
基于AIS数据的交汇水域船舶会遇态势辨识
2021-03-10 13:31李文楷张春玮
中国航海 2021年1期
马 杰, 李文楷, 张春玮, 张 煜
(武汉理工大学 a.航运学院; b.内河航运技术湖北省重点实验室;c.国家水运安全工程技术研究中心; d.物流工程学院, 武汉 430063)
船舶会遇问题是海上船舶交通的研究热点[1],是确定船舶避让责任的重要依据和前提。[2]船舶会遇态势是船舶在航行过程中从不同方向相互驶近形成的会遇局面,一般分为对遇态势、交叉态势和追越态势。[3]在交通密度大、态势复杂的交汇水域,若能准确辨识船舶会遇态势,将对交汇水域的交通安全监管和降低船舶碰撞事故率产生重要的现实意义和应用价值。[4]
近年来,船舶自动识别系统(Automatic Identification System, AIS)[5]在海上交通控制和监控中得到广泛的应用,AIS也成为研究船舶会遇态势的重要工具。现有基于AIS数据的会遇态势研究主要是从空间角度展开利用统计分析、分布拟合等方法提炼船舶会遇特征,挖掘船舶会遇行为规律。冮龙晖等[6]从最近会遇距离和两船航向夹角等会遇特征参量中提取船舶会遇信息;朱姣等[7]构造由船舶位置、航速和航向组成的船舶航行状态空间模型辨识船舶会遇态势;甄荣等[8]利用AIS数据提取船舶经纬度信息,通过计算船舶间的相对距离并利用密度聚类方法进行船舶空间位置聚类分析,制定船舶会遇态势判别规则;ZHANG等[9]通过构建两船距离、航向差和相对航速的拟合方程对船舶会遇态势和潜在的碰撞风险进行描述。从空间角度进行会遇特征分析和会遇态势辨识,忽略了会遇过程的时空变化特性,特别是在通航环境复杂的交汇水域,船舶机动转向的情况较多,船舶运动表现出较大的不确定性将导致会遇特征更大范围的波动。仅考虑会遇船舶间的空间约束和位置特征进行会遇态势判别,会发生误判的情况。马杰等[10]考虑会遇的时空变化,提出一种船舶会遇特征序列构建方法并利用支持向量机(Support Vector Machine, SVM)实现船舶会遇态势信息的分类提取,但该方法需利用完整的船舶会遇轨迹信息,无法用于船舶会遇态势的在线辨识。
鉴于以上不足,本文重点考虑船舶会遇过程的时空演化特性,从AIS产生的海量数据中提取船舶航向差和相对距离作为会遇特征并构建会遇特征序列,建立基于支持向量机与贝叶斯滤波(Support Vector Machine and Bayesian Filter, SVM-BF)[11]的会遇态势辨识模型。通过建立BF与会遇态势的对应关系,使改进的SVM-BF模型能满足交叉、对遇和追越等不同会遇态势辨识的需要,有效提高辨识准确率,为船舶会遇危险局面分析与研判提供一种智能化方法。
1 会遇特征序列构建
1.1 会遇特征参量计算
会遇几何模型是研究在会遇过程中两船行为的重要方法。[12]会遇几何模型将会遇船舶视作以一定速度做矢量运动的2个质点,因此,可借助平面几何的相关知识来计算在会遇过程中的会遇特征参量。[13]2艘船舶的会遇场景见图1,在会遇过程中,相对距离的最小值(最近距离)可反映出两船接近的程度,若最近距离大于一定范围,则两船之间发生不会遇,通常将6 n mile作为会遇局面的限定值。[14]但仅考虑距离特征是不够的,辨识会遇态势还需考虑2艘船舶的相对方位。航向差是判别船舶会遇态势的重要依据,由于大多数船舶的对地航向都能通过全球定位系统(Global Positioning System, GPS)有效地获取,因此,采用对地航向计算两船的航向差作为会遇船舶相对方位的表征。[15]综合以上因素,确定以会遇船舶的相对距离与航向差作为会遇特征参量。设本船的经纬度坐标为(lngo,lato),速度标量为vo,对地航向为φo,目标船的经纬度坐标为(lngt,latt),速度标量为vt,对地航向为φt。2种会遇特征参量为

