
基于卷积神经网络和支持向量机的事件相关电位识别方法
2021-12-03 03:15于鸿伟谢俊何柳诗杨育喆张焕卿徐光华
西安交通大学学报 2021年12期
于鸿伟,谢俊,何柳诗,杨育喆,张焕卿,徐光华
(西安交通大学机械工程学院,710049,西安)
脑机接口(BCI)是一种不借助外周神经通路而使大脑与外界直接交互的技术[1]。基于脑电信号的脑机接口应用可以采用多种脑电形式,包括稳态视觉诱发电位(SSVEP)和事件相关电位(ERP)等[2]。ERP是由一系列的特定刺激诱发的瞬态大脑响应,反应了大脑对物理刺激的加工机制。ERP主要由易受刺激物理特性影响的外源性成分如P1、N1、P2等,和不易受刺激物理特性影响的内源性成分如N2、P3(或称P300)等组成。目前研究最多、最广泛的是P300电位[3],对于ERP的检测也大多是检测其是否包含P300成分。但是,ERP信号具有个体差异性强、信噪比低等特点,导致其检测困难[4]。
预处理、特征提取和识别分类是ERP脑电信号处理的重要内容,并得到了广泛深入的研究[5]。传统的ERP信号处理一般通过手动提取脑电信号中的频域或时频域特征信息,然后对提取到的特征进行有监督分类的方式来实现[6]。为了准确判断脑电信号中是否含有P300成分,研究者们已经提出多种方法,如独立分量分析(ICA)、支持向量机(SVM)、逐步线性判别分析(SWLDA)、贝叶斯线性判别分析(BLDA)、xDAWN等算法。文献[7]利用ICA对叠加后的脑电信号进行去平均和白化处理,从而达到快速提取P300成分的目的,但是该方法需要对多次视觉刺激下的脑电信号进行平均处理,因而限制了其实用性。文献[8]利用SVM算法对第二届国际BCI竞赛公开数据集中的Data Set IIb数据集进行分类,该方法虽然可以用低通道数和高传输速率完成分类,但是分类准确率有待提升。文献[9]显示SWLDA算法在基于P300特征的BCI中得到了成功的应用。文献[10]利用BLDA算法对第三届国际BCI竞赛公开数据集中的Data Set IIb数据集进行分类并获得了较高的准确率。SWLDA和BLDA算法相比非线性分类方法具有较低的计算复杂度和不易过拟合的优点,但两个算法都需要手动对数据进行预处理和特征提取,并且预处理和特征提取的好坏直接影响最终的分类效果。xDAWN是针对时间锁定、相位锁定的ERP信号的特征提取算法,多与其他的分类算法配合使用[11],文献[12]显示xDAWN算法能够提升线性判别分析(LDA)等分类算法对于ERP信号的分类性能,然而该算法只考虑了ERP信号的空域信息,没有考虑时域内的信息。
相对于传统的特征提取方法,深度学习可以自动挖掘信号更深层次的特征,能够避免信息丢失,目前已广泛应用于脑机接口的分类辨识中[13]。文献[14]首次把卷积神经网络(CNN)应用到P300信号的检测中,并且取得了较高准确率。基于该研究,文献[15]在训练中引入批量标准化方法,进一步提高了网络对P300信号的识别正确率。上述研究表明,CNN算法可以在ERP脑电信号识别分类中取得较好的效果,但是由于ERP脑电信号具有个体差异性强、信噪比低,以及脑电数据量往往过少等特点,CNN算法往往会出现过拟合现象,目前应用于脑电信号识别的CNN算法均面临这个问题。
