
基于大数据的实验室局域网络含噪字符识别方法研究
2021-07-14 08:50杨磊
内蒙古民族大学学报(自然科学版) 2021年3期
杨 磊
(安徽财经大学 教务处,安徽 蚌埠 233000)
0 引言
实验室局域网含噪字符易受到环境等因素的干扰,导致含噪字符的识别能力较差,需要研究含噪字符图像特征识别模型,结合模糊相关性特征检测方法,进行含噪字符图像识别[1].对含噪字符图像特征识别是建立在特征提取和模糊度分析基础上,建立含噪字符图像特征识别的统计分析模型,采用模糊信息融合方法,进行含噪字符图像局部模糊特征提取和识别[2],相关的含噪字符图像特征识别方法研究受到人们的极大关注.
在传统方法中,对含噪字符图像局部模糊特征识别方法主要有子空间特征识别方法,模糊特征检测方法和区域分块信息增强方法等[3].文献[4]提出空间欠采样技术的含噪字符图像特征识别方法.通过构建实验室局域网含噪字符图像的空间采样模型,结合局域网含噪字符特征分析方法进行信息特征分析等.该方法有效提高特征识别能力,但该方法在进行含噪字符图像局部模糊特征识别时精度不高.
针对上述问题,本文提出基于模糊边缘特征检测和模板匹配的含噪字符图像局部模糊特征精准识别方法.
实验结果表明:采用本文方法可以提高含噪字符识别能力,且优越性能显著.
1 含噪字符图像视觉空间采样及特征提取
1.1 基于大数据的含噪字符图像视觉空间采样
为了实现含噪字符图像特征识别,首先需要对含噪字符图像视觉空间进行采样,本文借助大数据对其进行采样处理.
假设含噪字符图像视觉空间数据为ϑ1(i),ϑ2(i),...,ϑn(i),通过公式(1)获取含噪字符图像视觉空间数据,即:

式(1)中,ϑ代表含噪字符图像视觉空间基本数据量,a,b表示含噪字符图像视觉空间数据的基本特征,A,B表示不同含噪字符图像视觉空间数据的基本特征集合.
在上述获取的含噪字符图像视觉空间数据后,由于该样本数据量较大,存在一定重复及噪声较大的数据样本,需要对该数据进行有效的清洗,即:

式(2)中,ϑ(k)代表精确的局域网含噪字符图像视觉空间数据,g(k)代表局域网含噪字符图像视觉空间数据总集,v(k)代表干扰、重复的含噪字符图像视觉空间数据集.
在此基础上,通过构建含噪字符图像的三维可视化特征重建模型[5].结合含噪字符图像的局部模糊特征采样结果,进行含噪字符图像的模糊特征分析.
假设含噪字符图像的边缘轮廓长度为L=xmax-xmin,含噪字符图像的分布空间区域的宽度为W=ymax-ymin,结合模糊边缘区域重构方法,进行含噪字符图像的特征重构和识别,建立含噪字符图像的模糊特征块分配模型[6],得到含噪字符图像的局部模糊空间分布像素序列为:

其中,m为含噪字符图像的轮廓曲线分布维数,p代表含噪字符图像上的一点.结合模糊信息融合方法,进行含噪字符图像的特征识别[7].基于边缘轮廓特征检测方法,构建含噪字符图像的分布式模板匹配函数为ηm(x,y)∈{-1,0,1},对含噪字符图像进行空间区域定位,得到图像分量为:

