
基于改进人工蜂群优化K-means的入侵检测模型
2019-06-06 09:39于立婷谭小波
沈阳理工大学学报 2019年6期
于立婷,谭小波,解 羽
(沈阳理工大学 信息科学与工程学院,沈阳 110159)
无线传感器网络(Wireless Sensor Network,WSN)是一种分布式传感网络,通过大量静止或移动的传感器节点以自组织和多跳的方式形成,并以传感器节点之间相互协作的方式来采集、处理和传输网络覆盖区域内所被感知对象的信息,最后将这些信息发送给网络的所有者[1]。WSN由于其能耗低、成本低等优点,广泛应用于工业监测[2]、智能交通[3]和医疗卫生[4]等领域。但随着WSN的大规模应用,也暴露了一些缺陷:(1)由于WSN需要根据不同的应用环境来提供服务,所以网络一旦被部署就不能重复利用,从而增加了WSN的部署成本;(2)现有的分布式控制、拓扑维护和路由算法等将带来大量的计算和信息交互,这将加快节点能量消耗的速度,极大缩短传感器节点以及整个网络的生命周期;(3)WSN采用多跳的传输方式,当网络中某些节点任务过载或连接断开时,无法动态改变路由机制,导致数据传送失败,使得整个网络状态不稳定,甚至瘫痪。
针对上述缺陷,许多学者将软件定义网络(Software Defined Network,SDN)[5]架构引入WSN中,形成一种新型的网络架构——软件定义WSN(Software Defined Wireless Sensor Network,SD-WSN)[6-7]。相比于传统的WSN,SD-WSN可以根据实际需求,对传感器网络中节点的感知通信半径以及节点运行状态进行动态调整,并且SD-WSN还可以通过编程的方式重新配置网络设备的参数来应对突发的故障,实现实时监控和维护网络设备性能,减少了人工维护的成本和难度,大大提高网络管理的效率。
然而,网络安全是SD-WSN实用化的前提条件,而SD-WSN在集中控制下,控制器的入侵攻击是SD-WSN面临的最大威胁[8-9]。目前,针对SD-WSN安全方面的研究较少,考虑到网络架构的继承性,部分SDN中的入侵检测方案具有一定借鉴性。
姬生生[10]提出了一种基于SDN和Bloom Filter的入侵检测方案,通过量化网络流量关键值和网络入侵行为的参数特征,采用分层检测的方式,围绕关键节点选择监测节点;该方案提高了主控节点检测的准确性,并减小整个网络的能量消耗,但在检测率上有待提高。Maggi等[11]提出了一种基于SOM的DDoS攻击检测方法,该方法在SDN网络环境下,通过构建流量的六元组特征矩阵的方法,并采用SOM分类算法来检测,但需要花费较长的训练时间。石冬冬[12]提出的一种基于数据挖掘K-means算法的异常检测模型,具有较低的误检率,但需要对大量数据进行预处理训练和分类,存在较长的训练过程。Nasrin等[13]提出了一种基于系统调用序列和参数分析的入侵检测系统,在四种针对系统调用的字符串类型的统计模型基础上,引入“聚类”概念,使用聚类参数推断出同一系统调用的不同使用方式,建立更准确的参数模型,能够正确识别异常情况,但运行耗费较高。
综上所述,基于聚类的入侵检测算法过度依赖聚类中心的选取,采用人为经验或随机取样的方法选取聚类中心存在一定风险,在一定程度上降低了K-means算法的聚类效果。由此,本文提出了一种基于改进人工蜂群优化的K-means入侵检测模型,该模型采用改进的人工蜂群算法对K-means算法中的初始聚类中心的选择进行优化,并采用基于划分的K-means算法对网络中的数据进行聚类分析。实验结果表明,基于人工蜂群优化的K-means入侵检测模型可以在较小的迭代次数下选择出优化的聚类中心,并在聚类效果方面表现出较高的检测率和较低的误报率,达到了较好的检测效果。
1 改进人工蜂群优化K-means算法
传统K-means算法并不能达到较好的聚类效果,本文将采用优化适应度函数的方法改进传统的人工蜂群算法,并且采用改进后的算法对K-means算法的初始聚类中心的选择进行优化,进而提出改进的人工蜂群优化K-means算法。
1.1 K-means算法
K-means聚类算法的基本思想是在数据集中随机选取k个样本,将这些样本定义为初始聚类中心,然后计算其余样本到聚类中心的距离,并且将这些样本归类到距离其最近的聚类中心所属的类簇中。当样本中的所有数据都分配到所属的类中,再通过迭代计算类簇中数据的平均值得到新的初始聚类中心。当迭代后的聚类中心趋于相近时,即平方误差准则函数趋于收敛,则算法结束,否则继续下一次初始聚类中心的选择。平方误差准则函数如下。
(1)
式中:x(i)表示第i个类簇;μc(i)表示第i个类簇的均值。各类簇内的样本越相似,该类内样本的平方误差越小。样本之间的距离使用欧几里得来计算。K-means算法流程图如图1所示。

