
产业集群知识图谱构建方法研究
2022-07-10 14:36范存庆余军合战洪飞
科技与经济 2022年3期
范存庆 余军合 战洪飞 王 瑞
(宁波大学机械工程与力学学院,浙江 宁波 315211)
产业集群是推动区域经济发展的重要形式,产业集群中包含企业、人员、机构等众多主体,各主体之间都有直接或间接的复杂关系,构成庞大的网络结构。随着大数据技术的发展,通过获取产业集群相关数据,构建产业集群网络结构,从微观的角度研究产业集群的发展规律,更能详细研究产业集群的内部演化规律。知识图谱是研究网络结构数据的有效工具,其本质是一个能对现实世界中事物之间的关系进行直观映射的语义网络,可以利用知识图谱理论方法来研究产业集群的内部结构。知识图谱作为大数据技术的重要组成部分,现在已经被广泛应用[1]。
车金立等构建了军事装备知识图谱,用于实现军事装备领域的知识问答[2];在煤矿安全领域,刘鹏等将知识图谱结合Lattice LSTM模型和语义相似度计算,提出了一种自然语言知识查询方法,从而提高了煤矿安全信息资源整合[3];杜志强等围绕自然灾害事件、灾害应急任务等4个要素,结合本体建模方法和条件随机场模型构建了洪涝灾害应急知识图谱,根据数据关联,实现对相关数据节点的推荐应用,为提高自然灾害应急响应研究提供了理论方法基础[4];Rotmensch等提出了一种使用基本概念从大规模电子病历中提取医学信息并自动构建高质量健康知识图谱的方法[5];Fang等将计算机视觉算法和本体模型相结合,开发出建筑安全知识图谱,可依照安全法规自动识别建筑工地的安全隐患[6];Xiao等采用BiLSTM+CRF模型从大量文献中提取气象模拟知识并结合Neo4j图数据库构建气象模拟知识图谱,实现气象模拟知识的结构化存储和集成[7]。
本文选取宁波地区的注塑机产业集群作为研究对象,提出构建产业集群知识图谱的整体框架,构建产业集群本体模型,并从互联网平台获取数据,构建注塑机产业集群知识图谱,探索产业集群知识图谱的应用。
1 产业集群知识图谱整体框架设计
产业集群相关数据包括企业基本信息、专利信息、产品信息和人员需求信息等,这些数据包括结构化数据和非结构化数据,良莠不齐且数据量大,并非所有数据都可以用于构建知识图谱。因此构建产业集群知识图谱需要先明确产业集群的本体模型,根据建模结果从海量的数据中抽取相应的实体和关系,构建产业集群知识图谱。本文提出的整体框架如图1所示。
