论文的被使用情况或者是受利用的程度相对应,从而与文献的被引情况等一起纳入到指标体系中用以对论文的影响力进行描述。当然,前提是要以文献资源的数字化以及网络环境作为基础,并且论文的下载数据也能够获取。将论文的下载次数作为对论文的质量以及影响力的评价指标已有研究,已有的研究还包括对期刊、论文的下载指标与被引指标的关系,特别是两者的不一致性所进行的考察等。[3-4]
1.2 差异性考察
下载情况与被引情况具有同一性的基础,两种类型指标均是对描述对象的内在价值的侧面反映,已有的研究对论文或是期刊的被引情况与下载情况之间的差异进行了考察,如在考察年度被下载以及被引用的论文的年代分布,下载次数与被引次数以及有关复合指标在期刊中的分布状况,期刊或者论文按照被引次数与下载次数以及有关复合指标等的排序相关性。[4]仍将CNKI的镜像站版作为数据来源,并以图书情报类的期刊论文为例,假设图书情报类文献的最大引文年限为3年。由于从直观上,在最大引文年限之后文献的受利用程度会随着时间呈现下降的趋势,那么不严格地,如果选取考察时长为5年,则该时段能够大致反映文献被引情况的主要部分,从而对该文献的受利用程度进行基本的表征,或者说认为该时段足够长以至于近似体现论文被引情况的统计性质,再考虑文献的下载情况作为对文献影响力的侧面反映,与被引情况相比往往会具有较短的延时性,而且从直观上论文的下载情况随时间的衰减速率也会相对较高,[4]所以仍然选取上述的考察时长来近似体现论文下载情况的统计性质。由此选取2004年与2005年6月份出版的图书情报类期刊论文作为考察对象,同时需要指出,由于选取的考察时长是建立在能够对文献的被引情况以及下载情况进行近似表征的假设基础上,所以在这里忽略由起始考察时间的不同所带来的文献考察时段的差异,以近似满足所得原始数据之间的可比性要求。
对于所选取的论文样本集,由于在上述考察时段内每篇论文均具有与其对应的被引总量与下载总量,所以能够得到这两个指标的随机样本对。将这些论文的被引总量与下载总量分别由小到大进行排序,根据依次得到的各个指标值的等级,能够给出论文的被引总量与下载总量之间的等级相关系数为0.7011,其中当指标值相同时取相应的指标值等级为其平均等级,同时从总体上假设检验的结果为在0.05水平下论文的下载总量与被引总量之间存在等级相关关系,同样地可以得到论文的年均被引次数与其年均下载次数之间的等级相关系数为0.7008,并且在0.05水平下论文的年均被引量与年均下载量之间也存在等级相关关系。进一步地,将论文的年均被引量与年均下载量分别除以相同发表年度的论文的年均被引量与年均下载量的算术平均值,则可以得到论文的相对年均被引量以及相对年均下载量,那么类似地可以得到该两相对量之间的等级相关系数为0.7058,而且在0.05水平下论文的相对年均被引量与相对年均下载量之间同样存在等级相关关系。这些从直观上反映了论文的下载情况与被引情况之间所具有的同一性,同时也能够注意到两者等级相关的密切程度均接近于一般意义下的强相关范围,其中数据统计的时间为2011年10月。
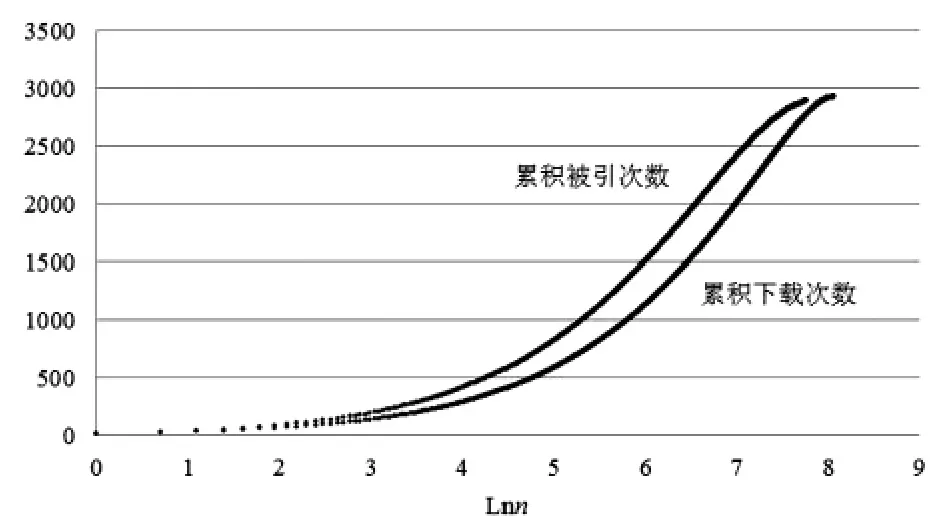
图1 论文指标的累积量与论文累积量之间的关系图