图1 K-means聚类算法流程图
1.2 改进的人工蜂群算法
1.2.1 人工蜂群算法
蜂群算法最开始由Seeley在1995年提出,之后被学者Karaboga应用在函数的极值问题的求解中,并以此提出了人工蜂群算法[14](Arificial Bee Colony,ABC)。该算法受蜜蜂采蜜的启发,根据蜜蜂在采蜜过程中的角色转换所设计,模拟蜜蜂不断地寻找优秀蜜源的过程,并最终找到全局最优蜜源。人工蜂群算法的主要思想如下。
设有N个蜜源{x1,x2…xN},每个蜜源都代表一组问题的解,可以用d维向量来表示每个问题的解。假设蜜蜂总共进行循环M次,每个蜜源可以被蜜蜂重复开采L次。
初始化阶段:随机产生N组d维向量作为N组解,然后计算每组解的适应度值,将解按照适应度值的大小进行排列,将适应度值大的一半作为引领蜂,剩下的一半作为跟随蜂。引领蜂在其蜜源周围进行领域搜索,根据式(2)产生一个新的蜜源。比较两个食物源的适应度值,并保留适应度值较好的蜜源。
Xij=xij+rij(xij-xkj)
(2)
式中:Xij代表xij附近的一个新的位置;k、j都属于随机数,k=1,2…N,并且k≠i;rij∈[-1,1],使得新位置约束在xij附近;xij为原蜜源。
跟随阶段:跟随蜂根据引领蜂所选择蜜源的适应度值,利用轮盘赌方法,根据式(3)得到的概率寻找合适的引领蜂。选择后,跟随蜂根据式(2)在蜜源的领域产生一个新的蜜源,并且比较前后两个蜜源的适应度值,保留适应度函数较好的蜜源。
(3)
式中:fitnessi表示第i个蜜源的适应度值;Pi表示跟随蜂选择下一个引领蜂的概率。当引领蜂经过L次循环蜜源没有变化后,则引领蜂离开该蜜源,变为侦察蜂,继续去寻找新的蜜源。
1.2.2 改进适应度值的人工蜂群算法
传统人工蜂群算法在初始搜索阶段不一定可以保证优秀蜜源的全局搜索,且在随后的搜索中也可能陷入局部最优的情况,影响算法的整体性能。而适应度函数将会对种群的寻优方向、进化行为、迭代次数和寻优结果有着重要的影响,因此本文通过改进适应度函数的方法,使其在初始阶段搜索范围扩大,避免陷入局部最优。改进过程如下。
定义1 设X为数据集,X={x1,x2,…,xn},假设其中的k个样本数据被聚类划分成类Si,Si={x1,x2…xk},定义类内距离dbet(Si)为类Si中任意两个数据x、y的平方和。
dbet(Si)=∑x,y∈Si‖x-y‖2
(4)
定义2 设X为数据集,X={x1,x2,…,xn},假设其中的k个样本数据被聚类划分为类Si,Si={x1,x2…xk},定义类间距离dwit(Si,Sj)为类Si到其他类Sj的距离,则
(5)
式中:k、p分别为类Si和类Sj中的数据对象个数;x、y分别为类Si和类Sj中的数据对象。
本文将类间距离的倒数和类内距离进行加和得到蜜源的适应度函数,一组数据的聚类结果与类间距离、类内距离都有密切的影响,类间距离越小,说明数据之间的聚类效果越好。因此,本文最后采用的适应度函数为
(6)
1.3 改进的人工蜂群优化K-means算法
根据以上对适应度值的改进,提出了改进的人工蜂群优化K-means算法。该算法的基本思想是:通过改进的人工蜂群算法进行一次迭代,将所得到的一组解作为K-means算法的初始聚类中心并进行一次K-means聚类,用聚类后得到的新的聚类中心去更新蜂群,作为下一次的初始蜜源;如此不断迭代执行人工蜂群算法和K-means算法,直到达到事先设定的最大迭代次数。算法的具体步骤如下。
(1)设置引领蜂、跟随蜂和侦察蜂的数量,最大迭代次数Max以及控制参数Limit;当前迭代次数Cycle,初始值为1;聚类类别数K,随机选择N个蜜蜂,产生初始蜂群{Z1,Z2,…,ZN}。
(2)根据式(6)计算蜂群中每只蜜蜂所代表的初始聚类中心的适应度值,并排列优先级,选取适应度值高的蜜蜂作为引领蜂,其余作为跟随蜂。
(3)利用公式(2)进行领域搜索,得到新位置,并计算该位置的适应度值。若适应度值高于原位置,则新位置将代替原位置,否则,保留原位置。当所有引领蜂完成搜索后,利用式(3)计算概率Pi。
(4)跟随蜂根据概率Pi,采用轮盘赌的方法选择引领蜂。Pi越大,引领蜂选择蜜源的适应度值越大,该蜜源被跟随蜂选择的机会也就越大。当跟随蜂完成选择,转变为引领蜂后,利用式(2)继续进行领域搜索,依据贪婪算法选择适应值更高的位置。
(5)在所有跟随蜂完成搜索后,将得到的位置作为K-means算法的初始聚类中心,对数据集中的数据进行一次聚类,得到新的聚类中心作为人工蜂群算法的初始蜜源去更新蜂群。
(6)如果引领蜂在经过次迭代后,其位置没有任何改变,则引领蜂将转变为侦察蜂,并采用新位置代替原位置。
(7)如果当前迭代次数大于先前所设定的最大次数Max,则迭代结束,算法结束;否则转到第2步,Cycle=Cycle+1。
2 仿真实验与结果分析
为了比较该算法的性能,将在Matlab环境下对K-means算法、传统人工蜂群算法优化K-means算法以及改进人工蜂群优化K-means算法进行仿真。
2.1 实验数据
实验数据为目前应用广泛的KDD CUP99数据集,该数据集来自于美国空军局域网连续9个星期的网络数据,其组成是带有标识的训练数据和未标记的测试数据[15-16]。在训练数据集中包含了正常数据类型normal和22种攻击类型的数据组成,如表1所示。

