
论水文计算中的相关性分析方法
2017-05-07 03:18闫宝伟段美壮
水利学报 2017年9期
闫宝伟,潘 增,薛 野,段美壮
(华中科技大学 水电与数字化工程学院,湖北 武汉 430074)
1 水文现象中的相关性及其度量
相关性分析是研究现象之间是否存在某种依存关系,并对具有依存关系的现象探讨其相关方向以及相关程度,是研究随机变量之间相关关系的一种统计方法。相关性普遍存在于水文现象中,无论水文事件内部属性间(如洪水的峰和量等),还是由外部原因(如空间、因果关系等)引起的相关性,如洪水的地区组成和遭遇、降雨和径流的关系等,都是两个或多个变量间的互相关。水文时间序列(如年、月径流)有时会存在短滞时或长滞时的相依关系,属于单个变量不同时序间的相关,称之为自相关。除了单相关即两个变量相关外,一个要素或变量还可能同时与几个要素或变量之间相关,如径流不仅与降雨有关,还受蒸发、气温、下垫面及人类活动等影响,这种相关关系称为复相关,水文计算中的多元回归就属于此类。在多变量情况下,研究两个要素或变量同时消除了其余控制要素影响后的相关,称为偏相关,例如应用偏相关分析可以寻找与径流量显著相关的气象因素和土地利用-覆被变化因素等[1]。相关性分析是水文计算的一项重要内容,深入了解水文现象中出现的这些相关性,并能根据研究对象和分析目的的不同选用适合的分析方法,对解决实际问题将有很大的帮助。
1.1 相关性的度量 水文变量之间的相关性按其度量方式不同可分为相关性指标和相关性结构,其中相关性指标是衡量变量间相关程度的度量指标,包括以下指标。
(1)刻画全局相关性的相关系数,如Pearson线性相关系数ρ、Spearman秩相关系数R和Kendall秩相关系数τ。线性相关系数仅适用于描述呈线性相关关系的变量,而秩相关系数由于具有单调递增变换不变性和对异常数据有较强的抗冲击能力等良好性质,致使它非常适用于描述变量间的非线性相关关系。但它们只是对变量间关联程度的全局度量,不能捕捉到复杂变量的局部相关性特征。
(2)描述极值相关特征的尾部相关系数,包括上尾部相关系数λU和下尾部相关系数λL。尾部相关系数是一个广泛应用于极值理论的相关性测度指标,在分析水文极值事件的属性特征(如洪峰与洪量、干旱历时与烈度等)时发挥着重要作用[2-3],如果不考虑它们之间的尾部相关性,可能会出现高估或低估水文极值事件的风险[3-4]。
(3)表示变量间共享信息量的互信息I,它能够有效捕捉变量间的非线性关系。I越大,变量之间的相关性越强,也可以将互信息看作是相关系数在高维非线性情况下的推广,在水文预报因子的选择和水文模型的不确定性分析等方面有一定的优势[5-7]。
相关性结构是指变量间是以何种模式相关,或者通过什么结构可以将两个或多个变量的概率分布联系起来,通常采用Copula函数描述。Copula函数是定义域为[0,1]均匀分布的多维联合分布函数,它可以将随机变量之间的相关程度和相关模式有机地结合在一起,从而刻画随机变量间的相关性结构。相关性指标是一个单一数值,无法充分反映变量之间的相关特性,而相关性结构能够捕捉变量间所有的相关性信息[8]。
