
基于语料库的同一后缀不同构词过程的形态生成能力研究
——以派生后缀“-ly”为例
2022-04-24 07:41李华剑邓耀臣
东北亚外语论坛 2022年2期
李华剑 邓耀臣
大连外国语大学英语学院 大 连 116044 中 国
一、引言
词缀生成能力一直是语言形态研究中的热门话题。不同的词缀基于构词规则能够不断的创造新的复杂单词,但是基于构词规则所产生的新词的数量变化很大。例如在英语中以“-th”结尾的单词(warmth)很少,而以“-ness”结尾的单词(goodness)却有成千上万,研究不同词缀的生成能力既可以了解不同词缀的构词能力的差异,也可以让我们从词汇层面观察语言的发展和变化趋势。
二、文献综述
词缀生成能力是语言形态研究中最热门和最具争议的话题之一。Plag (2003)将生成能力描述为词缀的固有属性即“用来创造新的复杂词汇”,关于词缀生成能力及其测量方法,在许多文献中提出了不同的观点和方法(Aronoff, 1976; Chitashvili & Baayen, 1993; Baayen & Renouf, 1996; Plag, 1999, 2004; Baayen, 1992, 1993,1994, 2001, 2009; Bauer, 2001; Gaeta & Ricca, 2003; Pustylnikov & Schneider-Wiejowski, 2009;among many others)。例如,Gaeta & Ricca(2003)选择了58个意大利语的派生后缀,将基于语料库和基于词典分别所得出的词缀生成能力数据进行了一个对比分析。这是因为在对意大利语的词缀相关研究中,频数尽管一直以来都被认为是评价词缀在构词过程中的生成能力可用的一个相关参数,但是很少有研究将其作为主要研究对象,此前的研究主要还是以词典为导向来评估词缀的生成能力。为此该研究基于自建的报纸语料库,对这58个派生后缀从频数和罕见词(Hapax/词频为1)这两个角度进行生成能力的评估,并将数据和之前的以词典为导向的数据进行全方面的对比,最终的研究发现表明,在词缀生成能力研究领域,基于语料库的数据整体更加可靠,因为它们避免了词典编撰过程中的一些缺点(例如词典有时出于全面性的考虑会保留一系列已经很少使用的古老的复杂形式,这会对以词典为导向的研究产生干扰),使用基于真实语料的大规模语料库往往能更全面准确的反映不同词缀的生成能力,这个研究结论同样也证实了Baayen的观点的合理性与可实践性。