表1 KDD CUP99入侵检测实验数据的标识类型
KDD CUP99训练数据集包含了1个类标识和41个固定的特征属性,41个固定的特征属性包含34个连续属性和7个离散属性。本实验采用KDD CUP99数据集中的攻击类型的10%抽样kddcup.data_10_percent,将该数据集按照4∶1的比例分为训练数据集和测试数据集[17]。根据SD-WSN实时获取信息的特点,本文将描述节点流量变化及更新维护网络数据统计信息所需的流量特征加入到数据集中,如表2所示。

表2 网络特征属性
表2中流量相关的的属性值用于DDOS攻击检测;路径相关的属性值用于路由攻击检测。将表2中的特征属性加入到简化的KDD CUP99数据集中,并通过仿真模拟得到包含这些属性的数据,如表3所示。
2.2 数据预处理
数据预处理是在算法建模之前,对数据的异常和缺失等情况进行处理。并以此来提高挖掘数据的效果,数据预处理的流程如图2所示。

表3 加入属性后的KDD CUP99数据集

图2 数据预处理过程
2.2.1 数据清洗
数据清洗是将数据中一些与数据本身并无关联的数据去掉,保留关键数据,同时采用全局变量、数据属性的均值填补空缺数据,使数据集平滑,提高实验结果准确度。
2.2.2 格式转换
格式转换的过程将KDD数据集的41个属性中非数值类型的数据转换为数值类型的数据,并需要将数据进行离散化处理,这种方式将需要分析的数据量精简,以此更好的提高聚类的效果。
2.2.3 归一化
归一化的过程是为了消除特征属性值之间的量纲影响,将数据集特征属性值之间存在较大差异的数据进行处理,使数据的绝对值转换成相对值,以此加快梯度下降求最优解的速度。
对数据进行归一化处理,其公式如下所示。
(7)
此方法将原始数据进行了等比缩放,式中Xnorm为利用公式归一化后的数据,X′为原始的入侵检测数据,Xmax、Xmin分别是原始入侵检测数据中每一个属性的最大值和最小值。处理后的数据如表4所示。