1.2 相关性指标和相关性结构的联系 Copula函数是刻画变量间相关性结构的一种有效工具,它通过参数θ间接地描述变量间的相关性,如对于随机变量X与Y,其边缘分布分别为u和v,则上述相关性指标可由二维Copula函数Cθ(u,v)得出。例如,对于Kendall秩相关系数τ,两者存在如下关系[9]:
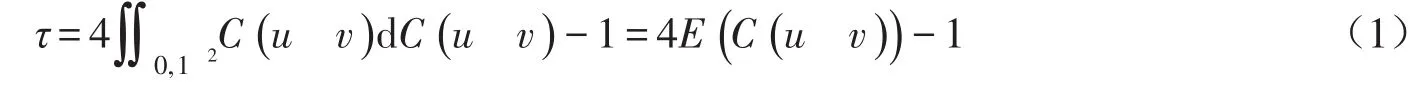
式中:E(·)为期望函数。
对于Spearman秩相关系数R,则存在如下关系[9]:
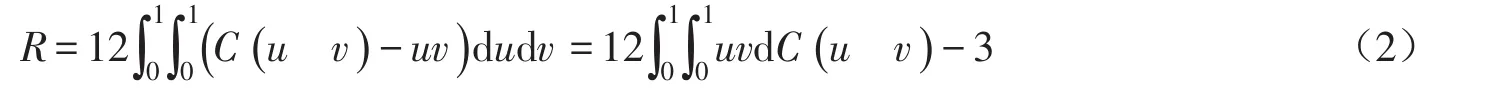
而对于尾部相关系数,引入Copula函数后,λU和λL可简化为[4]:
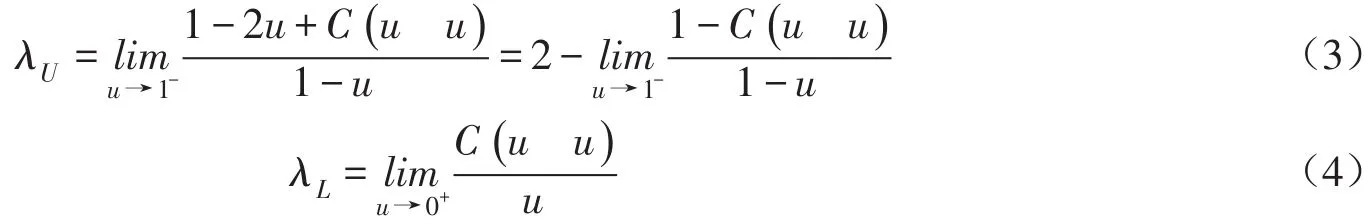
根据互信息的定义,有[10]

其中,HC(uv)称为Copula熵。从而Copula函数将相关性指标与相关性结构有机结合起来,由于随机变量的所有统计特征均包含在边缘分布中,Copula函数通过将联合分布分为边缘分布和相关性结构两部分分别处理,完整地保留了变量间所有关于相关性的信息,逐渐成为水文变量相关性分析的一种理想工具,近几年得到了广泛应用和发展[10-12]。
2 相关性分析方法及适用范围
水文计算中相关性分析的目的,一是插补展延资料,分析目标变量的统计特征;二是通过随机模拟,增大样本容量;三是辨识主要影响因子,简化计算。相应的分析方法包括回归分析、自回归分析、R/S分析、主成分分析及Copula函数等。其中,回归分析是研究两个或多个变量间的互相关性;自回归分析则是分析某一变量时序间的短滞时相关性;R/S分析适用于描述某一变量的长程相依性;主成分分析则试图将多个变量含有的共同成分提取出来,重新组合成一组新的互相无关的综合变量;Copula函数旨在通过构造变量间的联合分布函数,研究变量间的相依概率特征。
2.1 回归分析 回归分析尤其是线性回归分析是进行水文系列插补展延最常用的方法,而实际上建立在二元正态分布假设基础上的线性回归并不是水文系列插补展延的合格方法[13]。究其原因,线性回归中的相关变量X和Y的总体分布是遵循二元正态分布的,而水文变量往往呈偏态型,拿偏态型的水文变量套用只有服从正态分布的变量才适用的方法,本身就存在理论误差,刘光文[13]曾利用两个假想水文系列对线性回归进行误差检验,结果表明,线性回归插补展延的误差往往不小,他认为“人们对水文频率计算从最初即不肯使用正态分布,何以对系列插补展延等水文问题就坦然使用假定二元正态分布的回归相关,岂非自相矛盾”。
由此看来,偏态型的水文变量不宜直接应用线性回归方法,要么经过正态变换后应用[14],要么进行非线性回归分析。回归分析的目的无非是插补展延资料或是预测未来趋势,其实质是求因变量Y在自变量X已知时的期望,即回归方程相当于y=E(y|x),对于偏态型的水文变量,该方程一般为非线性方程,其求解可以借助于Copula函数,如下[15]:

