
基于遗传模拟退火算法的立体仓库储位优化
2020-03-06 12:56张文怡
计算机应用 2020年1期
朱 杰,张文怡,薛 菲
(北京物资学院 信息学院, 北京 100149)
0 引言
在物流仓储中应用自动化立体仓库可以实现货品的多层存储以此提升空间利用率和节省成本支出[1]。为了适应日益增快的物流速度,需要进行储位优化即重新给自动化立体仓库中的货品分配储位以此达到提高作业效率和降低物流成本的目的。
自动化立体仓库储位优化的数学模型主要以提高出入库效率和保证货架稳定性为目标建立,使用改进遗传算法[2]、病毒协同进化遗传算法[3]、基于Pareto的遗传算法[4]、粒子群算法[5]和精英多策略[6]求解。考虑货品分类存放的模型使用遗传算法[7]、病毒协同进化遗传算法[8]和多种群遗传算法[9]进行求解。Kim等[10]提出以最小化拣选周期为目标的模型,使用改进模拟退火算法求解;Park等[11]提出最小化移动距离为目标的模型,并且使用基于改进交叉操作的遗传算法(Genetic Algorithm, GA)求解;Pan等[12]提出最小化预期数量和实际库存差值以及考虑负载均衡的模型,使用遗传算法求解;Chen等[13]提出最小化行进距离的模型,并使用混合序列堆叠算法求解;Muppani等[14]建立以最小化拣选距离为目标的数学模型,使用分支定界算法求解;Muppani等[15]使用模拟退火(Simulated Annealing, SA)算法求解最小化拣选成本和存储成本的储位优化模型。
以上研究中的数学模型基本上以运行效率和货架稳定性为目标,并且大多采用遗传算法和模拟退火算法求解。其中:遗传算法虽然全局搜索能力强但过早收敛且易陷入局部最优解;模拟退火算法局部搜索能力强,但收敛速度慢。为改善以上问题,本文将全面地考虑储位分配问题,建立同时考虑作业时间、货架稳定性和货品分组存储的数学模型。使用引入自适应交叉变异操作和逆转操作的遗传模拟退火算法(Simulated Annealing Genetic Algorithm, SAGA)求解,以此兼顾全局和局部搜索能力并且提高算法收敛速度。
1 自动化立体仓库储位优化模型建立
自动化立体仓库中的操作基本由堆垛机和传送带完成,其布局如图1所示。由于不同货品的质量、周转率和所属组别不相同,因此建模时需要考虑货架稳定性以及周转率和货品组别对运行效率的影响,合理优化储位分配,实现最小化出入库时间、相关货品距离和货架重心。所有货品都具有唯一的货品编号且不会随着储位变动而变化。
图1 自动化立体仓库布局Fig. 1 Automated warehouse layout
由于储位优化问题的复杂性过高,所以出于方便求解和满足自动化立体仓库不能交叉存储货品的运作特点,提出以下假设:
1)货品储位都是长、宽、高相同的正方体,并且所有货品都适应储位尺寸;
2)忽略堆垛机存取货物和启制动的时间;
3)一个储位只能存储一种货品。
在储位优化模型建立的过程中,变量xij,yij,zij分别表示第i组第j个货品的x轴、y轴和z轴坐标;qi为第i组货品组内平均坐标;Q为货品中心坐标;G为货品中心坐标距离出入口的距离;d为所有货品到对应组内平均坐标的距离总和;D为所有组内平均坐标到货品中心坐标的距离总和。其他涉及到的参数如表1所示。
自动化立体仓库储位分配优化问题建立的数学模型:
1)以最小化出入库时间为目标的函数F1。
储位分配中的首要目标是提高出入库效率即降低货品出入库行走时间,即pij越高的货品出入库时间越短。由于货架之间存在距离,所以x轴方向行走的单位距离是储位长度和货架之间距离之和l+h。

(1)表1 储位优化模型参数定义 Tab. 1 Storage location optimization model parameter definition
2)以最小化同组货品距离为目标的函数F2。
降低相关性高的货品存放储位的距离,可以减少出入库操作产生的成本。使用关联规则挖掘算法[16-17]求解销售订单中存在的货品相关性即经常出现在相同订单中的货品,定义相关性高的货品为同一组别货品。
首先定义货品的组内平均坐标qi:
(2)
然后定义所有货品到对应组内平均坐标距离的总和d:
d=
(3)
最后定义货品中心坐标即所有组内平均坐标的均值Q:
(4)
根据式(2)和(4)计算所有组内平均坐标到货品中心坐标距离的总和D:
D=
(5)
根据式(6)计算货品中心坐标和出入口的距离G:
(6)
为了减小同组货品储位之间距离且保证其均匀分散在出入库口,结合式(3)、(5)~(6)得出目标函数F2:
(7)
3)以最小化货架重心为目标的函数F3。
为了确保仓库作业流程的安全防止货架倾覆,需要降低货架重心即最小化货品合成重心。
(8)
最后,由式(1)、(7)~(8)可以得出储位优化的数学模型:
s.t. |xij-xts|+|yij-yts|+|zij-zts| >0,i,t=1,2,…,n;j=1,2,…,ki;s=1,2,…,kt;k≠t;j≠s
(9)
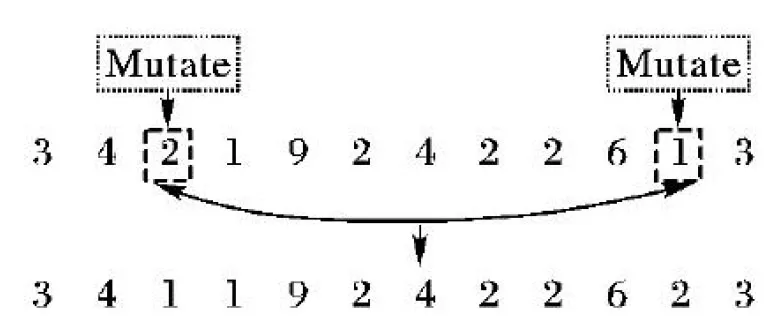
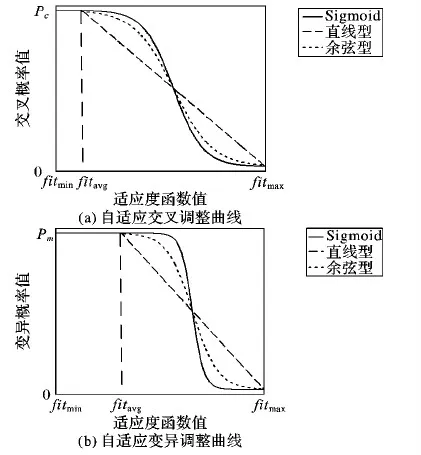
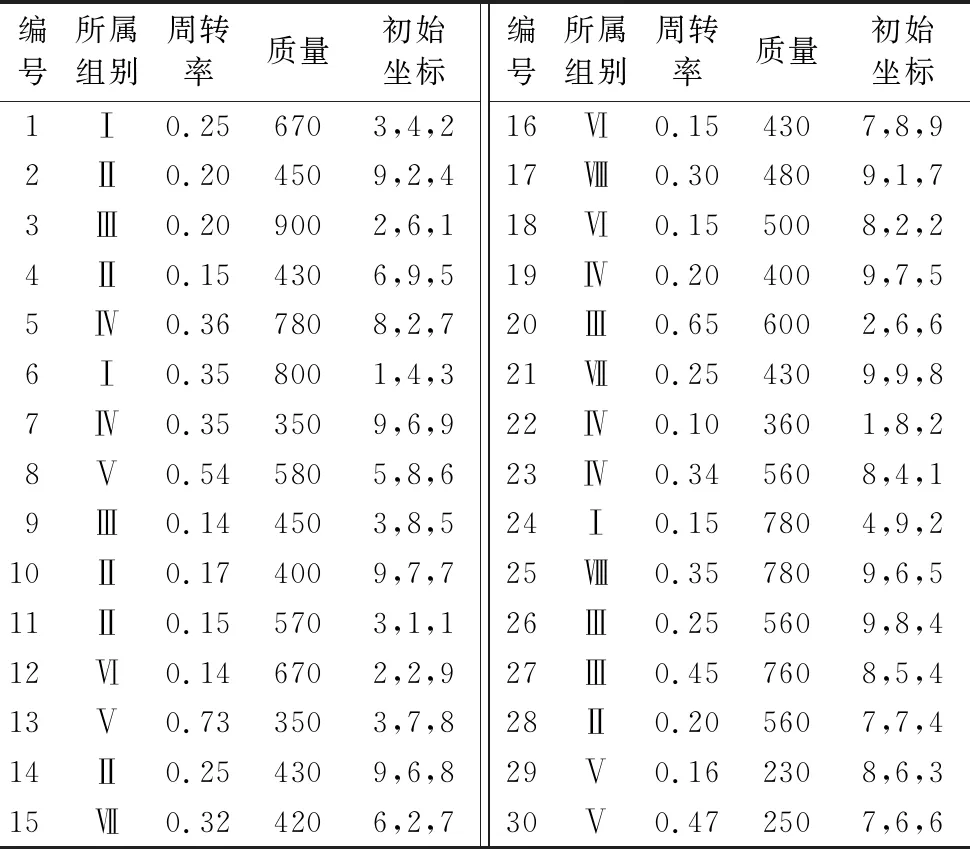
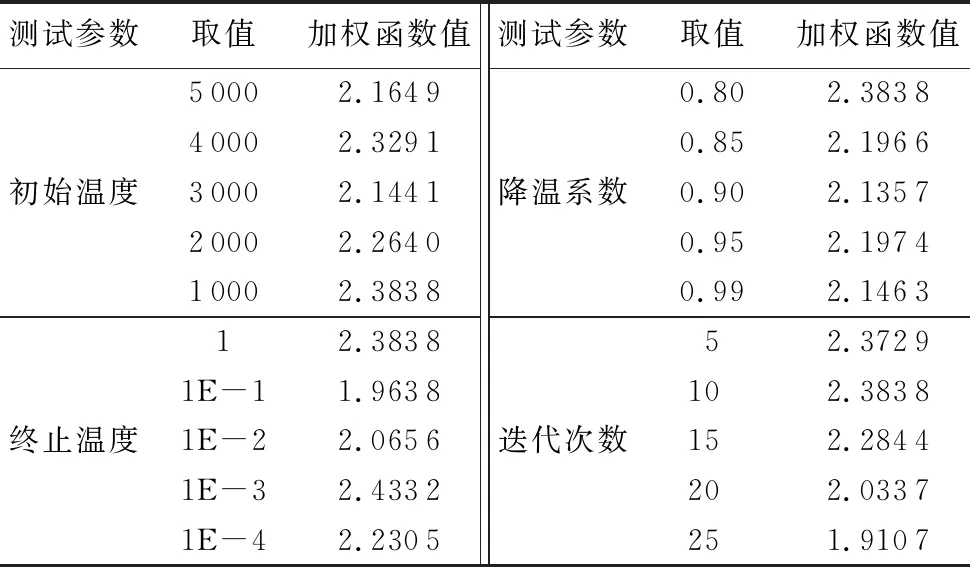
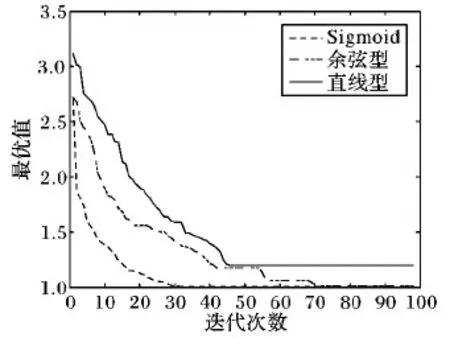
