
样本量估计及其在nQuery+nTerim和SAS软件上的实现*
——群随机试验(三)
2018-07-16 06:08曹颖姝陈平雁
中国卫生统计 2018年2期
周 军 曹颖姝 陈平雁
南方医科大学生物统计学系(510515)
7.2.4 配对设计的差异性检验
方法:Donner & Klar(2000)[3]提出的配对群随机设计两个率差异性检验的样本量估计建立在大样本正态近似理论基础上,其检验效能公式为:
(7-7)
其中,
(7-8)
式(7-7)为双侧检验,单侧检验时只需将α/2替换为α。式中,k为配对的群对子数,简称群对子数;n为每个群的样本量,简称群样本量;π1和π2分别为试验组和对照组的事件发生率;σB为群间标准差。
在计算群对子数(群样本量)时,需给定群样本量(群对子数)。首先设定群对子数(群样本量)的初始值,然后迭代群对子数(群样本量)直到满足设定的检验效能为止。此时的群对子数(群样本量),即研究所需的最小群对子数(群样本量)。
【例7-8】某试验欲评价社区控烟干预对重度吸烟者戒烟的有效性。采用配对群随机设计,将社区作为群,把特征相近的社区匹配成对子,对子中的两个社区分别随机分到试验组或对照组。试验组接受为期4年的社区控烟干预,对照组无干预。主要评价指标是4年后戒烟率。假设试验组和对照组4年后的戒烟率分别为25%和15%,群间方差为0.00318,每群抽取500名受试者,检验水准设为0.05,采用双侧检验,试估计当检验效能为90%时所需的社区个数及总样本量[7-8]。
nQuery+nTerim 4.0实现
设定检验水准α=0.05,采用双侧检验,检验效能取1-β=90%。
在nQuery+nTerim 4.0主菜单选择:
方法框中选择:CRT Two Proportions Inequality Matched Pair
在弹出的样本量估计窗口计算框中选择:Calculate required number of matched pairs of clusters for given power and sample size,将各参数值键入,结果如图7-15所示,即共需8对(16个)社区,每个社区需随机抽取500名受试者,本研究总的样本量为8000人。

图7-15 nQuery+nTerim 4.0关于例7-8样本量估计的参数设置与计算结果
SAS 9.3 软件实现
Proc IML;
Start CPMP(a,side,format,e1,p2,sitab2,index,x,power);/*index为指示变量,index=1表示求群对子数,此时需要赋值x为群样本量;index=2表示求群样本量,此时需赋值x为群对子数;a为显著性水准;side表示单双侧检验;k为群对子数;N为群样本量;format为指示变量*/
error=0;if(a>1|a<0)|(p2<=0|p2>=1)|(index^=1 & index^=2)|(x<=0)|(sitab2<=0)|(format^=1 &format^=2 & format^=3)|(side^=1 & side^=2 )|(power>100|power<1) then error=1;if error=1 then stop;if(format=1) then do; p1=p2+e1;solve="Differences";end;if(format=2) then do;