Copula函数的引入,从概率的角度分析了变量间的非线性相依关系,从而可以实现水文变量的非线性回归分析,并可以给出预测的置信区间[15]。以清江隔河岩水库为例,说明这种方法的有效性,其中Copula函数选用Gumbel-Hougaard Copula。
选取清江隔河岩水库坝址断面1960—2003年共44年的年降水与年径流资料,按本文介绍的非线性回归方法,计算出降水-径流的非线性回归曲线及95%的置信区间,如图1所示。便于比较,图中还同时绘出了线性回归的趋势线及95%的置信区间。其中,降水与径流的相关系数r2高达0.929 8,如此高的相关性,线性回归似乎可以取得很精确的插补展延,而事实并非如此,两条趋势线在降水量的均值附近几乎是重合的,在此区间内两种方法都可以进行有效的插补,但对于极值(最不利)样本,线性回归预测值明显小于非线性回归值。以样本中最大值为例,即P=2.2%,线性回归插补值为629.55,非线性回归值为664.71,真实值为671.20,误差分别为-6.21%和-0.97%,外延的误差可能会更高。再者,线性回归的置信区间要大于非线性回归值,尤其是在极值附近,也进一步验证了文献[13]关于“线性回归不是水文系列插补展延的合格方法”的科学论断。
2.2 自回归分析 不同于回归分析,自回归分析的研究对象是一个时间序列,研究的是一个变量短滞时自相关的性质,多用于随机模拟或误差校正。同线性回归模型一样,自回归模型也是建立在正态分布的基础上,对于偏态型的水文变量仍需做一些变换,这样难免在转换过程中出现信息失真。在假定水文时间序列服从马尔柯夫过程的前提下,水文随机模型可以看作是一种条件概率模型,这样模型的重点就转移到如何构造有效的联合分布或条件分布,如基于核密度估计的非参数方法[16-17]。如上所述,Copula函数是构造联合分布的一种有效方法,从而可以将该条件概率模型推广到更一般的情形[18]。
设水文时间序列Xt一阶相依,利用Copula函数可求得Xt依Xt-1的条件分布函数[19],根据抽样的反函数法就可以对水文时间序列进行随机模拟了,称这种基于Copula函数的随机模型为CAR(1)模型[19]。如果Xt是平稳序列,如年径流,则该模型为平稳CAR(1)模型;如果Xt是非平稳序列,如月或日径流等,则该模型为季节性CAR(1)模型[20]。CAR(1)模拟的原理不是对样本进行直接抽样,而是首先生成样本对应的概率值,并且该值是按一定的相依结构进行排序的,然后再以此概率对样本抽样。由于样本序列的所有特性都包含在分布函数里面,所以不会产生信息的失真,能够保持原有序列的分布特征。
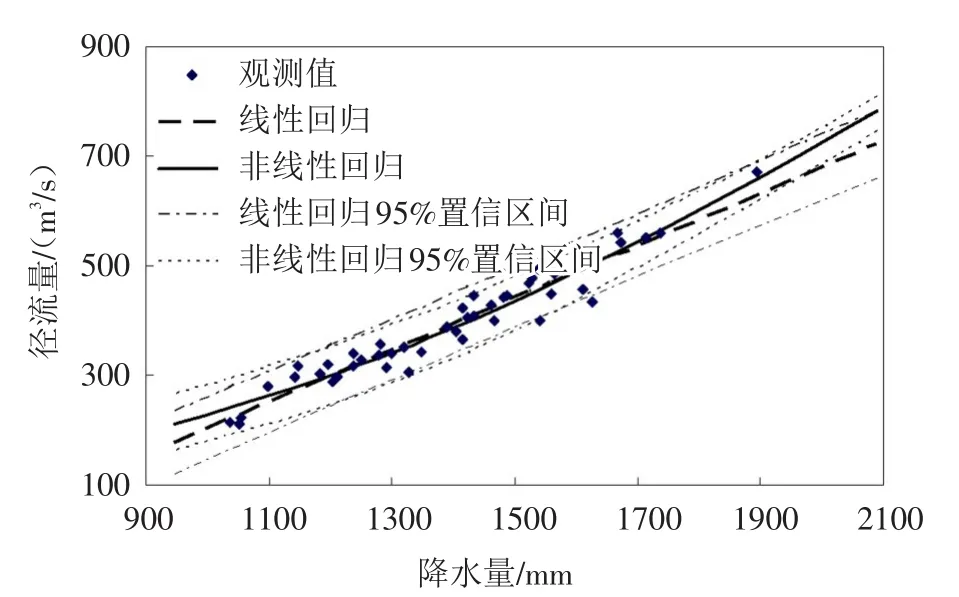
图1 隔河岩水库降水—径流的回归分析
2.3R/S分析 根据相关结构特性,水文时间序列可分为独立、短滞时相关和长滞时相关三种情形。短滞时相关可以由自相关系数来定量表征,长滞时相关结构常由Hurst系数给出。Hurst系数是水文学家Hurst在大量实证研究的基础上提出的,用来定量表征时间序列的持续性或长程相依性[21],一般采用R/S分析法(也称重标极差分析法)计算,其基本内容是:对于一个时间序列{xt},把它分为A个长度为N的等长子区间,对于每一个子区间Ia,记Ra为IM上的极差,Sa为IM上的标准差,计算每个IM上的Ra/Sa,可得A个值,取其平均值记作(R/S)N,Hurst提出并经Mandelbrot证实,有如下关系式存在[22]:

式中:K为常数,h为Hurst系数,可由最小二乘法求得。
为了描述现在对未来的影响,Mandelbrot引进了一个相关性度量的指标C(t),它表示零时刻过去的增量和未来增量的相关系数。根据分数布朗运动理论,得出了C(t)与h的关系:

从分数布朗运动及其相关函数来看,当h=0.5时,任意t时刻过去与未来增量的相关函数C(t)=0,这时序列为独立的随机过程;当h>0.5时,C(t)>0,正相关,即序列未来的变化趋势受过去变化趋势的影响,并且两者的变化趋势相同;当h<0.5时,C(t)<0,负相关,序列未来的变化趋势同样受过去变化趋势的影响,但两者的变化趋势相反。因此R/S分析在时间序列中具有很强的预测预报作用[23],还可以用于水文序列的变异性分析[24]。
布朗运动是分数布朗运动h=0.5时的特例,两者的区别在于布朗运动中的增量是独立的,而分数布朗运动中的增量是非独立的。如果假定水库蓄水过程服从分数布朗运动,即认为在调洪过程中,任意时间间隔的蓄洪量增量不是相互独立的,而是与过去有关,或者认为,任意时刻水库的蓄水量与初始蓄水状态有关,由此可以得到水库调洪演算随机数学模型的一般形式[25-26],即

式中:H(t)为库水位过程,H0为初始库水位;Q(t)为任意时刻入库洪水;(qH,C)为相应时刻的泄洪;、分别为入流和泄洪的均值过程线;C为流量系数等水力参数;G(H)为水库面积-水位关系曲线。
与文献[25]不同的是,Bh(t)服从分数布朗运动而不是维纳过程(布朗运动),由此将水库调洪演算的随机数学模型推广为更一般的情形,通过方程的求解或模拟,可以求得库水位过程的概率密度,进而可以应用于水库的防洪风险分析。
2.4 主成分分析 水文事件往往包含多个特征变量,这些特征变量能从不同的侧面反映所研究对象的特征,但在某种程度上存在信息的重叠,具有一定的相关性,因此有可能用较少的综合指标分别综合存在于各变量中的各类信息。主成分分析就是这样一种方法,在力求数据信息丢失最少的原则下,对高维的变量空间降维,将多个实测变量转换为少数几个不相关的主成分,把各变量之间互相关联的复杂关系进行简化分析。在水文计算中,主成分分析较多的用于提取影响气候变化因子的主成分,建立降水与主成分的回归分析模型,进而对未来降水进行预测[27]。
洪水事件是一个包含洪峰、洪量和峰现时间等多特征变量的极值水文事件,单纯由一个变量分析其重现期是不全面的,文献[28]试图对各个变量加权,求得一个能反映洪水过程量级的综合指标,但由于各变量间存在一定的相关性,直接加权求和可能会使某些重叠信息多次加权,因此,可以考虑采用主成分分析的方法先提取出洪水事件的几个相互独立的主成分,然后对所得的主成分根据方差贡献率加权得到综合指标。现以隔河岩水库为例说明之。