图1 2艘船舶的会遇场景

(1)
2)两船航向角φo和φt延长线交于点Q,航向差为
(2)
从AIS原始数据中提取会遇船舶轨迹数据(包括经纬度、航速和航向等),考虑AIS数据缺失和不同步等问题,对轨迹进行插值、同步等预处理,保证每秒时间点上都有数值,最后利用式(1)和式(2)计算会遇船舶2个特征量。
1.2 会遇特征序列提取
船舶会遇是一个时空演化的过程,因此,需同时从空间和时间2个方面对其进行考量。通过上述会遇特征参量的计算,获得会遇船舶在空间上的表征。进一步考虑会遇特征在时间上的变化。首先,从会遇初始阶段,以10 s为采样间隔,对其内的相对距离和航向差分别计算平均值,得到2维均值向量作为会遇特征向量。考虑到2种会遇特征参量的量纲存在差异,对其进行标准化处理为
(3)
(4)
[D1A1…DkAk…DmAm]
(5)
设数据集中包含的会遇船舶数量为s对,则可提取s条会遇特征序列构成会遇特征矩阵Wm,s为
(6)
2 基于SVM-BF会遇态势辨识
2.1 辨识模型
SVM[17]是一种基于边缘最大化的监督学习算法,其目标是找到一个超平面使不同类别的数据点之间的分离间隔最大化。其基本原理是利用核函数[18]的方法将数据从低维度投影到高维度,实现数据点在高维空间的线性可分。仅使用SVM辨识会遇态势建模容易出现误判虚警的情况。针对该问题,采用SVM与BF相结合的方式进行辨识建模,在现有SVM-BF[19]的基础上,通过设计SVM-BF中BF与会遇态势的对应关系,使每个BF对应一种船舶会遇态势,将辨识船舶会遇态势设计成一个二分类问题,从而实现对交叉态势、对遇态势和追越态势等态势,模型框架见图2。

图2 基于SVM-BF的船舶会遇态势辨识模型框架
模型的训练过程如图2所示,首先从AIS数据集中构建会遇特征矩阵Wm,s并将其划分为训练集特征矩阵Tm,n和测试集特征矩阵Tm,n*。tm,j表示训练集中第j对船舶的会遇特征序列为
tm,j=[f1,j…fk,j…fm,j],fk,j=[Dk,jAk,j]
(7)
式(7)中:根据fk,j可确定Ck,j的类别,Ck,j∈{交叉,对遇,追越,其他(非会遇)}。随后对SVM每个判别模块逐次训练,将fk,j与Ck,j输入到SVM判别模块(由3个SVM组成)中,得到每个SVM超平面的权重和偏置。训练BF判别模块(由3个BF组成)并确定每个BF判别模块的阈值τ,不失一般性,3个BF判别模块分别对应交叉态势、对遇态势和追越态势。对应模型的测试过程如图2所示,tm,j*为测试集中第j*对船舶的会遇特征序列,将tm,j*输入到SVM判别模块,SVM判别模块会输出第j*对船舶对应的会遇类别序列C为
C=[C1,j*…Ck,j*…Cm,j*]
(8)
将其作为BF判别模块的输入,并将每个BF判别模块输出的后验概率与对应的阈值τ进行比较即可实现对交叉态势、对遇态势和追越态势等态势的辨识。
2.2 辨识算法
首先对SVM判别模块进行训练。在SVM判别模块中,根据Tm,n中fk,j以及对应的Ck,j建立形如{fk,j,Ck,j}的数据对,并在每个SVM判别模块中按照Ck,j的类别赋予Ck,j标签。在第1个SVM判别模块中,当Ck,j属于交叉时,Ck,j被标记为1,否则,Ck,j被标记为-1。将这些数据对作为第1个SVM判别模块的输入。在Ck,j(wΤfk,j+b)≥1的约束条件下,目标函数为
(9)
式(9)中:w和b为超平面的权重和偏置。由于训练数据通常是线性不可分的,因此,需要寻找一个核函数将这些低维数据映射到更高维度的空间,即
φ(fk,j)×φ(fq,l)=K(fk,j,fq,l)
(10)
结合拉格朗日乘子法,有
(11)
对式(11)进行求解为
(12)
由式(9)~式(12)可得到第1个SVM超平面的权重与偏置,实现第1个SVM判别模块的训练。初始化Ck,j并重新确定Ck,j标签,当Ck,j属于对遇时,Ck,j被标记为1,否则,Ck,j被标记为-1,将数据对输入到第2个SVM判别模块中,计算相应超平面的权重与偏置,以完成第2个SVM判别模块的训练。依此类推,重新标记Ck,j并将标记好的数据对输入到第3个SVM判别模块中,计算第3个SVM超平面的权重与偏置,结束SVM判别模块的训练过程。
随后对BF判别模块进行训练。建立由Ck,j组成的会遇类别序列C作为BF判别模块的输入,第1个BF判别模块会求解交叉态势对应的后验概率密度函数P(θ|C)。由于BF是对Ck,j进行二分类,而直接使用二项分布较难求解P(θ|C),考虑到共轭分布不仅可求出后验分布的封闭形式,同时,也保留先验分布的性质,使估计概率更加准确。而β分布与二项分布是一组共轭分布,因此,采用β分布作为θ的先验分布[20]为
(13)
式(13)中:β分布的超参数a和b为每种会遇态势的“置信度”权重,即Ck,j所属的会遇态势的有效观测值,a和b初始值设定为1,表示θ在初始时刻服从均匀分布。Γ(a)是Gamma函数为

