
聋人句子阅读中的视觉功能补偿现象:副中央凹-中央凹效应的证据 *
2022-06-02 12:21王影超叶佳滢袁小源闫国利
心理与行为研究 2022年2期
秦 钊 王影超 叶佳滢 袁小源 闫国利,3
(1 教育部人文社会科学重点研究基地天津师范大学心理与行为研究院,天津 300387) (2 天津师范大学心理学部,天津300387) (3 学生心理发展与学习天津市高校社会科学实验室,天津 300387)
1 引言
聋人视觉功能补偿现象是指,为了弥补听觉信息的缺失,聋人的视觉功能会发生补偿性改变,表现出视觉功能的增强(闫国利, 秦钊, 2021;Alencar et al., 2019)。这种改变既包括空间维度的增强,也包括时间维度的增强。相比健听者,聋人能够觉察到边缘视野内更远处的刺激(Buckley et al., 2010),或者对副中央凹/边缘视野内刺激的觉察速度更快(Pavani & Bottari, 2012)。
聋人视觉功能补偿现象不仅会影响低水平的视知觉任务,也会影响高水平的阅读任务(Dye et al.,2008)。在句子阅读过程中,补偿现象的一种表现形式是,相比阅读能力匹配的健听读者,聋人对副中央凹视野内文本信息的加工效率更高(刘璐,闫国利, 2018; 闫国利 等, 2019; Yan et al., 2015)。Yan 等采用边界范式,在早期眼动指标上发现了汉语聋人读者的语义预视效益;而在晚期眼动指标上发现了聋人读者的语义预视代价,以及健听读者的语义预视效益。随后,刘璐和闫国利采用消失文本范式发现,当副中央凹视野的词N+1 呈现40 ms 消失后,不会影响聋人的副中央凹词汇通达,但是会对阅读水平相当的健听读者造成干扰。因此,在句子阅读过程中,聋人读者存在副中央凹视觉功能补偿现象。
那么,聋人在副中央凹视野内表现出的视觉功能补偿现象如何影响其中央凹的信息加工过程?在视知觉任务和词汇识别任务中均发现,副中央凹视野内的有效刺激会促进中央凹目标刺激的加工。而聋人的视觉功能补偿现象会使其受到的促进作用更大(刘璐, 2017; Prasad et al., 2017)。刘璐采用副中央凹启动范式,在3°视角上设置字形相似启动字,要求被试对中央凹的目标字进行词汇判断。结果发现,聋人读者的启动效应明显大于健听读者。
但是,在句子阅读过程相关研究中,尚无文献直接探讨聋人的副中央凹视觉功能补偿现象对中央凹加工过程的影响。在视知觉任务和词汇识别任务中发现的聋人副中央凹视觉功能补偿现象对其中央凹加工过程的促进作用,能否反映在句子阅读水平中?对于阅读过程而言,中央凹的词汇通达比副中央凹的预视加工更为重要(Rayner &Bertera, 1979)。而且,在汉语句子阅读过程中,字与字之间没有空格,汉字排列紧密,读者更容易从注视点右侧的汉字提取信息。因此,本研究将操纵副中央凹字N+1 和中央凹字N 之间的关系,以探究聋人句子阅读过程中的副中央凹视觉功能补偿现象能否促进其中央凹的词汇识别过程。