根据隔河岩水库1951—2004年汛期3h时段资料选取历时为7d的年最大洪水过程,描述洪水过程的指标选为洪峰、1d洪量、3d洪量、7d洪量和主峰峰现时间5个指标,分别记为x1、x2、x3、x4和x5。按主成分分析方法,前两个主成分的方差贡献率分别为75.24%和19.26%,累积贡献率接近95%,因此可以认为前两个主成分足以反映整个洪水事件的信息。得到的两个主成分分别为:
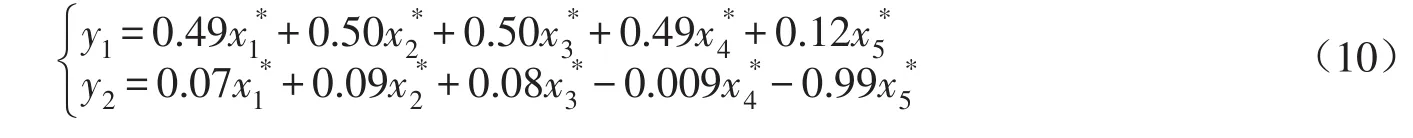
则对两个主成分按方差贡献率进行加权得到的综合指标为:z=0.796y1+0.204y2。
根据所得的综合指标计算每年最大洪水过程的综合指标值,按指标大小对每年的洪水过程进行排序。水库调洪的结果可以作为洪水过程量级的一个较客观的衡量,对洪水的恶劣程度可以按洪水经水库调度所得的最高库水位和最大下泄流量进行排序[28]:对于调洪最高水位高于汛限水位的洪水过程,按调洪最高水位进行排序,对于调洪水位相等的洪水过程,按照最大下泄流量进行排序。将隔河岩水库每年的最大洪水过程输入到水库的调洪程序中,得到每年的最高调洪水位和最大下泄流量。按上述原则对每年的洪水过程进行排序,并与由综合指标法所得的排序进行比较,得到两种方法排序的秩相关系数τ=0.96,优于文献[28]所得结果(τ=0.91),图2绘出了两种排序所得经验频率的P-P图,说明两种排序结果基本一致,尤其是对较严重的几次洪水过程排序完全一致,从而表明所得的综合指标确实能够反映洪水事件的总体量级。

图2 两种排序方法所得经验频率的P-P图

图3 不同样本容量同频率设计值的分布情况
2.5 Copula函数分析法 相关性指标是变量间整体或局部相关程度的衡量,无法完整刻画变量间的相依关系。Copula函数以概率的形式反映变量间的相依性,是描述变量间相关性结构的有效工具,它不仅可以描述变量间的互相关关系,还可以刻画变量的自相关特性,如上面提到的年、月或日径流等的随机模拟。Copula函数所刻画的互相关既可以是同一水文事件的各属性变量,如暴雨、洪水和干旱等极值水文事件的各特征变量[29];还可以是相互之间有关联的不同水文事件,原则上要有一定的物理联系,如不同区域的丰枯遭遇[30]、不同季节的旱涝组合[31]以及干支流或支流间的洪水遭遇问题等[32]。
在数学上,随机变量之间的相关性由多元分布函数完全刻画,Copula函数作为构造多元分布函数的一种有效工具,在理论层面上,可作为一种比较理想的相关性分析方法,但在应用层面上,可能会受到水文样本容量的制约而产生较大的抽样误差,使计算结果失真。以二维Copula函数推求的同频率设计值为例,分析抽样误差对设计值的影响,进而分析Copula函数计算结果的可靠性。图3给出了不同样本容量N下,文献[33]统计试验方案①在相关性系数ρ=0.3、联合概率p=0.999(联合重现期为千年一遇)、模拟次数m=1000时,Copula函数计算的同频率设计值组合,可以看出,样本容量越大,抽样误差越小,推求的设计值越接近于理论值。若推求的设计值相对误差同时小于等于某一给定的许可误差,则认为该设计值组合结果可靠,相应的可靠度即为图中方框内点的个数与所有点的个数的比值。
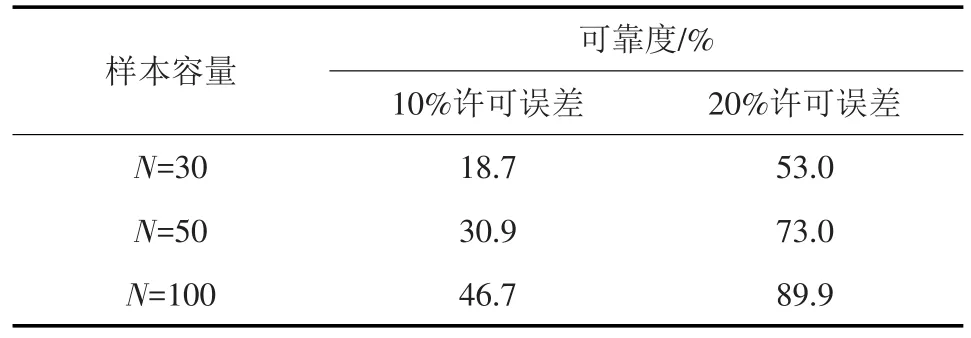