(14)
θ的似然函数服从二项分布为
(15)
根据贝叶斯公式,θ的后验分布P(θ|C)可通过似然函数bin(u|v,θ)与先验分布β(θ|a,b)相乘得到[21]:
(16)
当会遇类别序列C中的Ck,j为交叉时,v=1,u=1;Ck,j为非交叉(对遇,追越和其他(非会遇))时,v=1,u=0。随着每次输入Ck,j,a和b的表达式更新为a=a+u,b=b+v-u。通过计算P(θ|C)的期望值来累积辨识tm,j是否属于交叉态势为
E(θ|C)=P(tm,j=交叉态势|C)=
(17)
将E(θ|C)与τ1进行比较,如果E(θ|C)>τ1,第1个BF判别模块会将第j对船舶的会遇态势辨识为交叉态势。与第1个BF判别模块相同,第2个BF判别模块也会根据E(θ|C)和τ2的关系辨识第j对船舶是否为对遇态势。依此类推,第3个BF判别模块会根据E(θ|C)和τ3的关系辨识第j对船舶是否为追越态势。如果3个BF判别模块的期望都小于阈值,SVM-BF会将第j对船舶辨识为其他(非会遇)。遍历Tm,n中会遇类别序列C,得到BF判别模块对交叉态势、对遇态势和追越态势等态势的整体辨识准确率。当整体辨识准确率达到90%时,可使SVM-BF模型获得良好的训练效果和泛化性能。因此,在对BF判别模块训练的过程中,如果BF判别模块对交叉态势、对遇态势和追越态势的整体辨识准确率小于90%,则需分别修改阈值τ1、τ2和τ3的数值,并再次遍历Tm,n中的会遇类别序列C,重复上述步骤,直到BF判别模块对每种会遇态势的整体辨识准确达到90%,才可结束BF判别模块的训练过程。从Tm,n*中选取tm,j*输入SVM判别模块,得到tm,j*对应的会遇类别序列C,将其输入到BF判别模块得到第j*对船舶的会遇态势,实现船舶会遇态势辨识(测试)。基于SVM-BF的会遇态势辨识伪码如下:
算法名称:基于SVM-BF的船舶会遇态势辨识
输入:测试集矩阵Tm,n*,阈值τ1、τ2和τ3
BEGIN
1.FORj*INn*
2.选取tm,j*=[D1,j*A1,j*…Dk,j*Ak,j*…Dm,j*Am,j*]
3.令fk,j*=[Dk,j*Ak,j*],tm,j*=[f1,j*…fk,j*…fm,j*]
4.初始化会遇类别序列C
5.FORkINm
6.输入fk,j*到SVM判别模块
7.根据式(10)~式(12)计算的w和b得到Ck,j*
