
基于自监督聚类算法的小样本医学图像分类
2022-03-12 18:19马修玉何良华
电脑知识与技术 2022年3期
关键词:深度学习
马修玉 何良华






摘要:基于深度学习的医学图像分析是智慧医疗的一个重要方向。但是通常情况下,医学图像数据集数据量很小,而且由于医学图像的标注困难,耗费大量人力物力,所以带标签的训练数据很难获取。如何使用极少的带标签数据和无标签的数据得到一个较好的网络模型是本文的主要研究内容。该文提出基于深度聚类的自监督网络模型作为特征提取器,并且使用标签传播算法对特征进行分类,解决了只有极少量标签(例如1张,5张或者10张)即小样本情况下的医学图像分类问题,在BreakHis数据集上取得了比传统机器学习算法更好的效果,并且接近于全监督学习方法。
关键词:深度学习;深度聚类;自监督学习;小样本学习;标签传播算法;医学图像分类
中图分类号:TP311 文献标识码:A
文章编号:1009-3044(2022)03-0078-03
开放科学(资源服务)标识码(OSID):
1 概述
深度学习算法,尤其是卷积神经网络在医学图像分析领域的广泛使用使得诊断的准确性有了很大提升。虽然基于深度学习的方法能在这些任务上取得比传统机器学习方法更好的效果,但是这些方法通常都需要大量已标注的数据集作为训练数据。因此如何在已标注样本很少的情况下(即小样本情况),利用仅有的已标注数据以及无标签数据解决医学图像分类成为一个很重要的问题。
最近,很多对标注数据需求量小或者不需要标注数据的方法受到人们关注,出现了很多无监督学习的方法,自监督学习就是其中最具代表性的一种。自监督学习的思想非常简单,就是输入的是无标注的数据,但是通过数据本身的结构或者特性,人为构造标签出来。有了标签之后,就可以类似监督学习一样进行训练。传统机器学习算法中,聚类算法是一种涉及数据点分组的机器学习技术,不需要数据标签,属于无监督学习算法的一种。结合两种思想本文主要做了以下工作:
1)提出基于深度聚类的自监督网络模型,利用无标签数据训练出较好的特征提取模型。
2)提出改进的标签传播算法,利用上述特征提取模型和有限的带标注样本进行分类,在BreakHis数据集上取得了很好的分类效果。
2 相关工作
2.1 自监督学习
自监督学习作为无监督学习方法的一个子集,可以从大规模未标记数据中学习一般图像和视频特征,而不使用任何人为标注标签。自监督学习的方法通常是设置一些前置任务(如图像上色、图像修补、图像拼接等),训练网络去解决前置任务,在完成这些任务的过程中,网络就学习到了相应的特征。
何凯明在2019年提出了MoCo(Momentum Contrast)[1], 使用动量的方式更新encoder参数,解决新旧候选样本编码不一致的问题;Chen Ting在2020年提出了SimCLR[2],在encoder之后增加了一个非线性映射
[ghi=W* ReLU (W* hi)]
效果直接比MoCo高出了7個点,并直逼监督模型的结果;何凯明在改进自己的方法加入相同的非线性层后提出MoCov2,效果反超SimCLR;近些年来人们开始把自监督学习用于医学图像分析,例如谷歌提出了大型自监督模型改进医学图像分类[3]。
2.2 深度聚类与标签传播
聚类的目标就是根据某一相似性度量准则,将相似的数据分到同一类,尽管人们提出了很多的聚类算法,但是这些方法在高维数据上表现得很差。由于深度学习的发展,以及神经网络内在的非线性变换的特点,深度神经网络可以将数据转化成更易于分类的特征表示,通常把使用深度学习的聚类方法称之为深度聚类(deep clustering)[4]。
标签传播算法[5]是一种基于图的半监督学习算法,它以一种迭代的方法通过带标注数据推测无标注数据的标签,其基本思路是用已标记节点的标签信息去预测未标记节点的标签信息,经常被用于社区发现。
2.3小样本学习
机器学习在数据密集型的领域取得了巨大的成功,但是在数据集比较小的时候通常效果更不太理想,最近人们提出了小样本学习来解决这个问题。基于度量学习的小样本学习方法比如MathingNet[6],ProtoNet[7]等都取得了不错的效果。
3 自监督聚类模型
3.1 自监督聚类模型