表1 不同样本容量Copula函数计算结果的可靠性分析
表1列出了许可误差分别为10%和20%时,不同样本容量下Copula函数计算结果的可靠度。若许可误差为10%,3种样本容量对应的可靠度都较低,N=100时可靠度也只有46.7%;若降低对许可误差的要求,例如取许可误差为20%,3种样本容量对应的可靠度均有较大程度提高,N=100时可靠度接近90%,即便如此,我国目前也很少有站点能满足该样本容量的要求。因此,即使Copula函数较其他多变量分析方法优势明显[33],但仍然难以摆脱样本容量对它的制约。有限样本容量下,利用大数据理论进一步挖掘样本数据隐含的有效信息,如外延性和相关性等特征,或许可以在一定程度上提高Copula函数计算结果的可靠性。实际应用中,也可根据给定的可靠度和许可误差,参考本例的统计试验确定满足精度要求所需的最小样本数。
3 假相关
假相关一般指两个变量之间表现出的一种虚假的相关关系,而实际并不存在统计关系。假相关可分为两类[34],一类是隐假相关,是由于包含相同的变量造成的,也称自身假相关,例如上下游年径流、径流量与输沙率、降雨历时与降雨强度等,它们之间由于包含了相同的元素而呈现出较强相关性,若利用它们之间的强相关性通过回归分析间接插补展延区间年径流、含沙量和降雨量等,则丝毫无助于计算精度的提高[35],属于典型的回归分析方法的误用。回归方程除了包含反映变量平均关系的确定项之外,还包含反映变量随机性的误差项,但该误差也仅仅是当前因变量的误差,若利用当前自变量、因变量的某种函数关系推算第3个变量,该误差也将不可避免的传递给第3个变量。对于因变量而言,由于其和自变量的高度相关而使误差项可以忽略,但该误差传递到第3个变量时,由于变量的量级发生了变化,误差的影响可能会占据主导地位,从而造成插补展延的失效。
第2类是显假相关,包括点簇假相关、对数变换假相关和辗转假相关等。对于点簇假相关,仍然是回归分析技术的误用,回归分析的前提是样本来自于同一个总体,而点簇分布的样本显然不是,因此会造成相关分析的失效。对数变换是否会造成假相关,不可一概而论,若变量间存在指数函数、幂函数等非线性关系,经对数变换后可转化为线性关系,从而可以继续使用线性回归分析方法;而若利用对数变换将两个不相关的变量处理成看似相关的变量,则会造成视觉上的错觉而误用回归分析。辗转假相关则同第1类假相关类似,存在误差的传递和累积,致使计算结果误差过大而失效。
假相关是相关分析中出现的一种假象,它并非相关分析技术本身的问题,而是误用这种技术所引起的。为了避免误用假相关,不宜对原始变量进行任何数学转换和运算(指数和幂函数关系除外),而应直接研究原始变量。
4 结语
水文变量常呈现非线性和非正态性,线性回归和自回归分析直接用于水文计算时会遇到理论障碍,Copula函数通过描述变量间的相关结构,理论上可以有效解决水文变量的非线性、非正态问题,但在应用层面上,可能会受到水文样本容量的制约而使其计算结果失真,尤其是对于多维Copu⁃la函数更应该慎用。R/S分析能够表征时间序列的长程相依性,如果任意时刻水库的蓄水量与初始蓄水状态有关,则可利用R/S分析法建立更为一般的水库调洪演算随机模型,借此分析水库防洪风险。主成分分析通过对高维变量进行空间降维,可以将洪水事件的多个特征变量转换为少数几个不相关的主成分,进而得到反映洪水恶劣程度的综合指标,实现洪水的综合排序。
