
大数据分析场景下分布式数据库技术的应用
2015-02-06 06:21
移动通信 2015年12期
(中国移动通信集团设计院有限公司网络所,北京 100080)
1 引言
随着移动互联网的迅猛发展,运营商网络中的数据呈现爆炸性增长,带来海量数据存储、分析及管理的需求。大数据分析场景以非结构化数据为主,运营商由小型机构建的传统数据库系统在架构、成本、分析能力等方面均出现瓶颈或不满足发展需求,运营商系统对分布式数据库需求大量增加。因此,秉承“高效低成本”的指导原则,并实现大数据的交换、整合和分析,本文基于运营商大数据分析系统,探讨了以分布式数据库为特征的架构方案具体落地。
2 建设驱动力
在大数据时代,面对海量数据的井喷式增长,传统集中式数据库的弊端日益显现,采用分布式数据库的驱动主要来源于以下方面:
(1)更强的扩展能力:传统小型机构成的数据库系统受限于其架构,最多几百TB级别的数据容量,其扩展性能已接近瓶颈。而分布式数据库架构能够动态地增添存储节点,在支持PB级别的数据环境方面更具优势。
(2)较大的成本优势:大数据下,传统小型机及数据库扩容成本急剧提升,而分布式数据库在成本方面具备较大的优势。以运营商存储总量为500TB的大数据分析系统为例,在考虑服务器、数据库软件及网络设备的整体架构方案设计下,传统数据库架构造价成本为11.2万元/TB,而分布式数据库架构造价成本仅为2.2万元/TB,单位造价降低80%。
(3)更优的使用效果:在大数据分析场景下,分布式架构的列存储、透明压缩、并行处理等技术很容易实现海量存储和管理要求,可以及时响应大规模用户的读/写请求,在查询、统计和分析类操作较传统数据库具备天然的优势。
3 实现分布式数据库的关键技术
3.1 MPP+Shared Nothing架构
分布式数据库一般基于MPP(Massive Parallel Processing,大规模并行处理)技术实现,由多个松耦合的处理单元构成,每个处理单元都有自己的计算资源、存储资源和软件资源,如总线、内存、硬盘、操作系统和数据库实例等。每个处理单元都是独立的、自给的、对等的,整个系统中不存在单点瓶颈。
分布式数据库提供动态扩展的方式,由多个处理单元协同完成相同的任务,多个处理单元之间的信息交互是通过节点互联网络实现的。每个节点只访问自己的本地资源,不存在异地内存访问的问题,是一种完全无共享(Shared Nothing)结构。该架构下,数据平均分布到系统的所有节点上,每个节点存储每张表或表分区的部分行,所有数据加载和查询均可自动在各个节点服务器上并行运行。
3.2 混合存储(按行或按列)
区别于传统行存数据库,分布式数据库的数据在磁盘中支持混合方式(按行或按列)进行组织和物理存储。由于列存储架构对查询、统计和分析类操作具备天然的优势,因此在运营商经营分析系统等大数据分析场景中能获得很好的应用。混合存储的优势体现在以下方面:
(1)更高灵活性:混合按列或按行存储数据,每张表或表分区可以由管理员根据应用需要或者数据格式的不同,指定不同的存储和压缩方式。该方式可较大地提高配置的灵活性,具体如图1所示。

图1 混合存储示意图
(2)提高响应速度:查询语句时,传统行存数据库需要从磁盘上将整行数据取出,而列存储只读取所需要的列,其他列的数据不需要读取。该方式可大幅降低I/O开销,提高查询性能和响应速度。
(3)高扩展性:分布式数据库的独特存储格式对列数据可再细分为“数据包”。无论一个表有多大,数据库只操作相关的数据包,性能不会随着数据量的增加而下降,这样表数据可以达到很高的可扩展性。
3.3 高效透明压缩技术
高效透明压缩技术能够按照数据类型和数据分布规律自动选择最优压缩算法,并设置了库级、表级、列级等压缩选项,灵活平衡性能与压缩比的关系,而且压缩与解压缩过程对用户是透明的。
由于分布式数据库支持列存储,列数据包内都是内容相关性高的同构数据,因此更易于实现压缩,压缩比可以达到5~20倍以上,数据占用空间较传统数据库可节省50%~90%。此外,压缩态下对I/O要求大大降低,数据加载和查询性能比传统数据库快几十倍以上。
3.4 智能索引
与传统数据库建立在行数据上的细粒度索引技术相比,分布式数据库的智能索引是一种建立在数据包上的粗粒度索引。每个数据包在加载数据时自动建立,包含过滤信息和统计信息。粗粒度的智能索引包含了描述数据间相互依赖关系的高级信息,能够准确识别数据包的需要,可有效解决复杂的多表连接和子查询。表中的所有列自动建立,不需用户手工建立和维护。