另外,将论文分别按照被引次数以及下载次数进行降序排列,则能够得到论文的被引次数累积量以及下载次数累积量与论文累积数之间的关系如图1所示,其中n为论文的累积数,纵轴为论文被引量或是下载量的单位的倍数,在这里单位分别取为6次以及100次,单位的选取是任意的,目的只是为了能够将这两个指标的变化情况纳入图中,两曲线的相对位置并不绝对。从直观上被引次数与下载次数在论文中均具有布拉德福分布的特征,假设取分区数为3,对于论文的被引次数可以取其核心区的论文数为190篇,各分区的累积被引次数的平均值为5795,标准差仅约为4,同时各论文分区的论文数相继比的平均值为3.049,标准差为0.866,如果不严格地,则认为论文被引次数的分布近似满足布拉德福分布的分区描述。同样对于论文的下载次数,其核心区论文数为318篇,各论文分区的论文数相继比的平均值为2.610,标准差仅为0.485,与被引次数相比,这也是下载次数在论文中的分布更为分散的侧面反映。由于在末尾分区处格鲁斯下垂的出现,那么大量的论文具有相对较低的指标值,从而使得论文数相继比会在末尾分区处出现异常,而由于下载次数的分布相对较为分散,所以与被引次数相比能够在一定程度上减弱末尾相继比偏高的状况,从而相继比的标准差也会相对较低。在图1中看出在论文累积数的末端,对于下载次数与被引次数,格鲁斯下垂都能够有所显现,所以在靠后的分区处均会出现相继比的异常,例如取分区数等于5,对于下载次数与被引次数分别有各分区的论文数的相继比为1.909,1.625,1.670,2.989以及1.878,1.536,1.546,2.508。同时,被引次数在论文样本中的分布也能够与布鲁克斯公式相一致,其核心区以及非核心区的拟合方程分别为c=120.03n0.7477与c=4937.7Lnn-20340,判定系数分别为0.9976以及0.9939,类似地对于下载次数在论文中的分布可以得到其拟合方程为d=1567.9n0.7222与d=93582Lnn-452058,判定系数分别达到0.9992以及0.9961。从直观上下载次数与被引次数在论文样本中均具有布拉德福分布的特征,能够注意到与下载次数的分布相比,在分区数相同的情况下被引次数具有相对较少的核心区论文数,从而在一定程度上反映了下载次数在论文中的分布可能会更为分散。
图2中考察论文指标累积值的相对量,此时两指标曲线能够进行相互比较,其中横轴为论文数的累积比重,纵轴为论文下载次数与论文被引次数的累积比重。当论文累积百分比由坐标原点变化至点A时,下载累积比重均位于被引累积比重的下方,说明在该范围内对应于相同的论文累积比重,被引累积百分比会相对较高,从而被引次数在论文中的分布也会相对较为集中。而在点A至点(1,1)的范围内下载曲线位于被引曲线的上方,反映了与下载次数相比被引次数更多的集中于排序相对靠前的论文,而且在该范围内两曲线之间的相对位置也是由于两曲线段具有相同的端点 (0,0)与 (1,1)的缘故。
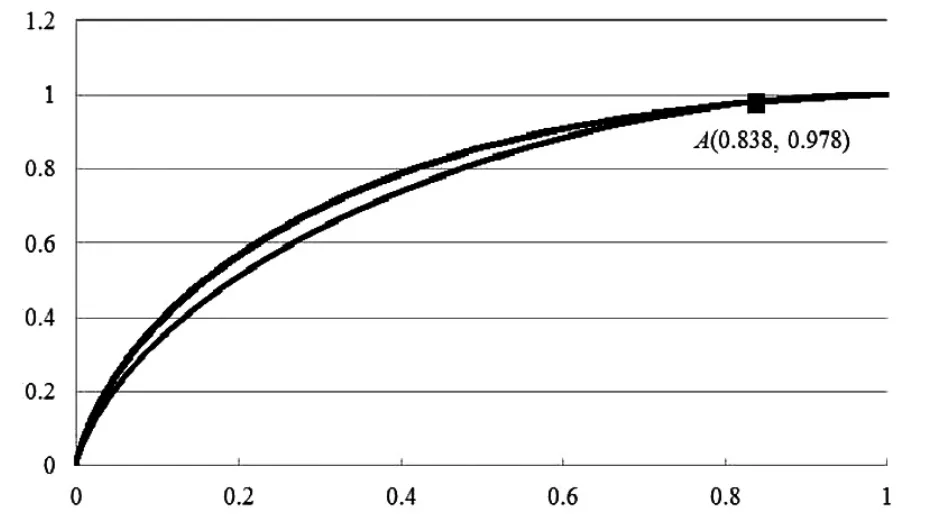
图2 论文指标的累积比重与论文累积比重之间的关系图
图1与图2是以图书情报类的期刊论文作为考察对象,需要改变学科的属性以及时间范围以对所得认识的一般性进行检验。在上述对论文下载次数进行考察的基础上,采用在文献[6]中所建立的论文学术影响力评价指标体系,选取论文影响力的描述指标分别为论文截至数据统计时间的被引总量,论文的年均被引量,论文在发表后三年中的被引总量,论文在发表后的最大年度被引次数,论文所属期刊的影响因子,论文的相对年均被引量,论文所属期刊的相对影响因子;论文在发表后三年中的相对被引总量,论文截至数据统计时间的下载总量,论文的年均下载量,以及论文的相对年均下载量,其中相对指标的取值是采用绝对指标值与对应绝对指标的算术平均值相除来得到。