在阅读过程中,中央凹目标词的注视时间会受到副中央凹视野内单词特性的影响,这种现象称为副中央凹-中央凹效应(parafoveal-on-foveal effect, PoF)(Drieghe, 2011)。其中,最为稳定的是PoF 重复效应(Mirault et al., 2020),即副中央凹和中央凹呈现的词相同(重复呈现词N),会促进词N 的加工。研究者常用PoF 重复效应来探究句子阅读过程中,读者的词汇加工方式是序列加工还是平行加工(胡笑羽 等, 2010)。Dare 和Shillcock(2013)以健听的英语母语大学生为被试,采用边界范式,设置不同的预视条件。结果发现,与无关词预视条件相比,在重复词预视条件下,词N 的注视时间更短。随后,胡笑羽等(2013)在汉语母语读者中重复了上述结果。也有研究者发现了与之相关的电生理证据(Mirault et al.,2020)。
聋人作为特殊群体,存在副中央凹视觉功能补偿现象,这种现象可能会影响其PoF 重复效应的大小或发生时间。Dare 和Shillcock(2013)认为,PoF 重复效应与副中央凹启动效应的原理相似,当副中央凹预视字与中央凹目标字相关时,会促进目标字的识别。结合聋人副中央凹启动实验的结果来看(刘璐, 2017; Prasad et al., 2017),预计聋人的PoF 重复效应会大于健听读者。而现有句子阅读实验的结果表明,聋人对副中央凹视野内文本信息的加工效率更高(刘璐, 闫国利, 2018;Yan et al., 2015)。基于此,预期聋人能够更快地获得字N+1 的信息,并将其与字N 的信息进行整合,即聋人的PoF 重复效应出现得更早。
综上,为了探讨聋人句子阅读过程中的副中央凹视觉功能补偿现象对其中央凹加工过程的影响,本研究将采用边界范式(胡笑羽 等, 2010),在自然阅读的状态下,操纵字N 和字N+1 之间的关系,测量聋人的PoF 重复效应。另外,为了排除阅读技能和发展因素对实验结果的影响,设置三组被试,分别是聋人组、阅读能力匹配组和生理年龄匹配组,匹配组均为健听读者(刘璐, 闫国利, 2018)。由于聋人的副中央凹视野优势(刘璐,闫国利, 2018; Yan et al., 2015),本研究预期:(1)相比阅读能力匹配组,聋人的PoF 重复效应更大或者出现得更早;(2)相比年龄匹配组,聋人的阅读水平较低,而副中央凹视觉功能补偿现象能够在一定程度上弥补这种不足,使得两组被试的PoF 重复效应没有差异。
2 研究方法
2.1 被试
聋人被试选自天津某聋人学校的初高中生,3 岁前失聪,优势耳听力损失程度大于80dB,未植入人工耳蜗,且父母均健听。年龄匹配组选自天津某中学的初高中生,与聋人组的年龄和智力匹配。阅读能力匹配组选自天津某小学四年级学生,与聋人组的智力、阅读理解能力、阅读流畅性和正字法意识匹配。
具体测验如下。(1)智力测验:本土化后的瑞文标准推理能力测验,结果用百分等级表示(张厚粲, 王晓平, 1989)。(2)阅读理解能力:要求被试阅读一篇文章,并回答文末的题目,满分15 分(李利平 等, 2016)。(3)阅读流畅性:要求被试判断句子的对错,限时3 分钟,计算其阅读速度(字/分)(董琼 等, 2012)。(4)正字法意识:要求被试判断汉字是真字还是假字,满分45 分(董琼 等, 2012)。
