
聚类算法在图书馆微信公众号传播效果中的应用研究
2020-12-28 06:53高哲
新媒体研究 2020年17期
高哲

摘 要 公共图书馆微信公众号服务面对的用户群体庞大且复杂,所提供的文化服务内容多,如何获取更优质、用户需求更大的文化服务内容,是当前公共图书馆微信公众号服务所面临的挑战之一。大数据的发展为公共图书馆微信公众号传播效果的研究带来了新的契机。文章以国家图书馆微信公众号为例,将聚类算法应用于图文消息的特征数据,在大数据视角下对公共图书馆微信公众号消息传播效果进行探究,为微信公众号的运营工作提供科学的参考。
关键词 图书馆;微信公众号;大数据;聚类;算法
中图分类号 G250 文献标识码 A 文章编号 2096-0360(2020)17-0012-04
随着互联网以及移动应用技术的发展,基于微信的社交化阅读方式的影响力不断扩大。微信公众平台是基于微信的一个功能模块,它注册简单、推送效率高、信息沟通速度快,所具有的一对多即时信息推送的特点使其在政府机构、企业、高校以及个人中得以广泛应用。
公共图书馆担负着为公众提供文化服务的使命,“互联网+”背景下的公共图书馆微信公众号服务拓宽了公共图书馆的服务渠道[1],优化了公共文化服务方式,推动其从传统的服务模式转向多媒体融合服务模式。目前,图书馆微信公众号作为优质的线上文化服务方式,已经得到了较为广泛深入的研究。然而,已有研究多是针对高校图书馆微信公众号服务,对公共图书馆微信公众号信息传播效果的研究成果和深度还比较欠缺。公共图书馆微信公众号服务面对的用户基数大,范围广,用户群体复杂,所提供的文化服务内容多,如何从中获取更优质、用户需求更大的文化服务内容,是当前公共图书馆微信公众号服务所面临的挑战之一。
已有对图书馆微信公众号的量化研究多是基于大数据的微信传播指数(WCI)的横向研究,通过参考多个维度的数据计算各微信公众号的WCI,进而进行多个微信公众号的传播影响力比较。李龙等人[2]通过利用WCI工具对35所高校图书馆微信公众号进行量化比较,提出了高校图书馆微信公众号建设举措。王康等人[3]通过计算56所高校图书馆微信公众号WCI指数及相关分析,对高校图书馆微信公众号传播影响力的因素进行了研究。对于特定的微信公众号而言,进行量化的实证研究较少,且已有研究多是针对于高校图书馆微信公众号。王晓慧等人[4]以武汉大学图书馆为例,通过推文标题、主题、阅读数等的相关分析探究了影响高校图书馆微信公众号信息传播力的因素。李晓蔚[5]以四川大学图书馆微信公众号为例,通过方差分析探究了微信公众号传播影响力的相关因素。这些研究通过对高校图书馆微信公众号进行实证研究,探究了高校图书馆微信公众号运营内容以及运营方式的强化策略,从而提升高校图书馆的微信服务效能。
然而,以国家图书馆微信公众号为例的公共图书馆微信公众号用户群体庞大且复杂,用户行为和用户需求更为多样化,对公共图书馆微信公众号的纵向研究还比较不足,对公共图书馆微信公众号的信息传播效果的衡量缺乏科学的标准体系。因而在传统的对消息传播效果策略进行研究的基础上,探究如何从内容种类丰富的消息服务中,动态获取当前用户更为偏爱的服务内容,从而基于当前用户内容服务需求进行动态调整,显得尤为重要。
机器学习方法中的无监督聚类算法,通过数据驱动的方式,在综合考虑推送顺序、推送内容等影响因素的基础上,可以从大数据的视角下对内容服务效果进行综合考量。同时,该算法运算速度快,稳定性相对较高,可移植性好,适合基于大量样本数据进行学习,动态獲取用户内容服务需求,能够为公共图书馆公众号用户需求服务提供方法学参考。