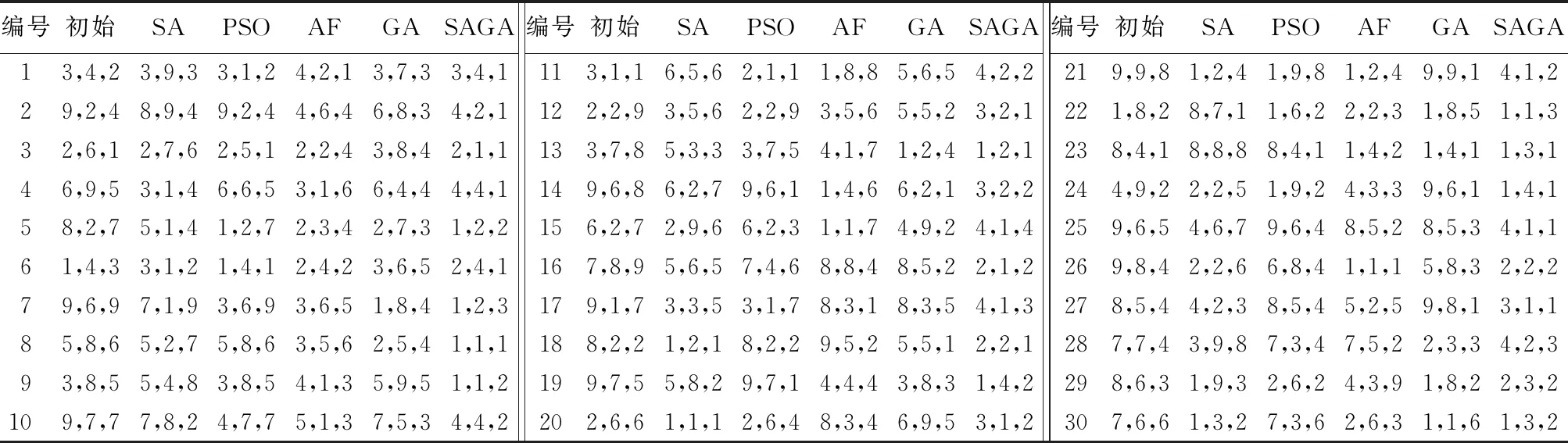
0 (10) 0 (11) 0 (12) 约束条件式(9)表示第i组第j个货品与第t组第s个货品分配的储位不相同;约束条件式(10)~(12)表示储位坐标的取值范围,并且xij,yij,zij均为整数。 由于模型中3个目标函数的量纲不一致,所以需要进行归一化处理。其中F2和F3都是无量纲,F1的单位是s,所以只需对F1进行归一化处理: (13) 式(13)中的η为归一化参数,其设置意义是为了防止在计算过程中出现数值溢出的情况,其取值为η=0.001。 为了防止多目标模型在求解时出现相互影响的情况,需要给目标函数添加权重系数ωs以此转化为单目标模型,式(14)为变型后的目标函数。其中使用层次分析法(Analytic Hierarchy Process,AHP)求解的权重系数为ω1=0.647 9、ω2=0.229 9和ω3=0.122 2。 (14) 1)染色体编码。 根据储位优化模型的特点,选择实数编码方式。染色体由货品所在储位编码和所属组别共同构建。每条染色体包含4×J个基因,其中J代表货品个数,具体形式如图2所示。 图2 染色体编码 Fig. 2 Chromosome coding 2)初始化种群。 初始化种群即随机生成NIND行4×J列的二维矩阵,其中NIND代表种群规模。种群中每条染色体对应一个解决方案。种群初始化时会出现同一储位分配给不同货品的现象,所以需要逐一遍历以此保证其唯一性。如果存在相同储位则随机生成储位坐标来替换此坐标,直至所有货品的储位均不相同为止。 3)构建适应度函数。 适应度函数的大小是决定在下一次迭代中该个体是否会被选择的重要条件,其直接影响算法的收敛性。式(15)所示为算法适应度函数: (15) 1)选择操作。 采用精英保留策略和轮盘赌相结合的方法选择个体,即适应度最高的父代个体直接保留至下一代,其余的个体使用轮盘赌的方式选择。以此防止父代中最优个体丢失的同时保证适应度高的个体拥有更大几率保留至下一代中,从而提高算法收敛性。 2)自适应交叉变异操作。 采用的交叉规则是两点交叉,变异规则是随机生成2个不能整除4的数字作为变异操作的交换位置,其具体操作如图3所示。交叉概率(pc)和变异概率(pm)取值会直接影响遗传算法的收敛效果:pc取值过大会破坏个体自身结构,反之算法的整体搜索速度缓慢;pm取值过大会产生大量随机解,反之会导致算法难以产生新解,所以采取自适应pc和pm来灵活协调收敛速度以此防止算法陷入局部最优解。自适应概率调整公式分为线性、余弦型和曲线型,线性调整公式如式(16)~(17)所示,fit′是交叉操作中适应度较大的个体,fit是变异染色体的适应度,并且K2>K1,K4>K3。 (16) (17) 余弦型自适应遗传算子为: (18) (19) 基于Sigmoid曲线的自适应遗传算子如式(20)~(21)所示,其中α=9.903 438。 (20) (21) 图3 变异操作 Fig. 3 Mutation operation 图4为三种自适应调整方式对比,从中可知基于Sigmoid曲线的自适应算子不仅可以在适应度小于均值时提高概率来产生新个体,同时相比于线性调整,其在多数个体适应度接近时提高概率来防止算法陷入局部收敛且提高幅度大于余弦型。在个体适应度接近最大适应度时拥有更低的概率,以此保证优秀个体不被破坏,所以选用曲线型自适应算子。 3)逆转操作。 逆转操作可以解决遗传算法局部搜索能力差和传统交叉算子难以使子代继承父代优良基因的问题,逆转操作具有单向性即只接受适应度提高的个体。具体操作为随机生成一个布尔变量R,若R=1则选择以所属组号作为中轴线的逆转操作,如图5(a)所示;R=0选择以所属组号作为边界线的逆转操作,如图5(b)所示。 图4 自适应调整曲线对比Fig. 4 Adaptive adjustment curve comparison 图5 逆转操作Fig. 5 Reversal operation 融合遗传算法和模拟退火算法可以克服遗传算法局部搜索能力差的缺点,达到兼顾算法全局和局部搜索能力的目的。模拟退火部分是对经过遗传操作的个体重新计算适应度并以一定的概率替换旧个体形成新种群。 1)设置初始温度。 算法是通过模拟金属降温过程来达到求解最优解的目的,所以要求设置的初始温度足够高以此保证新个体接受率趋近于1,但是过高的初始温度会影响算法效率。 2)新个体接受概率。 计算经过遗传操作的个体适应度值fit(x′),若fit(x′)≥fit(x)则以新个体替换旧个体;反之则以式(22)的概率来接受劣解: (22) 3)降温函数。 采用的降温函数是Tφ+1=r·Tφ,其中r∈(0,1)。降温系数r的选取是影响算法收敛性和效率的重要因素,系数接近于1则算法迭代缓慢;接近于0则影响算法求解结果。 根据以上操作步骤设计的SAGA流程如图6所示。 图6 改进SAGA的算法流程Fig. 6 Algorithm flowchart of improved SAGA 为了验证模型和算法的有效性而使用Matlab 2014a进行改进算法程序设计,并且选取30个货品进行储位分配优化操作。 其中仓库基本参数信息如表2所示,货品基本属性如表3所示。货品属性中质量是货品净重和托盘质量的总和;周转率是货品出入库次数占总次数的百分比。 表2 仓库基本参数 Tab. 2 Warehouse basic parameters 由于模拟退火算法是基于概率的方法,相关的算法参数对优化结果都存在影响,所以不能单纯依靠增加算法迭代次数来优化求解结果。