为了解决因ERP信号单次信噪比低,个体差异性大,一般需要多次叠加以增强信噪比才能实现瞬态电位有效辨识以及使用CNN对小样本脑电分类易产生过拟合等问题。本文使用深度学习中的经典算法,即CNN算法,并将SVM融入算法模型中,通过引入深度学习的模型优化技术,提出适于脑电信号的CNN-SVM深度卷积神经网络模型。模型直接作用于滤波后的原始脑电信号[16],自适应地从原始数据中逐层学习信号特征,并结合具有结构风险最小化的SVM算法实现不同信号的精细化识别。最终分类结果表明本文所提出的组合分类器方法对ERP信号分类的准确率有明显的提升。
1 CNN与SVM相结合的混合模型
考虑到脑电信号是一种非平稳信号,其个体差异性较大,再者对于ERP信号在单次实验中与背景脑电信号存在较小差异的特点,这些因素的存在都给ERP信号的有效分类带来了困难。现已知CNN中的卷积和池化等操作相当于对信号进行了特征工程,之后将提取到的特征送到全连接层进行分类。全连接层类似于多层感知机,而多层感知机对于线性可分的数据集来说,存在无穷多个超平面,其优化目标是经验风险最小化,这势必会导致分类的泛化能力较差。SVM的超平面是距离各个类别样本点最远的平面[17],SVM与多层感知机最大的不同在于其不仅关注训练的误差,还关注期望的损失,是一种使结构风险最小化的分类算法,其泛化能力势必会比以经验风险最小化的多层感知器强。因此,针对ERP信号的特点,以及CNN和SVM各自的分类优势,本文提出一种CNN结合SVM的脑电信号辨识算法,具体为首先通过先时域后空域卷积的时空分离卷积的CNN结构来对ERP信号进行识别,然后将自动识别到的特征送入到SVM进行分类,以实现对ERP微弱脑电信号更加准确的辨识效果。ERP信号辨识流程如图1所示。
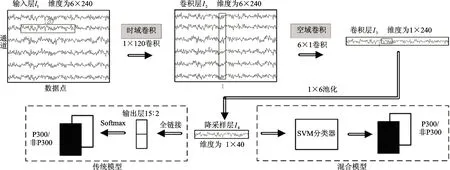
图1 包含对照算法和混合模型算法的ERP信号辨识流程
1.1 传统CNN模型
CNN由输入层、卷积层、池化层、全连接层和输出层组成[18]。通过增加卷积层和池化层,还可以得到更深层次的网络,其后的全连接层也可以采用多层结构。通常CNN可以看成由两部分组成,一部分是由输入层、卷积层、池化层组成的特征提取器;另一部分是由全连接层和输出层组成的分类器。在本文中,这种传统CNN模型作为对照算法来对相同数据集进行分类。
CNN中的卷积操作可以看作是输入样本和卷积核的内积运算
(1)
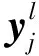
池化层一般在卷积层之后使用,它通过池化操作对输入的特征向量进行降采样,在实现数据降维的同时进一步突出提取的特征。池化操作通常分为两种:最大池化和平均池化,池化操作的表达式如下
(2)
式中,down(·)代表池化函数。
全连接层中的每个神经元都与池化层的所有神经元相连接,负责降低池化层的矩阵数据维数,处理有鉴别能力的特征,故其作用是对特征样本进行分类。全连接层的表达式如下
xl=f(αlxl-1+kl)
(3)
式中:xl、αl、kl表示全连接层第l层的输出向量、权重矩阵和偏移向量。
1.2 CNN与SVM混合模型结构
针对ERP原始信号兼具时、频、空域特征的特点,本文设计了一种先时域后空域卷积的时空分离卷积CNN结构,将其与SVM结合来对ERP信号进行识别。本文采用的CNN网络结构如图1所示,整个网络由5层网络组成:第1层为输入层,输入滤波后的原始多通道ERP信号,具体输入样本矩阵大小为6×240,表示输入数据为6个通道,240个采样点,即采样率为240 Hz下的1 s数据;第2层、第3层为卷积层,卷积层l2有6个一维卷积核,主要用来对输入的ERP信号进行时域滤波,卷积层l3有12个一维卷积核,主要用来对上一层的输出进行空域卷积;第4层为降采样层,降采样层l4采用12个大小为1×6的卷积核对l3层的输出进行降采样处理,降采样采用平均池化方法,步长与卷积核大小一致,同时使用Dropout方法防止过拟合;第5层为输出层,此处采用SVM分类器来解决对应于P300信号和非P300信号的二分类问题,分类算法采用一对一分类算法中的投票法,其核函数采用径向基核函数,C和Γ采用网格化搜索的方法来获取其最优值。