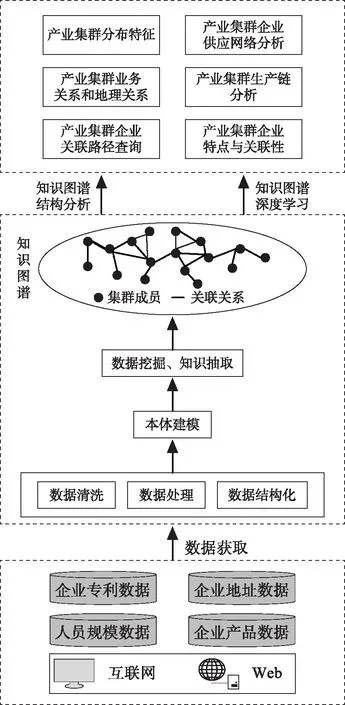
图1 产业集群知识图谱整体框架图
数据获取与预处理:数据的来源主要有天眼查之类的企业信息网站、企业专利库及招聘网站等,通过数据挖掘等手段进行获取,并对获取数据进行预处理,为信息抽取做准备。
本体建模和知识抽取:明确集群中企业、人员、产品等实体的属性以及各个实体之间的关系,构建产业集群的本体模型;根据本体模型从已有数据中抽取相关的企业实体、产品实体,同时抽取实体关系,构建知识图谱。
知识存储和可视化:在将数据转化成结构化数据基础上,抽取实体及其属性以及关系,构造“实体-关系-实体”三元组。传统的关系型数据库难以直观描述这种三元组关系,因此本文选用图数据库Neo4j存储知识图谱三元组。Neo4j可以直观反应实体之间的关系,并且利用Cypher图数据库查询语句可以对知识图谱进行高效的增删改查。
知识图谱应用:产业集群知识图谱从数据层面描述了产业集群的物理关系。通过知识图谱图结构分析方法和深度学习方法,对产业集群相关问题进行研究。
2 产业集群知识图谱构建
研究选择自顶向下的构建方式,先构建产业集群本体模型,再根据模型从数据中抽取相关实体和关系。
2.1 产业集群知识图谱本体建模
产业集群知识图谱建模侧重于构建知识图谱的本体模型,明确产业集群知识图谱中出现的实体概念和关系,实体概念可以理解为实体的类,关系是指对象之间的二元关系。其中实体概念一共包括6个:企业、人员、产品、地区、知识资源和科研院校。
企业类实体概念。企业是产业集群的主体,定义企业实体概念为{label;name;size;address;industry;time},中括号中是该实体的属性。其中label代表此类实体类别,比如“企业”;name代表企业名称,比如“富**机械制造有限公司”;size代表企业规模,选取企业参保人数作为企业规模的衡量标准;address代表企业所属地区,比如“北仑区”;industry代表企业所属行业,比如“通用设备制造业”;time代表企业成立时间,单位是年,如“2013”。
