
语言智能技术发展与语言数据治理技术模式构建
2022-07-15 01:29张凯薛嗣媛周建设
语言战略研究 2022年4期
张凯 薛嗣媛 周建设


提 要 梳理近60年(1960~2019)语言智能技术专利申请文献,可以发现近5年语言智能技术进步显著,预计在未来较长一段时期内仍将处于技术爆发期。当下,语言数据治理的重要性日渐凸显。分析当前智能技术赋能下机器翻译、智能客服、网络舆情监测、多语言资源建设等语言数据热点服务,指出语言数据治理体系面临的技术困境:(1)语言数据的偏见现象;(2)经典语言治理模型的短板。为破解困境并弥补经典数据挖掘模式的短板,提出点状聚合、线性组合和多层事态3种语言数据治理模式并展开对比分析,以期对智能化数据治理提供参考。
关键词 专利文献分析;语言智能技术发展;语言数据治理;语言数据治理技术模式
中图分类号 H002 文献标识码 A 文章编号 2096-1014(2022)04-0035-14
DOI 10.19689/j.cnki.cn10-1361/h.20220403
A review of the literature on patent applications for language intelligence technology over the past 60 years (1960– 2019) reveals that language intelligence technology has advanced significantly in the past five years. It is anticipated that the technological explosion will last for a long time in the future. The rapid development of language intelligence technology highlights the increasing importance of language data governance. Focusing on