该研究将以国家图书馆微信公众号为例,通过无监督算法对图文消息对应的特征数据进行聚类分析,从大数据视角下对消息传播效果进行实证研究。结果表明,通过无监督聚类方法所获取的需求度更高的推送内容符合相关研究中的头条优势的原则;非参数检验结果显示,通过聚类算法得到的两类消息的用户需求存在显著性差异。与以往的基于推送内容和推送顺序的研究不同,利用机器学习方法中的无监督聚类算法,可以通过数据驱动的方式在综合考虑推送顺序、推送内容等影响因素的基础上,从复杂多样的用户行为数据中进行挖掘,动态获取用户需求,科学调整用户服务内容,从而不断优化公共文化内容服务。
1 公共图书馆微信公众号传播效果实证研究
1.1 数据来源
该研究抽样单位为国家图书馆微信公众号,分析单位为2018年5月1日至2019年4月30日期间通过国家图书馆微信公众号群发的354篇图文消息。研究数据包括每篇消息的送达人数、推送顺序、阅读数、点赞(在看)数、分享数、留言数等,统计截止时间为2019年10月31日。
1.2 数据处理
1.2.1 聚类方法
聚类方法的基本思想是将具有相似特征的原始数据聚为一类。其中,k-means算法是一种常见的聚类算法,该算法基于随机给定的k个簇中心,依照最近邻原则,分别计算各样本点与簇中心的距离,从而将样本点归到相应的簇中,在此基础上,用均值方法对聚类的中心点重新进行计算,迭代上述过程,不断更新聚类中心以及样本所属类,直至算法收敛。
以国家图书馆为例的公共图书馆微信公众号所面向的用户基数大,用户行为相对复杂,用户需求多样化,因此,通过数据驱动的方式,可以更好地从大量用户数据中对用户需求进行挖掘。通过算法本身的迭代达到收敛条件,来获取用户需求更大的服务内容,从而动态调整公共图书馆微信公众号服务内容。此外,以k-means聚类算法为例的聚类方法运算速度快,稳定性相对较高,可移植性好,适合基于大量样本数据进行学习,动态获取用户内容服务需求,能够为公共图书馆公众号用户需求服务提供方法学参考。
因此,研究中将聚类算法应用于图文消息的特征数据,在大数据视角下对公共图书馆微信公众号消息传播效果进行探究,以数据驱动的方式从大数据视角下对影响因素进行综合考虑,获取适用于当前用户群体的消息内容服务,对公共图书馆微信公众号运营提供具有针对性的内容服务指导。
1.2.2 无监督聚类分析
无监督的k-means聚类方法可将n×p维的观测数据矩阵X划分成k类,返回包含每个观测数据类标记的n维向量y,如下列公式所示:
y=kmeans(X,k)
通过将354篇群发消息的相关数据进行整理,可以得到维度为354×4的矩阵A,其中每一行代表一条消息,每一列分别代表消息的阅读数、点赞(在看)数、分享数、留言数等特征数据。
在该研究中,将通过对矩阵A执行k-means聚类分析的方式,从群发图文消息中根据特征数据选取出用户欢迎度更高、需求更大的消息内容。通过利用无监督k-means聚类算法对矩阵A进行处理,其中k取值为2,可以返回354维的类标签向量b。算法选用欧式距离作为相似性度量,用k-means++算法进行聚类中心初始化。
1.2.3 需求度得分分析
对于每篇图文消息,分别记录其阅读数、点赞(在看)数、分享数、留言数、送达人数,根据以下公式得到每篇消息的需求度分数。同时,分别记录每篇消息的推送顺序。综合每篇图文消息的各项指标数据,通过需求度得分公式可以计算出每篇消息的分数,计算公式如下所示:
score=(阅读數×40%+点赞(在看)数×20%+分享数×30%+留言数×10%)/送达人数
1.3 结果分析
在该研究中,包含通过国家图书馆微信公众号从2018年5月1日至2019年4月30日期间推送的所有图文消息数据,时间跨度为一年,共计354条图文消息。