产品类实体概念。产品是产业集群经营活动的体现,也是产业集群的主体之一,定义产品实体概念为{label;name;class;frequency;function;price}。其中label代表此类实体的类别,如“产品”;name代表产品名称,如“注塑机”;class代表产品类别,如“生产设备”;frequency代表产品在集群中出现的频次;function代表产品功能,如“加工塑料制品”;price代表产品价格。
人员类实体概念。人员是产业集群中知识资源的载体,将人员实体概念定义为{label;age;sex;education;skill;post}。其中label代表此类实体的类别;age代表人员年龄;sex代表人员性别;education代表人员学历;skill代表人员技能;post代表人员岗位。人员类概念分为法人、研究人员及职工。
其他实体概念。地区类实体概念主要描述空间信息,用于关联企业业务活动。知识资源类实体概念主要描述产业集群的技术层面信息,包括专利、论文和技能等。科研院校类实体概念是集群中区别于企业的另一类机构实体,是论文等知识资源的主要输出单元。
在对产业集群知识图谱中的实体概念进行建模基础上,需要对实体间关系进行建模。关系包括实体间的二元关系以及实体和属性之间的关系。由于产业集群数据中有大部分结构化数据,其中的关联关系比较明确,方便对关系进行建模。结合前述步骤所建模的实体类概念,使用protégé工具构建出完整的产业集群知识图谱模式层及其实体类概念、实体关系和实体属性如图2、图3所示。
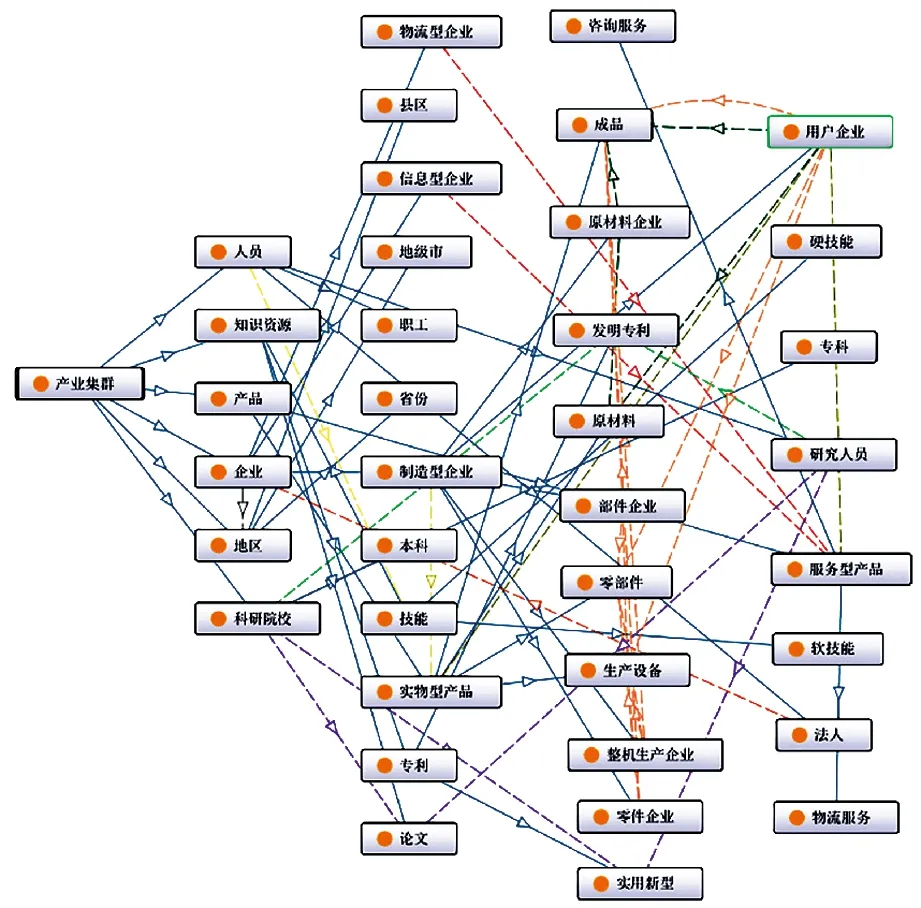
图2 产业集群知识图谱模式层概念关系
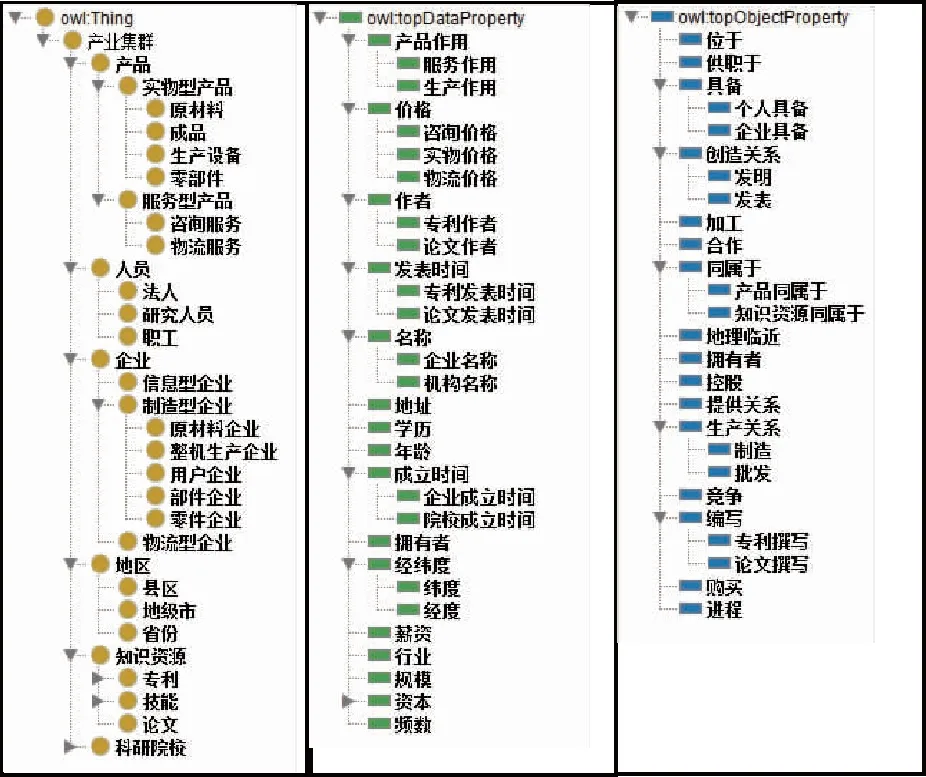
图3 产业集群知识图谱模式层概念及其关系
2.2 实体抽取和关系抽取
在本体建模基础上,可以从已有的数据中抽取相关的实体和关系,组成三元组,构建知识图谱。
企业实体及其关系抽取:企业基本信息主要存储在结构化数据中,由于结构化数据质量较高,具有规范的模式,对于结构化数据采用直接映射和基于规则的抽取方式。根据知识图谱建模部分所构建的企业本体模型,从数据库中提取“企业名称”字段作为name属性,“参保人数”字段作为size属性,“所属区县”字段作为address属性,“所属行业”字段作为industry属性,“成立日期”字段作为time属性,一共抽取到1 958个企业实体,部分“企业”实体数据如表1所示。
