
长相依均值渐变模型的Ratio检验
2018-12-24 10:43赵文芝任肖霖
西北大学学报(自然科学版) 2018年6期
赵文芝,任肖霖
(西安工程大学 理学院,陕西 西安 710048)
在对实际的金融数据进行分析的过程中,学者们发现金融市场经常会受到一些突发事件的影响,而使得金融数据在某个时刻k后,样本的分布或分布参数缓慢地开始变化。在对金融数据进行建模时,必须对渐变变点时刻进行检验。所以对均值渐变模型的变点检验也是统计学的研究热点。Jaruškov(1998)[1]对随机误差项为独立同分布序列的均值渐变模型进行了对数似然比检验,得出检验统计量的渐近分布为Gumbel分布;Huškov(1999)[2]对随机误差项为独立同分布序列的均值渐变模型进行研究,得到变点估计量的收敛速度及其极限分布;Huškov与Steinebach (2000)[3]使用CUSUM方法对渐变变点进行检验,得到检验统计量的极限分布;Alexander和Josef(2002)[4]研究随机误差项满足弱不变原理的渐变随机过程中变点的估计,并给出变点估计量的收敛速度;Madurkayova(2007)[5]对随机误差为独立同分布序列的均值渐变模型运用RCUSUM函数的比率构造Ratio统计量,进行单变点检验; Steinebach和Timmermann (2011)[6]研究了具有漂移项的随机过程中渐变变点,并对其进行序贯检验;Timmermann (2014)[7]对渐变变点进行在线监测,得到零假设和备择假设下检验统计量的极限分布;Vogt和Dette(2015)[8]研究了非参数模型中渐变变点估计量的渐近分布;Timmermann (2015)[9]研究了随机误差项满足弱不变原理的渐变随机过程,得到序贯检验统计量的极限分布。对于长相依序列,则有Wang Lihong和Wang Jinde[10]研究了带有长记忆性的移动平均模型(MA)中方差突变点的检测问题,在均值已知的情况下得到了未知变点的估计量及估计量的收敛速度,在均值未知的情况下得到原假设和备择假设下检验统计量的极限分布;Wang Lihong (2007)[11]给出随机误差为长相依序列的均值渐变变点的最小二乘估计量,得到该估计量的收敛速度;Wang Lihong (2008)[12]研究了长记忆MA模型中均值变点问题。
检验渐变变点问题最常用的方法是累积和(CUSUM)方法,然而现有的CUSUM检验在讨论检验统计量渐近性质时要求原假设与备择假设下对模型的尺度参数的估计应该是一致的。事实上,在观察值独立的情况下,对模型的尺度参数的估计也并不容易,相依序列的情况就更为复杂。本文基于CUSUM函数的比率构造了Ratio统计量,避免了CUSUM方法中的尺度参数估计,得到了零假设和备择假设下检验统计量的极限分布。
1 Ratio统计量
考虑如下均值渐变模型:
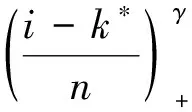
(1)
其中k*为未知变点,a+=max(0,a),μ,δ≠0,γ∈[0,1]均为未知参数。