采用G*Power 3.1 软件计算样本量,设置中等效应量f=0.25,α=0.05,Power=0.80,计算得到最少需要36 人。经过筛选和测验,实验最终包括54 人,每组18 人,测验成绩见表1。聋人组和年龄匹配组的生理年龄(p=0.413)和智力(p=0.897)均无显著差异。聋人组和阅读能力匹配组的智力(p=0.486)、阅读理解能力(p=0.479)、阅读流畅性(p=0.688)和正字法意识(p=0.904)均没有显著差异。

表 1 各组被试的测验成绩
2.2 实验设计
3(被试类型:聋人组、阅读能力匹配组、年龄匹配组)×3(预视条件:重复字预视、等同字预视、无关字预视)的混合实验设计。其中,被试类型是被试间变量,预视条件是被试内变量。
2.3 实验材料
填充句选自闫国利等(2021),正式实验句的编制步骤如下。
(1)目标字选取。从小学一至五年级语文课本(人教版)的生字表中,选取足量的单字名词,作为实验句的目标字N。(2)句子编制。句长在14~18 个字之间,句中字N 和字N+1 都是单字词,位于实验句的中间位置。(3)聋校教师评定。请天津某聋人学校的两位老师进行筛选,确保实验句符合绝大多数聋人被试的阅读水平。(4)小学生评定。请四年级学生对句子的难度(1=非常简单,5=非常难)、通顺性(1=非常不通顺,5=非常通顺)和字N 的预测性进行评定。实验句的难度较低,M=1.76(SD=0.53),通顺性较高,M=3.74(SD=0.49),且字N 的预测性较低,M=0.03(SD=0.05)。(5)无关预视字选取。在字N+1 的位置上,可能会呈现三种预视字:重复字(repetition)、等同字(identical)和无关字(unrelated)。重复字是原句的字N,等同字是原句的字N+1。
从生字表中,再次选取足量的单字名词,作为无关预视字。三种预视字的笔画数无显著差异[F(2, 256)=0.02, p=0.931],而字频存在差异,F(2,256)=55.24,p<0.001。等同字的字频高于其他两种预视字(ps<0.001),重复字和无关字的字频无显著差异(p=1.000)。三种预视字的笔画数和字频结果见表2。
2.4 实验设备和程序
实验设备是EyeLink 1000Plus 桌面式眼动仪,显示器的分辨率为1024×768 像素,被试眼睛距离屏幕63cm。每个汉字以28 磅宋体呈现,所占视角为1.3°。采用边界范式,在字N 和字N+1 之间,设置无形的边界,如图1。当被试注视边界之前的汉字时,在字N+1 的位置上,会呈现三种预视字。当被试眼跳越过边界时,边界后的字重新变回原句的字N+1(如“能”)。实验共包括129 个实验句和30 个填充句,其中38 个句子的后面有问题句,需要被试按键回答。采用拉丁方平衡实验句和预视条件的匹配关系,编制三套程序,每名被试只做其中一套。

图 1 实验材料和预视条件示例