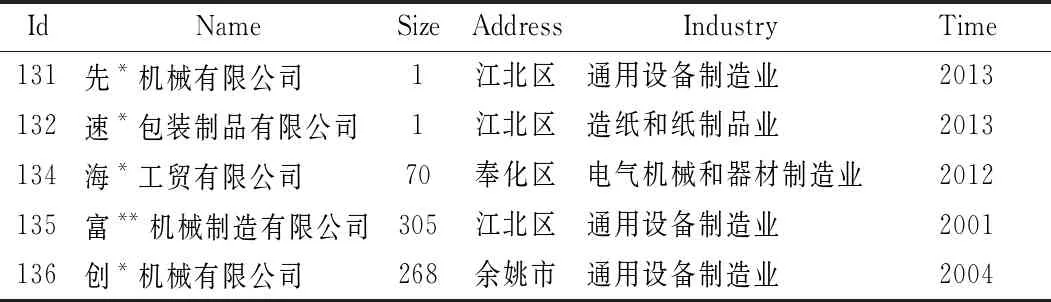
表1 企业实体数据(部分)
企业-企业关系的地理临近由企业地址计算得出,经过数据预处理阶段,每一个企业的地址都是唯一的,可以在地图上准确定位。结合百度地图开发平台API,将企业地址转换为经纬度进而计算出企业之间的相对距离,计算公式为:
(1)
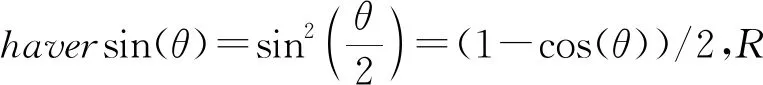
计算出所有企业两两之间的距离之后,将距离小于500m的两个企业设定为具有“地理临近”关系,并且将实际距离设置为该关系的权重。表2为部分企业关系数据。

表2 企业间关系数据(部分)
产品实体抽取:产品信息主要存储在非结构化文本中,然而由于这部分数据没有规范模式,因此使用BERT+BiLSTM+CRF模型进行实体识别。该模型有3个模块组成,第一个模块是BERT模块,负责将输入的文本转换成字向量输入到下一模块;第二层是BiLSTM模块,负责提取上下文语义特征并将结果输入第三模块;第三模块是CRF,负责对第二模块输出结果进行解码,对输入文本进行序列标注。
将文本输入该模型之前,需要先对文本进行标注,目前,常见的中文标注体系有三种:BMES、BIO和BIOES,本文采用的是BIO标注体系。标注对象是文本中的产品名称,B-PRO代表命名实体开始的字符,I-PRO代表命名实体剩余的字符,O代表非命名实体的字符。
选取了1 000家企业的经营范围文本数据进行标注,训练该模型。标注方法采用自动化标注和人工标注相结合的方式,最终一共标注了3 698个句子,将已标注的数据集按照7∶3的比例划分为训练集和测试集。实验评价指标采用准确率P,召回率R和F1值进行实体识别的效果评价。为了对比该模型的效果,选取BiLSTM+CRF模型和Word2Vec+BiLSTM+CRF模型进行对比实验,结果如表3所示。

表3 实验结果对比
结果证明BERT+BiLSTM+CRF在实体识别中效果较好。最终通过该模型抽取产品实体859个,以企业为单位将抽取到的产品名称存储在结构化数据中,并统计所有产品在所有企业出现的频次,基于构建的产品实体模型创建产品节点,其中产品名称作为name属性,产品频次作为frequency属性。