1.3 识别流程
在采用传统CNN模型作为对照算法对相同数据集进行分类对比的过程中,首先对ERP信号进行滤波处理。由于脑电信号的频率范围主要集中在0.5~30.0 Hz之间,因此可以采用0.1~20.0 Hz的带通滤波器对脑电信号进行滤波,仅保留有效的频率成分。ERP信号经过滤波后,送入CNN模型进行训练,在卷积层利用卷积核对数据的特征进行提取,之后通过降采样层压缩数据和参数量来减小过拟合。数据经过处理后,获得了信息含量更高的特征。最后,利用Softmax函数计算最后输出被分到每个类的概率,实现对ERP信号的辨识。
基于CNN对照算法的ERP信号辨识流程分为以下2个步骤:
(1)先用0.1~20.0 Hz的带通滤波器对脑电数据进行滤波,之后为P300数据和非P300数据组成的多通道数据集制作标签,并使用留出法将数据集随机划分,其中数据集的70%为训练集,15%为验证集,15%为测试集;
(2)进行模型训练,将训练数据和验证数据输入模型,得到训练好的CNN模型,然后实现对测试集数据的分类,得到P300信号识别结果。
本文提出的CNN-SVM组合分类器是在训练好的传统CNN模型的基础上,再次将滤波后的ERP信号送入到CNN中,并返回降采样层相应的特征值,将特征值送入到SVM中实现SVM分类器的训练,由此得到的CNN-SVM混合模型分类准确率相比传统CNN模型有着较大的提升。基于CNN-SVM组合分类器的ERP信号辨识流程分为以下5个步骤:
(1)先用0.1~20.0 Hz的带通滤波器对脑电数据进行滤波,之后为P300数据和非P300数据组成的多通道数据集制作标签,并使用留出法将数据集随机划分,其中数据集的70%为训练集,15%为验证集,15%为测试集;
(2)进行模型训练,将训练数据和验证数据输入模型,得到训练好的CNN模型;
(3)将全部数据集送入CNN模型中,导出降采样层的特征,将步骤1中70%的训练集和15%的验证集导出的特征作为训练特征,步骤1中15%的测试集导出的特征作为测试特征;
(4)SVM的核函数采用径向基核函数,C和Γ采用网格化搜索获取其最优值,用以训练SVM模型;
(5)将训练好的CNN-SVM模型用来对测试特征进行分类,得到P300信号识别结果。
由于脑电信号的样本数量较小,使用留出法训练模型会损失一定的样本信息。故本文对数据集进行了10次随机划分,重复进行实验后取平均值作为最终评估结果。
CNN-SVM组合分类器算法具体识别流程如图2所示。
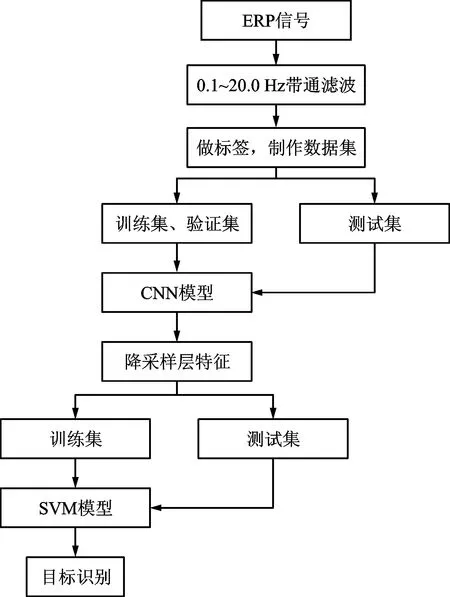
图2 混合模型识别流程
2 P300标准数据集
P300信号首先由Sutton提出[19]。P300信号指在一个小概率刺激后大约300 ms的潜伏期内出现的脑电幅值正偏移,如图3所示。P300检测属于二元分类问题:一类对应于一定时间范围内的P300信号;另一类对应于非P300时间段内的信号。
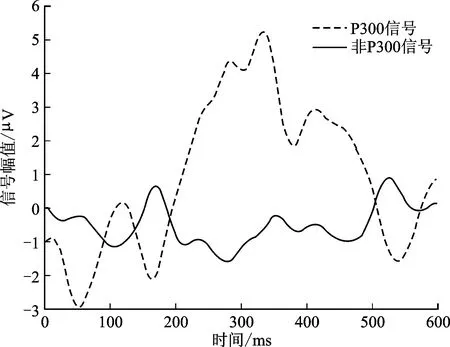
图3 P300和非P300信号