Baayen 生成能力计量方式
在生成能力计量研究这方面,Baayen(2009)的生成能力计算方式是一个著名而复杂的衡量指标。他的基于语料库的定量估算形态生成能力的方法已经成为构词过程生成能力共时和历时研究的主要范式(Gaeta & Ricca, 2003; Plag, 1999,2006)。Baayen的目标是计算在语料库中由特定的形态过程生成新词的概率,他提出了估算形态生成能力的定量方法。Baayen(2009)基于语料库中的罕见词(hapax legomena),也即词频为1的词,提出了三个生成能力维度,即已实现生成能力(realized productivity)、潜在生成能力(potential productivity)和扩大生成能力(expanding productivity),每一个维度都探索了生成能力的一个方面:
已实现生成能力(realized productivity),下文简称为“RP”,计算在构词过程中不同的后缀已经产生的不同单词的数量,Baayen认为这种衡量方法“显示了过去的生成能力和该后缀的使用程度”。
已实现生成能力的计算公式为:
RP=某一后缀已经产生的不同单词的数量
潜在生成能力(potential productivity),下文简称为“PP”,所表明的是某一个类别(或词缀)的潜在生成能力,通过统计“语料库中只出现一次的形态类别的所有单词的数量,再用该数据除以这一类别(或词缀)所构建的单词的总数量(包含所有词频的单词而不仅仅是频率为1的罕见词)。Baayen认为hapax的数量可以显示一个词缀的生成能力,这一测量方法同时也是“在某一语料库或文本中遇到尚未观察到的单词类型的概率”。
潜在生成能力的计算公式为:

扩大生成能力(expanding productivity),下文简称为“EP”,它是用给定语料库中该形态类别的hapax数量除以语料库中hapax词的总数量,Baayen认为这一指标可以有效地“评估形态类别扩张和吸引新成员的速度”。同时也指出“这个比率是对所有词缀对词汇增长率的相对贡献的估计”。