language data service sectors such as machine translation, intelligent customer service, opinion monitoring, and multilingual resource construction, this review paper analyses the tendencies of language data service development empowered by intelligent technologies. It points out that the language data governance system faces two technical complications, namely language data bias, and limitations of the traditional language governance models. In order to resolve the dilemma and challenges in language data processing and mining, three language data governance models are proposed and comparatively analysed, i.e., point aggregation, linear combination, and multi-layer state of affairs, which may serve as a reference for intelligent data governance.
patent document analysis; language intelligence technology; language data governance; language data governance model
當前人类社会正处于从信息时代到智能时代的过渡期,智能技术给人类生活带来了深远影响和美好前景。在人类不断探索智能技术的过程中,数据资源的重要性日益凸显,数据“管理”也逐渐走向数据“治理”。这意味着以语言符号体系为基础构成的各种数据将在开放的视野中被重新审视。
语言智能、语言数据治理均以语言符号为起点,分别向机器数字空间和社会文化领域展开探索,智能技术为关注社会群体空间和网络虚拟空间的语言数据研究提供了信息化条件下的治理手段,使治理的智能化发展成为可能。语言教学、新媒体及自媒体等现实场景,对智能技术和数据治理提出了更高的标准和要求。本文结合语言智能技术发展趋势,总结技术发展面临的挑战,综述技术赋能语言数据治理的现状,探索语言数据治理智能化发展的新模式。
一、从专利文献看近60年全球语言智能技术趋势及分布
专利文献记载了发明创造的内容,是科研机构和高科技企业的核心竞争力,相较学术论文更贴近实际应用或产品,是一种重要的知识产权保护手段。挖掘和分析语言智能方向的专利文献,可以通览语言智能技术发展,明晰语言智能技术创新方向和重点,同时也能为语言数据挖掘和智能化治理提供技术依据。
(一)全球语言智能技术发展趋势
作为人工智能范畴的专门术语(杨尔弘,等2018),“语言智能”是语言学、认知科学与人工智能的交叉和融合,是探究自然语言(人脑语言活动)和机器语言之间同构关系的科学(周建设,等2017;周建设2020)。语言智能包含计算智能和认知智能,依据数据对象分为人类生物特征处理、图像信息处理、文本语言处理等方面的技术。故此,本文将近60年(1960~2019)上述3项技术专利文献作为语言智能概念范畴下的分析对象。
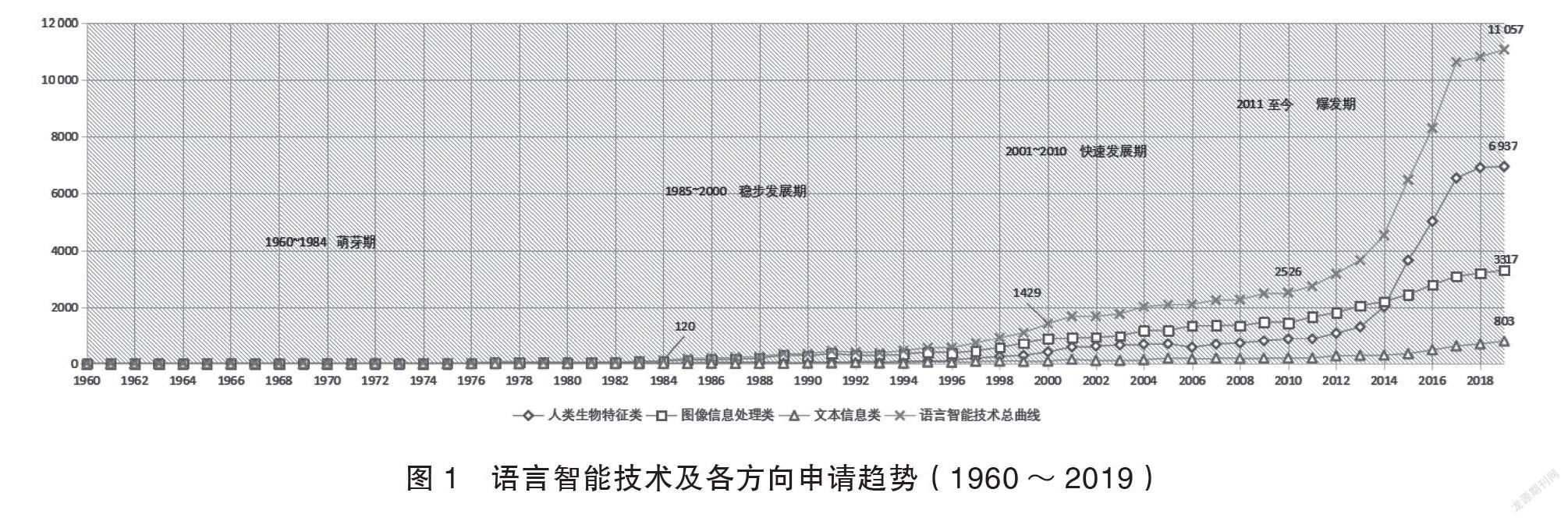
专利文献数据来源于Inspiro、incoPat平台,通过文献内容筛选及数量统计,可知:人类生物特征处理类(共计41 059件,其中G06K9/00分类共计22 612件,占比约55%,多是针对语言衍生数据、人工语言数据的技术创新)和图像信息处理类(共计40 387件,其中文字识别和G06K9/00分类共计3594件,占比约8.9%,多是针对语言学科数据、话语数据、人工语言数据的技术创新)的申请数量相当,各占比46%左右。语言文本信息处理技术类共计6347件,占比7.2%,多是针对语言学科数据、话语数据、语言代码数据的技术创新。将上述技术文献的历年申请情况按时间先后进行统计,呈现出的趋势如图1所示。