2 论文影响力的描述
仍然采用上述的论文样本,由于从直观上所选取的考察时长能够对论文的被引情况与下载情况的主要部分进行基本的反映,所以将论文从其发表到统计时间之内的被引次数与下载次数作为对论文被引总量与下载总量的大致表征,而且发表后三年中的论文的被引及下载情况也包含在考察时段内。考察论文的最大年度被引次数时需要确定论文的考察时长,在这里采用论文所属研究领域的期刊的被引半衰期作为衡量的指标,其假设是认为在被引半衰期之后论文的被使用次数会相对较少。如果将2011年图书情报领域期刊的被引半衰期的平均值取为5年,那么意味着期刊在5年前发表的文献在考察年度会相对较少的被引用,或者该领域文献的最大被引年度在通常情况下应当包含于5年内,所以仍然选取考察时间为2011年10月,同时论文的发表年度取为2004年与2005年,相应地取该6-7年内的最大引用年度的被引次数来近似表征论文自发表后的最大年度被引次数。另外,期刊的被引半衰期会随时间发生变化,由于图书情报领域的发展,所以该领域期刊被引半衰期的逐年增长,但是从直观上由于是对期刊的整体反映从而随时间具有其相对的惯性,所以被引半衰期的增长往往没有年份增加的速率快,那么对于所选取的2004年与2005年的文献,在通常情况下,如果将考察时段进行延长,则论文样本的发表时间仍然没有包含在相应考察年度的被引半衰期内,这也意味着在延后的考察年度中所选取的论文样本依然会相对较少被引用。所以尽管被引半衰期会有所增加,但是这并不影响将考察时间取为上述的2011年。进一步地,在所得数据的基础上对论文影响力的描述指标进行主成分分析,由此对各指标的权重进行确定并对论文的影响力进行描述,同时根据影响力的描述值也可以对上述描述指标的全面性进行考察。
在指标的相关系数矩阵中,可以看出期刊的影响因子与期刊的相对影响因子之间的显著相关,并且这两个指标与其余指标之间的相关系数的变化范围为0.376至0.396,其余指标之间的相关系数的最小值为0.566,那么从直观上仅由指标间的相关系数出发,可能需要提取两个主成分来替代已有的描述指标,分别对期刊类与论文类指标进行反映,前者包括期刊的影响因子以及期刊的相对影响因子,后者则与其余的指标相对应,由此主成分的结构关系以及各指标的归类情况均能够与已有研究较为吻合。[1]另外,期刊类或论文类指标相互之间的显著相关性也是在这里进行主成分分析的原因。
在总方差解释表中,由于前两个主成分所对应的相关系数矩阵的特征值均大于1,分别为7.827与1.598,并且这两个主成分所对应的方差累积百分比达到了85.682%。如果只考虑这两个主成分,那么利用成分矩阵中各指标与这两个主成分之间的简单相关系数可得各指标的公因子方差分别为0.961,0.963,0.912,0.904,0.864,0.962,0.864,0.910,0.700,0.680,0.704,此时公因子方差的平均值为0.857且标准差仅为0.110,由此提取这两个主成分。由于论文下载类指标的公因子方差均相对较小,所以只选取这两个主成分时对于论文的下载情况的反映可能会有其不足。在成分矩阵中,论文类指标与第一主成分之间的简单相关系数均相对较高,变化范围为0.801至0.956,与第二主成分的相关系数的绝对值均在0.253以下,期刊类指标则与第二主成分高度正相关,相关系数均为0.760,与第一主成分的相关系数均为0.536。由此各指标均能按照所提取的两个主成分进行大致的归类,主成分的结构与仅从指标间相关系数出发得到的认识也相一致。