8.添加Ck,j*到C
9.END FOR
10.FORi=1 TO 3 DO
11.输入C到第i个BF判别模块
12.根据式(16)~式(17)计算E(θ|C)
13.IFE(θ|C)>τi
14.IFi=1
15.RETRUN 第j*对船舶属于交叉态势
16.IFi=2
17.RETRUN第j*对船舶属于对遇态势
18.IFi=3
19.RETRUN 第j*对船舶属于追越态势
20.END FOR
21.RETRUN第j*对船舶属于其他(非会遇)
22.END FOR
3 试验与分析
3.1 试验水域
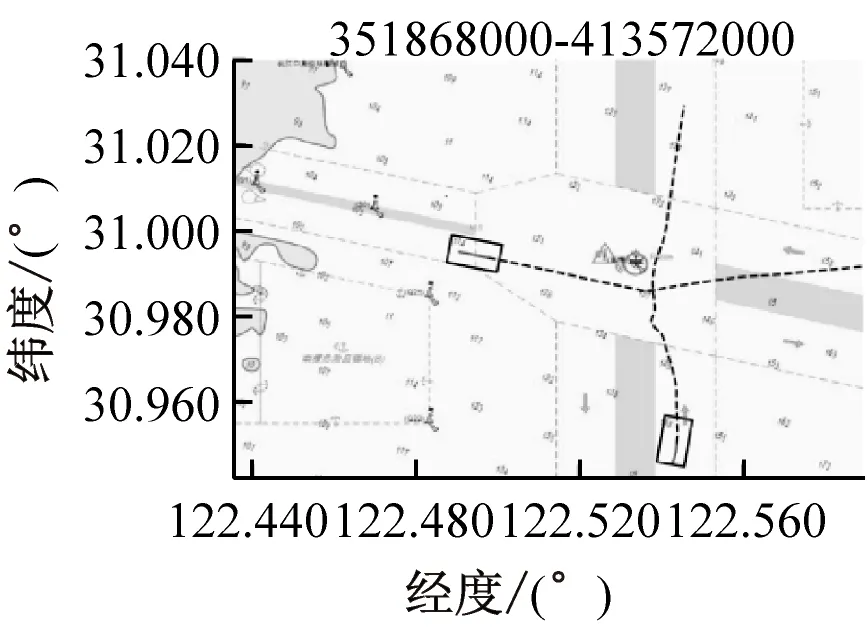
选取长江口南槽交汇水域作为研究对象,见图3,该水域船舶交通流量较大且船舶发生会遇的情况频繁,是典型的交汇水域,辨识该水域进行会遇态势的研究具有代表意义。收集该水域2017年7月—2017年11月的AIS数据开展模型训练和算法验证。提取船舶会遇态势信息并利用人工标注的方式确定船舶会遇态势类别,共得到1 200条船舶会遇数据,其中:训练集有800条数据,包含3种船舶会遇态势以及其他(非会遇)的数据各200条;测试集则包含每类数据各100条,共400条数据。进行数据预处理和特征提取并将时间窗口长度设置为150 s,因此,每条会遇特征序列中包含15个2维均值向量。
3.2 实例分析
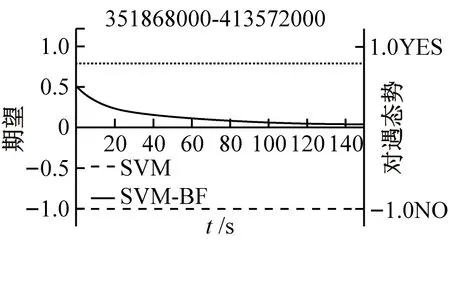
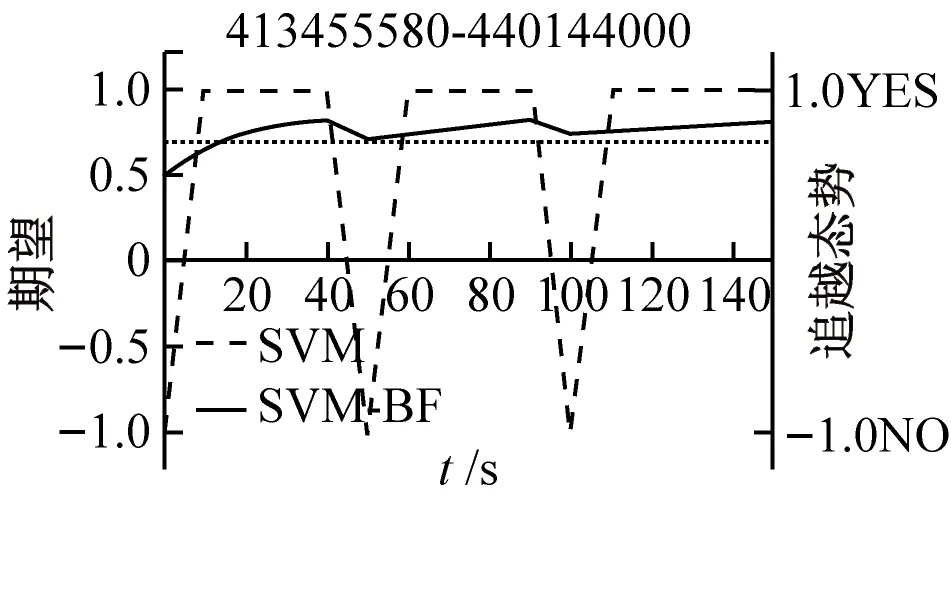
使用训练集数据训练SVM-BF模型,根据辨识算法中阈值的确定规则,得到τ1、τ2和τ3分别为0.7、0.8和0.7。分别使用SVM模型和SVM-BF模型对测试集进行测试。2种模型对5种场景实例的船舶会遇态势辨识结果见图4。交叉、对遇、追越、其他(非会遇)、有避让的交叉场景实例以及2种模型对不同场景实例的会遇态势辨识结果见图4a~图4t,图中实线为SVM-BF模型辨识结果的取值范围由左边的纵坐标轴确定;虚线为SVM模型的辨识结果并由右纵坐标轴确定,当取值1.0(YES)时为SVM模型正确辨识会遇态势,当取值-1.0(NO)时为SVM模型产生错误的辨识结果;水平虚线则表示τ1、τ2和τ3,5个场景实例中方框对应的轨迹段的窗口长度为150 s。