p1=e1;solve="Proportions"; end;if(format=3) then do; p1=p2#e1;solve="Ratios"; end;y=1;do until(pw>=power);y=y+1;if(index=1) then do;N=x;k=y;end;if(index=2) then do;k=x;N=y;end;
vd=sqrt((p1#(1-p1)+p2#(1-p2))/N+2#sitab2);pw=100#CDF('NORMAL',(abs(p1-p2)#sqrt(k))/vd-probit(1-a/side));end;pw=round(pw,0.001);print a[label="α"] side[label="1 or 2 sided"] solve[label="Solve using (p1-p2),(p1) or (p1/p2)"] e1[label="(p1-p2),(p1) or (p1/p2) under H1"] p2[label="p2"] sitab2[label="σ2B"] k[label="k"] N[label="N"] pw[label="Power(%)"];finish CPMP;
run CPMP(0.05,2,2,0.25,0.15,0.00318,1,500,90);/*例7-8*/;quit;
SAS 9.3 运行结果:
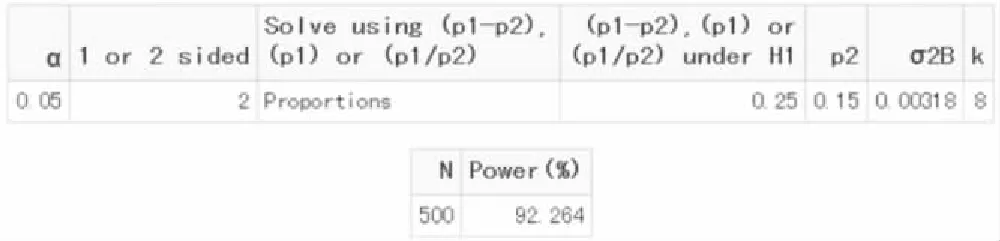
图7-16 SAS 9.3关于例7-8样本量估计的参数设置与计算结果
7.3两个发病密度的比较
7.3.1完全群随机设计的差异性检验
方法:Donner & Klar(2000)[3]和Hayes & Behnett[9]提出的完全群随机设计下两个发病密度差异性检验的样本量估计建立在大样本正态近似理论基础上,其检验效能公式为:
(7-9)
(7-10)
式(7-9)为双侧检验,单侧检验时只需将α/2替换为α。式中,m为每组群的个数,简称群数;n为群样本量;t为每个观察对象被观察的时间;λ1为试验组的发病密度,λ2为对照组的发病密度,CV为群间变异系数,由群间标准差除以均数得到,这里假设试验组和对照组的群间变异系数相等。
在计算群数(群样本量)时,需给定群样本量(群数)。首先设定群数(群样本量)的初始值,然后迭代群数(群样本量)直到满足设定的检验效能为止。此时的群数(群样本量),即研究所需的最小群数(群样本量)。
【例7-9】某试验欲评价改进的性病治疗服务对治疗性病的有效性。采用完全群随机设计,将社区作为群,试验组在社区接受改进的性病治疗服务,对照组采用常规治疗。研究的主要疗效指标是HIV感染人年发病率。假设试验组和对照组HIV感染人年发病率分别为0.5%和1%,群间变异系数为0.25,每个社区可抽取1000位居民,每人随访2年。设定检验水准为0.05,采用双侧检验,试估计当检验效能为80%时所需的社区个数及总样本量[10]。
nQuery+nTerim 4.0实现
设定检验水准α=0.05,采用双侧检验,检验效能取1-β=80%。
在nQuery+nTerim 4.0主菜单选择:
方法框中选择:CRT Two Rates Completely Randomized
在弹出的样本量估计窗口计算框中选择:Calculate required number of clusters for given power and sample size,将各参数值键入,结果如图7-17所示,即每组需要5个社区,每个社区需随机抽取1000居民,本研究总的样本量为10000人。
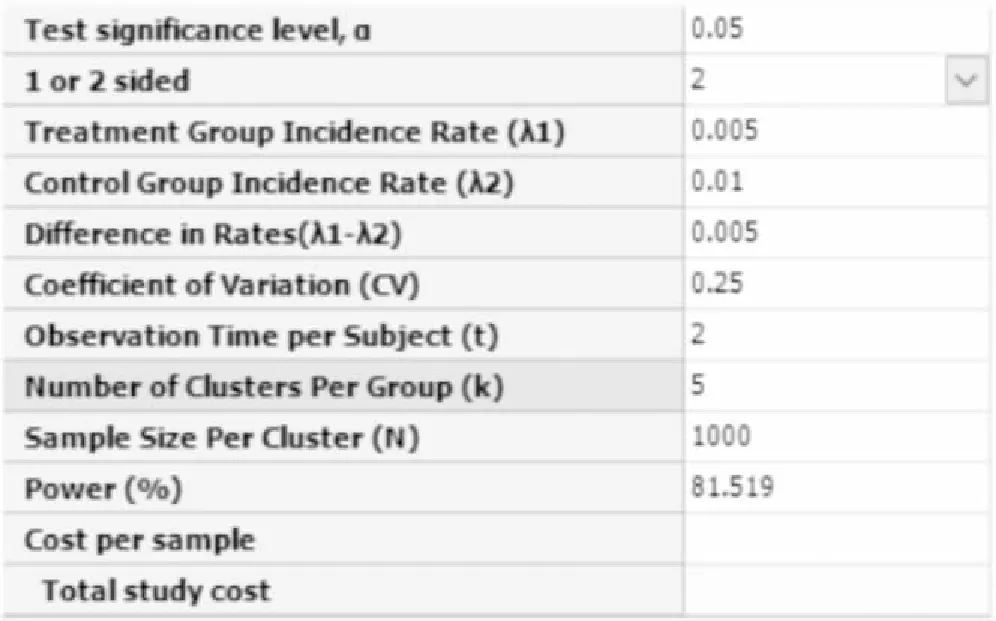
