
生态背景下基于人工智能深度学习的竹类害虫识别方法研究
2019-07-17 09:29李禹辰李非非李见辉
世界竹藤通讯 2019年3期
李禹辰 李非非 李见辉 余 飞 徐 杰
(1 电子科技大学 成都 611731;2 成都市森林病虫防治检疫站 成都 610032)
竹子(Bambusaceae),禾本科竹亚科植物,全世界约有70属,1 000种以上,广泛分布于热带、亚热带至暖温带地区。我国是世界上主要的产竹国,在长江流域、珠江流域等南方地区均有大面积栽植。竹子是一种经济价值较高的植物,是在生态、经济、社会、文化等方面效益结合最为紧密的优秀林种之一。
1 研究背景
2018年2月,习近平总书记来四川视察时指出“要因地制宜发展竹产业,让竹林成为四川美丽乡村的一道风景线”。四川省独特的自然立地条件,形成了以丛生竹为主,丛生竹、散生竹、混生竹兼有的竹资源富集区。目前,四川省有竹子18属160余种,分别占全国竹子属、种数的46%和32%;有竹林面积116余万hm2,居全国首位,产业发展潜力巨大。根据《四川省竹产业发展规划(2017—2022年)》要求,四川省将构建“一群三带+其他区”的竹产业发展格局,即“川南竹产业集群”“青衣江竹产业带”“龙门山竹产业带”“渠江竹产业带”及“其他发展区”。力争到2022年,基本形成以川南竹产业集群和青衣江、渠江、龙门山3大竹产业带为支撑的现代竹业发展格局,建成竹业重点县40个,竹林面积稳定在120万hm2,现代竹林基地突破67万hm2,竹产品就地初加工转化率和品牌覆盖率均超过70%,竹旅游康养达到5 300万人次;全省竹业综合产值达到500亿元,竹农人均竹业年收入达到1 500元。
在当前四川省竹产业大发展的有利背景下,逐步将以计算机、互联网、人工智能等高新技术为代表的科技支撑手段应用于竹产业发展的各个方面,实行精细化管理及提升生产效益是竹产业发展势在必行的趋势。作为竹产业发展的基础,在造林完成后,特别是抚育管护阶段对竹类相关害虫进行精准识别并进行有效防治,对高效益发展竹产业具有极其重要的现实意义。
2 智能识别技术发展现状
目前对于竹类害虫的识别大多依赖于人工判断识别,然而这类方法对从业人员专业知识和人力依赖性较强,当前我国森防体系和森林管护体系现实条件下,在生产一线具备相关专业知识的人员稀缺,无法准确判断虫害发生种类并及时采取有效防治措施,往往因时机延误造成损失,难以满足现代化林业高质量发展的需求。进入21世纪,随着计算机视觉技术和人工智能技术在理论研究和行业应用方面的高速发展,为高效、准确、便捷、智能的竹类害虫的识别提供了新的手段,为人工诊断提供了有效补充,对促进竹业健康发展、加速传统竹业向智慧竹业转型有着重要的现实意义和社会影响[1]。
