
造纸企业多源数据融合算法与生产物流智能调度研究
2022-01-22 10:34张海涛,唐美玲,刘锋,朱定欢
计算机时代 2022年1期
关键词:数据融合
张海涛,唐美玲,刘锋,朱定欢


摘 要: 为了有效地提高造纸企业智能调度的性能和效率,结合人工智能深度学习方法,针对造纸企业传感器数据融合探测、诊断决策和装载机调度等任务建立数据融合网络模型,提取数据的关联性特征,提高数据融合的精度和效率,并在此基础上开展生产物流智能调度研究。
关键词: 造纸企业; 数据融合; 生产物流; 智能调度
中图分类号:TP391 文献标识码:A 文章编号:1006-8228(2022)01-05-03
Research on multi-source data fusion algorithm and production logistics
intelligent scheduling in papermaking enterprises
Zhang Haitao, Tang Meiling, Liu Feng, Zhu Dinghuan
(College of Science, Hunan University of Technology, Zhuzhou, Hunan 412000, China)
Abstract: In order to improve the performance and efficiency of intelligent scheduling in papermaking enterprises effectively, in this paper, combined with the deep learning method of artificial intelligence, establishes a data fusion network model for the tasks of sensor data fusion detection, diagnosis decision and loader scheduling in paper enterprises, extracts the correlation characteristics of data, improves the accuracy and efficiency of data fusion, and carries out the research on intelligent scheduling of production logistics on this basis.
Key words: papermaking enterprises; data fusion; production logistics; intelligent scheduling
0 引言
造紙企业生产物流是指从企业的原材料、外购件入库,到企业成品库的成品发送这一全过程的管理活动。它贯穿于原材料和协作件的采购供应,到生产过程中半成品的存储、装卸、运输和成品包装,到仓储部门的入库验收、分类、储存、配送,最后送到客户手中的全过程,以及贯穿于整个生产过程的信息传递,其数据来源及数据量非常繁杂。
造纸企业具有规模大、设备多、覆盖区域广、运行时间长、运行条件复杂等特性,包含了木料接收、原木剥皮、原木削片、木片筛选、洗涤、磨浆、漂白和打包等环节,在这个过程中会产生大量类型丰富的数据。近年来,随着计算机信息技术和存储技术的快速发展,基于大数据的融合挖掘技术日益成熟,数据的价值渐渐被人们发现并利用,许多行业进入大数据时代,开启了重大的时代转型。数据融合指的是从数据中获取或挖掘出有用隐含信息并进行集成的过程,涉及数据库、统计分析、机器学习等技术[1]。传统的数据统计技术已无法满足海量多源的数据处理需求,更不能挖掘融合大数据中深层次的特征。而随着人工智能的发展,数据挖掘技术日渐成熟,效率显著提高,在海量多源数据中提取针对于目标任务的特征成为可能[2]。造纸过程产生的数据完全符合大数据的特征。