扩大生成能力的计算公式为:

综上所述,这三个维度都探索了生成能力的一个方面,具有不同的功能,基于这三个维度可以对派生后缀的生成能力进行综合评估。使用这三个维度衡量生成能力的方式在国内外的不同语言的研究中都得到了充分的验证,例如Seyyedeh Zohreh Aftabia& Abbas Ali Ahangara& Hassan Mishmast Nehib(2021)中基于Baayen的生成能力计算模型对波斯语的派生后缀的生成能力进行了定量的研究,研究基于Baayen(2009)提出的生成能力计算模型和Lotfi Zadeh的模糊集合理论,对Bijankhan语料库中波斯语派生词缀的生成能力进行了研究,一共对51个派生后缀进行考察,该研究的结果证明Baayen的生成能力衡量方式在评估波斯语词缀的生成能力方面同样有效。
在生成能力研究层面,就笔者目前所阅读的文献,目前已有的研究多集中于对一两个词缀进行深入的定量或定性的分析研究,例如Baayen & Neitt(1997)曾基于自建的新闻报纸的语料库对荷兰语的派生后缀“-heid”进行了定量分析,目前的研究鲜有综合不同的语料库进行生成能力的对比分析研究。因此本研究基于Brown语料库和LOB语料库这两个平衡语料库,选择派生后缀“-ly”为研究对象,由于基于“-ly”这一个派生后缀所产生的单词有两种词性,分别是形容词和副词,本研究将回答以下两个问题:
1.基于Baayen的生成能力三个衡量维度,以“-ly”为后缀派生的形容词和副词的生成能力是否有差异?如果有差异造成这种差异的原因是什么?
2.美式英语和英式英语的统计结果是否有差异?
三、研究设计
研究语料
本研究以Brown语料库和LOB(全称Lancaster-Oslo-Bergen)语料库为研究语料,Brown语料库由美国Brown大学在20世纪60年代初创建,该语料库收集了500个连贯的美国英语书面语,用于研究当代美国英语。它是世界上第一个平衡语料库,也一直是英语平衡语料库的标准,LOB语料库便是基于此标准模仿Brown语料库的比例建立起来的英国英语语料库,其语料搜集自1961年英国英语出版物上的文本,共500篇,这两个语料库对当代美国英语和英国英语有着足够的代表性可以支撑本次研究。