图7-17 nQuery+nTerim 4.0关于例7-9样本量估计的参数设置与计算结果
SAS 9.3软件实现
Proc IML;
Start CRCR(a,s,lamda1,lamda2,CV,t,index,x,power);/*t为每个个体的观察时间;index为指示变量,index=1时表示求群数,此时需要赋值x为群样本量;index=2时表示求群样本量,此时需赋值x为群数;t为每个观察对象被观察的时间;k为研究所需群数*/
error=0;if(a<0|a>1)|(s^=1& s^=2)|(lamda1<0|lamda1>1)|(lamda2<0|lamda2>1)|(index^=1 & index^=2)|(power>100|power<1) then error=1;
if error=1 then stop;cha=abs(lamda1-lamda2);y=1;do until(pw>=power);y=y+1;
if(index=1) then do;N=x;k=y;end;if(index=2) then do;k=x;N=y;end;
IF=1+CV##2#(lamda1##2+lamda2##2)#N#t/(lamda1+lamda2);pw=100#CDF(′NORMAL',sqrt(N#t#k#(lamda1-lamda2)##2)/sqrt((lamda1+lamda2)#IF)-probit(1-a/s));end;pw=round(pw,0.001);print a[label="α"] s[label="1 or 2 sided"] lamda1[label="λ1"] lamda2[label="λ2"] cha[label="λ1-λ2"] CV[label="CV"] t[label="t"] k[label="k"] N[label="N"] pw[label="Power(%)"];finish CRCR;
run CRCR(0.05,2,0.005,0.01,0.25,2,1,1000,80);/*例7-9*/;quit;
SAS 9.3 运行结果:

图7-18 SAS 9.3关于例7-9样本量估计的参数设置与计算结果
7.3.2配对群随机设计的差异性检验
方法:Donner & Klar(2000)[3]提出的配对群随机设计下两个发病密度差异性检验的群随机设计样本量估计建立在大样本正态近似理论基础上,其检验效能公式为:
(7-11)
(7-12)
式(7-11)为双侧检验,单侧检验时只需将α/2替换为α。式中,k为群对子数;ρ为配对的对子间平均相关系数,其余参数含义同上。
在计算群对子数(群样本量)时,需给定群样本量(群对子数)。首先设定群对子数(群样本量)的初始值,然后迭代群对子数(群样本量)直到满足设定的检验效能为止。此时的群对子数(群样本量),即研究所需的最小群对子数(群样本量)。
【例7-10】某试验欲评价长效驱虫蚊帐是否会降低黑死病的人年发病率,采用配对群随机设计,将地区作为群,将特征相近的地区配对成对子。试验组使用长效驱虫蚊帐,对照组无干预。预期1年后黑死病的人年发病率试验组为1%,对照组为2%。假定每个地区有500人参加,群间变异系数为0.5,对子间平均相关系数为0.5,采用双侧检验,检验水准为0.05,试估计检验效能为90%时所需群对子数及总样本量[11]。
nQuery+nTerim 4.0实现
在nQuery+nTerim 4.0主菜单选择:
方法框中选择:CRT Two Rates Matched Pair