其中,ψ为含噪字符图像的局部模糊特征抽样阈值,且0≤ψ≤1.采用向量量化检测的方法,获取含噪字符的量化编码,得到特征编码的均值为0,方差为,由此建立含噪字符的特征匹配模型,结合空间采样技术进行含噪字符图像重建和识别[8].
1.2 图像局部模糊特征提取与融合
通过模板自动匹配和小波多尺度分解方法,检测含噪字符图像的局部模糊特征,建立含噪字符图像的视空间区域融合模型[9],得到含噪字符区域分布的灰度直方图为:
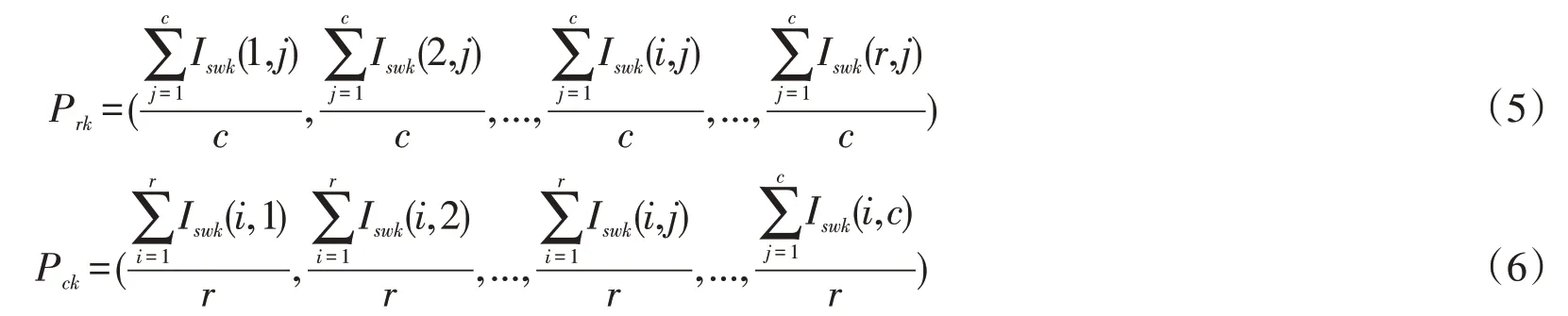
其中,c为含噪字符图像像素分布列数,r代表含噪字符图像像素分布行数,I代表局域网含噪字符图像的真实灰度值.
提取局域网含噪字符图像的谱特征量,根据谱特征量分布进行局域网含噪字符局部模糊特征的多维重建,含噪字符轨迹模糊度函数为:

式(8)中,Δu为含噪字符图像的全局阈值分割关联像素点,σ为含噪字符图像灰度差异度特征量.
在上述含噪字符图像灰度差异度特征量提取后,为了保证后续识别含噪字符的准确度,对其特征进行融合.将获取的特征量通过大数据技术进行融合.假设在特征量数据中存在多个数据,其大小值基本相同,为保证特征量的均匀分布,数据融合后的结果为:

式(9)中,G(a)代表融合结果,R代表图像局部模糊特征量,⊗代表数据融合介质,ϑ代表2个特征量相邻的概率.
在实验室局域网含噪字符图像区域内,提取实验室局域网含噪字符图像的局部关联帧,根据上述分析,提取含噪字符图像的局部模糊特征并对其进行融合.
2 含噪字符图像特征识别
2.1 含噪字符图像局部模糊区域像素特征点重构
构建含噪字符模糊区域视觉图像的稀疏性特征分割模型,重构含噪字符图像的边缘轮廓特征分布集,采用模糊边缘特征识别含噪字符图像特征,得到含噪字符图像相似度特征量,含噪字符图像的边缘与区域信息的变分水平集[10]为:

其中,

假设第k个含噪字符模糊区域的模糊分布特征向量为:

其中,Ic(y)为含噪字符局部模糊跟踪像素集,Ac表示含噪字符图像的尺度信息.根据灰度特征点重组,对含噪字符的图像信息进行融合,得到信息融合矩阵描述为:

其中,Lxy(x,σ)和Lyy(x,σ)为不同含噪字符特征匹配点的移动尺度.
采用超像素特征融合方法,得到含噪字符像素特征点重构输出为:

其中,p(ωi)为含噪字符图像的超像素大数据集分布维数.
2.2 含噪字符图像特征识别
基于GEPSO模型特征匹配方法[11],建立网含噪字符的模板自动匹配模型,采用小波多尺度分解方法,进行含噪字符图像局部区域重构和再检测,分割图像活动轮廓并进行优化.将含噪字符图像分割成M×N个2×2的子块Gm,n,得到含噪字符图像的匹配集为:

充分利用含噪字符图像字符串的分布进行特征匹配,融合图像边缘区域信息.采用大数据融合分析方法,进行含噪字符识别.建立含噪字符图像局部模糊特征检测模型,得到特征分布函数描述为:


其中,Gnew和Gold分别是含噪字符图像的分布向量集,进行含噪字符图像的视觉跟踪和分块匹配[12],实验室局域网含噪字符图像的特征识别输出为:

其中,ejθF(k1,k2)和ejθG(k1,k2)为含噪字符跟踪目标域的分量,模板匹配大小为N1×N2,局域网含噪字符图像的标准测试集为:

其中,‖sj‖表示sj中含噪字符图像相似度.结合模板匹配方法,检测和匹配含噪字符特征,建立含噪字符图像局部模糊特征的分块辨识模型.
3 实验分析
为了验证本文方法在实现实验室局域网含噪字符图像特征识别中的应用性能,进行仿真实验分析.
3.1 实验环境和参数
结合Visual C++和Matlab进行仿真实验,含噪字符图像采样数据库来自于网络数据库DadaSet,随机选取了5 000份实验数据进行特征识别,其中,训练集样本为2 000,测试集样本为1 000份,含噪字符的分布像素强度为120 dB,特征采样的时间间隔为0.46 s,样本的帧长度为500,根据上述参数设定,进行含噪字符的识别.
3.2 实验指标
通过对比本文方法,文献[3]方法和文献[4]方法的含噪字符识别精度、特征匹配的准确性以及识别用时,验证本文方法的有效性.
3.3 实验结果分析
3.3.1 不同方法识别精度分析为了验证本文方法的可靠性,在相同实验环境下对比3种方法对实验室局域网含噪字符图像识别精度,对比结果如表1所示.

表1 不同方法含噪字符图像识别精度对比Tab.1 Comparison of recognition accuracy of noisy character image by different methods
分析表1中数据,可以看出,在不同的迭代次数情况下,不同方法的含噪字符图像识别精度有所差异.当迭代次数为100时,本文方法的识别精度为93.4%,文献[3]方法的识别精度为84.3%,文献[4]方识别精度为85.6%;当迭代次数为300时,本文方法的识别精度为98.5%,文献[3]方法的识别精度为93.6%,文献[4]方法识别精度为96.5%;可以看出本文方法的最高识别精度可达98.6%,文献[3]方法的识别精度最高为94.3%,文献[4]方法识别精度最高为96.5%,本文方法的识别精度高于其他2种方法.这是由于本文方法采用大数据融合分析方法,建立含噪字符图像局部模糊特征检测模型等,对含噪字符进行识别,进而提高了本文方法的识别精度,证明本文方法具有一定的可靠性.
3.3.2 不同方法含噪字符图像识别效果分析为了验证本文方法在含噪字符图像识别效果的优势,采用3种方法对含噪字符图像进行识别用时的对比,实验结果如图1所示.