2.5 数据处理方法
眼动指标。以字N 和字N+1 位置为兴趣区,分别计算被试的PoF 效应和预视效应。纳入分析的眼动指标有:首次注视时间、凝视时间、总注视时间、回视入比率和回视出比率(Angele et al.,2013; Wang et al., 2021)。
数据剔除。对异常和极端数据进行剔除:(1)剔除注视时间小于80 ms 或大于1200 ms 的注视点。(2)剔除眼动记录缺失的试次(1.35%)。(3)剔除边界变化不合理的试次(10.51%)。(4)剔除边界后图片呈现延迟的试次。分析字N+1 的结果时,将边界后图片呈现时间延迟9 ms 以上的试次剔除(Angele et al., 2013),共剔除6.34%的试次。分析字N 的第一遍阅读相关指标时,将延迟25 ms 以上的试次剔除(Angele et al., 2013),共剔除0.55%的试次。分析字N 的总注视时间和回视入比率时,剔除标准与字N+1 的标准一致。(5)分析时间指标时,剔除2.5 个标准差以外的极端试次,平均剔除1.72%的试次。
分析软件。采用R 软件(4.1.1)的lme4 软件包(1.1-27.1),将时间指标log 转化后,对其进行线性混合模型分析,对二分变量进行广义线性混合模型分析,并采用lmerTest 软件包(3.1-3)计算p 值。报告的结果有回归系数β、标准误SE、t/z 值和 p 值。
模型信息。第一个模型的固定效应是被试类型和预视条件,随机效应是被试和项目,字N+1 的字频是协变量。将聋人组视为基线,在三组被试之间设置两对连续比较,即聋人组-年龄匹配组和阅读能力匹配组-聋人组。同理,将无关字预视当作基线,在三种预视条件之间设置两对连续比较。分析字N 时,无关字预视和其他两种预视条件之间的差异,都可称之为PoF 效应(Dare &Shillcock, 2013)。其中,PoF 重复效应是指重复字和无关字预视条件的比较(Mirault et al., 2020)。随后,为了作进一步的简单效应分析,参照前人研究(刘璐, 闫国利, 2018; 闫国利 等, 2019; 闫国利等, 2021),重新构建一个模型,将预视条件当作固定效应,单独比较每组被试在不同预视条件之间的差异。
3 结果
聋人组、年龄匹配组和阅读能力匹配组,问题句判断的准确率分别为90%、95%和93%。被试类型的主效应显著,F(2, 51)=4.79,p=0.012。聋人组的准确率低于年龄匹配组(p=0.010),而阅读能力匹配组和其他两组读者的差异不显著(ps>0.05)。
3.1 字N 的注视结果
在不同预视条件下,三组被试对字N 的注视时间及回视入比率结果见表3。
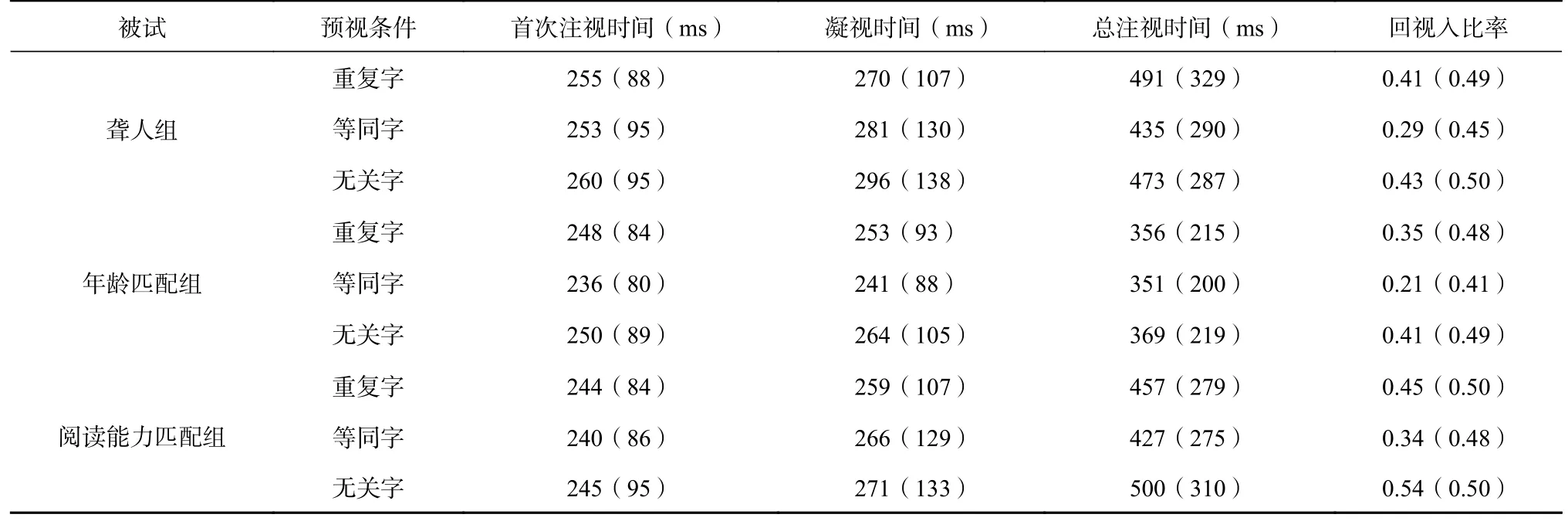
表 3 字N 的眼动结果