假设
(2)
其中,{εj,-∞ 0 (3) 符号‘~’表示左边与右边的比率趋近于1。由文献[11]可知,式(2),(3)定义的{ei}是带有长记忆性的线性平稳过程。 假设检验如下: H0:k*=n; H1:k* 考虑Ratio检验统计量 (4) 其中[na]表示取整,0 定理1假定Y1,…,Yn满足模型(1)且原假设H0成立,有 (5) 证明由文献[13]中式(2),(6)可得,存在一个分数布朗运动{Bd(y):0≤y<∞},0 (6) 其中κ是一个常数。 由文献[14]可知 (7) 其中 因此,有 O((logT)1/2)a.s. (8) (9) 由文献[3]中式(2.14)类似可得 因此 (10) 其中i,k=1,…,n,i 取k=[nt],i=[ns],0 Bd([nt]-m′+1)-Bd(n(t-y))dy]= (11) (12) 对于一个给定的k=[nt],结合式(10)~(12),有 (13) 类似地,可得 (14) 结合式(13),(14),可得定理结论。 定理2假设Y1,…,Yn满足模型(1)且k*=[nt],对任意的0 n1/2|δn|→∞, (15) 则在备择假设H1下,对a (16) 证明取k=k*,i=k*。 上式中方括号内的表达式有非零的正极限。因此由式(15)可知当n→∞时 定理1给出了原假设下检验统计量的极限分布,定理2给出了备择假设下统计量依概率趋于无穷,这说明当检验统计量的值大于临界值时拒绝原假设。 首先采用Monte Carlo方法对检验统计量Zn的极限分布进行数值模拟得到临界值。考虑到直接分析检验统计量Zn的极限分布较难,本文采用检验统计量的样本分位数来近似检验统计量极限分布的分位数。 考虑如下数据生成过程: 其中n为样本容量,k*为变点位置,ei为FARIMA(0,d,0)过程。 首先验证d的变化对假设检验的影响,取k*=n=1 000,μ=1,δ=2,γ=1,取d=0.1,0.2,0.3,0.4,对每一个d,分别对产生长度为1 000的FARIMA(0,d,0)序列,代入Zn可计算得一个值,重复进行1 000次得到1 000个样本,用该样本的分位点来近似统计量的极限分布的分位点,得到检验统计量极限分布的α分位数,如表1。 表1 检验统计量极限分布的α分位数Tab.1 α quantile of cimiting distribnt 分别取样本容量n=500,800,1 000,μ=0,δ=2,γ=1,重复进行1 000次试验,检验水平α=0.05。模拟的经验水平和经验势函数值见表2和表3。同时运用文献[11]中所给的CUSUM检验的分位数,模拟所得的经验水平和经验势函数值见表2和表3括号中的数值。 表2 Zn的经验水平Tab.2 The empirical siye of Zn 注:括号中的数据为CUSUM检验法得到的经验水平值。 由表2可知,当d=0.1时,样本容量n越大,Ratio检验统计量的检验水平越接近于0.05,检测水平失真较小。同时,CUSUM检验的检验水平失真也较小。 