目前,智能识别技术已经广泛应用于多个行业,且取得了长足进步。在昆虫识别领域,基于传统图像处理技术的识别已开展了一些研究并获得了一定成效。Christian等[2]使用了几何形态学来分析熊峰翅的变异性;潘鹏亮等[3]使用数字形态学区分了桃红颈天牛雌雄成虫间的差异;赵汗青等[4]通过利用数学形态特征提取的方法提取到半翅目等昆虫的整体图片的叶状性、似圆度等特征,但由于上述方法只能提取昆虫的部分形态学特征而无法完全提取一张图像的所有特征,因而大多适用于昆虫的粗分类。刘景东[5-6]通过从卷蛾亚科研究人员手中获得的标准图构建了53种根据前翅的翅脉模板图来识别卷蛾不同的种类,但这种方法的缺点是模板匹配的计算量大,识别过程耗时较长,且鲁棒性(鲁棒性是Robustness的音译,指系统在其参数发生变化时性能保持稳定的能力)不强。Weeks等[7-8]利用主成分分析法对寄生蜂的翅脉特征进行分析,完成了对寄生蜂的识别,然而此类方法对虫类图像的质量要求较高,图像中光照、角度、背景等环境因子对识别精确度有较大影响。经过行业应用实际效果比较,以上几种基于传统图像处理的昆虫类识别方法大多存在计算较复杂,识别过程耗时较长,且鲁棒性较差的缺点,在行业应用中普及较为困难。由于竹类害虫存在种类繁多,实际环境中背景较为复杂等具体情况,上述几种传统方法的识别效果不佳,整体实用性不强,无法大规模应用于林业生产实际。
目前,较之传统图像处理技术,人工智能深度学习在图像分类和目标识别领域已经取得了巨大进步,在生物类的识别领域也开展了较广泛的研究与应用。Lim等[9]使用AlexNet(一种神经网络结构模型,以下的LeNet、GoogLeNet均同)对ImageNet(一个计算机视觉识别大型数据集,是目前深度学习图像领域应用得非常多的数据集,关于图像分类、定位、检测等研究工作大多基于此数据集开展)上的27种昆虫进行实验并取得了不错的效果;程尚坤[10]在储粮害虫的检测中使用了深度学习并使得甲虫类的识别率达到95%;Cheng等[11]在生态背景下利用深度学习神经网络对10种害虫进行识别并取得了较高的识别率;Motta等[12]在进行野外成年蚊子分类识别的研究中分别采用了LeNet、AlexNet和GoogLeNet模型来进行训练,其中GoogLeNet取得了最佳的83.9%的识别率,远高于AlexNet的74.7%识别率。
可见,基于深度学习的图像识别方法,通过数据集的训练能够使计算机学习到更多的图像特征,识别鲁棒性更强,对于生态背景的适应性也更好,并且训练好后的模型识别效率也更高,对于硬件的计算性能要求大大降低,实用性得到极大的提高。因此,本研究提出一种基于深度学习的竹类害虫识别方法,以期实现生态背景下几种主要竹类害虫的自动识别,为大规模、高质量的竹产业发展中的害虫智能识别与防治提供一种先进科学方法与技术支撑。
3 研究数据