传统的自监督学习算法通常以大量的自然图像比如ImageNet,作为训练数据集,构造前置任务,模型能够在训练过程中学到底层的图像特征。自监督模型能够使用无标签数据进行训练,从而得到很好的特征提取器。传统的网络自监督训练以每一张图为一类,进行实例区分来训练网络。由于自然图像分类通常类别数量很大,无法利用类别信息,而医学图像分类任务通常类别已知(比如乳腺癌可以分为良性和恶性),因此可以设计基于聚类的自监督网络模型。
本文提出基于深度聚类算法的自监督网络模型,如图1所示。设计一个聚类队列,在模型训练的同时,以聚类算法更新队列,使模型不仅能学习区分不同实例,而且能学习同类别的相似性。网络采用两个分支,其中一个分支以动量方式更新参数,并且将输出用来更新聚类队列,同时设计一个队列存储C个类别的均值向量,在迭代训练过程中采用k-means算法不断地更新均值向量,具体步骤见算法1。自监督训练分支采用InfoNCE损失函数。
[LossNCE=-logexp (q∙k+ / T)i=0Kexp (q∙ki / T)]
[Loss=LossNCE+λ∙Losssim]
结合聚类损失函数得到最终损失函数([λ]为平衡因子):
算法1: 自监督聚类
输入:特征向量 [q, k]
输出:聚类队列[ q] , 训练损失 [Losssim]
开始 :
[for q, k in DataLoaer : ]
[j=argmax{ k ∙ avgi }Ni=1]
[enqueuej, k ]
[avgj= 1Kj i=1Kjkj, i]
[d=q∙avgj]
[Losssim+=Id>thresold*d]
[return Losssim]
结束
3.2 标签传播算法
标签传播算法的基本理论是:每个节点根据相似度将自己的标签传播给相邻的节点,对于传播的一个节点,它通过计算与周围节点的相似度,根据相似度大的节点的标签来更新附近的标签,最终相似度大的节点的标签都会被分为同一标签。本文先将输入的特征向量进行正则化,映射到球面空间,再进行标签传播,详细过程见算法2,其中[Xl= x1, y1 … xl, yl] 为已标注数据集,[Yl=y1, … , yl ∈{1 … C}] 为类别标签, 类别数量 [C] 已知,并且所有类别在已标注数据集中都有展示。[Xu= xl+1, yl+1 … xl+u, yl+u] 为未标注数据集,[Yu=yl+1, … , yl+u ∈{1 … C}] 为待预测数据,通常情况下,[l << u]。要解决的问题就是根据 [Xl] ,[Yl] ,[Xu] 预测 [Yu] ,具体算法步骤见算法2。
算法2: 标签传播
输入:特征向量矩阵 [X], 实标签矩阵[ Yl∈l × C] , 软标签矩阵 [Yu∈u × C] ,传播矩阵 [ T∈l+u × (l+u)]。
输出 : 标签矩阵 [Y ]。
步骤:
1. 正则化输入特征向量 : ; [xi= xixi]
2. 计算相似度权重矩阵: [wij=exp- dijσ2=exp (- d=1D(xdi - xdj) σ2)]
3. 计算标签[ j] 传播到标签 [i] 的概率 : [Tij= Pj →i= wijk=1l+uwkj]
4. 传播: [Y=cat(Yl, Yu)] [Yt= T × Yt-1]
5. 重置 [Y ]中已标记样本的标签: [Fl= Yl]
6. 重复步骤 4 和 5 直至 [Y] 收敛。
笔者将第一阶段训练好的模型作为特征提取器,将支撑集(support set, 有标签), 查询集(query set,无标签)同时送入模型作为输入,得到其在特征空间的映射,然后再将其归一化到球形特征空间,通过标签传播算法进行预测分类,整个流程如图2所示。
4 实验与结果分析
4.1 实验数据集
实验主要在BreakHis数据集上进行,BreakHis (Breast Cancer Histopathological Image) 包括82个病人,一共7909张乳腺癌病理图片。数据集包含了四种放大倍数(40x,100x, 200x, 400x)的显微图片,分为良性肿瘤,恶性肿瘤两个大类。
4.2 实验流程
本文主要以ResNet50 和 MoCo作为基线模型和提出的自监督聚类模型MoCo + simLoss 作为对比。本文实验基于Python3.7环境和PyTorch1.0框架,使用2块NVIDIA GEFORCE 2080Ti GPU进行训练和测试。所有实验的输入图像长寬固定为224,batchsize 设置为64,训练50 epoch,采用分类准确率来衡量算法的效果,数据增强方面则使用了随机水平翻转,随机 HSV 变化,随机缩放和随机剪切。优化算法采用动量为 0.9 随机梯度下降(SGD)。