图4为P300字符拼写矩阵[20],它是由Farwell和Donchin在1988年提出并设计的P300拼写器,由26个英文字母和9个数字以及下划线排列组合成的字符矩阵。随机高亮字符矩阵的某一行或某一列代表一次刺激,一次实验中6行及6列均被高亮一次,总共12次刺激。当包括此字符的行或者列被高亮时,要求受试者对此刺激做出反应,此时会产生P300波形;当不包含此字符的行或者列被高亮时,受试者不做出反应,相应不产生P300波形。

图4 P300字符拼写矩阵[20]
本文使用了3个公开数据集,即第二届国际BCI竞赛公开数据集中的data set IIb[21]和第三届国际BCI竞赛公开数据集中的data set II的受试者A和B的数据集[26]。这3个数据集是由美国的Wadsworth中心提供,记录于BCI2000通用平台,数据采集于图4中的P300拼写器进行的实验,脑电信号采集于64个脑电电极,采样率为240 Hz。实验过程中字符矩阵的每一行和每一列高亮状态的持续时间为100 ms,随后有75 ms的间歇期,每个字符都会闪烁15次,在15次闪烁之后,会有2.5 s的休息时间,以通知受试者这个字符已经拼写完成,并将注意力集中于下一个字符,具体的实验流程如图5所示。
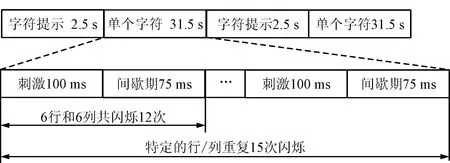
图5 实验流程图
表1显示了3个数据集包含的P300/非P300信号的数量。Ⅱ代表第二届国际BCI竞赛公开数据集中的data set II,III-A代表第三届国际BCI竞赛公开数据集中data set II的受试者A的数据集,III-B代表受试者B的数据集。Ⅱ数据集中有42个字符。每个字符由12组信号样本组成,其中2组默认含有P300信号,10组默认不含有P300信号。因此,Ⅱ数据集有42×15×2=1 260组标签为“P300信号”的样本,有42×15×10=6 300组标签为“非P300信号”的样本。Ⅲ-A和Ⅲ-B数据集都包含85个字符,所以它们都包含有85×15×2=2 550组标签为“P300信号”的样本,有85×15×10=12 750组标签为“非P300信号”的样本。

表1 每个数据集的P300/非P300信号的数量
根据国际标准10/20系统法,本研究采用的是视觉区和顶区的FCz、C1、Cz、C2、Pz和POz共6个通道的脑电信号。数据大小为6×240,代表6个通道持续采集1 s的数据量。
3 辨识结果
3.1 P300/非P300识别准确性
在CNN-SVM组合分类器的训练阶段,对每个数据集进行单独训练,输入样本矩阵大小为6×240。网络的搭建、训练与测试使用Keras深度学习框架,实验硬件平台具体为:CPU型号为Intel(R)Core(TM)i5-7500 CPU@3.40 GHz,内存容量为16 GB,GPU型号为AMD Radeon R5430。
图6为利用本文提出的混合模型计算出的Ⅲ-A的P300信号识别准确率的混淆矩阵,其中图中的行表示预测标签,列表示实际判别结果标签。由图6可以看出,本文提出的CNN-SVM组合分类器算法对P300信号的分类准确率为93.5%,对非P300信号的分类准确率为94.3%,两类信号的识别率均超过了90%,说明CNN-SVM组合分类器能够较好地完成两类信号的分类。
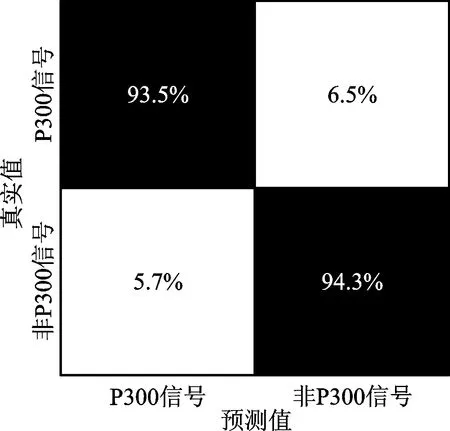
图6 P300信号识别准确率混淆矩阵
此外,为了验证CNN-SVM组合分类器的有效性,本节将CNN-SVM组合分类器与SWLDA和BLDA算法在数据集Ⅱ、III-A和III-B上获得的分类精度进行了比较,结果见表2。表中的第1行列出了用于比较的分类算法,第2~4行分别列出了在数据集Ⅱ、III-A、III-B上不同分类算法的P300分类精度。