由这两个主成分所对应的矩阵特征值以及在成分矩阵中各指标与所提取的主成分之间的相关系数可得这两个主成分F1与F2的表达式,分别为F1=0.341z1+0.342z2+0.329z3+0.331z4+0.192z5+0.341z6+0.192z7+0.329z8+0.290z9+0.286z10+0.291z11;F2=-0.177z1-0.176z2-0.199z3-0.170z4+0.601z5-0.177z6+0.601z7-0.200z8+0.160z9+0.156z10+0.161z11,其中zi为Z标准化后的指标值,进而有论文影响力的得分表达式为w=0.253z1+0.254z2+0.240z3+0.246z4+0.261z5+0.253z6+0.261z7+0.239z8+0.268z9+0.264z10+0.269z11。
按照该得分表达式以及指标在标准化后的取值能够得到论文样本的影响力分值,将论文按照其对应分值进行降序排列,则能够得到论文的累积分值与论文的累积量之间的关系,从而对论文分值在论文中的分布状况进行反映。如果不考虑论文的下载总量与论文的年均下载量以及论文的相对年均下载量来进行类似的考察,以前8项指标的原始数据经过标准化后进行主成分分析时,所得到的指标间的相关系数矩阵并不是正定矩阵,从矩阵元素来看,究其原因是由于在所统计的数据的基础上,部分指标之间具有偏高的相关系数,去除后3项指标更增加了矩阵中这些指标对应列之间的一致性,从而使得指标的相关系数矩阵能够近似为不满秩,由此导致了该矩阵的非正定。当然这并不意味着这部分指标之间的绝对重叠,出现这种情况仅仅是针对这里的原始数据而言,另外所选取的论文样本数为3179,也超过了一般情况下所要求的指标数量的5倍。因此可以去除部分相关程度较高的指标使得矩阵为正定,而且去除部分相对系数较高的指标,也能够在一定程度上避免对论文影响力的反映的不足。
由剩余的7项指标重新进行考察,类似地可以得到期刊的影响因子与期刊的相对影响因子与其余指标之间的相关系数为0.383至0.391,而这两个指标之间仍然呈显著相关,其余指标之间的相关系数的最小值为0.922。所以按照相关系数可能仍然需要提取两个主成分分别与期刊类指标与论文类指标相对应,在总方差解释表中,前两个主成分所对应的特征值分别为5.257与1.539,相应的方差累积百分比为97.092%,同时这7个指标的公因子方差分别为0.969,0.970,0.963,0.931,0.999,0.999,0.963,公因子方差的平均值为0.971,标准差仅为0.024。所以提取这两个主成分,在成分矩阵中所有的论文类指标与第一个主成分的相关系数在0.947至0.965之间进行变化,与第二个主成分之间的相关系数的绝对值则相对较低,且均在0.202以下,而且两个期刊类指标与这两个主成分的相关系数分别均为0.571以及0.821,由此按照成分矩阵各指标均能够进行大致的归类。