
基于迁移学习的机场场面目标检测与跟踪技术研究
2021-06-28 12:23李彦冬夏正洪
电子测试 2021年2期
李彦冬,夏正洪
(中国民用航空飞行学院,四川广汉,618300)
0 引言
机场场面监视是民航安全运行中的重要一环,一直以来都是民航关注的一个重要问题。传统的机场场面监视主要利用场监雷达和多点定位等基于电磁波的技术手段对场面目标的位置和身份进行识别。这种方式对于目标的位置信息能够较好地进行判断,然而对于目标的类型,尤其是一些非合作目标的身份,缺少鲁棒的判断能力。
从2012年开始,深度学习技术逐渐成为人工智能领域的一个研究热点[1]。近年来,针对深度学习技术的研究在图像理解、语音识别、自然语言处理、围棋对弈、自动驾驶等领域都取得了超越传统方法的突破性成果[2]。深度学习技术是一种以数据驱动的机器学习方法,可以通过大量的数据对机器学习模型进行训练,从而让模型获得对于数据模式的识别能力。然而,在很多实际的应用场景中,数据的获取比较困难,小样本环境是深度学习技术在实际应用中通常会遇到的问题,迁移学习技术是解决小样本问题的方式之一[3]。
本文以深度学习技术为研究对象,在模型训练数据不足的情况下,采用迁移学习的策略研究对于机场场面目标的视频识别与跟踪方法。实验结果表明,基于迁移学习的策略,本文中的深度学习模型对于场面中的目标具有较好的检测与识别能力。
1 基于深度学习技术的目标检测
目标检测是计算机视觉领域的一个基础而重要的问题,其研究目标是从图像或视频场景中准确定位潜在物体的位置,并且对目标物体的类别进行准确的识别。传统的目标检测算法主要通过从图像中提取大量的潜在目标框,然后对各个框图内的目标进行特征提取与识别。这种识别方式的缺陷有两点:(1)通常图像目标框的数量会比较庞大,逐个处理会影响目标检测的速度;(2)传统方法采用人工设计特征(如:LBP, SIFT等)对目标框的特征进行提取,这些特征通常具有较弱的判别和泛化性能。
深度学习是近年来兴起的一种机器学习方法,其主要特点是对于目标特征的提取不再基于人工设计特征,而是基于层层相连的深度数学模型。通过大量数据的的训练,原本参数随机初始化的深度网络能够学习到数据中潜在的特征,从而完成特征的提取。众多研究表明,这种通过学习方式获得的目标特征相比于传统的人工设计特征具有更好的表达能力。深度学习模型作为一种数据驱动的数学模型,对数据量的要求比较高,因此,对于一些数据量相对有限的特定应用场景,通常采用迁移学习的策略。迁移学习的思路是先通过在大型数据集上对深度学习模型进行训练,让模型的训练误差达到收敛,确定模型中的参数值,然后通过针对特定小样本数据集的训练,对模型参数进行微调更新,从而让模型对于小样本数据集具有特征提取与判别的能力。通过迁移学习策略,解决了小样本数据集对于深度模型的训练支持不足的问题,有效地扩展了深度学习技术在特定场景的应用。
2 基于迁移学习的场面目标检测
针对机场场面视频数据集相对环境比较单一,训练样本较少的特点,本文利用基于迁移学习的场面目标检测模型训练方案进行面向场面目标的检测模型训练(如图1所示)。该方案主要分为:构建深度学习模型、构建训练数据集和模型训练三个主要部分。

图1 基于迁移学习的场面目标检测模型训练方案
2.1 构建深度学习模型
目标检测的深度学习模型主要分为精度较高的两阶段模型和速度较快的一阶段模型两个大类。针对场面目标检测的实时性需求,本文选择了一阶段代表性的YOLO模型作为目标检测模型进行研究。YOLO是一种端到端的目标检测模型,针对原始图像通过骨干卷积网络提取特征,然后通过设计的Neck结构对于特征在多尺度上进行融合,最终在输出层通过非最大抑制(Non-Maximum Suppresion, NMS)的策略进行检测框的生成。YOLO模型具有轻量级,运行速度快的特点,在通用数据集的测试上也具有一定的目标识别准确度。
2.2 训练数据集
在训练数据集方面,本文采用了通用的目标检测数据集MSCOCO和实地采集的广汉机场视频图像数据集。
MSCOCO数据集在目标检测领域是一个应用广泛的数据集,其包含了91个目标类别,超过10万张用于训练和测试的图片,对于大型深度网络来说是一个常用的数据集。但是,由于机场场面的运行具有其具体特点,因此针对机场实地采集数据,也进行了相应的目标标注用于训练。图2是人工标注的一个样本图像。其中,行人以标签0作为标记,飞机以标签4作为标记。