表3 Zn的经验势函数值Tab.3 The emipirical power of Zn 注:括号中的数据为CUSUM检验法得到的经验势函数值。 由表3可知,当样本容量增加时,Ratio检验统计量经验势函数值也在增加,而且样本容量越大,经验势函数值越接近于1,检验的效果越好。同时,与CUSUM检验法相比,Ratio检验统计量的经验势函数值更接近1,检验效果更胜一筹。 由表2和表3可知,d越大,假设检验统计量的经验水平失真越小,经验势函数值越接近于1。 然后,验证γ的变化对假设检验的影响。分别取样本容量n=500,800,1 000,μ=0,δ=2,d=0.1,γ=0,0.25,0.5,0.75,1,重复进行1 000次试验,检验水平α=0.05。模拟的经验水平和经验势函数值见表4和表5。同时运用文献[11]中所给的CUSUM检验的分位数,模拟所得的经验水平和经验势函数值见表4和表5括号中的数值。 表4 Zn的经验水平Tab.4 The empirical siye of Zn 注:括号中的数据为CUSUM检验法得到的经验水平值。 由表4可知,当γ=1时,样本容量n越大,Ratio检验统计量的检验水平越接近于0.05,检测水平失真较小。同时,CUSUM检验的检验水平失真也较小。 表5 Zn的经验势函数值Tab.5 The empirical power of Zn 注:括号中的数据为CUSUM检验法得到的经验势函数值。 由表5可知,当样本容量增加时,Ratio检验统计量经验势函数值也在增加,而且样本容量越大,经验势函数值越接近于1,检验的效果越好。同时,与CUSUM检验法相比,Ratio检验统计量的经验势函数值更接近1,检验效果更胜一筹。 实例 为验证Ratio检验法的有效性,以全球平均温度为例,分析从1880年到1980年的101个历史数据(数据来自http://www.datatang.com/data/3490),首先得到原始数据的时序图,如图1所示。 图1 全球平均温度时序图Fig.1 Global average temperature sequence diagram 从图1观察发现,所选时间段间的数据呈现渐变的趋势,可能存在变点。用本文的Ratio检验法,假设检验如下: H0:k*=101; H1:k*<101,δ≠0。 将所选数据带入检验统计量Zn中,计算得到在α=0.05检验水平下,Ratio检验统计量Zn=1.198,大于d=0.1,μ=0,δ=2,γ=1时对应的临界值0.305 7,因此拒绝原假设,也就是说所选时间段间的数据存在变点。 记时间1880年为t=1,1881年为t=2,一直到1980年为t=101,运用最小二乘法估计出变点发生在t=42,即1922年。从图1可以看出,1922年后全球平均温度呈上升趋势,查阅相关资料,猜测可能是工业革命以后,人类大量使用化石燃料,制造了大量二氧化碳等温室气体所造成的温室效应引起了全球平均气温的波动。 Yi=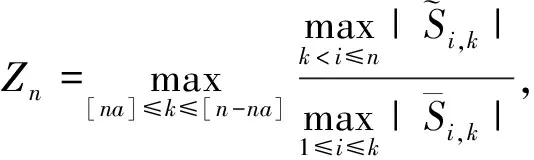
