
基于SFA的中国物流业效率研究
2018-08-06 06:34刘俊华GUOJuLIUJunhua
物流科技 2018年7期
郭 举,刘俊华 GUO Ju,LIU Junhua
(内蒙古工业大学 经济管理学院,内蒙古 呼和浩特 010051)
(School of Economic and Management,Inner Mongolia University of Technology,Hohhot 010051,China)
0 引 言
随着我国区域协调发展进程不断推进,产业分工趋势不断增强,物流业逐渐被认为是继降低物资消耗、提高劳动生产率之后的又一利润源泉。近年来,我国物流业发展迅猛,日趋成为中国国民经济中至关重要的基础服务业。物流业作为现代服务业的重要组成部分,对促进国民经济高效运行、调整产业结构、扩大内需等都具有积极影响。但目前我国物流业发展存在一些突出问题,其中物流业效率问题一直是物流业发展的瓶颈,阻碍了我国物流业向绿色、高效和集约化方向发展。杨川梅(2014)[1]指出,中国制造业物流成本占产品成本的30%~40%,比发达国家高出10个百分点。因此,研究我国物流业效率及其影响因素,对节约物流成本促进我国物流业高效发展具有十分重要的意义。
目前,对于物流业效率的研究,国内学者主要采用非参数的数据包络分析(DEA)。刘俊华等(2014)[2]采用DEA测度了2007~2012中国西部12省区的物流业全要素生产率。马丁(2017)[3]运用DEA对2001~2014年陕西省物流效率进行了实证研究。但是DEA在测度效率时没有考虑随机误差,所有样本共用一个确定性生产前沿,估计结果容易受异常数据的影响。带参数的随机前沿分析(SFA)将随机误差项与技术无效率项分离,避免了直接将随机误差不恰当地计入技术无效率中,并充分利用了每个样本的信息,估计结果稳健性更高,较为科学合理。因此,本文采用SFA对我国物流业效率及其影响因素进行研究。
1 SFA介绍
随机前沿分析是一种考虑了随机因素的带参数前沿分析方法,以实际产出与随机前沿产出比值作为技术效率值。SFA需要事先设定生产函数形式,进行模型假设,然后对模型进行检验,并对前沿生产函数进行参数估计同时对技术效率进行测度。
随机前沿分析一般形式如下所示:

式(1)中,y表示产出,x表示投入,β为待估参数。随机扰动分为两部分:一部分用于表示统计误差,被称为随机误差项,用v来表示,v:iddN(0),主要由不可控因素引起,如自然灾害、政策环境、测量误差等;另一部分用于表示技术的无效率,被称为技术无效率项,用u表示,通常假设u服从半正态、截断正态和指数分布,技术无效率项取值在0~1之间。面向产出的技术效率表示为实际产出与前沿产出的比值:

在u的分布已知的情况下,利用最大似然估计可以估计出模型参数以及技术效率的平均值TE=E[exp(-u)]。根据Jondrow,Lovely Materov&Schmidt(1982)[4]提出的混合误差分解方法,将技术效率表示为TE=exp[-E(u|ε)],可以从混合误差(v-u)项中分离出技术无效率项u,进而可以求出每个决策单元的效率值。
2 物流业效率SFA模型构建
Aigner等(1977)[5]和Meeusen等(1977)[6]同时提出考虑了时间变量和随机误差项的基于柯布道格拉斯(Cobb-Douglas)生产函数的SFA模型,能利用面板数据更合理地测度技术效率。Battese等(1995)[7]巧妙地将技术效率影响因素引入SFA模型,既考虑了技术效率随时间的变化,又能“一步”完成对技术效率及其影响因素的估计,避免了“两步法”因技术无效率效应相互独立假设不具有一致性而产生的估计结果偏差,被广泛运用于实证研究。柯布道格拉斯生产函数因为函数形式简单且具备良好的经济学特性,在实证分析和应用中被广泛使用。因此,本文选用基于柯布道格拉斯生产函数的Battese等(1995)提出的“一步法”SFA模型,对我国物流业效率及其影响因素进行研究。SFA模型如下所示:
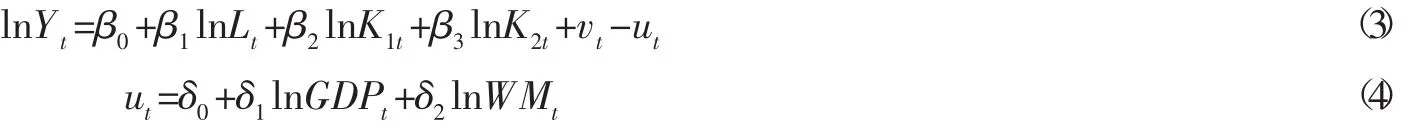
式(3) 中Yt表示第t年物流业产出,Lt和Kt分别表示第t年物流业劳动和资产投入,vt表示随机噪声,ut表示技术无效率。。式 (4) 中 GDPt和 WMt分别表示第 t年的国内生产总值和网民数量。β和δ表示待估参数。在既定的技术水平和要素投入条件下,面向产出的第t年的技术效率为:
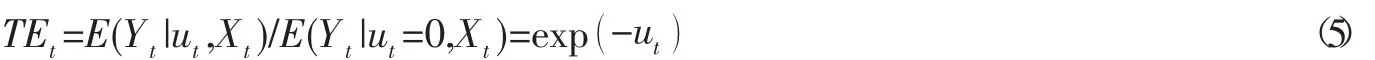
3 数据来源与变量说明
本文所使用数据均来源于2008~2017年历年的《中国统计年鉴》。由于我国国民经济行业分类中并没有明确提出物流产业,通过历年统计数据分析发现,我国交通运输业增加值占物流业增加值80%以上,物流业以交通运输业为核心,两者高度相关,所以本文选取交通运输业数据作为物流业数据。投入考虑劳动和资本两个方面,以货运周转量(Yt,单位:亿吨·公里)作为物流业产出。劳动投入选取的是交通运输从业人员数(Lt,单位:人),包括铁路运输业、道路运输业以及装卸搬运和运输代理业从业人员;资产投入选取的是运输工具的数量(单位:辆),由于铁路货车和公路货车差异很大,故分别考虑,铁路货车辆数用K1t表示,公路货车辆数用K2t表示。考虑的可能影响物流业效率的两个外生变量是国内生产总值(GDPt,单位:亿元)和网民数量(WMt,单位:人)。
4 模型估计与效率分析
4.1 模型估计
运用Frontier4.1对SFA模型进行估计,估计结果如表1所示:

表1 模型估计
表1中γ值为0.99且在10%的水平下显著,说明SFA模型是合适的。劳动投入L的系数为0.06且在5%的水平下显著,说明每增加一单位从业人员数投入,货物周转量将增加0.06单位;资产投入K1和K2的系数分别为-2.34和-0.02,前者在20%的水平下显著而后者不显著,说明运输工具投入对货物周转量已经存在冗余,铁路货车辆数冗余情况较为明显。外生变量GDP和WM的系数分别为-0.27和-1.01,前者不显著,后者在10%的水平下显著,说明国内生产总值和网民数量对我国物流业效率均存在促进作用,国内生产总值的促进作用不明显,而网民数量的促进效果显著。
4.2 效率分析
通过Frontier4.1对SFA模型完成估计,可得2007~2016年中国物流业效率估计结果,如表2所示:

表2 2007~2016年中国物流业效率
根据2007~2016年各年份中国物流业效率值,可得我国物流业效率在2007~2016年的变化趋势如图1所示:
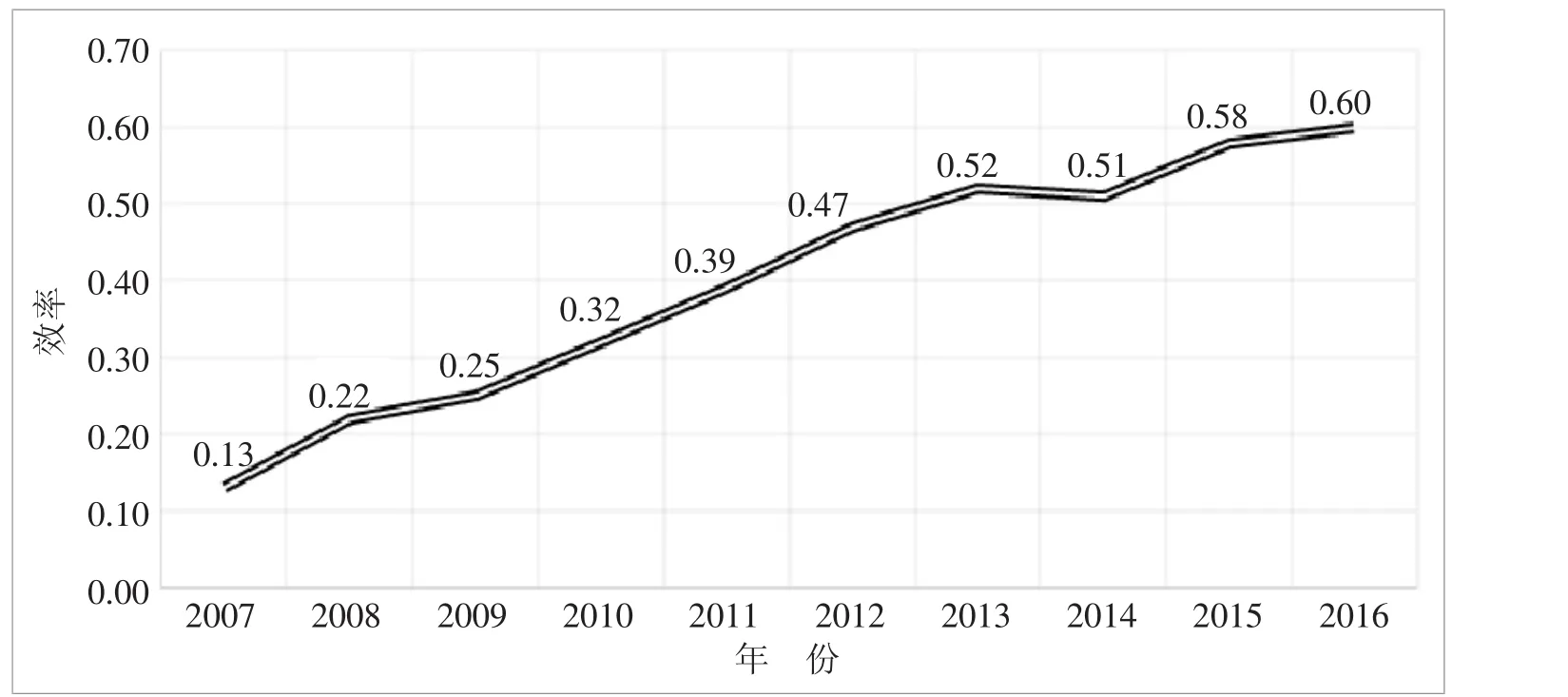
图1 2007~2016年中国物流业效率变化趋势
由表2可知,2007~2016年我国物流业平均效率水平为0.40,效率水平较低。由图1可以看出我国物流业效率在2007~2016年总体呈上升趋势,仅在2014年同比回落了0.01,具体原因有待分析。
5 结论和建议
本文根据2007~2016年我国物流业相关投入产出数据,运用SFA对我国物流业效率及其影响因素进行了研究,得出以下结论并给出针对性建议:
近10年,我国物流业效率总体呈上升趋势,但是平均效率水平仍然较低。网民数量对我国物流业效率有明显的促进作用,政府相关部门可以通过完善我国互联网基础设施建设,优化互联网上网环境,提高互联网服务水平,扩展农村互联网业务,提高我国网民数量。物流从业人员数投入能有效地提高物流货物周转量,因此国家可以创造有利条件吸纳更多物流从业人员。但是运输工具数量已经存在冗余,单纯的增加运输工具将导致物流产出的下降,可减少对运输工具进行不必要的投资,在已有基础上进行合理调度,实施内涵式管理,充分利用已有运输工具。
猜你喜欢
甘肃教育(2020年14期)2020-09-11
物流技术与应用(2019年8期)2019-09-04
汽车观察(2018年12期)2018-12-26
江苏年鉴(2018年0期)2018-02-12
中国制笔(2016年1期)2016-12-01
时代英语·高二(2015年1期)2015-03-16
现代企业(2015年2期)2015-02-28
中国卫生(2014年11期)2014-11-12
江苏年鉴(2014年0期)2014-03-11
体育师友(2011年2期)2011-03-20