图2 广汉机场视频图像人工标注(4:飞机,0:行人)
2.3 训练模型
在实际的模型训练中,针对输入图像X,首先通过目标检测模型完成网络的前向传导:

公式(1)中,f(x)是基于网络模型参数(W, b)的目标检测模型。模型初始化参数随机,通过前向传导之后,获得潜在的目标检测结果H = [H1, H2, ..., Hn]。目标检测结果与数据集标签之间的差异,作为训练的损失E(W, b):

对于损失E(W,b),通过梯度下降方法(Stochastic Gradient Descent,SGD)对网络参数(W,B)进行更新:
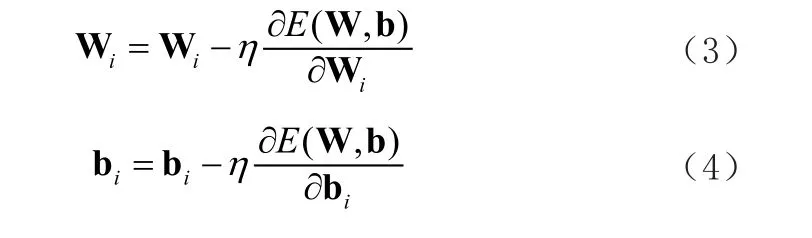
经过训练后的网络f(W, b)通过更新网络的参数,能够拟合训练数据集的特点,从而具备目标检测的能力。
本文中采用的MSCOCO数据集尺度比较大,具有良好的模型参数训练功能,但是不具备针对特定场景的目标检测标记。因此,在实际训练过程中,先使用MSCOCO数据集对参数训练到收敛,然后使用人工标注的广汉机场数据集进行迁移训练,从而使模型具有良好的对于机场场面目标的检测与跟踪能力。
3 实验分析
本文使用的深度学习硬件平台主要包括Xeon(R)W-2133处理器(3.6GHz),64GB内存和RTX2080Ti显卡。实验软件环境采用64位Ubuntu18.04操作系统。实验结果表明(表1),经过迁移学习的深度目标检测模型能够在广汉机场对飞机、车辆和人物目标的识别准确率达到82%,跟踪准确率达到78%。在图像处理速度方面,由于深度网络的运算开销较大,采用CPU的处理速度较慢,约为3帧/秒。但是,在采用GPU处理之后,图像处理的速度能够达到约45帧/秒,可以满足实时的场面目标检测与跟踪需求。

表1 广汉机场场面目标检测模型实验结果
图3是三帧视频在迁移学习前后的目标检测效果对比。从图中可以发现,仅仅通过在大型数据集MSCOCO上训练得到的目标检测模型并不能够很好地应用于机场场面环境的目标检测工作中,出现了较多的飞机漏检、将VOR导航台错判为飞机等目标检测错误。在迁移学习后,模型对于机场场面的飞机、行人和汽车都能够进行较为准确的识别。因此,迁移学习在深度目标检测模型应用于具体场景中的时候具有非常关键的作用。

图3 同一帧视频在迁移学习前(左)与迁移学习后(右)的目标检测效果对比
4 结束语
本文针对基于迁移学习的机场场面目标检测与跟踪技术进行了研究。采用迁移学习的策略,使基于大型通用目标检测数据集训练的目标检测模型具有了针对特定机场场面目标的检测与跟踪能力。基于广汉机场实地采集的视频图像分析,该方法具有较好的场面目标检测与跟踪性能,并且在GPU计算的条件下,能够具备实时图像处理的能力。
猜你喜欢
环球时报(2023-02-28)2023-02-28
中学生数理化·七年级数学人教版(2020年11期)2020-12-14
铁道通信信号(2020年3期)2020-09-21
艺术品鉴证.中国艺术金融(2018年8期)2019-01-14
艺术品鉴证.中国艺术金融(2018年10期)2019-01-08
艺术品鉴证.中国艺术金融(2018年12期)2018-08-26
百科探秘·航空航天(2018年4期)2018-05-14
新高考(英语进阶)(2017年11期)2018-01-22
文史博览·文史(2017年4期)2017-04-21
唯实(2015年5期)2015-07-22