相关性分析是水文计算的一项重要内容,几乎涉及到水文计算的各个领域,除了上面列出的几种方法外,还包括典型相关分析、灰关联分析和协整理论等,由于这些方法在水文计算中运用较少,本文不再赘述。此外,还有一些分析计算要尽量避免相关性,例如在水文模型的构建中,参数间要尽量独立,以减少模型的不确定性;在进行多目标优化时,多个目标也要保证相互独立,否则可能会对某个目标多重加权,难以达到优化的目的[36]。相关性分析的先决条件是变量间确实存有物理上的联系,对物理意义上毫无干系却表现出统计关系的变量进行相关性分析反而可能会得到错误的结论,在确保可以应用相关性分析方法解决问题时,还要明晰各种方法的适用条件和范围,避免误用和滥用这种技术。
参 考 文 献:
[1] 冉圣宏,李秀彬,吕昌河.渔子溪流域水文过程影响因素的特征时间尺度分析[J].地理研究,2007,26(2):337-345.
[2] 闫宝伟,郭生练,陈璐,等.Copula函数在水文计算中的适用性分析[J].数学的实践与认识,2012,42(3):85-93.
[3] 刘和昌,梁忠民,常文娟,等.干旱历时与干旱烈度的尾部相关性分析[J].水电能源科学,2014(4):1-3.
[4] POULIN A,HUARD D,FAVRE A-C,et al.Importance of tail dependence in bivariate frequency analysis[J].Journal of Hydrologic Engineering,2007,12(4):394—403.
[5] 赵铜铁钢,杨大文.神经网络径流预报模型中基于互信息的预报因子选择方法[J].水力发电学报,2011,30(1):24-30.
[6] 陈璐,叶磊,卢韦伟,等.基于Copula熵的神经网络径流预报模型预报因子选择[J].水力发电学报,2014,33(6):25-29.
[7] 龚伟,杨大文.水文变量高维非线性相关分析与水文模型结构不确定性评估[J].水力发电学报,2013,32(5):13-20.
[8] 肖义.基于Copula函数的多变量水文分析计算研究[D].武汉:武汉大学,2007.
[9] Nelson R B.An Introduction to Copulas[M].Springer,New York,1999.
[10] 陈璐.COPULA函数理论在多变量水文分析计算中的应用研究[M].武汉:武汉大学出版社,2013.
[11] 郭生练,闫宝伟,肖义,等.Copula函数在多变量水文分析计算中的应用及研究进展[J].水文,2008,28(3):1-7.
[12] 宋松柏.Copulas函数及其在水文中的应用[M].北京:科学出版社,2012.
[13] 刘光文.泛论水文计算误差[J].水文,1992(1):4-11.