图1中,总曲线和3个方向技术的申请文献呈现出一定规律性趋势,同时三者之间也存在一定差异。按照总曲线趋势可简单进行如下阶段性划分。
(1)萌芽期(1960~1984)。自1960年起,每年3类处理技术均有少量的分布,申请量没有明显差距,總量维持在几十项的规模。人类生物特征处理、图像信息处理技术基本在同一阶段开始被关注。1965~1975年的10年间,生物特征识别技术受到重视;1977年后针对图像数据的内容对比、目标识别技术取得一定进展并引起了研究人员的持续关注。而文本符号处理技术发展一直相对滞后。1984年,语言智能技术专利单年申请量首次突破三位数,总曲线中出现了首个关键点,之后年份增速开始提升。
(2)稳步发展期(1985~2000)。该阶段内各方向申请量出现明显增加,增长速度较为稳定,2000年年底申请总量首次接近1500件/年,总曲线出现第二个关键点。图像信息处理受到了更多的关注,增长量较其他类明显,本阶段结束时该方向增长约6倍,研究重点由图像的内容对比转移到了基于图像内容的信息检索技术研究,其间自然场景下的文字符号识别技术开始受到关注。文本符号处理技术在该时期复苏,相较图像信息处理技术发展申请量上存在约15年差距,直到1999年申请量单年破百(图像信息处理1985年达到),此后关于文本符号的内容抽取技术受到更多青睐。
(3)快速发展期(2001~2010)。本阶段结束时,语言智能技术申请总量增加0.76倍,图像信息处理得到持续关注,图像内容检索技术、人类面部特征识别、文本内容结构化抽取、文本信息对比等技术点最为突出,增长趋势愈发明显。在快速发展期,围绕语言符号的智能问答技术申请开始出现,图像、文本内容分类的创新技术呈现较快发展。