图1 不同方法特征匹配准确度对比Fig.1 Comparison of feature matching accuracy by different methods
分析图1可以看出,采用3种方法进行含噪字符图像特征匹配的准确度有所差异.随着匹配次数的增加,3种方法的匹配准确度也随之提高.当匹配次数为4时,本文方法的准确度约为87%,文献[3]方法的准确度约为72%,文献[4]方法的准确度约为65%;当匹配次数为10时,本文方法的准确度约为98%,文献[3]方法的准确度约为90%,文献[4]方法的准确度约为85%.可以看出本文方法在进行含噪字符图像特征匹配的准确度最高,这是由于本文方法对含噪字符图像字符串的分布进行特征匹配,融合图像边缘区域信息等,实现了含噪字符图像的特征匹配,从而提高了本文方法的特征匹配能力.
3.3.3 不同方法识别用时分析为了验证本文所提方法的可行性,实验对比3种方法在含噪字符图像识别的用时,实验结果如图2所示.
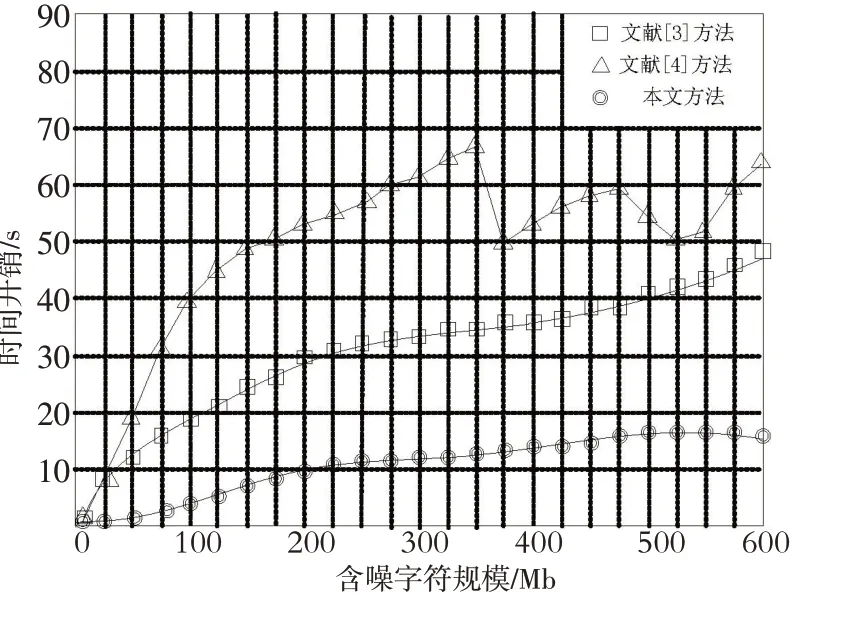
图2 不同方法含噪字符识别用时对比Fig.2 Time comparison of noisy character reagnition by different methods
分析图2可以看出,在相同的含噪字符规模下,3种方法的识别用时不相同.其中,本文方法的识别用时较低,其次为文献[3]方法和文献[4]方法.本文方法的识别用时最大约为18 s,文献[3]方法的识别用时最大约为50 s;文献[4]方法的识别用时最大约为69 s.这是由于所提方法对含噪字符图像局部模糊区域像素特征点进行重构,构建含噪字符图像特征识别模型,通过识别模型直接对其进行识别,进而缩短了识别的用时,验证了本文方法的工作效率较高,具有一定的可行性.
4 结束语
本文提出的基于大数据的实验室局域网含噪字符识别方法研究,通过分析实验室局域网含噪字符图像的特征,将此特征进行重建、提取等,实现了基于大数据的含噪字符的识别.实验结果表明,采用本文多提方法对含噪字符进行识别的精度较高,特征匹配的准确度最高可达98%,在识别过程中识别用时均小于20 s,在现实的应用中具有一定意义.
猜你喜欢
科海故事博览·下旬刊(2022年4期)2022-05-07
电脑知识与技术(2019年29期)2019-12-16
小学生学习指导(低年级)(2019年12期)2019-12-04
电脑爱好者(2019年8期)2019-10-30
电子制作(2019年16期)2019-09-27
魅力中国(2017年15期)2017-09-16
价值工程(2016年32期)2016-12-20
考试周刊(2016年34期)2016-05-28
中小企业管理与科技·中旬刊(2014年10期)2015-02-03
农机使用与维修(2014年10期)2014-10-23