智能索引本身占空间很少,扩展性很好,建立索引后无膨胀。后续的数据包建立索引的速度不会受到前面数据包的影响,建立索引的速度相当快。并且在数据查询时不需要解包就能得到统计值,可进一步降低I/O速度,对复杂查询的优化效果明显。
3.5 并行处理技术
分布式数据库针对数据加载和数据查询实现了自动高效的并行处理技术,充分利用智能算法适配实现多核CPU资源并行,实现数据库分区内的查询并行。针对不同的数据分布及特征智能选择不同算法进行处理,如低效的写操作、并发运行且消耗大量资源的查询操作,控制在各自适合的条件下运行。
分布式并行技术具有系统资源管控能力,通过可配置的负载均衡机制,有效调度和平衡各个节点的负载及并行处理过程。用户所面对的都是同一个数据库系统,它负责调度各节点的工作,分解查询请求,制订节点查询计划,并对不同节点的查询结果进行汇总。并行处理技术可以将一个用户的单个查询任务分解在同一台主机的多个CPU上并行运算,也可以将一个用户的多个查询任务分解在同一台主机的多个CPU上并行运算,还可以将多个用户的多个查询任务分解在多台主机的多个CPU上并行运算。
4 分布式数据库架构方案设计
4.1 技术要求
移动互联网的迅猛发展使得运营商网络中数据流量激增,运营商如何把握市场转型所带来的机遇,做好数据经营的价值挖掘,以低成本、高效率的运营模式面临挑战,将会是一个重要的课题。
本文以某省运营商大数据分析系统为例,为实现深度挖掘支撑精准营销和精细化服务,并实现对大量并发自助服务查询的支撑要求,将该系统中的分布式数据库分为融合计算集群和自助查询集群。其中,融合计算集群有效数据量为300TB,并要求具备高效并行计算能力;自助查询集群有效数据量为150TB,并要求具备复杂关联查询的支持能力。
4.2 网络架构
分布式数据库需要通过网络传输大量的数据,为提升网络带宽并最终改善数据库性能,一般建议采用万兆交换网络。本文将系统分为集群一(融合计算集群)和集群二(自助查询集群),两集群共用核心万兆交换机。每集群配置相应数量的节点,每个节点配置2个万兆网卡和2个千兆网卡绑定后分别连接2台交换机,从网卡、交换机、节点等环节均实现高可用性。其中,千兆电口网卡用于外部对节点的管理登录连接及监控信息通讯;万兆光口网卡用于集群内部节点管理和节点间数据通讯。具体如图2所示。
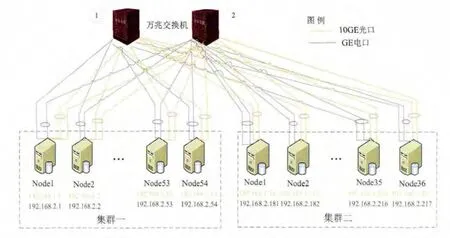
图2 分布式架构网络部署图
每台交换机划分2个VLAN(Virtual Local Area Networks,虚拟局域网)。VLAN1支撑融合计算集群,VLAN2支撑自助查询集群,并各自预留一定的扩容余量。
4.3 硬件架构
分布式数据库的性能很大程度上取决于CPU、内存、I/O设备、磁盘数量等硬件配置是否均衡。资源配置均衡合理,避免瓶颈的出现,才能获得更优的性能。例如,CPU和内存的比例一般要求在1:8或以上;应确保每个数据库分区使用独立的磁盘,以匹配分布式数据库的无共享架构。
仍以前文架构为例,系统集群一和集群二分别部署54、36个节点,每个节点包含1台X86服务器及8块1TB内置磁盘。每个集群内的节点均为对等节点,共同提供计算或查询服务。集群之间不存在依赖关系。
分布式数据库可采取将一个大的集群拆分成多个高可用组的方式,实现高可用性。例如,融合计算集群共54个节点,可拆分成18个高可用组,每组内3个节点轮转方式备份,每个节点的2个文件系统分别在另外2个节点上各有1份数据拷贝,确保任何节点宕机后数据库仍然可以正常使用。
分布式数据库配置硬盘及支持的数据空间换算过程如表1所示:

表1 分布式数据库配置硬盘及数据空间计算模型
由此可见,配置硬盘及支持的压缩数据空间大约在1:1之间。但考虑本文仅保守取定5倍的压缩比例,且目前单节点配置硬盘已经广泛达到24TB(12块2TB),分布式数据库可支持的数据空间还有较大的提升潜力。
4.4 应用效果
以前文提到的融合计算集群和自助查询集群为例,最终通过MPP架构数据库集群实现了较高的并行计算能力、高并发访问支持能力以及高效即席查询能力来支持数据分析平台的业务需求。主要应用效果如下:
(1)混合应用的负载支撑
分布式数据库可支持各种类型的应用,如数据装载、数据加工、数据计算、数据更新和删除、数据插入导出、用户并发查询等操作。分布式数据库通过良好的索引技术和并发机制能够很好地支持混合负载场景,满足业务需要。
(2)大量业务的负载管理
分布式数据库可承载大规模的数据容量及大量的业务,有大量的业务用户使用。通过高效的工作负载管理能力实现各类作业有条不紊地运行,提高系统的整体吞吐量。工作负载管理可提供用户优先级管理(高优先级用户可以使用更多系统资源)、数据优先级管理(热点数据优先,查询热点数据获取更多系统资源)、作业并发度控制(按作业执行成本分类,控制每类作业的并发度)、作业类型管理(如数据装载、查询、调用)等。