企业-产品和产品-产品关系抽取:通过分词发现,企业和产品之间的关系包括“制造”“批发”“提供”3种。因此,产品和企业的关系采用直接映射的方式构建,其中“制造”“批发”两个关键词在对企业经营范围文本进行分词时保留,然后直接与抽取到的产品进行匹配,构建“企业-制造/批发-产品”三元组。对于服务类型的产品,比如“仓储”“货物运输”等,和企业的关系为“提供”,构建“企业-提供-产品”三元组。
将两种产品出现在同一家企业的共现关系定义为产品-产品关系,关系名称为“同属于”。此外,构建产品的共现矩阵,比如“注塑机”和“塑料制品”在一家企业同时出现则计数1,如果在另一家企业又同时出现则计数加1,将两种产品的共现频次经过归一化后的数值作为“同属于”关系的权重,权重越大,产品关联越强,反之越弱。
2.3 知识融合
由于数据来源多样,存在同一个实体在不同数据源中表述不一致的问题,造成实体冗余,降低了知识图谱的质量。为解决这一问题,需要进行实体对齐。针对不同实体使用基于匹配规则和基于相似度两种方式进行实体对齐。对于企业实体,使用基于匹配规则的知识融合,即建立企业名称库,将抽取的实体统一匹配到名称库中,将表述统一。
对于产品实体,由于产品数量多,而且同一产品的表述远不止两种,因此提出基于语义相似度的知识融合。使用BERT输出的产品词向量,计算两个产品向量的余弦相似度,计算公式为:
(2)
其中x,y为两个词的词向量,计算出的余弦相似度越接近1,两个词越相似,越接近0,两个词越不相似。本文设置语义相似度的阈值为0.7,即余弦相似度大于等于0.7的词判定为相似词,将两者对应的实体进行融合。
经过知识融合,最终构建的图谱一共有实体2 596个,包括“企业”和“产品”;关系38 965个,包括“地理临近”“制造”“批发”“提供”“同属于”。将所有三元组全部存入Neo4j数据库中,其部分结果可视化结果如图4所示。
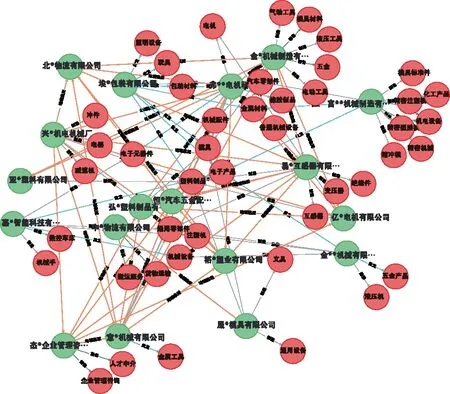
图4 产业集群知识图谱(局部)
3 产业集群知识图谱分析
企业之间的业务配套往往和地理位置的临近紧密关联,即在地理位置上临近的企业之间有较多的业务往来,反之,有较多业务往来的企业地理位置较临近。企业之间的业务往来可以从产品体现。