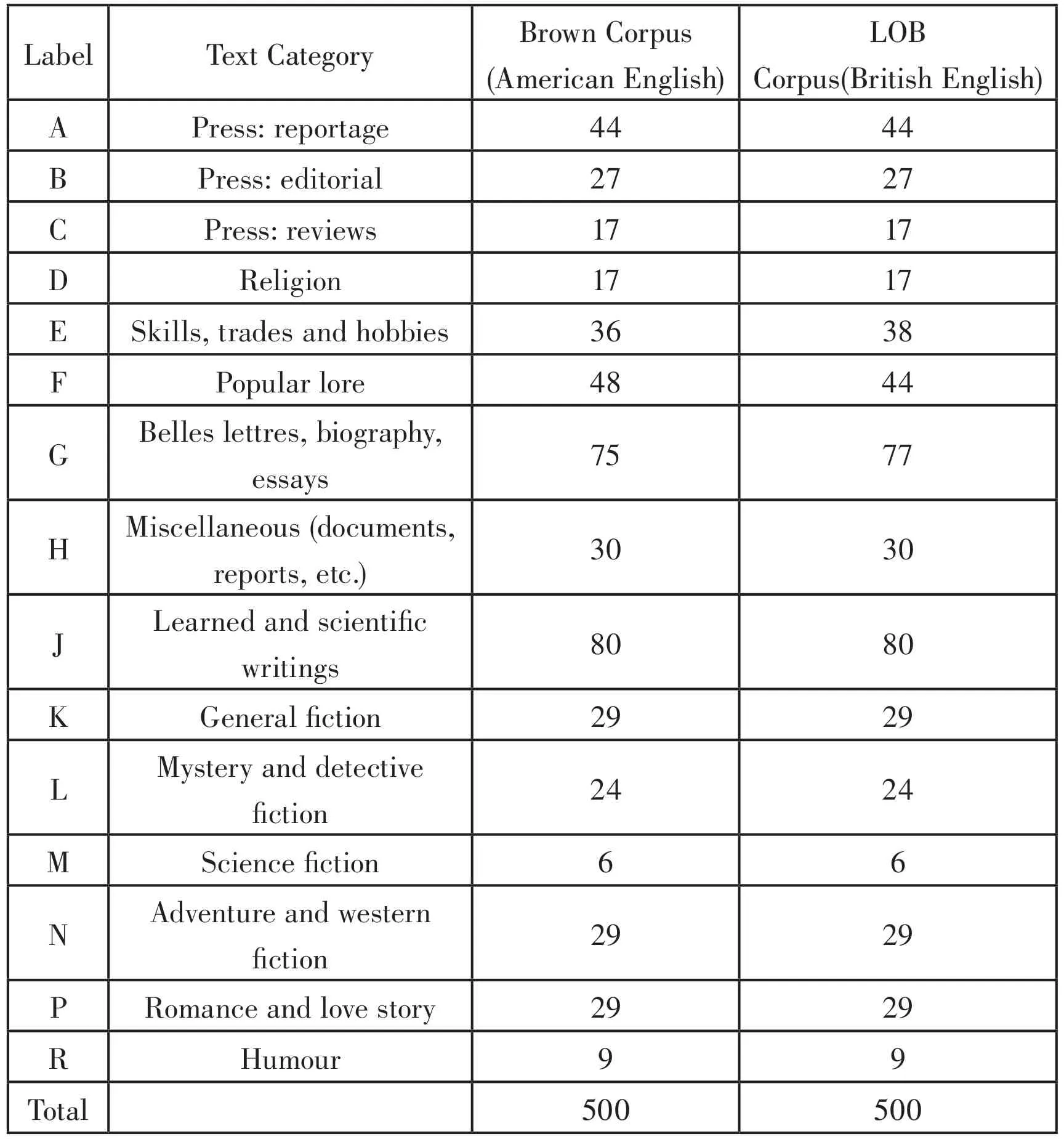
表1 Brown语料库和LOB语料库概况
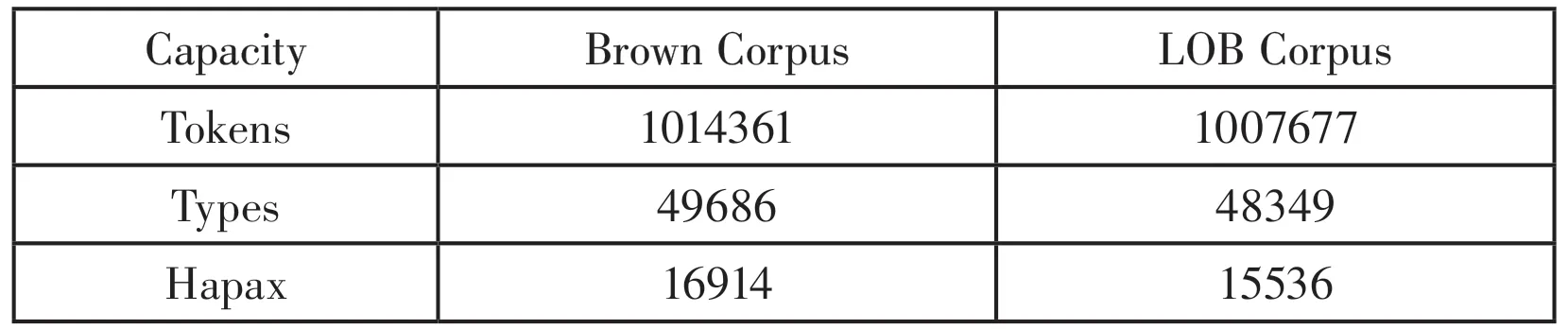
表2 Brown语料库和LOB语料库的具体容量
研究工具
本研究主要使用LancsBox和Excel这两个工具辅助研究。LancsBox是由兰卡斯特大学开发的一款多功能语料分析工具,使用LancsBox可以很快捷方便制作基于词频的Wordlist,便于后续研究。LancsBox也可以对文本进行词性标记,由于本研究主要考察副词和形容词的生成能力,因此可以借助LancsBox快速准确的排除其余词性的单词。得到最终要研究的数据后使用Excel协助进行进一步的数据筛选处理以保证结果的准确性,同时可以制作不同的表格使数据更加直观。
研究步骤
1.使用LancsBox将派生后缀“-ly”分别基于Brown和LOB语料库制作wordlists,将wordlists导入Excel后进行两步筛选,保证数据的准确性:
①基于LancsBox所制作的wordlists已经标好了全部单词的词性,将数据导入Excel后筛选出以“-ly”为后缀的形容词和副词:
②再进行完以词性为标准的筛选后,进行人工核验,将最后的结果核验无误后进行下一步的研究。
通过以上两个筛选步骤来保障研究数据的精确性和完整性。
2.将整理完的研究数据通过Excel依照Baayen所提出的生成能力计算方式进行计算,将研究结果以表格形式呈现并继续进行分析。
数据统计
基于Brown和LOB语料库,将以“-ly”为后缀生成的单词经过筛选过后,分为形容词和副词两个类别以表3的形式呈现
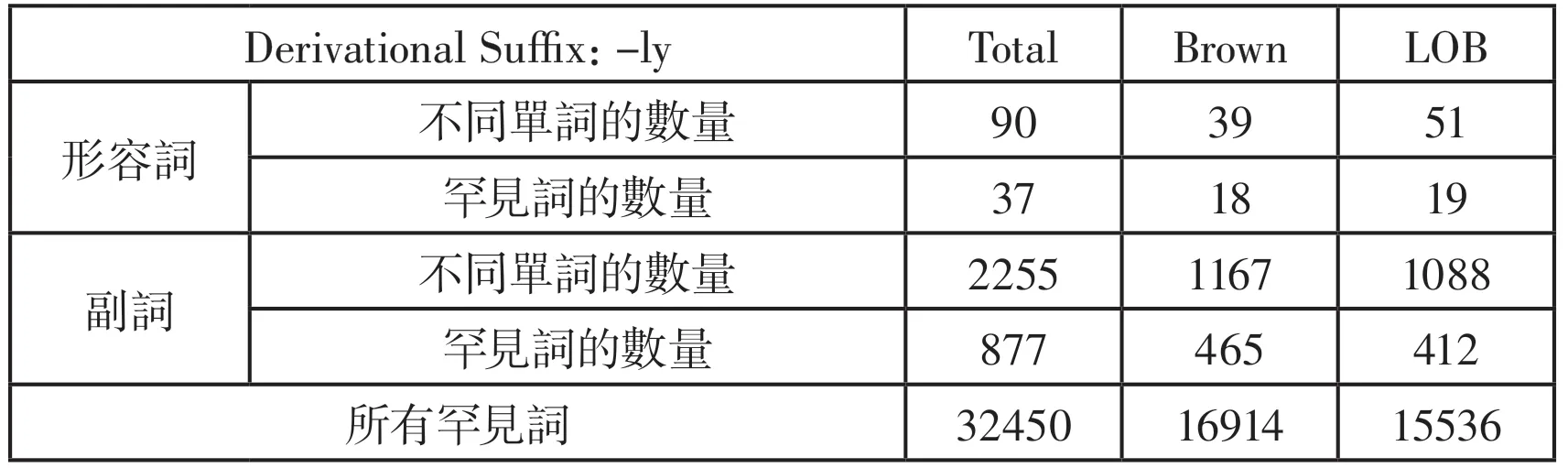
表3 以”-ly”为后缀的单词数量
四、结果与讨论
1.基于Baayen的生成能力三个衡量维度,以“-ly”为后缀派生的形容词和副词的生成能力是否有差异?如果有差异造成这种差异的原因是什么?