表4 预处理后的KDD CUP99数据集
2.3 实验结果与分析
在Matlab环境下,对预处理后的数据集采用改进的人工蜂群优化K-means入侵检测模型进行训练,使用测试集中(测试集是带有标记的数据)的每一条数据计算其与分类模型中所有类簇中心的距离,将每条数据归类到离它最近的类簇当中,根据类簇上的标记对每条数据进行异常检测,区分正常数据和异常数据。
利用改进的人工蜂群算法对数据集进行寻优,并记录迭代200次和400次的适应度函数值。图3和图4分别是对数据集进行200次和400次迭代后的适应度函数值曲线。
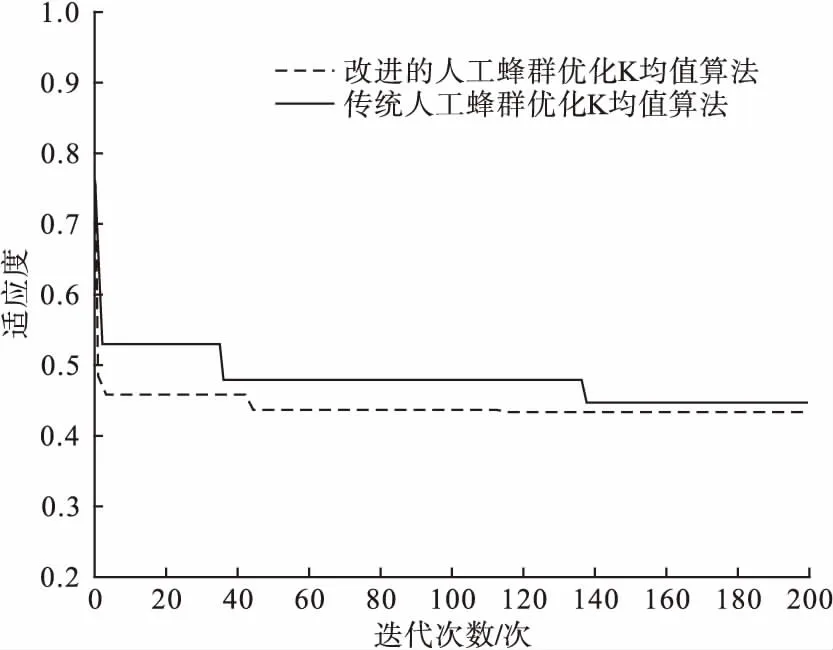
图3 200次迭代适应度函数值
由图3可知,改进的人工蜂群优化K-means算法的适应度函数值较传统的人工蜂群优化K-means算法有相对的降低。表明改进后的算法在聚类效果上有了明显的提高。由图4可知,传统人工蜂群优化K-means算法在迭代150次达到最优,而改进的人工蜂群优化K-means算法在迭代的前100次快速收敛,并达到极优值,在迭代100次后无限接近于最优值,较传统的人工蜂群优化K-means算法迭代速度明显加快。

图4 400次迭代适应度函数值
与改进的K-means算法不同,传统K-means算法k值的确定是随机选择的,而k值的选择在很大程度影响聚类结果。因此,本实验根据k值的选取情况,利用检测率和误检率两项指标,如式(8)、式(9)所示,对传统的K-means算法、传统人工蜂群优化的K-means算法以及改进的人工蜂群优化K-means算法进行评价。实验结果如表5所示。

(8)

(9)
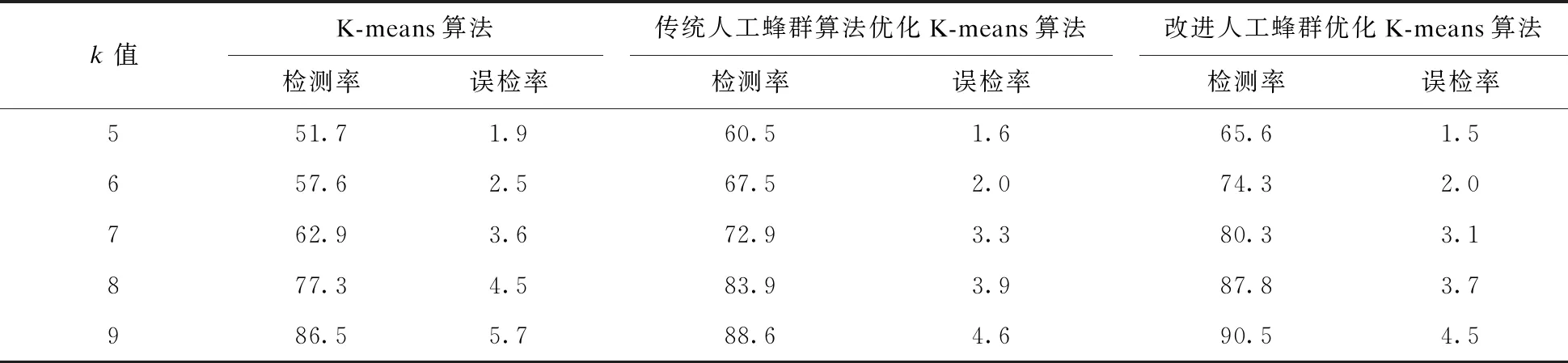
表5 检测率和误检率 %
图5为K-means算法、传统人工蜂群优化的K-means算法以及改进的人工蜂群优化K-means算法的检测响应时间曲线。
由图5可知,相比于K-means算法和传统人工蜂群优化的K-means算法,改进的人工蜂群优化K-means算法随着k值的增加,响应时间明显低于其他算法。响应时间上的差距主要在K-means算法确定k值的方法上,采用优化的人工蜂群算法改进K-means的k值选取方法,避免随机选取和经验选取的不准确性,从而达到快速迭代的效果。