本文从传感器数据融合、诊断决策和装载机调度等主要数据融合任务入手,从原理上设计了多个数据融合模型。通过制浆造纸企业真实数据实验验证,本研究提出的方法能有效地提高企业生产智能调度的性能和效率,是造纸企业在创新发展过程中迫切需要解决的关键科技问题。
1 造纸企业多源数据融合算法
1.1 传感器数据融合探测网络模型
针对生产现场温度、噪度、压力、浆浓度等传感器探测异常数据纠缠稀薄、传统神经网络易陷入局部最小、梯度消失爆炸问题,利用SSEAE对数据进行无监督学习,提取高维稀疏特征,并引入PCA对特征进行压缩降维,利用高斯核SVM分类器进行最后的数据判别[1]。其具体前馈公式如⑴-⑷所示,其中[ni]为第[i]层的隐藏单元数,[n0]代表输入层单元数,[T]是隐藏层单元的加权和输入,[U]是隐藏层单元值。可以看出,每一层的自编码器都是前面一层的更高维非线性表示,这些非线性高维特征中总有一个维度会更适合于最后的分类决策,为引入PCA和SVM提供了可能[2]。
[T1=t11X,t12X,…,t1n1X]
[=i=0n0v11ixi,i=1n0v12ixi,…,i=1n0v1n1ixi] ⑴
[U1=u11X,u12X,…,u1n1X]
[=ft11X,ft12X,…,ft1n1X]
[=fi=1n0v11ixi, fi=1n0v12ixi,…, fi=1n0v1n1ixi] ⑵
[U2=fj=1n1v21jfi=1n0v11ixi, fj=1n1v22jfi=1n0v12ixi,…, fj=1n1v2n2jfi=1n0v1n1ixi] ⑶
[Uk=fl=1nk-1vk1l…(fj=1n1v21jfi=1n0v11ixi,fl=1nk-1vk2l…fj=1n1v22jfi=1n0v12ixi,…,fl=1nk-1vknkl…fj=1n1v2n2jfi=1n0v1n1ixi] ⑷
1.2 装载机智能调度预测网络模型
针对多源传感器大数据融合模型,结合装载机调度负荷预测综合影响因素、用户所需浆纸特性、网络参数、环境特性和收敛速度等方面,本文提出基于GRU网络的装载机智能调度预测网络数学模型,利用聚类分析算法减轻不同用户浆包需求的干扰,并且对辅助环境信息进行量化,把历史需求数据作为网络的总输入,挖掘出需求预测与多源信息的综合深层关系[3]。具体算法如下。
[atu=i=1Iwiuxti+h=1Hwhust-1h] ⑸
[stu=fatu] ⑹
[atr=i=1Iwirxti+h=1Hwhrst-1h] ⑺
[str=fatr] ⑻
[ath'=strh=1Hwhh'st-1h+i=1Iwih'xti] ⑼
[sth'=φath'] ⑽
[sth=1-stusth'+stust-1h] ⑾
其中[u]是更新门向量的下标,[r]是重置门向量的下标,[h]是[t]时刻隐藏单元向量的下标,[h’]是[t]时刻新记忆单元的下标,[f]和[φ]是激活函数,[sth’]表示在[t]时刻新记忆单元的信息。
为了解决样本获取问题,进一步提高数据利用率和网络性能,利用MMD衡量源領域和目标领域数据的分布差异[4],从而根据MMD的值选择和调整迁移学习网络模型,将源领域有价值的知识迁移到目标领域,防止负迁移现象的发生,并运用大数据处理技术,最终实现制浆造纸过程数据处理科学化。
假设[F]是一个在样本空间上的连续函数集,那么MMD可以表示为:
[MMD[F,p,q]=sup(Ep[fx]-Ep[fy])] ⑿