图3 长江口南槽交汇水域
1)对于交叉场景实例,由图4b~图4d可知:SVM模型在70 s时产生误判,辨识结果直到80 s后才趋于稳定,最终SVM模型会将此场景实例辨识为交叉态势。相比于在对交叉态势辨识时,SVM-BF模型产生的期望E(θ|C)在20 s时已超过τ1,虽然E(θ|C)在60~80 s时出现波动但始终大于τ1。因此,SVM-BF模型会在20 s时将此场景实例辨识为交叉态势。
2)对于对遇场景实例,由图4f~图4h可知:2种模型在所有的采样点都产生了正确判断,2种模型都会将此场景实例辨识为对遇态势。
3)对于追越场景实例,由图4j~图4l可知:SVM模型在50 s和100 s 2个时刻产生误判,辨识结果直到110 s后才稳定。相比于SVM-BF模型在辨识追越态势时,虽然期望曲线也在这2个采样点出现震荡,但E(θ|C)始终大于τ3所在的水平线,因此,SVM-BF模型会将此场景实例辨识为追越态势。
4)由图4n~图4p可知:在对其他(非会遇)场景实例辨识时,由于存在频繁的转向行为,SVM模型产生大量的误判,并做出错误的辨识结果。而SVM-BF模型可对SVM产生的初判结果做出累积判别,虽然期望曲线出现持续的波动,但E(θ|C)一直都小于τ1、τ2和τ3。因此,SVM-BF模型会将此场景实例辨识为其他(非会遇)。
5)对于有避让的交叉场景实例,由图4r~图4t可知:船舶避让行为使得SVM模型在120 s后都做出误判,相比于在辨识交叉态势时,虽然SVM-BF模型的期望曲线在120 s时也出现下降,但E(θ|C)始终位于τ1所在的水平线之上,因此,SVM-BF模型会将此场景实例辨识为交叉态势。由图4a~图4t可知:在对交叉、对遇和有避让的交叉3种场景实例的会遇态势进行辨识时,SVM-BF模型产生的累积期望在第2个采样时刻已经超过阈值。
因此,将SVM-BF模型应用到实船避碰时,超过阈值的辨识结果可帮助船长辨识船舶的会遇态势。此外,交汇水域存在多船会遇的情况,多船会遇态势辨识的通常采用两两船舶依次判断,本文所提出的方法虽然基于两船之间进行会遇态势辨识,但很容易应用到多船场景。
a)交叉场景实例