聋人组的总注视时间高于年龄匹配组(β=0.19,SE=0.09, t=2.07, p=0.043),阅读能力匹配组的回视入比率高于聋人组(β=0.39, SE=0.19, z=2.05,p=0.040)。相比无关字预视,重复字和等同字预视条件下字N 的凝视时间(|t|s≥2.15, ps<0.05)和总注视时间更短(|t|s≥1.96, ps≤0.05),且回视入比率更低(|z|s≥2.42, ps<0.05),存在 PoF 效应。
在总注视时间上,聋人组和阅读能力匹配组在无关字和重复字预视条件之间的交互作用显著(β=0.10, SE=0.05, t=2.12, p=0.034)。从平均值来看,两组被试的结果趋势相反,见图2。聋人组在重复字预视条件下的总注视时间大于无关字预视(18 ms),存在预视代价。而阅读能力匹配组在重复字预视条件下的总注视时间小于无关字预视(43 ms),表现出PoF 重复效应。
进一步比较每组被试在不同预视条件下字N 的结果,分析每组被试的PoF 效应。聋人组:相比无关字预视,等同字预视条件下的回视入比率更低(β=-0.61, SE=0.18, z=-3.37, p<0.001),重复字预视条件下的凝视时间更短(β=0.06, SE=0.03,t=2.47, p=0.014),即聋人在早期阅读指标凝视时间上表现出PoF 重复效应,如图2 所示。年龄匹配组:相比无关字预视,等同字预视条件下的凝视时间更短(β=-0.08, SE=0.03, t=-2.45, p=0.015),且回视入比率更低(β=-0.93, SE=0.23, z=-3.98,p<0.001)。阅读能力匹配组:重复字和等同字预视条件下的总注视时间(|t|s≥2.51, ps<0.05)和回视入比率(|z|s≥2.61, ps<0.01)均小于无关字预视条件,即阅读能力匹配组在晚期阅读指标上表现出PoF 重复效应。
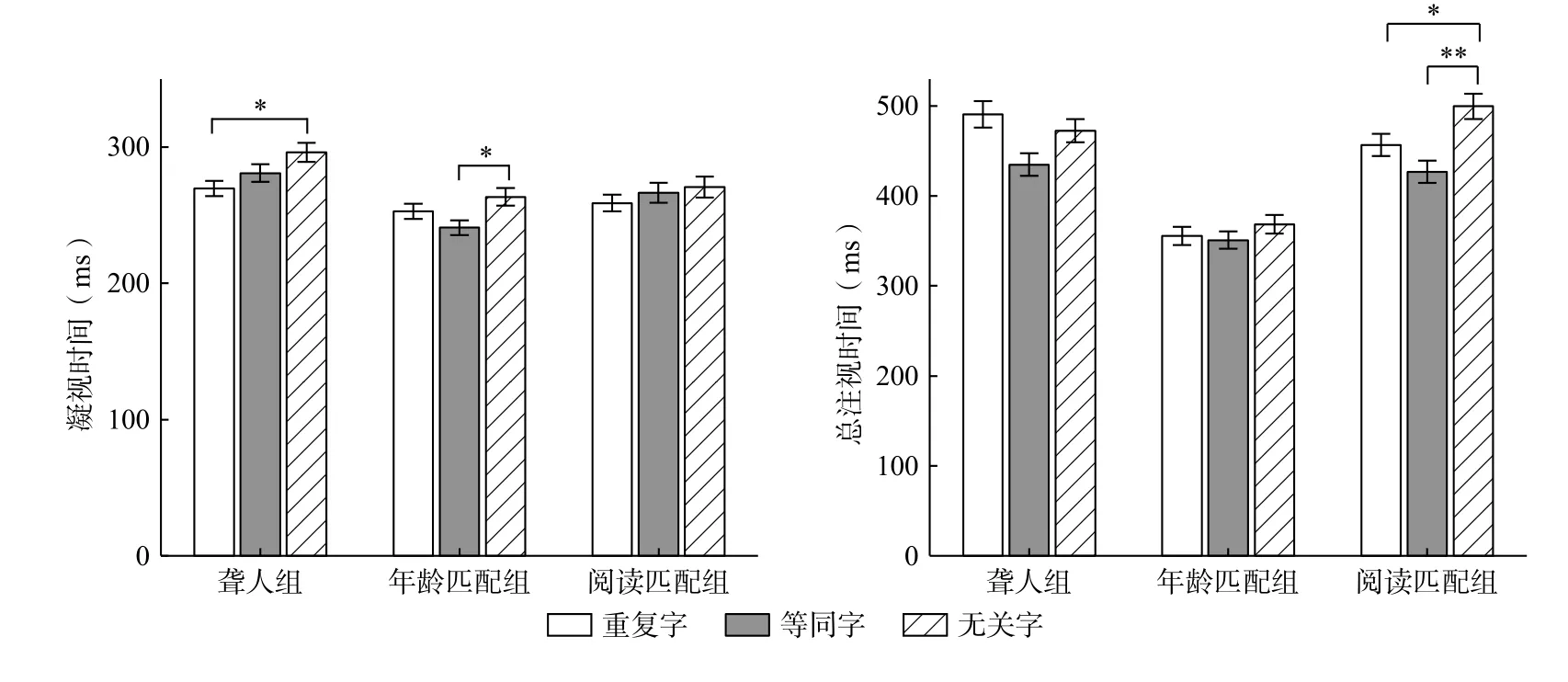
图 2 字N 的凝视时间和总注视时间
3.2 字N+1 的注视结果
在不同预视条件下,三组被试对字N+1 的注视时间及回视出比率结果见表4。

表 4 字N+1 的眼动结果
聋人组的回视出比率低于阅读能力匹配组(β=0.58, SE=0.23, t=2.50, p=0.013)。相比无关字预视,等同字预视条件下字N+1 的首次注视时间、凝视时间和总注视时间都更短(|t|s≥4.44,ps<0.001),且回视出比率更低(β=-0.54, SE=0.11,z=-4.84, p<0.001),存在等同预视效益。重复字预视条件下字N+1 的首次注视时间和凝视时间小于无关字预视(|t|s≥2.08, ps<0.05)。
在回视出比率上,聋人组和阅读能力匹配组在无关字和重复字预视条件之间的交互作用显著(β=0.45, SE=0.22, t=2.05, p=0.041)。从平均值来看,阅读能力匹配组在重复字预视条件下的回视出比率低于无关字预视,而这两种预视条件对聋人没有显著影响,见图3。

图 3 字N+1 的首次注视时间和回视出比率