需要在保持其他参数不变时逐一测试模拟退火部分的算法参数最优取值,表4所示为算法运行20次的平均加权函数值。根据测试结果可知初始温度T0=3 000;终止温度Tend=1E-1;降温系数r=0.9;迭代次数L=25。算法优化参数取值为表5所示。 由于采用归一法进行多目标模型求解,不同的权重系数取值对求解结果也存在影响,所以需要对权重取值进行敏感性测试,结果如图7所示。图7(a)中货品存放位置较低,可以保证货架稳定性,但货品储位距离出入库口较远且同组货品聚集度较低不利于提高运行效率;图7(b)中货品聚集度较高,但位置较高不利于保证货架稳定性且距离出入库口较远;图7(c)为使用层次分析法求解权重的储位分配,货品基本分布在出入库口附近、重心较低并且相同组别货品的聚集度较高。由此可知采用层次分析求解的权重系数更利于优化储位分配结果,但不同权重取值只影响储位分配结果,对于算法优化性能不产生影响。 表3 货品相关属性以及初始储位安排 Tab. 3 Items related attributes and initial storage location assignments 表4 模拟退火参数测试 Tab. 4 Simulated annealing parameter test 表5 算法优化控制参数 Tab. 5 Algorithm optimization control parameters 表6所示为使用不同自适应遗传算子的算法运行20次求解效果对比。从结果可知采用基于Sigmoid曲线的自适应遗传算子求解问题的平均解和最优解平均优于其他方式19.338 4%和22.408 9%。图8为不同自适应遗传算子迭代过程对比,可看出基于Sigmoid曲线的自适应遗传算子在迭代30次左右可以得到最优解,相比于其他自适应算子平均少迭代25次左右并且不易陷入局部最优解。由此可以验证使用基于Sigmoid曲线的自适应遗传算子求解问题的优越性。 表6 不同自适应遗传算子求解效果对比 Tab. 6 Comparison of solution effect of different adaptive genetic operators 图7 不同权重下的储位分配Fig. 7 Storage assignments under different weights 图9所示为使用标准粒子群优化(Particle Swarm Optimization, PSO)算法、遗传算法(Genetic Algorithm, GA)、模拟退火(Simulated Annealing, SA)算法、人工鱼群(Artificial Fish Swarm, AF)算法和SAGA求解问题的迭代对比,其中SA中的所有算法参数以及GA、PSO和AF的种群大小均与SAGA相同;AF的拥挤因子a=0.618,视野范围V=35;GA的交叉概率pc=0.7,变异概率pm=0.2;PSO的学习因子c1=c2=10,惯性系数ξ=0.6。