图5 检测响应时间变化曲线
图6、图7展示了K-means算法、传统人工蜂群优化K-means算法以及改进人工蜂群优化K-means算法检测率与误报率的变化曲线。

图6 检测率变化曲线
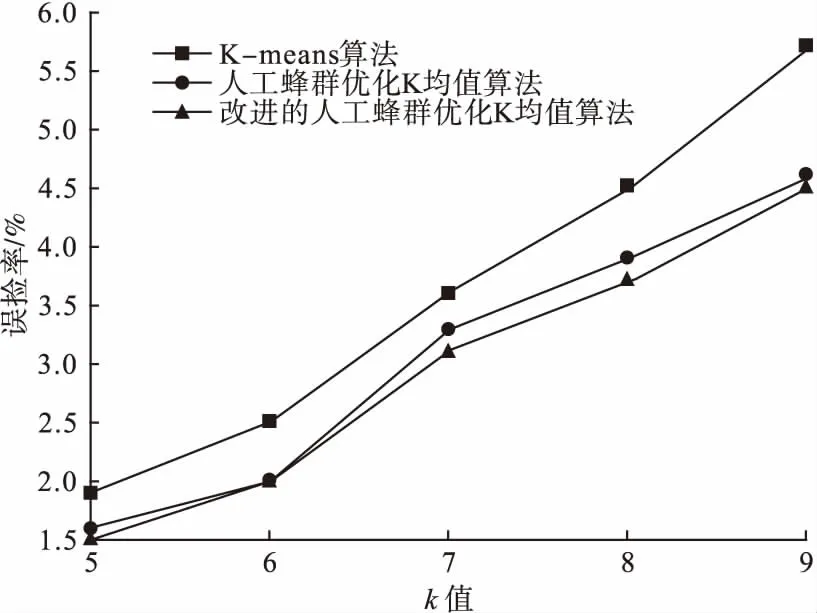
图7 误检率变化曲线
实验结果分析:表5中K-means算法、传统人工蜂群优化K-means算法以及改进人工蜂群优化K-means算法,根据k值的选取不同,分别得到相应的检测率和误报率。比较实验结果以及图6、图7的变化曲线可以看出,改进的人工蜂群优化K-means算法在检测率上较其他两种算法提高5%以上,误检率降低至4.5%。
3 结束语
针对SD-WSN网络环境下,传统K-means入侵检测模型检测率低、检测速度慢等问题,提出了一种基于改进的人工蜂群优化K-means检测模型。该模型首先通过优化适应度函数的方法改进传统人工蜂群算法,加快算法的迭代速度,实现快速寻优。通过改进的人工蜂群算法优化K-means算法,实现K-means算法初始聚类中心的优化选择,消除了传统K-means算法初始聚类中心随机选择的弊端,提高了入侵检测中各种攻击类别的聚类效果,并加快了异常检测速度。仿真结果表明,改进的人工蜂群算法优化K-means入侵检测模型较传统入侵检测模型的检测率提高5%以上,误检率降低至4.5%。
猜你喜欢
计算机仿真(2022年8期)2022-09-28
林业与生态(2022年5期)2022-05-23
小哥白尼(军事科学)(2020年4期)2020-07-25
高中生·天天向上(2018年1期)2018-04-14
郑州大学学报(工学版)(2018年2期)2018-04-13
自动化学报(2017年1期)2017-03-11
学苑创造·B版(2015年12期)2016-06-23
中国塑料(2016年11期)2016-04-16
现代计算机(2016年17期)2016-02-28
舰船电子工程(2010年1期)2010-04-26