进一步比较每组被试在不同预视条件下字N+1 的结果,分析每组被试的预视效应。聋人组:相比无关字预视,等同字预视条件下的注视时间都更短(|t|s≥3.51, ps<0.001),且回视出比率更低(β=-0.59, SE=0.20, z=-2.99, p=0.003)。年龄匹配组:等同字预视条件下的注视时间均小于无关字预视(|t|s≥2.36, ps<0.05)。阅读能力匹配组:相比无关字预视,等同字和重复字预视条件下的首次注视时间(|t|s≥2.29, ps<0.05)和凝视时间更短(|t|s≥2.21, ps<0.05),且回视出比率更低(|z|s≥2.57, ps<0.05)。因此,三组被试都表现出稳定的等同预视效益。
4 讨论
本研究采用边界范式,测量聋人读者、阅读能力匹配组健听读者和年龄匹配组健听读者的PoF 重复效应。结果发现,聋人组的PoF 重复效应反映在早期阅读指标,而阅读能力匹配组的只出现在晚期阅读指标。因此,相比阅读能力匹配组,聋人组的PoF 重复效应出现得更早,表现出副中央凹视觉功能补偿现象,与预期一致。
在聋人组和阅读能力匹配组中,都发现了PoF 重复效应,与前人结果一致(胡笑羽 等, 2013;Angele et al., 2013; Dare & Shillcock, 2013; Mirault et al., 2020)。Angele 等提出两种可能的解释:(1)重复字预视条件下,读者对字N+1 的预视加工促进了字N 的识别。(2)重复呈现的目标字中断了当前注视字的加工。吸引者假说(attraction hypothesis)认为,若字N+1 的预视加工遇到困难,则预视字会吸引读者的注意,使其提前计划下一次眼跳,导致字N 的注视时间变短(胡笑羽等, 2010; Hyönä, 1995)。
如果是由于重复字的“吸引”,破坏了字N 的加工,那么将会对随后的阅读过程造成负面影响,例如出现更多的回视。但是,重复字预视条件下的结果趋势与该假设不符。因此,实验结果不支持吸引者假说,即PoF 重复效应是由于重复字预视促进了字N 的识别。对年龄匹配组而言,目标字都是非常简单的单字词,在较短的时间内便能够完成词汇通达,所以没有发现PoF 重复效应。
聋人组和阅读能力匹配组的PoF 重复效应,在时间进程上存在区别。聋人组的PoF 重复效应出现得更早,直到晚期变为预视代价,与Yan 等(2015)语义预视的结果一致。这种时程上的差异可能是由于:(1)聋人采取更直接的字形-语义编码策略。Yan 等认为,在汉语阅读过程中,聋人可以通过字形-语义编码通路更快地完成预视词的语义通达,而无须依赖语音的中介。但是,由于重复字的语义信息和句子的语境信息不连贯,直到晚期加工阶段,这种语义冲突最终破坏了阅读过程,对字N 的识别产生即时的影响(崔磊 等,2010),表现出预视代价。(2)聋人的副中央凹视觉功能补偿现象。刘璐和闫国利(2018)认为,由于听觉信息的缺失,聋人的视觉功能会发生补偿性改变,呈现出视觉注意资源的再分配,即与健听者相比,聋人会将更多的视觉注意资源分配至中央凹以外的视野。这种视觉注意资源的分配模式,能够提高聋人对副中央凹视野内文本信息的编码速度(刘璐, 闫国利, 2018),促进其对字N+1 预视信息的提取和加工(闫国利 等, 2019)。