研究所用数据由2个部分组成:一部分采集自四川省邛崃市某竹林基地,使用移动手持设备在正常光照下采集,包括3种竹类害虫(竹象虫、竹蝗、竹织叶野螟),此为本文算法的主要识别目标;另一部分采集自互联网昆虫图库(www.insectimage.org),包括3种其他昆虫(蚂蚁、蜜蜂、蜻蜓),主要用于增加数据种类,作为训练与识别的干扰种类,提高识别算法的鲁棒性和实用性。
数据对于神经网络的训练至关重要。一般来说,数据量越大,训练出来的模型精度越高,泛化能力越强。因此利用已有的数据,通过翻转等数据处理,可以制造出更多的图片,进而提高网络的精度和泛化能力。本研究通过旋转、高斯滤波、椒盐噪声、变亮+椒盐噪声、变暗+高斯滤波几种数据处理方式,进行虫类图像数据的增强和扩充,如图1所示。

图1 经数据增强扩充后的竹象虫成虫图片
通过数据增强方法扩充并筛选,形成共计5 663张虫类图片的数据集,且均为生态背景下的虫类图片。虫类图像数据集共分7类(表1),分别为竹织叶野螟、竹蝗、竹象虫幼虫、竹象虫成虫、蚂蚁、蜜蜂、蜻蜓,其中由于竹象虫成虫与幼虫形体区别较大,故分类进行识别。
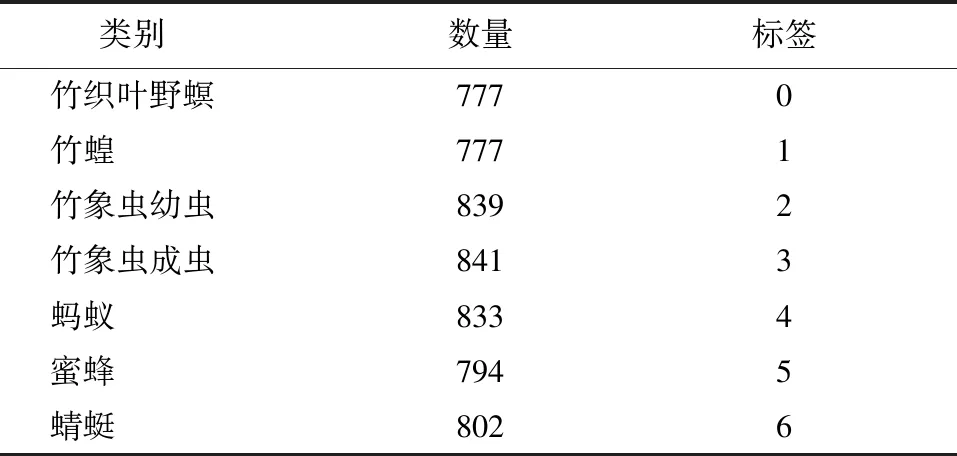
表1 虫类数据集各类图片数量
本研究中采用的图像分辨率大小均为256×256,并对数据集的每一种昆虫图像进行标签,记作n,代表图像所属的类别:0代表竹织叶野螟;1代表竹蝗;2代表竹象虫幼虫;3代表竹象虫成虫;4代表蚂蚁;5代表蜜蜂;6代表蜻蜓,如图2所示。

图2 数据集标记示例
4 研究方法
本研究基于GoogLeNet网络的竹类虫害识别方法。GoogLeNet网络相比于AlexNet等早期网络拥有更宽、更深的网络结构。同时,所需要的参数也大大减少。GoogLeNet特有的Inception模块构成的网中网结构能够使其获得更多的图片特征。Inception模块的设计特点是用稠密结构来替代网络中的局部稀疏结构,这种特点使得Inception可以在具备稀疏性来减少参数的同时利用密集矩阵进行运算,这使得网络利用资源的效率大大提高。本文的识别模型结构图如图3所示,GoogLeNet在分类层之前使用了连续的9层Inception模块来提取特征。在分类部分,采取了平均池化层,使得整个网络结构参数减少了,抑制了过拟合现象的出现,从而降低了训练的难度。
实验所使用的计算机CPU为英特尔酷睿i7-7700,显卡为英伟达GeForce GTX 1080Ti,操作系统为Ubuntu16.04。实验均采用相同的参数,所用参数学习率为0.005,动量参数设置为0.9,权值衰减系数为0.000 5,Gamma矫正参数为0.1,采用小批量训练且以24张图片为一组,共进行100轮训练,每轮训练进行1万次迭代。所有实验均在Caffe(卷积神经网络框架)下进行。Caffe是一个开源的深度学习框架,实验所有的测试结果均可在Caffe上复现。

图3 基于GoogLeNet的竹类害虫识别模型结构
在深度学习中,数据集通常被分为独立的3个部分:训练集、验证集和测试集。其中训练集用来估计模型,验证集用来确定网络结构或者控制模型复杂程度的参数,而测试集则检验最终选择最优模型的识别性能。