在弹出的样本量估计窗口计算框中选择:Calculate required number of clusters for given power and sample size,将各参数值键入,结果如图7-19所示,即每组需要10个地区,每个地区需随机抽取500人,本研究总的样本量为10000人。
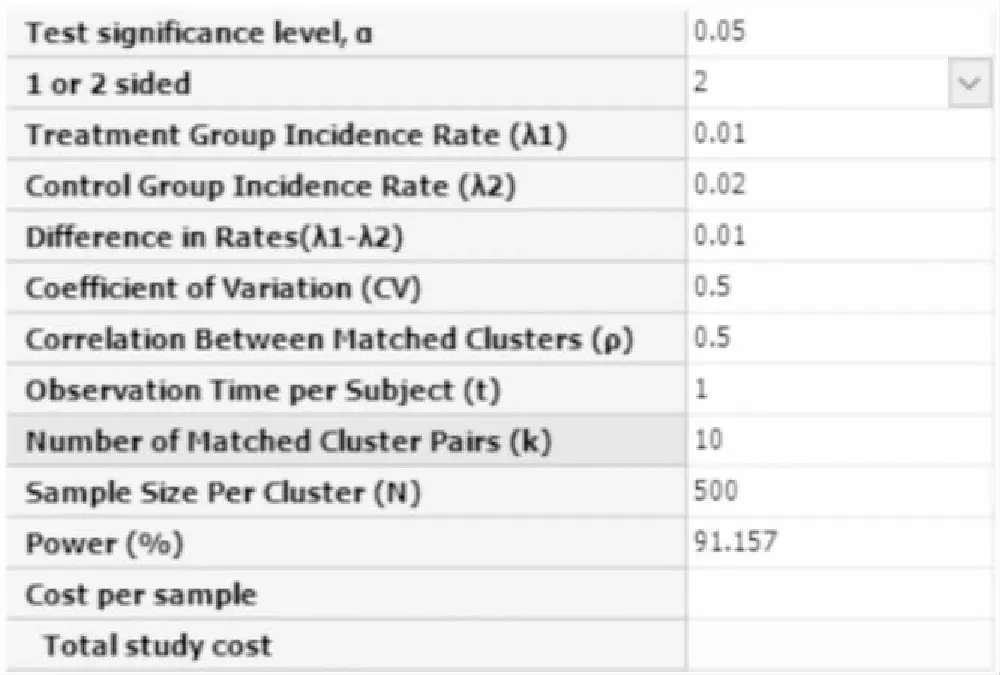
图7-19 nQuery+nTerim 4.0关于例7-10样本量估计的参数设置与计算结果
SAS 9.3软件实现
Proc IML;
Start CRMP(a,s,lamda1,lamda2,CV,rou,t,index,x,power);/*index为指示变量,index=1时表示求群对子数,此时需要赋值x为群样本量;index=2时表示求群样本量,此时需赋值x为群对子数;rou为配对对子间平均相关系数;t为每个观察对象被观察的时间;k为研究所需群数*/
error=0;if(a<0|a>1)|(s^=1 & s^=2)|(lamda1<0|lamda1>1)|(lamda2<0|lamda2>1)|(rou<0|rou>1)|(index^=1 & index^=2)|(power>100|power<1) then error=1;if error=1 then stop; cha=abs(lamda1-lamda2); y=1;do until(pw>=power);y=y+1;if(index=1) then do; N=x; k=y; end; if(index=2) then do; k=x; N=y; end; IF=1+((CV#(1-rou))##2)#(lamda1##2+lamda2##2)#N#t/(lamda1+lamda2);pw=100#CDF(′NORMAL',sqrt(N#t#k#(lamda1-lamda2)##2)/sqrt((lamda1+lamda2)#IF)-probit(1-a/s));end;pw=round(pw,0.001);print a[label="α"] s[label="1 or 2 sided"] lamda1[label="λ1"] lamda2[label="λ2"] cha[label="λ1-λ2"] CV[label="CV"] rou[label="ρ"] t[label="t"] k[label="k"] N[label="N"] pw[label="Power(%)"];finish CRMP;
RUN CRMP(0.05,2,0.01,0.02,0.5,0.5,1,1,500,90); /*例7-10*/;quit;
SAS 9.3 运行结果:

图7-20 SAS 9.3关于例7-10样本量估计的参数设置与计算结果
群随机设计复杂多样,本系列只是介绍了两个均数、率和发病密度的比较。需要指出,对于两个均数以及两个发病密度比较的等效性/非劣性检验的样本量估计方法尚待提出。
猜你喜欢
内蒙古统计(2021年4期)2021-12-06
中国卫生统计(2019年3期)2019-07-10
中国卫生统计(2019年3期)2019-07-10
飞天(2019年6期)2019-07-08
文物鉴定与鉴赏(2017年11期)2017-11-27
科技与创新(2017年3期)2017-03-17
电脑知识与技术(2016年22期)2016-10-31
科技与创新(2015年23期)2015-12-08
农业科技与装备(2014年11期)2015-02-02
中国卫生统计(2012年1期)2012-12-04