(4)爆发期(2011年至今)。以深度学习为代表的人工智能技术快速发展,引起各类语言模型不同程度的发展和创新,对语言智能技术起到极大促进作用。该时期语言智能技术专利申请量呈井喷式增长,截至2019年年底,总量增长3.1倍,2015年后每年递增25%左右。2014年年底,人类生物特征处理和图像信息处理技术申请量首次持平,以生理特征智能识别为代表的生物处理技术快速突破,该类申请爆发,说明该阶段有较强研究力量投入该领域且创新成果显著。文本信息处理技术呈现技术点齐头并进、增长明显的态势,其中语言数据的关系抽取、实体识别技术等逐步成为研究核心,分析可知该时期围绕各类型语言数据开展了大量数据挖掘工作,进行了较好技术储备,为展开数据治理提供了基础。
由总曲线不难发现,近5年语言智能技术取得的进步是显著的,同时在发展过程中研究关注点也出现多次转移。参与本次分析的3类技术,在萌芽期数据相差不大,如今差异明显。以2019年专利申请量为例:人类生物特征处理6937件、图像处理3317件、文本处理803件,可以看出具有人类生物属性和图像符号属性的数据相比文字类抽象数据的显性特征更强,在技术创新方面率先取得突破。语言信息技术虽在2011年后得到显著发展,但较其他两类数据的处理技术申请量上仍有约15年的差距。依据总体趋势预判,未来较长一段时期语言智能技术仍处于技术爆发期,更具抽象特性的语言数据将会受到更多研究人员的关注。
(二)语言智能技术分布情况
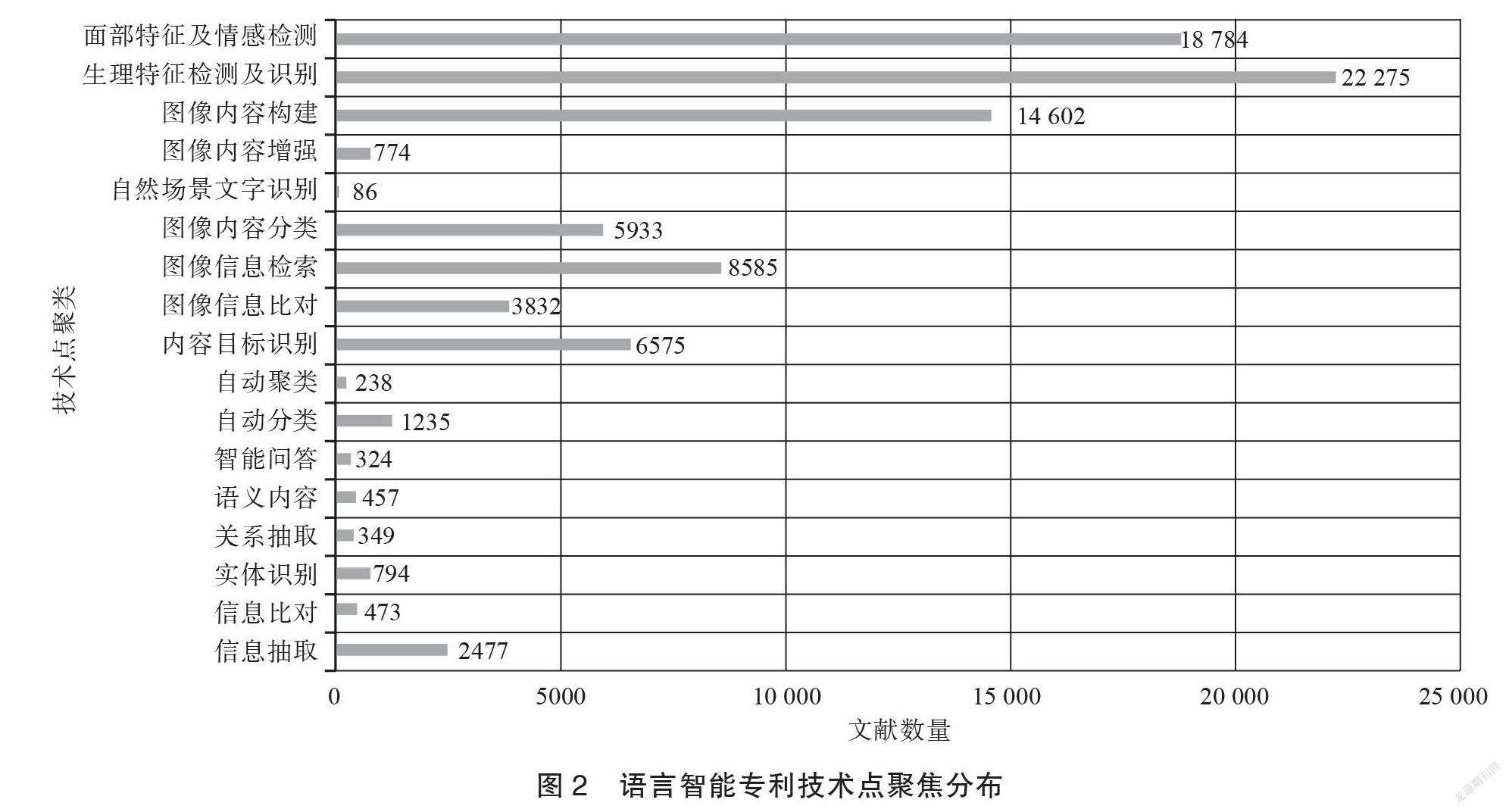
本研究共筛选出相关文献87 793件,按照技术方向进行聚类分析,形成技术点聚焦分布图。如图2所示,共形成17种技术聚焦点,其中人类生物特征类2种,图像信息处理类7种,语言信息类8种。
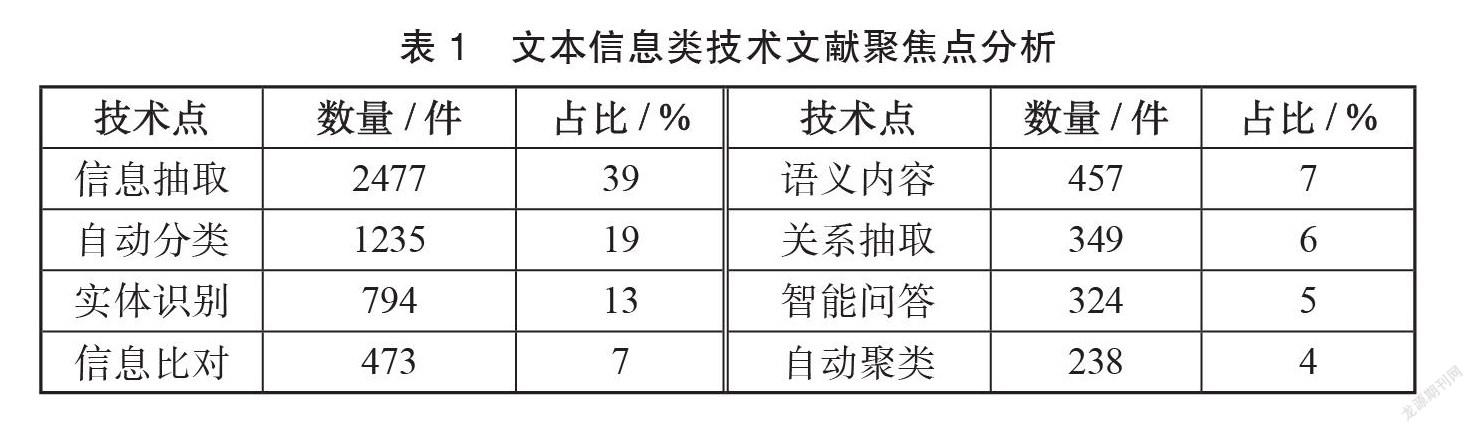
从申请量上看,文本符号信息技术文献量较其他两类存在较大差距,进一步观察此类技术的6347件文献并完成技术占比统计,具体结果见表1。
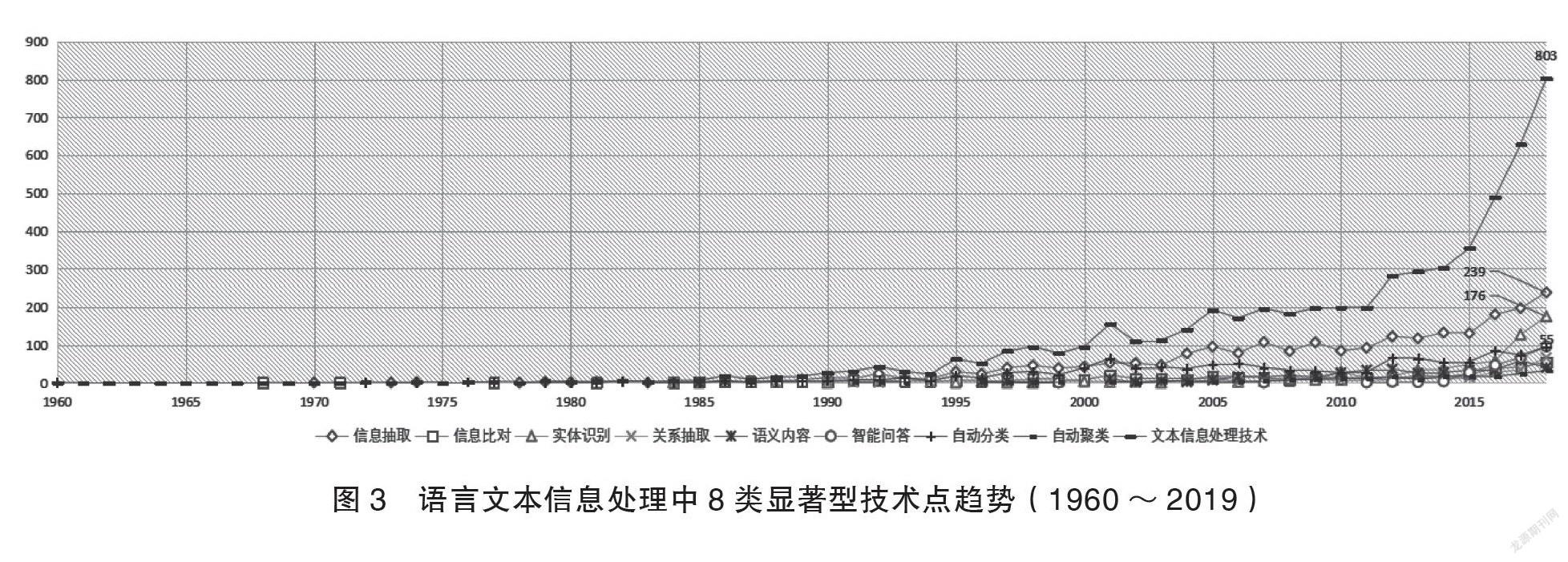