为研究训练集与测试集比例对模型识别准确率的影响,采用4种不同训练集与测试集比例进行测试,分别为:1)9∶1(数据集的90%作为训练集,10%作为测试集);2)8∶2(数据集的80%作为训练集,20%作为测试集);3)7∶3(数据集的70%作为训练集,30%作为测试集);4)6∶4(数据集的60%作为训练集,40%作为测试集)。
5 结果与分析
5.1 Loss曲线分析
Loss曲线是用来衡量网络训练情况的一种方法,Loss曲线收敛即代表模型能够被训练。图4为训练过程中的Loss曲线图,其中纵坐标表示Loss值,横坐标为训练轮数。由图4可以得出结论:模型在对竹类害虫图片数据集进行训练过程中,Loss值一直呈下降态势,并能够很快趋近于0,这表明模型训练过程中没有出现过拟合现象。可见,本文模型在对竹类害虫图片数据集训练过程中展现了优越的性能。

图4 Loss曲线图
5.2 F1值分析
F1值,又称平衡F分数,是用来衡量分类模型精确度的一种重要指标,同时兼顾了分类模型的查全率(Recall)和查准率(Precision)。查全率是针对原来样本而言的,它表示样本中的真样例有多少被预测正确。查准率是针对测结果而言的,它表示预测为真的样例中有多少是真正的真样例。
对竹类害虫的识别结果分为4种情况:一是正确肯定(TP),预测为真,实际为真;二是正确否定(TN),预测为假,实际为假;三是错误肯定(FP),预测为真,实际为假;四是错误否定(FN):预测为假,实际为真。
因此,查全率定义公式如(1)所示,查准率定义公式如(2)所示。
(1)
(2)
本文中查全率表示某一类竹子害虫被识别出来的比例,比率越大则表示漏掉的样例越少;查准率表示在所有识别为某种害虫类别的样例中,实际属于该类别的样例的比例,比率越大表示模型识别得越准确。本文模型在4种不同比例的训练集与测试集下,各类竹类害虫识别结果的查全率和查准率如表2所示。
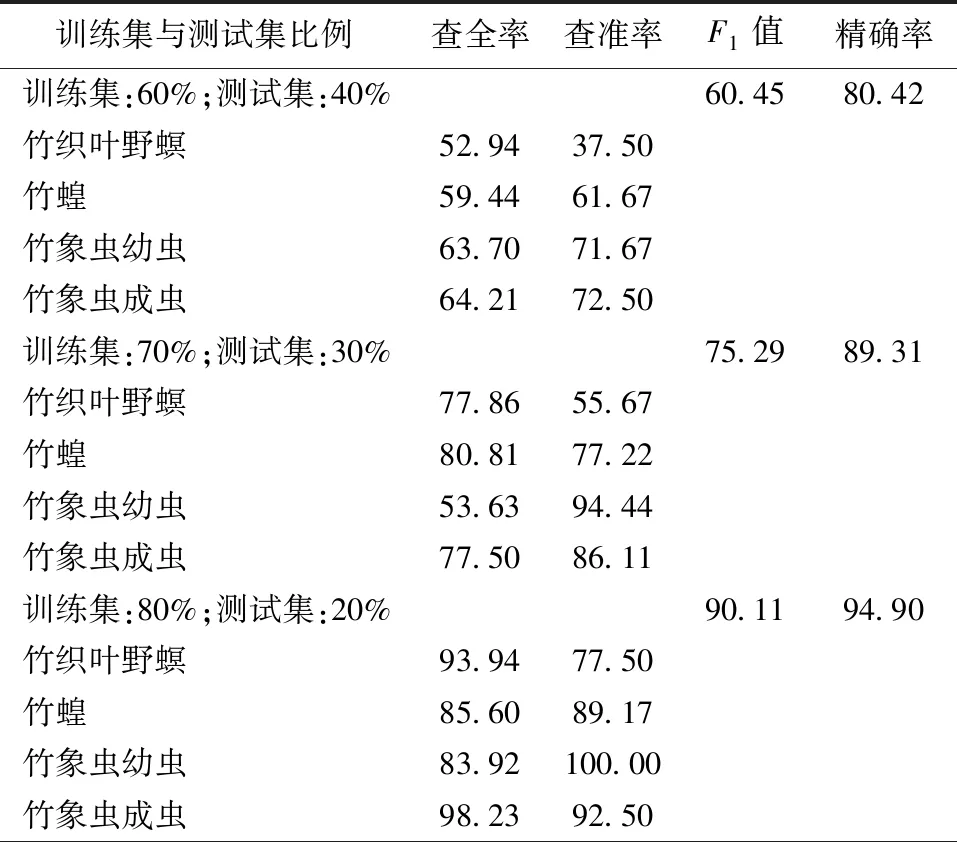
表2 不同训练集与测试集比例的查全率、查准率、
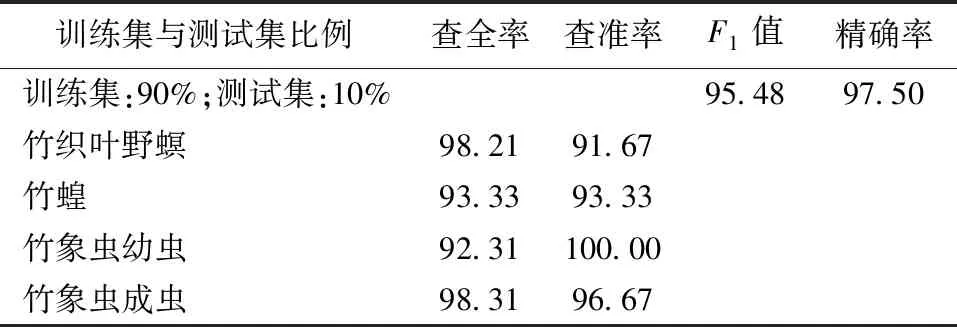
表2(续)
F1值作为对查全率和查准率的综合评估指标,可以看作是模型查全率和查准率的一种加权平均,是表示这两者对模型的影响的最优平衡点。F1值定义公式如(3)所示。
(3)
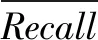
由表2可得,竹类害虫识别模型在4种不同训练集与测试集比例情况下的平均查全率分别为60.07%、72.45%、90.42%、95.54%,平均查准率分别为60.84%、78.36%、89.79%、95.42%,因此根据公式(3)可得本文模型的F1值分别为60.45%、75.29%、90.11、95.48%。