总而言之,上述两种观点都能解释聋人的PoF 重复效应。但是,聋人能否加工语音信息仍然存在争议(闫国利 等, 2019; Yan et al., 2015)。而且,重复字的视觉特征也能促进中央凹目标字的识别,无需完成预视字的语义通达(Angele et al.,2013)。所以,不能完全依靠字形-语义通路来解释聋人的PoF 重复效应。本研究更倾向于支持聋人副中央凹视觉功能补偿现象的存在,引起了聋人的早期预视效益和晚期预视代价。
对字N+1 的结果分析发现,在等同字预视条件下,三组被试都表现出稳定的等同预视效益,重复了闫国利等(2019)的结果。在重复字预视条件下,仅在阅读能力匹配组中发现了预视效益。相比等同字预视,重复字和无关字都是不符合句子语境信息的预视字,都会对随后的阅读过程产生干扰(王穗苹 等, 2009)。而聋人组和年龄匹配组在注视字N 时,就已经能够意识到这个问题。由于阅读能力匹配组的阅读技能低于年龄匹配组,而且不存在视觉功能补偿现象,所以在字N+1 的早期加工阶段,仍然存在重复字预视效益,见图3。随后,通过更多的回视逐渐整合句子的语境信息,直到晚期加工阶段,重复字和无关字预视条件之间的差异才消失。
聋人的副中央凹视觉功能补偿现象会如何影响其阅读过程?相比健听读者,聋人读者的词汇加工特点是否存在差异?关于上述问题,Bélanger和Rayner(2015)提出了聋人的词汇加工效率假说(word-processing efficiency hypothesis)。该假说认为,与健听读者相比,在一次注视过程中,聋人读者对词汇的加工效率更高。本研究发现,聋人读者的字N 回视入比率和字N+1 回视出比率低于阅读能力匹配的健听读者。这说明聋人读者在词汇识别过程中,不需要多次回视,便能够完成词汇的语义通达,支持词汇加工效率假说。Bélanger和Rayner 认为,这种高效的词汇加工特点是由于聋人能够快速地提取副中央凹视野内的预视信息,而且聋人词汇识别过程无须语音编码的参与,字形和语义的连接更加紧密。本研究再次证实了聋人句子阅读过程中存在副中央凹视觉功能补偿现象。但是,在汉语阅读过程中,是否有语音编码的参与(闫国利 等, 2019),仍有待后续进一步研究。
5 结论
在聋人读者和阅读能力匹配的健听读者中,发现了汉语句子阅读时的PoF 重复效应。相比阅读能力匹配组,聋人的PoF 重复效应出现得更早。这说明聋人对副中央凹视野内文本信息的加工效率更高,表现出视觉功能补偿现象。
猜你喜欢
体育科技(2022年2期)2022-08-05
意林·全彩Color(2018年9期)2018-11-13
知识文库(2018年21期)2018-05-14
科学与财富(2018年32期)2018-01-02
分析化学(2017年12期)2017-12-25
中学物理·高中(2016年12期)2017-04-22
金融理财(2015年7期)2015-07-15
海外星云 (2014年21期)2015-01-14
小樱桃·童年阅读(2014年11期)2014-12-01