由表1可知,语言信息抽取(39%)是占比最大的细分领域,其次是自动分类(19%)和实体识别(13%),上述3类研究已有一定的技术储备,在开展语言符号的信息处理中已发挥重要作用。语义内容(7%)、关系抽取(6%)、智能问答(5%)等聚焦点近年来虽然一直是研究热点,但申请占比还不突出,由此来看,上述聚焦点距离业界实践应用还有一定距离,仍将是重点和难点研究方向。表1中8类显著型技术点发展趋势显示,上述技术点均在1990年后呈现增长态势(见图3)。1991~2010年的20年间,各技术点均得到快速发展,2011年后全球范围内语言信息技术专利申请量增速明显,其中语言信息抽取、实体识别技术最为突出,随着各行业中语言数据资产化进程的开展,上述两个方向仍将同步维持较高成果产出。
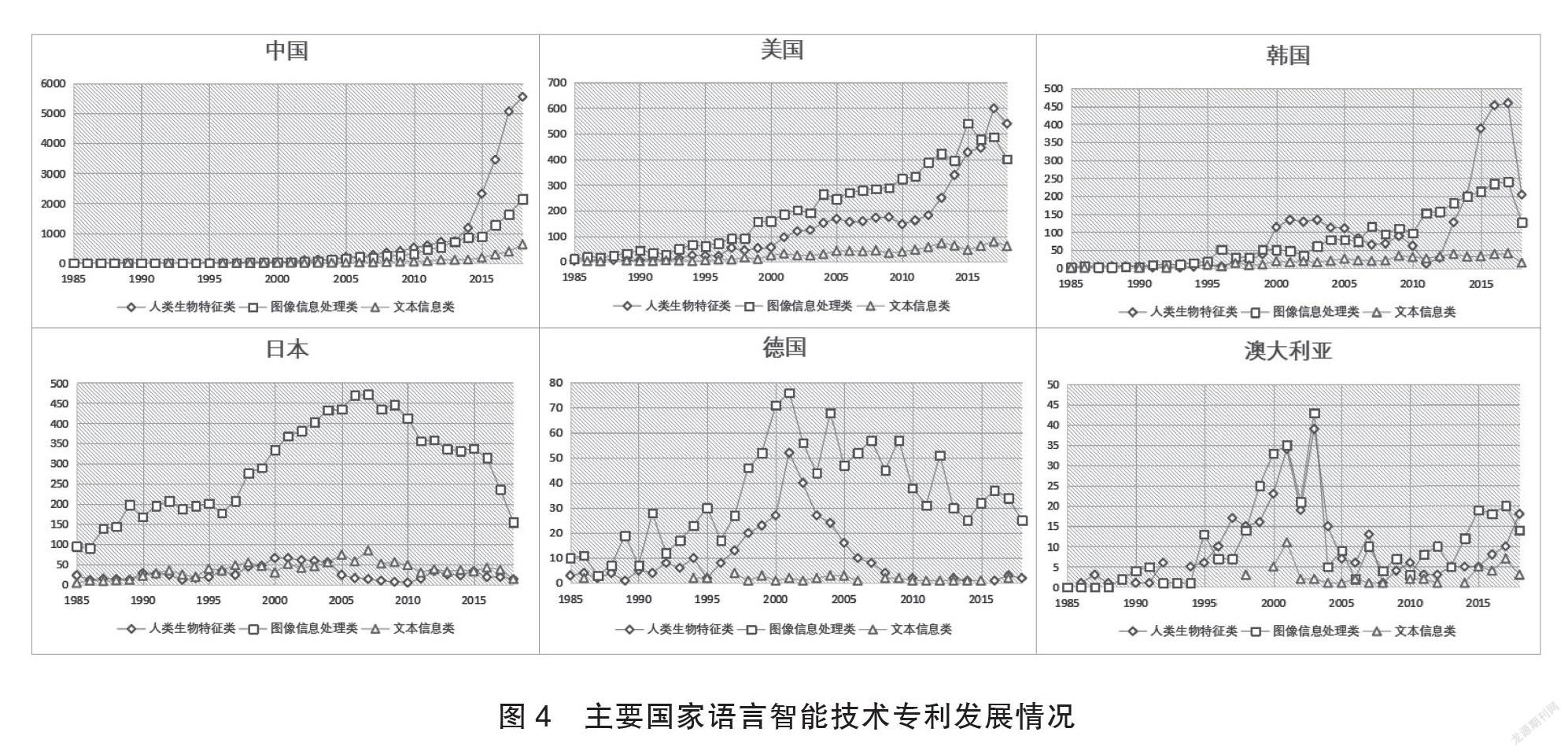
为分析全球主要国家语言智能技术发展情况,我们对文献数据按国别分别进行分类统计,形成各国趋势曲线(见图4)。这些图反映出各国的变化曲线呈现一定的差异。
从领域发展过程看,中国较美国、德国和日本等国技术起步较晚,到2005年后才出现明显增速,10年后中国在该领域的技术专利拥有量已处于领先位置。分析各国3条技术曲线趋势,美国、日本、德国和澳大利亚等国对图像信息处理更为关注,其中日本的该条曲线最为突出,中美韩在人类生物信息处理研究上具备一定的优势。在2005年前后,日本、德国和澳大利亚等国分别出现了曲线的下降拐点,可见此时期三国的研究焦点发生过转移,而中美两国的增长曲线相似,曲线分布较均衡,呈持续增长态势。通过上述六国各自3条技术曲线的分布情况不难发现,文本信息处理研究有较大的发展空间。
2013年,我国率先提出人工智能范畴下的“语言智能”概念,与全球该方向专利申请的爆发期基本吻合,体现我国研究人员对此方向的持续重视和创新,此概念的提出恰逢其时。语言智能研究既是对多模态信息处理技术的继承,也为计算智能和认知智能研究对象界定了范围,成为多领域、多模态信息技术交叉融合发展的重要方向。未来5~10年间语言智能发展仍处于技术爆发增长期,是学术研究、产业发展的重点布局方向。
二、语言数据治理现状及困境