由此可知,当训练集与测试集比例为9∶1时识别模型的平均查全率和平均查准率都较高,且F1值达到了95.48%。较高的平均查全率和查准率代表本文识别模型能从多种虫类中较准确识别竹类害虫,较高的F1值表示识别模型具有较好的综合性能和较高的实用性。
5.3 精确度分析
模型的精确度(Accuracy)是分类正确的样本数占样本总数的比例,反映了模型对整个样本数据的判定能力(即能将真的判定为真的,假的判定为假的)。计算公式如(4)所示。
(4)
由公式(4)可得模型的精确度(如表2所示),通过对比在4种不同训练集和测试集比例下模型的精确度可以得出结论:模型的精确度随训练集比重的增大而增大。在本实验中,当训练集和测试集的比例为9∶1时精确度最高,达到了97.5%。因此,本文的识别模型具备较高的精确度,能较准确地识别出各类竹类害虫。图5为竹类害虫识别成功的示例。可见,本文的识别模型能够满足生态背景下竹类害虫识别的要求,具有较强的实用性。

图5 竹类害虫识别示例
6 结论与展望
本研究基于人工智能深度学习的竹类害虫识别方法,相比于传统的图像处理方法,其深度学习模型能提取更多的图像特征,能对生态背景下的竹类害虫识别有更好的精确度和适应性。本文首先构建了具有5 663张图片的虫类数据集(包含3种竹类害虫和3种其他昆虫类),并利用GoogLeNet特有的Inception模块构成的网中网结构能够使其获得更多的图片特征,进行了4组不同训练集与测试集比例的模型识别实验。实验结果显示,模型在对竹类害虫图片数据集进行训练过程中,Loss值一直呈下降态势,并能够很快趋近于0,这表明模型训练过程中没有出现过拟合现象,展现了优越的性能。此外,模型的精确度随训练集比重的增大而增大,当训练集和测试集的比例为9∶1时识别表现最好,F1值达到了95.48%,精确度为97.5%,表明模型能较准确的识别出实验中的各类竹类害虫,体现了识别模型具有较好的综合性能和较高的实用性。
因本文着重于方法的探索,在数据集中只包含了3种竹类害虫,在后续的研究中将加入数量更多、更丰富的竹类害虫图像数据,研究建立准确率更高的识别模型,实现更多种类竹类害虫的自动识别并扩展至其他树种虫害。此外,目前所用于训练的单张图片仅包含一种目标害虫,后续将考虑加入多目标检测方法,实现单张图片中多种害虫的准确识别,以达到更好的实用价值。
猜你喜欢
现代电子技术(2018年20期)2018-10-24
现代电子技术(2018年16期)2018-08-21
现代情报(2018年11期)2018-01-07
中国绿色画报(2017年11期)2018-01-04
现代电子技术(2017年23期)2017-12-20
计算机应用(2016年10期)2017-05-12
文艺生活·中旬刊(2016年9期)2016-11-07
中国管理信息化(2009年10期)2009-06-19