4.3 实验结果
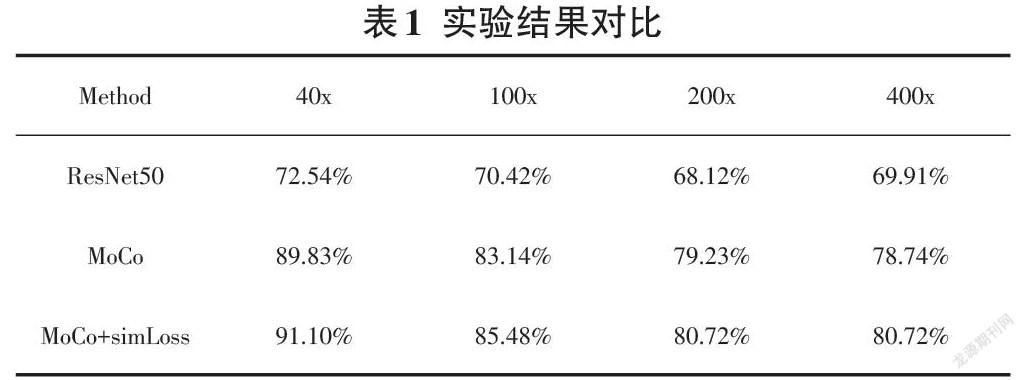
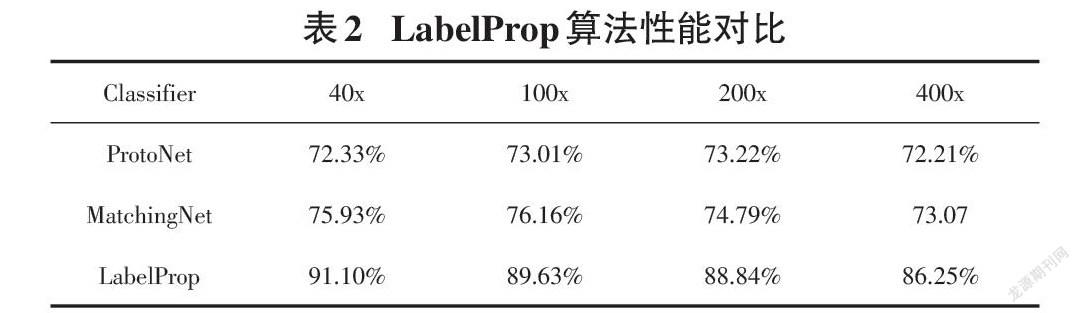
实验结果表1表明,基于MoCo的自监督网络模型比ResNet50预训练模型有很大的性能提升,说明自监督在医学图像特征提取任务上的有效性并且加入自监督聚类simLoss模块能有效提升模型的性能;表2 验证了标签传播算法的有效性,实验结果表明标签传播算法比基于欧式距离的ProtoNet 和基于余弦距离的MatchingNet效果要好很多。
最后与传统分类算法相比,实验结果表3表明模型在 5-shot 以及 10-shot 的情况下已经比传统算法有更好的分类效果, 并且随着每个类别的有标签样本的增多,模型分类效果越来越好。
5 总结
本文提出了基于自监督聚类算法的医学图像分类模型,通过对比和消融实验证明了本文提出的方法在小样本情况下的医学图像分类问题上比传统的机器学习算法和全监督算法具有更好的效果。
参考文献:
[1] He K, Fan H, Wu Y, et al. Momentum contrast for unsupervised visual representation learning[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2020: 9729-9738.
[2] Chen T, Kornblith S, Norouzi M, et al. A simple framework for contrastive learning of visual representations[C]//International conference on machine learning. PMLR, 2020:1597-1607.
[3] Azizi S, Mustafa B, Ryan F, et al. Big self-supervised models advance medical image classification[J]. arXiv preprint arXiv:2101.05224, 2021.
[4] Min E X,Guo X F,Liu Q,et al.A survey of clustering with deep learning:from the perspective of network architecture[J].IEEE Access,2018,6:39501-39514.
[5] Zhu X.Learning from Labeled and Unlabeled Data with Label Propagation[J]. Tech Report, 2002.
[6] Vinyals O, Blundell C, Lillicrap T, et al. Matching networks for one shot learning[J]. Advances in neural information processing systems, 2016,29: 3630-3638.
[7] Snell J, Swersky K, Zemel R S. Prototypical networks for few-shot learning[J]. arXiv preprint arXiv:1703.05175, 2017.
【通联编辑:梁书】
猜你喜欢
中国教育技术装备(2016年19期)2016-12-27
现代商贸工业(2016年25期)2016-12-26
江苏教育·中学教学版(2016年11期)2016-12-21
江苏教育·中学教学版(2016年11期)2016-12-21
现代情报(2016年10期)2016-12-15
考试周刊(2016年94期)2016-12-12
新教育时代·教师版(2016年23期)2016-12-06
法制与社会(2016年32期)2016-12-01
考试周刊(2016年64期)2016-09-22