b)辨识交叉态势
c)辨识对遇态势

d)辨识追越态势

e)对遇场景实例

f)辨识交叉态势

g)辨识对遇态势

h)辨识追越态势

i)追越场景实例

j)辨识交叉态势

k)辨识对遇态势
l)辨识追越态势

m)其它(非会遇)场景实例

n)辨识交叉态势

o)辨识对遇态势

p)辨识追越态势

q)有避让的交叉场景实例

r)辨识交叉态势

s)辨识对遇态势

t)辨识追越态势
3.3 总体结果
2种模型对测试集进行辨识的总体结果见表1,表1中的准确率是2种模型在不同窗口长度下的辨识结果。例如,在90 s时间窗口中,SVM和交叉对应的百分数表示SVM在窗口长度为90 s时对交叉态势的辨识准确率。由表1可知:在不同场景下,SVM-BF模型在各个时间窗口下的准确率都要高于SVM模型,尤其对其他(非会遇)场景,SVM-BF仍能以超过91%的准确率对其进行辨识。此外,2种模型辨识的准确率都随着窗口长度的增加而提高,这也与实际情况相吻合,更长的时间序列包含更丰富的会遇态势信息,因而模型的泛化能力也会相应的提高。

表1 2种模型的辨识结果
4 结束语
针对因交汇水域通航环境复杂易产生船舶会遇态势的误判问题,选取相对距离和航向差得到会遇船舶在空间上的表征,计算其均值向量并在时间轴上展开,构建会遇特征序列。使用会遇特征序列辨识船舶会遇态势考虑会遇过程时空演化特性。联合SVM与BF建立会遇态势辨识模型,实现对SVM初步辨识结果的平滑滤波,消除误判虚警的情况,提高辨识准确率。选取长江口南槽交汇水域的AIS数据开展模型和方法验证,结果表明:SVM-BF能以较高准确率对交叉态势、对遇态势和追越态势等态势进行辨识。在SVM模型产生误判的情况下,SVM-BF模型依然可根据累积的期望做出正确的辨识结果。提出的模型和方法可应用于交汇水域的会遇态势自动识别与预警。今后可在辨识模型中考量更多的会遇特征参量,并进一步探究影响会遇态势演化的相关因素,以提升模型的准确性。
猜你喜欢
舰船科学技术(2022年10期)2022-06-17
新世纪智能(高一语文)(2021年3期)2021-07-16
汽车与安全(2020年1期)2020-05-14
中国外汇(2019年19期)2019-11-26
中国化肥信息(2019年5期)2019-06-25
民用飞机设计与研究(2019年4期)2019-05-21
电子制作(2017年24期)2017-02-02
中国卫生(2015年2期)2015-11-12
高中生学习·高三版(2014年3期)2014-04-29
高中生学习·高三版(2014年3期)2014-04-29