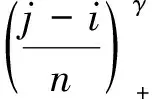
2 统计量的极限分布
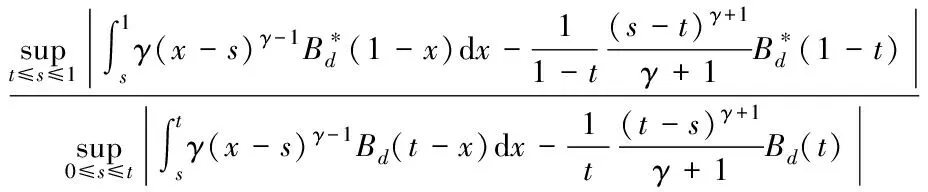
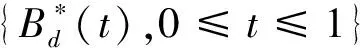

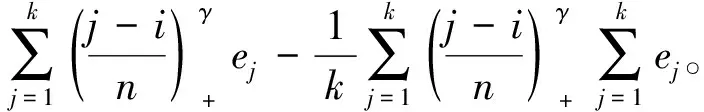
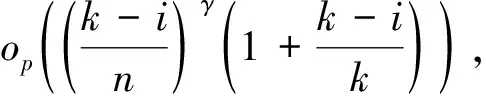
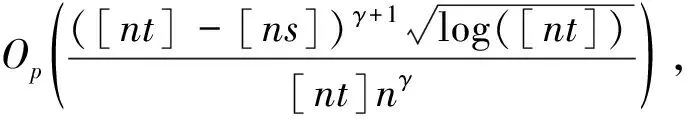
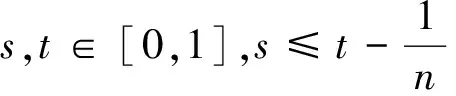
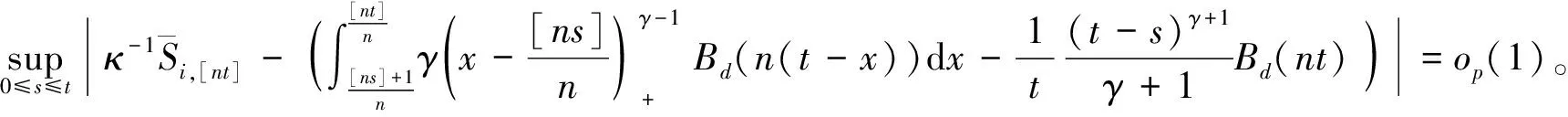
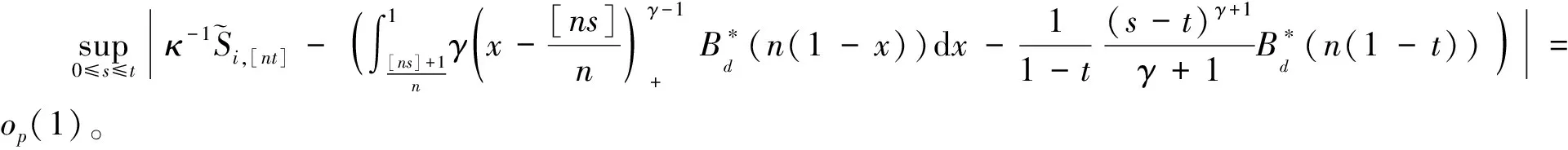
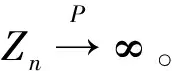
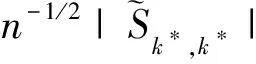
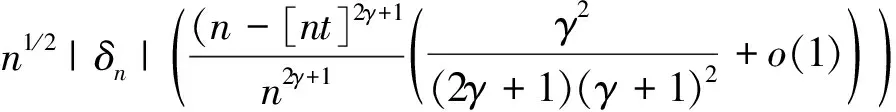
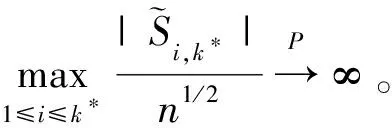
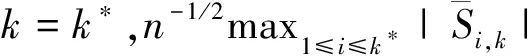
3 数值模拟及实例分析
3.1 数值模拟





3.2 实例分析
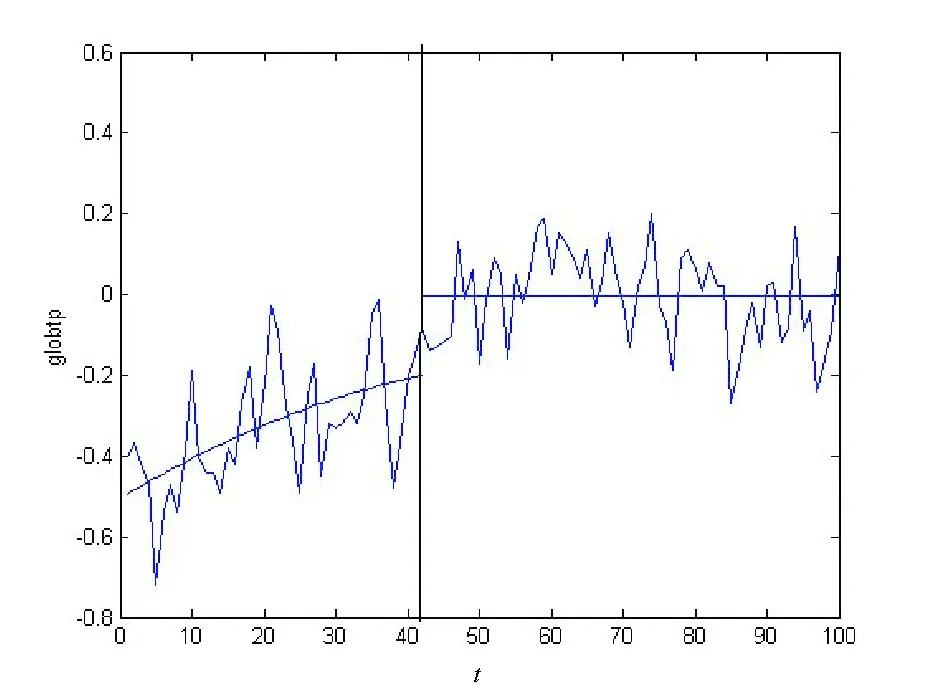
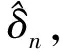
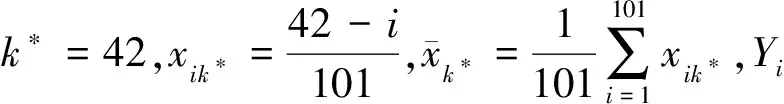 猜你喜欢
统计与信息论坛(2022年7期)2022-07-12哈尔滨商业大学学报(自然科学版)(2021年6期)2021-12-20数学物理学报(2021年4期)2021-08-30温州大学学报(自然科学版)(2021年1期)2021-06-08湖北第二师范学院学报(2020年8期)2020-10-13筑路机械与施工机械化(2020年7期)2020-08-20河南科学(2020年4期)2020-06-03安徽师范大学学报(自然科学版)(2020年1期)2020-03-28中国商论(2018年22期)2018-09-10价值工程(2017年19期)2017-07-12
猜你喜欢
统计与信息论坛(2022年7期)2022-07-12哈尔滨商业大学学报(自然科学版)(2021年6期)2021-12-20数学物理学报(2021年4期)2021-08-30温州大学学报(自然科学版)(2021年1期)2021-06-08湖北第二师范学院学报(2020年8期)2020-10-13筑路机械与施工机械化(2020年7期)2020-08-20河南科学(2020年4期)2020-06-03安徽师范大学学报(自然科学版)(2020年1期)2020-03-28中国商论(2018年22期)2018-09-10价值工程(2017年19期)2017-07-12