基于Baayen的生成能力三个衡量维度对两个语料库的数据整合进行计算并且以表4记录
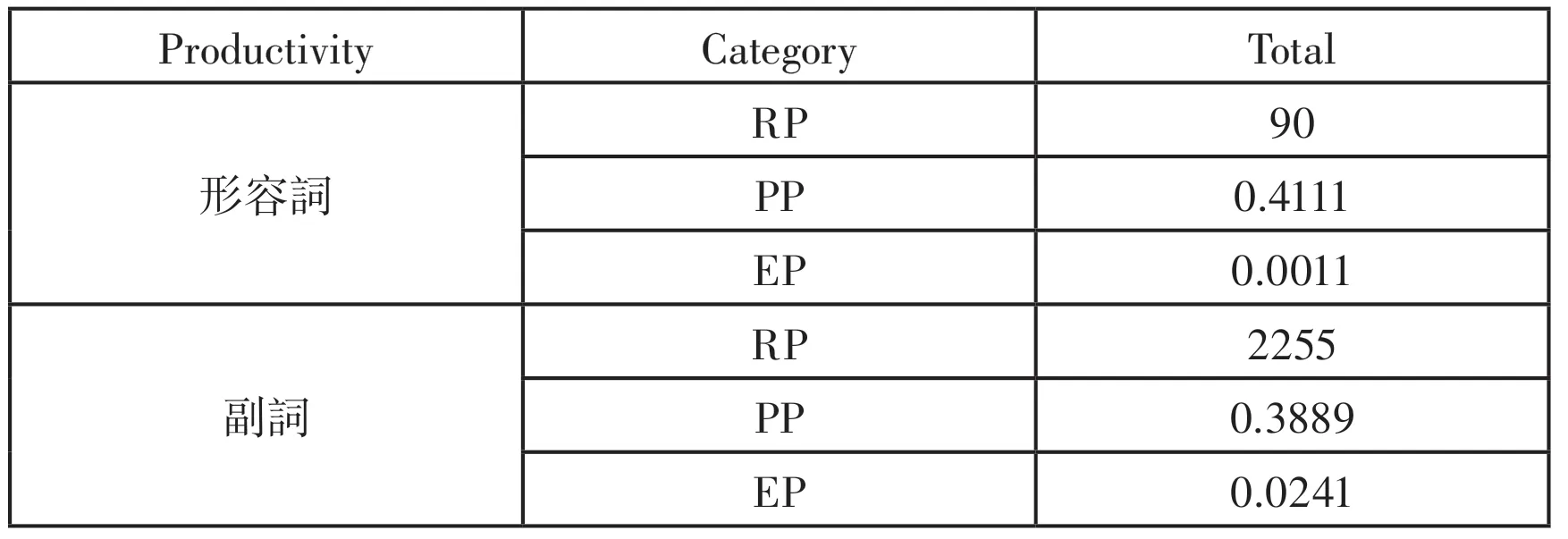
表4 基于语料库的形容词和副词的生成能力
从表4可以看出,以“-ly”为后缀派生的形容词和副词的生成能力存在明显差异。具体来说在所使用的语料库中形容词的单词数量远远小于副词的单词数量,因此形容词的RP和EP远小于副词的RP。同时形容词的PP略大于副词的PP,但两者的差距并不是很大,没有像RP和PP那么明显的差异性。
“-ly”既是副词后缀也是形容词后缀。“-ly”作为本族语的副词后缀,几乎可以加在一切的形容词后面,表示状态(如cheerfully)、程度(greatly)以及时间(recently)等等,因此以“-ly”为后缀的副词数量特别庞大。与之相比,“-ly”也可以加在名词后面充当形容词后缀,在这种情况下,“-ly”并不是活性词缀,它的构词数量是很有限的,其主要意思为like a (像……的)、characteristic of(有……性质的)以及suited to(适于……的)等等,例如,ghostly(像鬼一样的)、brotherly(有兄弟特点的)、manly(适合男子的)等等,因此以“-ly”为后缀的形容词数量不是很多。
RP这一衡量维度显示了过去的生成能力和该后缀使用的程度,EP这一衡量维度是对所有词缀对词汇增长率的相对贡献的估计,从上文可以得出以“-ly”为后缀的副词数量特别多,而以“-ly”为后缀的形容词数量不是很多,因此在语料库中“-ly”的副词的RP和EP均远大于形容词。
PP这一衡量维度是表示在某一语料库或文本中遇到尚未观察到的单词类型的概率,由于“-ly”为后缀的形容词数量不是很多,所以很多以此形成的形容词相对而言比较陌生,而对以“-ly”为后缀的副词已经非常熟悉,因此在某一语料库中遇到尚未观察的单词类型概率两者相差不大。前者是因为数量少很多不是很熟悉,后者是构词数量很多因此也会遇到尚未观察到的单词类型,但总体而言两者相差不是很多。PP多与EP相结合来考察词缀的生成能力。
2.美式英语和英式英语的统计结果是否有差异?