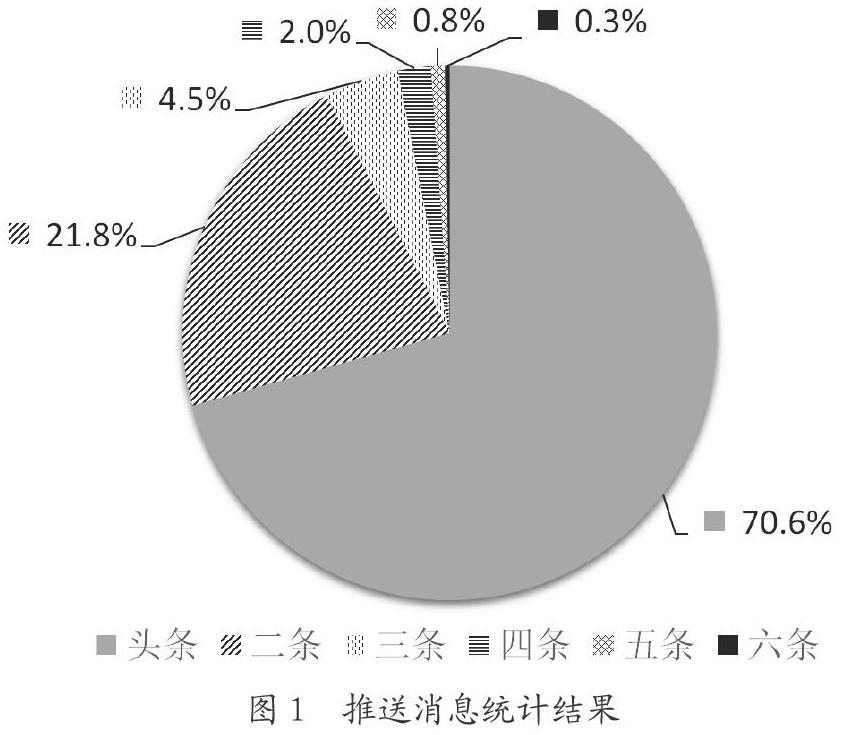
通过对所有推送消息进行统计,结果显示,其中头条占比为70.6%,各推送顺序类型消息的占比情况如图1所示。
通过对推送消息数据所对应的矩阵A执行聚类分析,利用k-means算法将特征数据分成两类,一类包含69条图文消息。其中,包含头条67条,头条占比为97%。无监督k-means聚类方法从大数据视角下对消息传播效果进行了分析,通过无监督聚类方法所获取的需求度更高的推送内容符合相关研究中的头条优势的原则。
对每篇文章的需求度得分进行排序,k-means聚类结果中的69条消息有47条排在需求度得分top50的文章中,与得分排在top70文章的重复比例为87%,与top100重复比例为100%。
根据k-means聚类所得到的类标签向量b,可以将需求度得分分为两组。对两组数据进行非参数检验,检验结果如表1所示。非参数检验结果显示,两组数据之间存在显著性差异。
通过对无监督聚类结果结合需求度得分进行对比分析,可以得出,基于聚类算法的用户需求更高的推送内容符合相关研究中的头条优势原则;非参数检验结果显示,通过聚类算法得到的两类消息的用户需求存在显著性差异。
国家图书馆微信公众号服务所面向的用户群体庞大复杂,用户需求呈现多样化的特点,与基于推送内容和推送顺序的研究不同,该研究利用机器学习方法中的无监督聚类算法,通过数据驱动的方式对用户行为样本数据进行挖掘,能够获取科学的用户服务内容服务指导。
2 讨论
通过无监督k-means聚类方法,根据每篇消息的阅读数、点赞(在看)数、分享数、留言数等特征数据,将国家图书馆微信公众号一年内共354篇群发图文消息分成两类,得到69篇公众需求度更高的消息。同时,通过需求度得分公式,分别计算每篇消息的得分并进行排序。结果显示,通过k-means算法得到的69篇消息,在需求度得分排序中排在top100,在top70中重合率为87%。
在通过聚类方法得到的69篇消息中,头条文章所占比例为97%,符合相关文献中的头条优势的原则。此外,69篇消息中头条文章在全部头条文章中所占的比例为27%,表明无监督k-means聚类方法可以在综合考虑推送顺序、推送内容等影响因素的基础上,更加精细地获取公众需求度更高的消息。
通过k-means算法得到的69篇消息进行归类统计,讲座、公开课、公益展演等所占比例为39%;展览类占16%;征文、活动、图书推荐类占22%;新闻、馆情资讯类占23%。其中包括 “本周讲座”“国图公开课招募”“节假日开馆安排”等常设栏目的部分内容以及部分国图新闻类资讯。
展览类文章中包含《永乐大典》文献展及内容报道、动漫原画特展、《四库全书》特展等热门展览。以《永乐大典》文献展为例,微信公众号配合线下展览进行了系列线上宣传,内容包括丰富有趣的展览预告、对《永乐大典》所经历的飘摇多舛的命运的阐述、通过幽默风趣的语言再现《永乐大典》的编纂过程等等,让读者对展品有了更深入的理解。
在征文、活动、图书推荐类中包括“我和我的祖国”征文活动、“行囊中的那本书”分享活动、古籍修复活动、“文津图书奖”获奖图书等。公共图书馆微信公众号作为传播读书的有效途径之一[6],可以通过用户活跃程度更高的读书类相关活动,不断提升图书馆微信公众号运营的读者参与度[7]。
基于微信公众号平台,在做好常设栏目内容推送的基础上,可以通过把握用户阅读兴趣,配合线下展览进行宣传、通过举办图书相关分享和推荐活动等方式,为用户提供需求度更高、更加丰富多彩的文化内容服务。