从图9可知,SAGA算法的迭代曲线始终低于其他算法。同时相比其他算法而言,其不易陷入局部最优解中,并且SAGA平均比其他算法早40代左右收敛到最优解上。由此可知在相同的迭代次数时SAGA具有更好的收敛性和优化能力,以此证明算法的改进效果显著。 图8 不同自适应遗传算子迭代过程对比Fig. 8 Comparison of iterative processes of different adaptive genetic operators 表7为算法运行20次求解表4数据的储位优化问题的平均优化程度取值,其中SA与SAGA的计算方式较为相近,所以对应数值的比较更加具有针对性。从表7中可以看出SAGA对F1的优化程度比SA高出37.794 9个百分点;对F2的优化程度比SA高出58.463 0个百分点;对F3的优化程度比SA高出25.927 5个百分点。由此验证SAGA求解问题的有效性和优越性。其中求解的仿真优化储位坐标结果如表8所示。 为了验证算法的有效性,需要测试算法在不同的货品规模下的稳定性。将表3数据依照不同的货品规模进行分组,其具体分组信息如表9所示,结果如图10所示。从图10(a)可知SAGA在不同货品规模下求解的加权函数值一直低于其他算法的求解结果且优化效果稳定;在图10(b)中,SAGA对F1的优化程度在货品规模为5、10和15时与GA的优化效果相近,但是随着货品规模增加优化效果愈加明显;在图10(c)中,随着货品规模的增加,SAGA对F2的优化效果与GA的优化效果趋同,优势不明显;在图10(d)中可知SAGA对F3的优化程度明显优于其他算法且优化效果稳定。由此可以验证SAGA求解不同货品规模问题时优化效果稳定。 单位:% Tab. 7 Comparison of target function value optimization degree unit:% 表8 不同算法的仿真优化储位坐标结果 Tab. 8 Coordinates results of simulation optimization of storage location assignment by different algorithms 表9 数据分组情况 Tab. 9 Data grouping 为了进一步验证算法的有效性,采用文献中的算例进行求解,算例数据具体为表10所示。表11为算法运行20次的各个目标函数最优解和平均解。