假设[X]和[Y]是从分布[p]和[q]采样得到的两个数据集,数据集的大小分布为[m]和[n],那么MMD的经验估计为:
[MMDF,X,Y=sup1mi=1mfxi-1ni=1nfyi] ⒀
总的来说,MMD可以看作是在再生核希尔伯特空间中两个点的距离,可以用来衡量两个分布的距离[5]。
[MMD[F,X,Y]=[1mm-1i≠jmkxi,xj]
[+1nn-1i≠jnkyi,yj-2mni,j=1m,nkxi,yi]12] ⒁
2 实验结果与分析
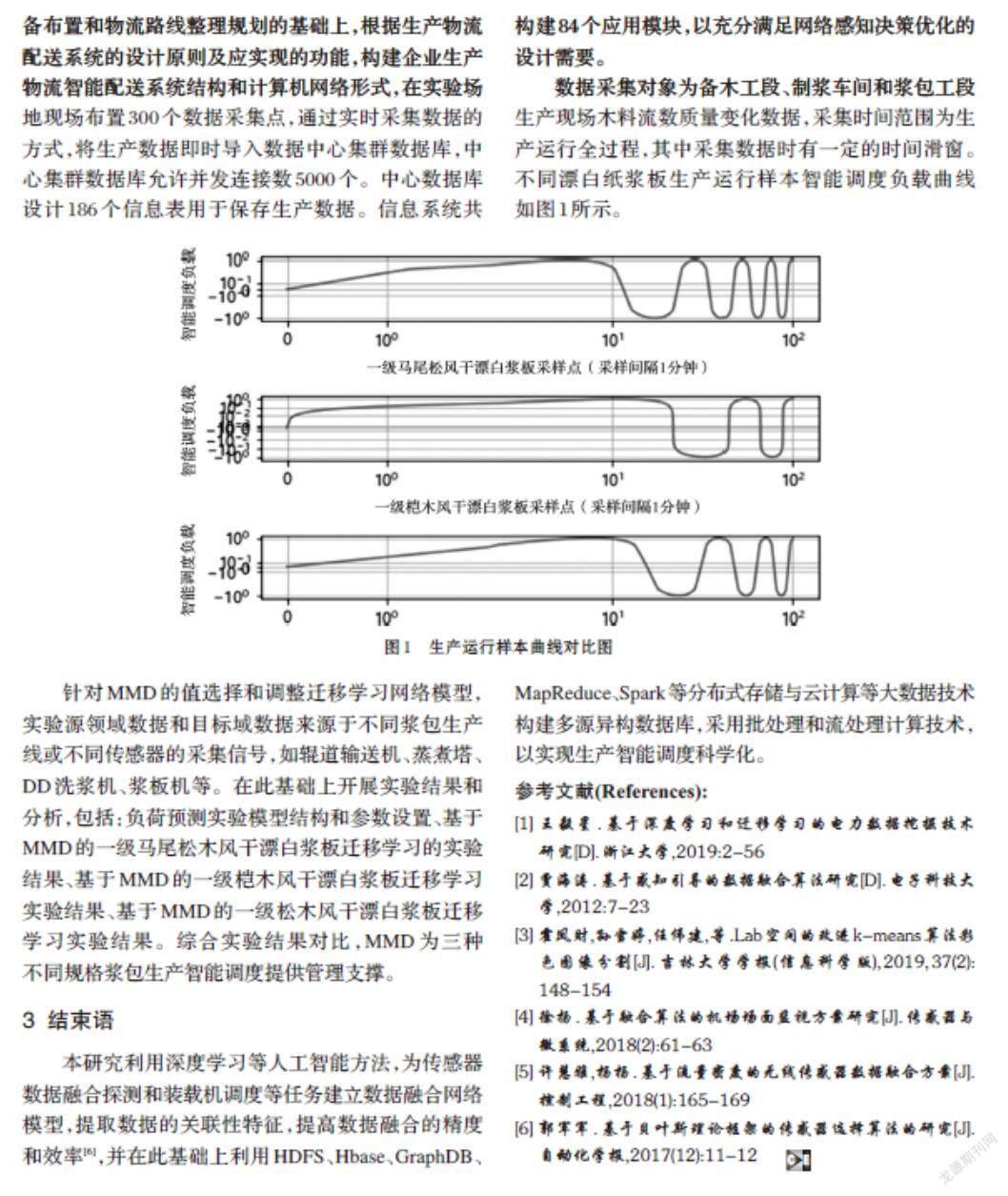
针对现代生产物流系统结构,对造纸企业生产设备布置和物流路线整理规划的基础上,根据生产物流配送系统的设计原则及应实现的功能,构建企业生产物流智能配送系统结构和计算机网络形式,在实验场地现场布置300个数据采集点,通过实时采集数据的方式,将生产数据即时导入数据中心集群数据库,中心集群数据库允许并发连接数5000个。中心数据库设计186个信息表用于保存生产数据。信息系统共构建84个应用模块,以充分满足网络感知决策优化的设计需要。
数据采集对象为备木工段、制浆车间和浆包工段生产现场木料流数质量变化数据,采集时间范围为生产运行全过程,其中采集数据时有一定的时间滑窗。不同漂白纸浆板生产运行样本智能调度负载曲线如图1所示。
针对MMD的值选择和调整迁移学习网络模型,实验源领域数据和目标域数据来源于不同浆包生产线或不同传感器的采集信号,如辊道输送机、蒸煮塔、DD洗浆机、浆板机等。在此基础上开展实验结果和分析,包括:负荷预测实验模型结构和参数设置、基于MMD的一级马尾松木风干漂白浆板迁移学习的实验结果、基于MMD的一级桤木风干漂白浆板迁移学习实验结果、基于MMD的一级松木风干漂白浆板迁移学习实验结果。综合实验结果对比,MMD为三种不同规格浆包生产智能调度提供管理支撑。
3 结束语
本研究利用深度学习等人工智能方法,为传感器数据融合探测和装载机调度等任务建立数据融合网络模型,提取数据的关联性特征,提高数据融合的精度和效率[6],并在此基础上利用HDFS、Hbase、GraphDB、MapReduce、Spark等分布式存储与云计算等大数据技术构建多源异构数据库,采用批处理和流处理计算技术,以实现生产智能调度科学化。
参考文献(References):
[1] 王毅星.基于深度学习和迁移学习的电力数据挖掘技术研究[D].浙江大学,2019:2-56
[2] 贾海涛.基于感知引导的数据融合算法研究[D].电子科技大学,2012:7-23
[3] 霍凤财,孙雪婷,任伟建,等.Lab空间的改进k-means算法彩色图像分割[J].吉林大学学报(信息科学版),2019,37(2):148-154
[4] 徐扬.基于融合算法的机场场面监视方案研究[J].传感器与微系统,2018(2):61-63
[5] 许慧雅,杨杨.基于流量密度的无线传感器数据融合方案[J].控制工程,2018(1):165-169
[6] 郭军军.基于贝叶斯理论框架的传感器选择算法的研究[J].自动化学报,2017(12):11-12
猜你喜欢
现代电子技术(2016年24期)2017-01-19
东方教育(2016年10期)2017-01-16
电子技术与软件工程(2016年22期)2016-12-26
科技视界(2016年14期)2016-06-08
科技视界(2016年3期)2016-02-26
物联网技术(2015年11期)2015-11-26
物联网技术(2015年11期)2015-11-26
物联网技术(2015年8期)2015-09-14
物联网技术(2015年5期)2015-07-18
物联网技术(2015年4期)2015-04-27