注塑机生产企业涉及的行业较多,上游企业包括钢材、冶金铸造等机械类零部件生产加工行业,以及液压零件、电子仪器仪表、电子元器件等传动类和控制类零部件加工行业。下游企业则包括塑料建材、汽车配件、家用电器和物流、包装材料以及其他普通塑料制品行业。
使用Cypher图数据库查询语言可以精确查询节点和关系信息,如图5所示。选取“富**机械制造公司”为例,查询其2跳关系的节点及关系,可以发现作为主机厂,“富**机械制造公司”周边分布着物流公司,下游业务公司比如塑料制品企业,以及上游公司比如机械零件制造企业,整个集群依托地理位置临近形成,可以看出它们的相对位置充分利用了地理环境优势,方便开展企业业务,各个企业之间的业务相互配套,形成制造系统。
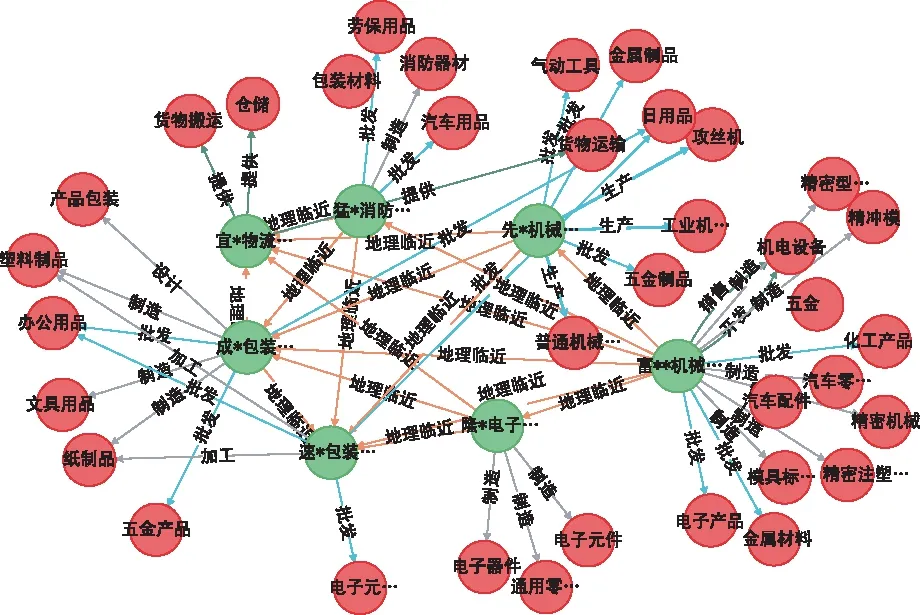
图5 注塑机某主机厂地理临近企业分布
4 总结与展望
本文将知识图谱和产业集群相结合,通过获取互联网平台中企业相关数据,经过数据预处理、知识图谱建模、知识抽取和知识融合构建了宁波市注塑机产业集群知识图谱,并将其存入Neo4j图数据库,使用Cypher图数据库查询语言查询注塑机主机厂周边企业,发现集群依托地理临近形成业务配套。
本文提出了产业集群知识图谱构建的整体框架,构建了产业集群知识图谱本体模型,并用注塑机集群验证其可行性,但目前所构建的知识图谱由于数据的不全,构建不够全面,知识节点粒度较大,仅是宏观层面的产业集群知识图谱。接下来将要收集更多数据,丰富该图谱,构建产业集群技术层面、人员层面等多维度知识图谱,将本体模型所涉及的实体和关系补全,进一步研究企业的各个方面的关联性。
猜你喜欢
少先队活动(2020年12期)2021-01-14
中国外汇(2019年18期)2019-11-25
军事运筹与系统工程(2019年4期)2019-09-11
电子制作(2018年11期)2018-08-04
哲学评论(2017年1期)2017-07-31
中国交通信息化(2017年3期)2017-06-08
中成药(2017年3期)2017-05-17
领导决策信息(2017年9期)2017-05-04
领导决策信息(2017年9期)2017-05-04
知识就是力量(2017年2期)2017-01-21