基于Baayen的生成能力三个衡量维度分别对Brown和LOB语料库进行计算并且以表5记录
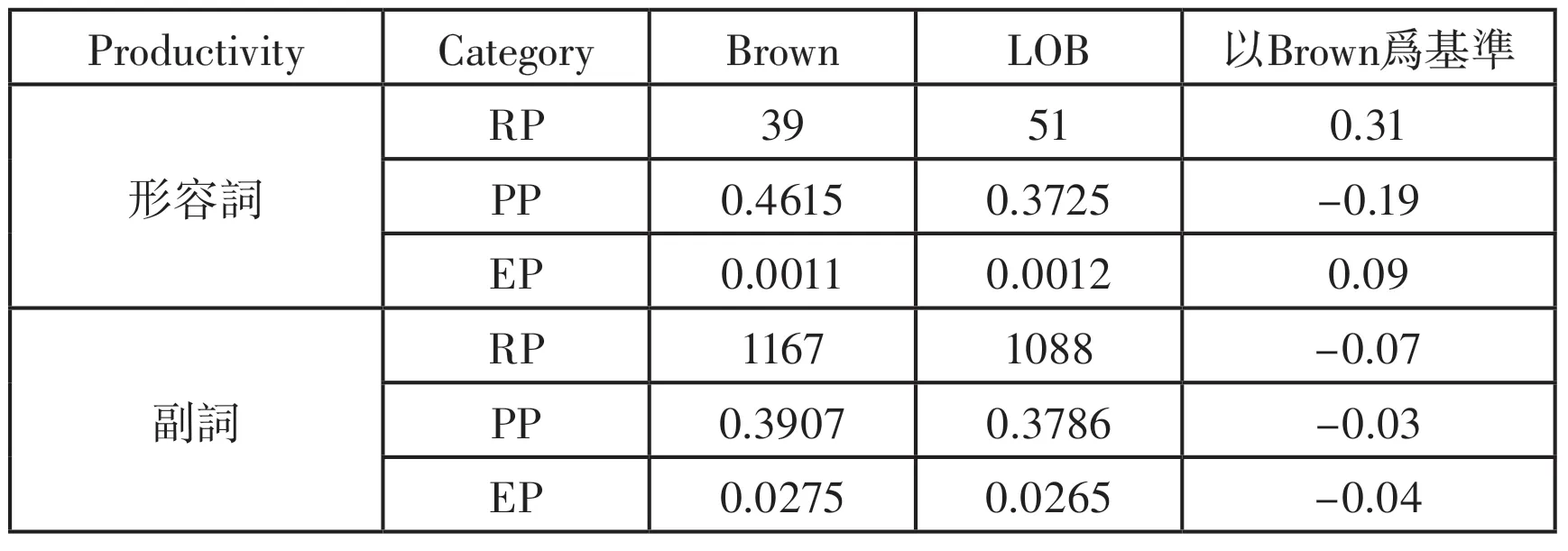
表5 基于语料库的形容词和副词的生成能力
从表5可以看出,在Brown和LOB语料库两个语料库中,前者代表的是美式英语,后者代表的是英式英语。从结果来看两者之间存在差异,在两个语料库中形容词的RP和PP的相对差异较为明显,其余各项数据的差异很小。总体而言,两个语料库之间存在差异但是差异不大。
这可能是因为英式英语和美式英语其实最大的差别就是发音,除了发音,词汇方面也存在差异。虽然美国和英国官方语言都是英语,而且有很深的渊源,但在日后的发展过程当中,因为文化不同,所以还是会产生差异,例如football,美式英语称之为橄榄球,英式英语称之为足球,因此存在差异但差异并不是很大。
五、结语
本研究基于Baayen的词缀生成能力的三个衡量维度,以Brown语料库和LOB语料库为研究语料,对派生后缀“-ly”进行了深层次考察,分为形容词和副词两个类别进行比较分析,结果表明形容词在已实现生成能力和扩大生成能力这两个维度均远小于副词,造成这种差异的原因大部分是因为因此以“-ly”为后缀的副词数量特别庞大,而以“-ly”为后缀的形容词数量不是很多。而在潜在生产力这一衡量维度形容词和副词的差别不大。造成这种差异的原因大部分是因为在某一语料库中遇到尚未观察的单词类型概率两者相差不大,前者是因为数量少很多不是很熟悉,后者是构词数量很多因此也会遇到尚未观察到的单词类型。同时也比较了代表美式英语的Brown语料库和代表英式英语的LOB语料库这两个语料库的数据统计结果的差别,结果表明有差异但差异不大。
本研究也存在明显的不足。一是选择研究的对象不多,仅仅选择了“-ly”这一个派生后缀作为研究对象,二是选择的语料库不是很新,容量也不是很大,有待于后续的研究进行进一步的丰富和补充。
猜你喜欢
红河学院学报(2021年4期)2021-11-19
三门峡职业技术学院学报(2021年4期)2021-04-19
韩国语教学与研究(2021年3期)2021-03-16
鸭绿江·下半月(2019年7期)2019-11-05
小说月刊(2017年16期)2017-12-01
西夏研究(2017年1期)2017-07-10
中国新通信(2016年17期)2016-11-17
电脑知识与技术·经验技巧(2016年1期)2016-03-14
辽金历史与考古(2016年0期)2016-02-02
高中生学习·高三版(2014年3期)2014-04-29