[14] 吴燕,李松仕.应用分布转换法插补展延水文系列的探讨[J].福州大学学报,1986(4):70-76.
[15] 闫宝伟,郭生练,郭靖,等.基于Copula函数的设计洪水地区组成研究[J].水力发电学报,2010,29(6):60-65.
[16] SHARMA A,TARBOTON D G,LALL U.Streamflow simulation:a nonparametric approach[J].Water Resourc⁃es Research,1997,33(2):192-308.
[17] 王文圣,丁晶.基于核密度估计的多变量非参数随机模型初步研究[J].水利学报,2003(2):9-14.
[18] CHEN X,FAN Y.Estimation of copula-based semiparametric time series models[J].Journal of Econometrics,2006,130:307-335.
[19] 闫宝伟,郭生练,刘攀,等.基于Copula函数的径流随机模拟[J].四川大学学报:工程科学版,2010,42(1):5-9.
[20] 周研来,郭生练,李天元,等.Copula-SAR模型及其在洪水地区组成随机模拟中的应用[J].武汉大学学报:工学版,2013,46(2):137-142.
[21] HURST H E,BLACK R P,SIMAIKA Y M.Long-term Storage:An Experimental Study[M].London:Consta⁃ble,1965.
[22] MANDELBROT B,VAN NESS J W.Fractional Brownian motion,fractional noise and application[J].SIAM Re⁃view,1968,10:422-437.
[23] 门宝辉,刘昌明,夏军,等.R/S分析法在南水北调西线一期工程调水河流径流趋势预测中的应用[J].冰川冻土,2005,27(4):568-573.
[24] 谢平,雷红富,陈广才,等.基于Hurst系数的流域降雨时空变异分析方法[J].水文,2008,28(5):6-10.
[25] 姜树海,水库调洪演算的随机数学模型[J].水科学进展,1993,4(4):294-300.
[26] 闫宝伟,郭生练.考虑洪水过程预报误差的水库防洪调度风险分析[J].水利学报,2012,43(7):803-807.
[27] 陈华,郭靖,郭生练,等.应用统计学降尺度方法预测汉江流域降水变化[J].人民长江,2008,39(14):53-55.
[28] 肖义,郭生练,刘攀,等.综合多特征量的洪水事件频率问题研究[J].人民长江,2007,38(4):127-129.
[29] 冯平,李新.基于Copula函数的非一致性洪水峰量联合分析[J].水利学报,2013,44(10):1137-1147.
[30] 闫宝伟,郭生练,肖义.南水北调中线水源区与受水区降水丰枯遭遇研究[J].水利学报,2007,38(10):1178-1185.
[31] 杨志勇,袁喆,方宏阳,等.基于Copula函数的滦河流域旱涝组合事件概率特征分析[J].水利学报,2013,44(5):556-561.
[32] 闫宝伟,郭生练,陈璐,等.长江和清江洪水遭遇风险分析[J].水利学报,2010,41(5):553-559.
[33] 闫宝伟,郭生练,郭靖,等.多变量水文分析计算方法的比较[J].武汉大学学报:工学版,2009,42(1):10-15.
[34] 丁晶,杨树林.论水文计算中的假相关[J].四川水力发电,1987(4):13-19.
[35] 马秀峰.回归分析中的伪相关与辗转相关[J].水文,1986(6):6-16.
[36] 纪昌明,李荣波,刘丹,等.梯级水电站负荷调整方案评价指标体系及决策模型[J].水利学报,2017,48(3):261-169.
猜你喜欢
河北地质(2021年3期)2021-11-05
筑路机械与施工机械化(2020年7期)2020-08-20
河南水利年鉴(2020年0期)2020-06-09
河南水利年鉴(2020年0期)2020-06-09
娃娃乐园·综合智能(2019年6期)2019-07-10
天津诗人(2017年2期)2017-11-29
河南水利年鉴(2017年0期)2017-05-19
少儿科学周刊·儿童版(2015年7期)2015-11-24
水利水电科技进展(2014年1期)2014-10-17
测绘通报(2013年2期)2013-12-11