表2 不同分类算法的P300分类精度
由表2可以看出,本文提出的CNN-SVM组合分类器在数据集Ⅱ、III-A和III-B上的所有分类算法中的分类精度最高。由于组合分类器使用CNN作为特征提取器,相比手动提取脑电信号中的频域或时频域特征信息,其能够自动挖掘信号更深层次的特征,避免信息丢失,组合分类器的分类结果也显著优于本文列举其他的分类算法。以上结果说明CNN-SVM组合分类器的分类精度相比于经典的ERP信号识别算法有了较大的提升。
3.2 不同重复次数下的P300检测精度
对CNN-SVM组合分类器和传统CNN算法在数据集II、III-A和III-B上的P300检测精度进行了比较,如图7~图9所示。由于在使用较少的重复次数的基础上实现检测精度的提升将有利于提高信息传输率[22],从而能够提高人脑和计算机之间的通信速度,因此本研究分析了不同重复次数k∈[1,15]下的P300检测精度。总体来说,CNN-SVM组合分类器比传统CNN算法能够获得更好的识别精度,CNN-SVM组合分类器的识别准确率相比单一CNN算法提高了4.36%。这是因为多层感知机是一种经验风险最小化的算法,在小样本上分类容易带来过拟合现象,而SVM是一种结构风险最小化的分类算法,其泛化性能相比于多层感知机势必会有所提高。对于数据集II、III-A和III-B,该组合分类器只需要重复4次字符闪烁就可以稳定达到90%以上的检测精度,具有较高的实用价值。
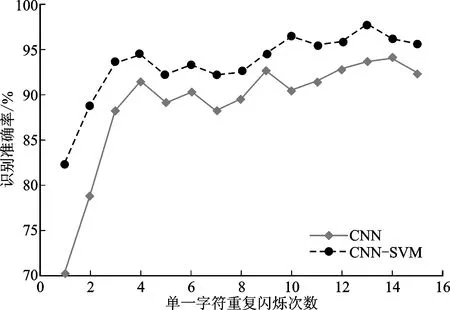
图7 2种方法在数据集II上的P300检测精度

图8 2种方法在数据集III-A上的P300检测精度
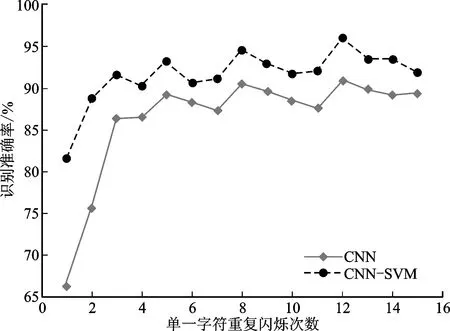
图9 2种方法在数据集III-B上的P300检测精度
4 结 论
针对ERP脑电信号存在个体差异性强、信噪比低等特点而导致其识别困难,以及传统的CNN算法对小样本脑电信号分类易产生过拟合等问题,本文在CNN和SVM融合模型的基础上提出了一种用于ERP信号分类识别的CNN-SVM组合分类器。该组合分类器不需要人工提取脑电信号的特征就能从滤波后的原始ERP信号中学习特征,最后采用结构风险最小化的SVM进行分类识别,有效减小了过拟合。实验结果表明,CNN-SVM组合分类器对于P300信号的识别准确率要明显高于SWLDA、BLDA和传统的CNN方法。在重复4次以上刺激后,该组合分类器的平均识别准确率在90%以上,表明该组合分类器能够实现ERP信号的精确识别,提高了脑机接口系统的实用价值。后续将通过改进神经网络结构,采用主动学习和最优停止等方法,对该组合分类器的泛化性能做进一步深入研究,以期提高该组合分类器在不同受试者之间的泛化能力。
猜你喜欢
农业工程学报(2022年12期)2022-09-09
现代电子技术(2022年15期)2022-07-28
电子产品世界(2022年4期)2022-04-21
计算机仿真(2021年11期)2021-12-10
科学与生活(2021年11期)2021-11-10
北京航空航天大学学报(2021年9期)2021-11-02
北京航空航天大学学报(2021年9期)2021-11-02
计算机系统应用(2021年9期)2021-10-11
计算机系统应用(2021年2期)2021-02-23
科技传播(2019年24期)2019-06-15