其中改善率是指SAGA求解的平均解相对于其他算法的平均解的优化程度。从表11中可知SAGA对F1的平均改善率最高为25.621 2个百分点;对F2的改善率最高为62.543 4个百分点;对F3的改善率最高为49.259 6个百分点。使用SAGA求解F1的最优解比其他算法平均优化14.664 0%,F2的最优解平均优化47.333 1%,F3的最优解平均优化35.075 3%。由此可以验证SAGA求解不同算法的优化能力以及稳定性。 表10 算例数据 Tab. 10 Example data 图10 不同货品规模下的函数值对比Fig. 10 Comparison of function values under different item sizes表11 不同算例的目标函数最优解和平均解 Tab. 11 Optimal solutions and average solutions of target functions for different examples 综上分析,SAGA相比其他算法在降低货品出入库时间、提高同组别货品聚集度和降低货架重心方面更具优势。相比其他算法而言,SAGA在求解不同货品规模问题和不同算例时优化性强、稳定性高且收敛性良好,由此验证了SAGA对解决储位优化问题的有效性。 为了达到提高货品出入库效率和保证货架稳定性的目的而建立以最小化货品出入库时间、相关货品之间距离和货架重心为目标的数学模型,并设计改进SAGA进行储位分配优化模型求解。其中对SAGA的改进分为以下两点:1)使用基于Sigmoid曲线的自适应交叉变异概率,以此控制算法的收敛性;2)添加逆转操作来提高算法局部搜索能力。仿真实验结果表明改进SAGA具有更好的收敛性、稳定性和优化能力,可以为自动化立体仓库储位优化问题提供更加优秀的解决方案。未来的工作方向是进一步考虑堆垛机存取货品和启制动时间对运行效率的影响。2 改进遗传模拟退火算法
2.1 算法初始化准备
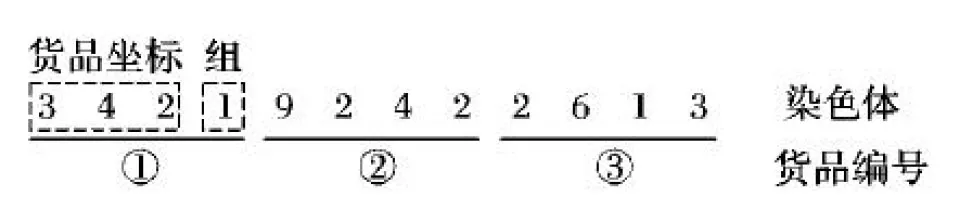
2.2 遗传算子

2.3 模拟退火

3 仿真实验与分析









4 结语
猜你喜欢
科学技术与工程(2022年26期)2022-11-01汽车实用技术(2022年10期)2022-06-09云南大学学报(自然科学版)(2022年1期)2022-02-21中国船检(2021年11期)2021-12-04校园英语·上旬(2020年1期)2020-05-09软件(2017年7期)2018-01-24卷宗(2017年16期)2017-08-30经营者(2017年3期)2017-04-27软件(2016年3期)2016-05-16对外经贸实务(2009年9期)2009-10-13