(3)满足高并发查询需求
在数据分析平台自助服务查询业务中,需面向基数庞大的客户群体提供即席查询服务,并发访问峰值量极大,因此要求自助服务查询数据库具有支持大并发的能力。
根据实际应用情况,分布式数据库可同时支持不少于200个并发查询任务。分布式数据库对于1亿条记录规模以内的数据查询,处理性能可控在2小时以内。对记录为2亿条数据的表同时进行数据加载和查询,查询时间可控在40分钟以内。
(4)满足高数据加载能力需求
根据实际应用情况,日汇总数据28亿条,单节点加载效率可达到1.5万条/秒;月汇总数据320亿条,单节点加载效率可达到5.5万条/秒。对于2亿条数据的表做单表汇总操作时间不超过90分钟。
针对多表关联的情况,日汇总表两表关联时,数据量为2亿×0.5亿情况下,关联汇总的时间可控在40分钟以内;在三表关联时,数据量为2亿×0.6亿×0.5亿情况下,关联汇总的时间可控在50分钟以内。
(5)满足高扩展能力需求
随着数据量的增加,应用功能不断丰富,分布式数据库系统势必需要进行扩容,增加处理能力和存储容量。分布式数据库通常采用增加新的处理节点的方式,实现处理能力和存储容量同时扩容。从系统扩展角度来说,分布式数据库集群最大节点支持数在1 000以上;从运维角度来说,300TB存储的分布式数据库集群在增加节点后能够在8小时内完成数据的重新分布。
数据库支持定制哈希位图,可尽量减少重分布的数据量以及减轻重分布期间对业务应用的影响,数据库支持数据重分布期间对外提供服务,为客户提供更多的选择。
(6)实现系统稳定性和高可用性需求
分布式数据库的高可用性包括应对多种故障,在网络连接异常、磁盘故障、节点级故障等情况下,应用均不需要重新连接,可以继续执行直至完成。同时,系统一般通过多副本等冗余机制来保证数据的高可用特性和安全。分布式数据库在CPU利用率达到70%以上和200个线程同时计算的状态下能够稳定运行,能保障7×24小时持续运行,年故障数可控在5次以内。
5 结束语
本文分析了大数据分析场景下分布式数据技术的建设驱动力及关键技术,并对分布式架构建设方案进行了详细的阐述。基于上述技术的分布式数据库系统已经在运营商VGOP、经分等多个大数据分析平台中得到应用。分布式数据库可提高运营商系统的通用性、可扩展性、灵活性,并在一定程度上降低了开发成本。后续将对分布式数据库进行进一步研究,以便其更好地服务于大数据的发展。
[1] 陈如明. 大数据时代的挑战、价值与应对策略[J]. 移动通信, 2012(17): 14-16.
[2] 刘昭,张海峰,李玮,等. 运营商发展大数据技术及建设模式展望[J]. 电信工程技术与标准化, 2015(3): 12-16.
[3] 赵东晖,李立奇,彭庆. 运营商大数据引入方案分析[J].移动通信, 2013(21): 69-74.
[4] 陈吉荣,乐嘉锦. 基于Hadoop生态系统的大数据解决方案综述[J]. 计算机工程与科学, 2013,35(10): 25-32.
[5] 全波,姚素丹. 移动互联网时代电信运营商流量经营探索[J]. 电信科学, 2012,28(7): 18-21.
[6] 翟岩龙,罗壮,杨凯,等. 基于Hadoop的高性能海量数据处理平台研究[J]. 计算机科学, 2013,40(3): 100-103.
[7] 康尚钦,李军,叶何亮,等. 基于分布式计算的电信联机采集系统设计[J]. 计算机与现代化, 2013(1): 91-94.
[8] 陈娜,张金娟,刘智琼,等. 基于Hadoop平台的电信大数据入库及查询性能优化研究[J]. 移动通信, 2014(7):58-63.
[9] 彭庆. 基于大数据技术的流量分析平台方案研究[J]. 邮电设计技术, 2014(8): 22-25.
[10] 郭健. 精细化流量经营业务支撑系统的研究与设计[J].电信工程技术与标准化, 2013(4): 1-5.
猜你喜欢
军事运筹与系统工程(2019年4期)2019-09-11
网络安全和信息化(2018年4期)2018-11-09
电子制作(2018年11期)2018-08-04
中国交通信息化(2017年3期)2017-06-08
知识就是力量(2017年2期)2017-01-21
雷达与对抗(2015年3期)2015-12-09
自动化博览(2014年12期)2014-02-28
深圳信息职业技术学院学报(2013年3期)2013-08-22
电子设计工程(2011年24期)2011-06-09