该研究以国家图书馆微信公众号为例,通过无监督算法对图文消息对应的特征数据进行聚类分析,对消息传播效果进行实证研究。结果表明,通过无监督聚类方法所获取的需求度更高的推送内容符合相关研究的头条优势原则;非参数检验结果显示,通过聚类算法得到的两类消息的用户需求存在显著性差异。与以往的基于推送内容和推送顺序的研究不同,利用机器学习方法中的无监督聚类算法,可以通过数据驱动的方式在综合考虑推送顺序、推送内容等影响因素的基础上,从复杂多样的用户行为数据中进行挖掘,动态获取用户需求,科学调整用户服务内容,为公共图书馆微信公众号的运营工作提供方法学参考,从而不断优化公共文化内容服务。
以国家图书馆为例的公共图书馆微信公众号服务所面向的读者群体庞大且复杂,用户需求多样,通过无监督聚类算法,以数据驱动的方式可以从大数据视角下对影响因素进行综合考虑,获取适用于当前用户群体的消息传播效果策略,对公共图书馆微信公众号运营提供具有针对性的指导,从而更好地提供读者服务。
此外,以k-means聚类算法为例的聚类方法运算速度快,稳定性相对较高,可移植性好,适合基于大量样本数据进行学习。因此,可以用于动态获取用户内容服务需求,为公共图书馆微信公众号用户需求服务提供了方法学参考。
3 结语
文中以國家图书馆微信公众号为例,通过无监督算法对图文消息对应的特征数据进行聚类分析,从大数据视角下对消息传播效果进行了实证研究。结果显示,通过无监督聚类方法所获取的需求度更高的推送内容符合相关研究中的头条优势原则;通过聚类算法得到的两类消息的用户需求存在显著性差异。与以往的基于推送内容和推送顺序的研究不同,文中基于庞大复杂的用户群体以及多样化的用户需求,利用机器学习方法中的无监督聚类算法,通过数据驱动的方式在综合考虑推送顺序、推送内容等影响因素的基础上,从大数据的视角下获取更加精细化的消息传播效果策略,为公共图书馆微信公众号的运营工作提供了方法学参考,从而不断优化公共文化内容服务。
参考文献
[1]张兴旺,李晨晖.当图书馆遇上“互联网+”[J].图书与情报,2015(4):63-70.
[2]李龙,王瑶,武含冰.基于新媒体大数据与读者点赞留言的高校图书馆微信公众号实证研究——以浙江省35所本科院校图书馆为例[J].图书馆学研究,2019(7):34-40,33.
[3]王康,王晓慧.高校图书馆微信公众号影响力指数相关性分析与发布内容研究[J].图书馆杂志,2018,37(5):52-57,81.
[4]王晓慧,王康.高校图书馆微信公众号信息传播影响因素研究——以武汉大学图书馆为例[J].上海高校图书情报工作研究,2017,27(4):35-38.
[5]李晓蔚.高校图书馆微信公众号传播效果实证研究——以四川大学图书馆为例[J].图书馆论坛,2016,36(11):84-91.
[6]李玉艳,钱军.图书馆微信公众号的传播策略[J].图书馆工作与研究,2016(2):95-97.
[7]姚鹏.高校图书馆微信服务大数据研究——以“985”工程高校为例[J].图书馆学研究,2017(4):62-67,50.
猜你喜欢
华东师范大学学报(自然科学版)(2019年5期)2019-11-11
阅读与作文(英语初中版)(2019年8期)2019-08-27
软件(2017年6期)2017-09-23
中学生数理化·高一版(2017年1期)2017-04-25
中学生数理化·高一版(2017年1期)2017-04-25
中学生数理化·高一版(2017年1期)2017-04-25
电子技术与软件工程(2016年23期)2017-03-06
科教导刊(2016年26期)2016-11-15
出版广角(2016年15期)2016-10-18
商(2016年27期)2016-10-17