进一步地,由主成分所对应的特征值以及成分矩阵中的相关系数可以得到两个主成分F3与F4以及论文影响力的得分表达式,分别为F3=0.421z1+0.421z2+0.419z3+0.413z4+0.249z5+0.249z7+0.419z8;F4=-0.157z1-0.157z2-0.163z3-0.148z4+0.662z5+0.662z7-0.162z8,以及w1=0.290z1+0.290z2+0.287z3+0.286z4+0.342z5+0.342z7+0.287z8。
根据论文影响力的得分表达式以及标准化后的数据能够得到每篇论文的影响力描述并得到各论文影响力分值排序的变化情况,如图3所示。
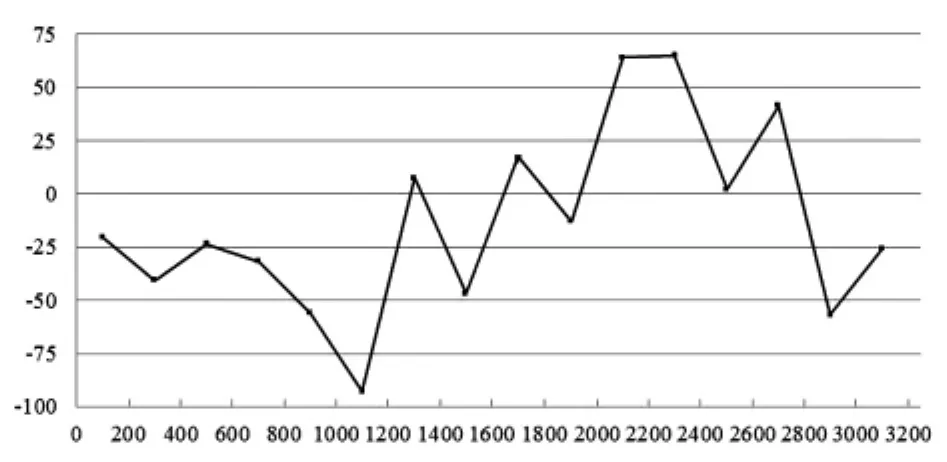
图3 论文影响力分值排序的变化情况
将论文按照其w1值进行降序排列,能够得到每篇论文的排序值r1,同时每篇论文有与其对应的w分值以及相应的排序值r,由此可得每篇论文的排序变化为r1-r。在图3中,横轴为论文影响力排序值r1的各个取值区间,纵轴为对应区间中论文排序变化的平均值,从整体上能够注意到排序相对靠后的论文的影响力会有所提升,相应地则有排序靠前的论文的影响力平均值的下降,从而反映了论文的下载情况对于论文得分的影响,而这种影响则来源于网络及数字环境所带来的论文获取的便捷性。
3 结束语
进一步地,还可以考察论文影响力的累积分值与论文的累积数量之间的关系,如采用两者的相对量来反映论文的影响力分值在论文中的集中或是分散程度。由于在经过指标数据的标准化后,部分论文的影响力分值会取为负值,所以可以考虑将各论文的分值分别加上常数以求分值的累积和。需要指出的是,尽管加上常数不会改变影响力分值所服从的分布,但是会影响影响力分值在论文中的集中或是分散的程度,由此需要对两种论文分值所加上的常数分别进行选取,使得所加常数对于两种分值在论文中的分布情况的影响尽可能相等,从而能够在此基础上对所得到的两种分值累积量进行比较,或者可以考虑对指标数据的标准化方法进行调整,从而使得最终的论文影响力分值为正,由此对论文的得分情况进行进一步的考察。
[1]钟文一,陈云鹏.基于引证系数的论文影响力评价方法研究 [J]. 情报科学,2011,29(5):706-712.
[2]郭红,潘云涛.影响因子分数平均值:一个评价学术论文质量的新指标[J].编辑学报,2006,18(6):475-477.
[3]张玉华,等.科技论文评估方法研究[J].编辑学报,2004,16(4):243-244.
[4]万锦堃,等.期刊论文被引用及其Web全文下载的文献计量分析[J].现代图书情报技术,2005(4):58-62.
猜你喜欢
工会博览(2022年8期)2022-06-30
智能建筑电气技术(2022年2期)2022-02-06
医学美学美容(2021年18期)2021-10-21
商用汽车(2021年4期)2021-10-13
制造技术与机床(2019年4期)2019-04-04
NBA特刊(2018年14期)2018-08-13
中国医疗保险(2018年3期)2018-07-14
人大建设(2017年11期)2017-04-20
中学生数理化·中考版(2017年12期)2017-04-18
瞭望东方周刊(2015年12期)2015-04-14
