
基于BP模型的逆向物流零部件库存预测
2013-10-20 04:30张迎新
统计与决策 2013年23期
张迎新
(1.天津科技大学 经济与管理学院,天津 300222;2.天津商业大学 宝德学院,天津 300384)
1 问题的提出
随着世界各国对生态资源、环境保护的日益关注,对可持续发展和循环经济的日益重视,逆向物流与闭环供应链的研究日益成为国际学术界关注的重点。面向高科技产品的包括正向供应链、逆向物流和售后维修服务在内的闭环供应链。正向物流是从原始设备制造商(OEM)发出高科技产品,经过特约服务商最终到达终端消费者手中。同理由于该种模式是OEM授权特约服务商/经销商进行销售和维修技术支持,因此OEM制造商在发出产品的同时连同维修零部件一同发出至零部件库。当终端消费者废弃该产品,即产品生命周期已经结束,产品进入报废阶段时,产品能够沿着原有的渠道逆流而上,重新回到OEM指定的处理节点,在处理节点进行残值价值判断,确定无维修价值的产品或者零部件进入再利用环节,按照“生产者承担”原则,原来的高科技产品制造商承担产品报废后对环境潜在影响的后续处理责任。如果在处理节点产品经过价值判断之后认定经过修复继续使用,则产品经过维修或翻新处理进入维修备件库以备待用。该模式的特点是整个正向和逆向物流可以被OEM所控制,而且通常都是按照这一模式来运作。
2 逆向物流零部件库存的原理与实例的比较
2.1 需求随机的多级系统的库存控制策略
由于高科技产品的逆向物流零部件具有需求随机,且区域内多级管理的特点,因此适用需求随机的多级系统库存控制方法。
某品牌手机销售商在大区内设有三个维修处,即有三个子库存点见下图1。

图1 三个库存点
级存储费率h1=1 h2=1 h3=1;备货期L1=1 L2=2 L3=0;缺货费率b=9需求率λ=6。欲求库存总费用最小时的库存水平则可通过如下方法求解。
由于订购费为零,采用基本库存策略,即保持各库存点的库存订货点在Sj(基本库存水平),当低于该值时订货,若在期初库存高于该值则不订货,一直等到库存下降到Sj.库存点1,2的备货期需求D1,D2分别服从均指为6、12的泊松分布。
根据供应链理论的基本公式,可得:

根据基本库存策略算法可得:

利用计算机模拟可以得到表1-3,可以得出同样的结果:


表1 库存点1的库存成本及基本库存水平

表2 库存点2的库存成本及基本库存水平
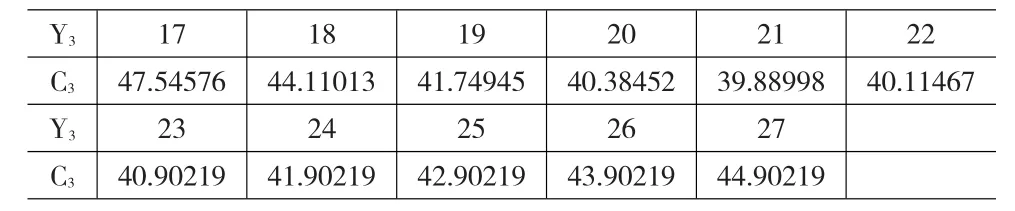
表3 库存点3的库存成本及基本库存水平
2.2 BP神经网络计算库存的原理与实例
2.2.1 BP神经网络求解步骤
1987年,Lapedes和Fayber首次应用人工神经网络分析模型进行预测,开创了人工神经网络预测的先河。分层网络是将一个神经元网络模型中的所有神经元按照功能分为若干层,一般有输入层、中间层和输出层、各层顺序连接。具体步骤如下:
(1)选取研究样本。根据不同的存货控制机制,可以以对单一零部件SKU的管理、对成套产品的管理,以及对二者组合的管理的方法来选择样本。应用BP神经网络模型进行预测与统计方法相比,在样本的选取上局限性小于传统的统计方法。
(2)把用来衡量高科技产品企业库存安全水平的建模变量作为神经网络的输入向量,确定输入层的节点个数。
(3)将代表分类结果的量作为神经网络的输出,设定输出层节点个数,而输出层节点个数由输出类别决定,对高科技产品企业的输出至少有两种,即单一产品SKU或成套产品SKU。
(4)确定隐含层节点个数。隐含层节点个数一般为经验值,与输入层和输出层的节点个数有关,并没有统一的数值要求,一般不宜太少。否则将影响网络的有效性,也不宜过多,否则会增加学习训练的时间。
(5)确定学习率和系统误差。学习率一般控制在0.01~0.9之间,取值不宜过大或偏小,因为学习率越小,训练次数越多,若学习率过大,每次权值的变动越剧烈,会影响网络结构的稳定性。一般来说,在以往的研究中,学习率选择0.05,误差ε通常需要根据输出要求来确定,为了保证系统的学习精度,在很多的研究中设定系统误差为0.1%。
(6)在输入各项参数后,就开始用训练样本来训练网络,使训练样本中的样本企业与参照企业的输入向量得出区分两类不同公司的输出向量,一旦学习训练完毕,便可作为被测企业预测的有效工具。
2.2.2 BP神经网络的计算实例
本文讨论电脑维修零件的库存水平。由于仅仅是进行算法的比较,所以只是假设最有利于计算的已知条件,在实际运作中,影响库存的因素有很多,如缺货成本、提前期、需求状况,存储成本、出库频率、物料的等级等。在此只选择最常考虑的影响因素进行分析,即选择缺货成本、存储成本和提前期。
BP网络的输入、隐含、输出层的设置如下图4所示:

图2 安全库存水平预测BP神经网络模型
确定隐含层神经元个数的方法比较多,以下为几种比较常用的经验公式:

式中:m为输入神经元数,n为输出神经元数,a为[1,10]之间的常数,T为隐含层神经元个数;

式中:n为输入神经元数,T为隐含层神经元个数;

式中:m为输入神经元数,n为输出神经元数,T为隐含层神经元个数。
本文采用第一种方法求得T=2+a=3~12
本文采用归一化公式,将原始数据归一化到[-1,1],其公式如下:

Xi、Yi分别为转换前、后的值,Xmax、XMIN分别为样本的最大值和最小值。然后使用Matlab进行仿真。

表4 归一化样本数据
如上表4所示,看到期望输出的范围是(-1,1),所以利用双极性Sigmoid函数作为转移函数。
所得结果如下(程序从略):
输入层到中间层的权值:
V=(- 9.1669 7.3448 7.3761 4.8966 3.5409)T
中间层各神经元的阈值:
θ=(6 .5885-2.4019-0.9962 1.5303 3.2731)T
中间层到输出层的权值:
W=(0.3427 0.2135 0.2981-0.8840 1.9134)
输出层各神经元的阈值:T=-1.5271
可见,用神经网络模型计算的结果考虑的影响因素更为全面,且不受分布约束的要求,各影响因素能有机结合、相互作用。
该方法较之传统的统计类分析方法相比,已经越来越多的受到学者的关注。本文通过以下的两张表分析优缺点。具体分析见表5和表6传统统计方法与BP神经网络的比较。

表5 传统统计方法与BP神经网络的比较(1)
综上,在预测精度、样本选择,以及系统误差方面,BP神经网络均表现出良好的优点。但是BP神经网络也存在一定的缺陷,如表6传统统计方法与BP神经网络的比较(2)。

表6 传统统计方法与BP神经网络的比较(2)
综上,在数学建模、稳定性和参数的严谨性角度,BP神经网络还有一定的缺陷。
3 结论
循环经济的发展,要求逆向物流为其疏通渠道。闭环供应链的建立可以协调正向和逆向物流在有效的体系中整体趋向最优。高科技产品闭环供应链库存预测的新方法BP神经元网络开启了一种崭新的研究领域,将技术研究和实际应用的结合,为人们解决高科技产品逆向物流中的实际问题构造了一种全新的思路,同时也丰富了统计方法,尽管BP神经元网络尚有一定的缺陷,随着研究的深入和理论的发展,其今后必能给我们的研究作出更大的贡献。
[1]E.Schoeneburg,N.Hansen,A.Gawelczyk.Neuronal Netswerke[M].Germany:Markt&Technik VerlagAG,1990.
[2]X.Wang,R.Babinsky,H.Scheich.Synaptic Potentiation and Depression in Slices of Mediorostral Neostriatum-hyperstriatum Complex[J].Neuroscience,1994,60(3).
[3]王旭,王宏,王文辉.人工神经元网络原理与应用[M].沈阳:东北大学出版社.
[4]唐纳德·F·布隆伯格著,逆向物流与闭环供应链流程管理[M].刘彦平译.天津:南开大学出版社,2009.
[5]周政.BP神经网络的发展现状综述[J].山西电子技术,2008,(2).
[6]孙建业,王辉.BP神经网络算法的改进[J].系统工程与电子技术,2004,(6).
[7]倪霖,刘琳.基于遗传神经网络的汽车回收逆向物流综合评价[J].计算机应用研究,2011,(8).
猜你喜欢
音乐天地(音乐创作版)(2022年1期)2022-04-26
小学生学习指导(低年级)(2021年9期)2021-10-14
中华诗词(2020年12期)2020-07-22
中学生数理化·七年级数学人教版(2019年10期)2019-11-25
小学生学习指导(低年级)(2019年9期)2019-09-25
北方经贸(2019年1期)2019-06-29
小学生学习指导(低年级)(2018年9期)2018-09-26
北京科技大学学报(社会科学版)(2016年6期)2017-03-21
科技与创新(2014年2期)2014-03-22