数据具有生产要素性质,只有信息化发展到一定阶段才能成为现实,才能被人认识(李宇明2020)。在近10年语言智能技术爆发式发展的背景下,2020年李宇明发表《语言数据是信息时代的生产要素》一文,明确语言数据是生产要素,并纳入数字经济视野。本节对信息时代下的语言数据来源、内涵进行初探,并对智能技术赋能语言数据应用及语言数据治理面临的挑战进行梳理。
(一)从语言数据到语言数据治理
人类形成前自然界只有“物理空间”,人类诞生后产生了“社会空间”,语言与社会空间共同发展,演变出以语音为载体的口头语言。随着社会空间发展,人类利用光波特性研究出有声媒介,加速了语言信息传播,伴随互联网时代的到来,人类迈入“信息空间”。当语言数据成为发展经济和数字科技的核心要素,语言数据已经不仅仅是一种文化概念,它是“具有声光电三大媒介,为人类与机器两个‘物种’共享,将应用在社会、信息、物理三元空间中”(潘云鹤2019)的事物。我们作为智能时代语言数据的创造和使用者,更需要理解语言数据内涵,并认识语言数据的特性。
语言数据是以语言符号体系为基础构成的各种数据,按数据功能简单概括为:语言学科数据、话语数据、语言衍生数据、人工语言数据和语言代码数据(李宇明,王春辉2022)。语言数据属于数据范畴,天然拥有大数据的3个重要特性:“基因”的存储性、规律的蕴含性、趋势的预测性(周建设,等2014),同时也具有区别于大数据的语言特性,即物质性和动态性。物质性指语言数据必须借助一定的载体传播信息,如语音、文字、图片等媒介;动态性指语言数据在时间、空间维度上是动态的,如新型短视频、中长视频媒体的快速兴起和应用,古文字研究在今天依然活跃,体现出语言数据的时空延展性。抖音日活跃用户超6亿(截至2020年12月,2019年日活跃用户4亿),快手日处理数据量超过3EB,日入数据量超5PB(5120TB)。大规模的数据以场景多片段构成(时间)、分布式存储(空间)的结构,事件内容较传统单篇文件、单视频展示之间体现出明显的时序关系,用户关注度也随时间在转移。
语言数据治理对于确保语言数据的准确、适度分享和保护是至关重要的。关注语言数据质量,保障语言数据稳定性、准确性,将语言数据从混乱治理成为有序,已逐渐成为国内外研究热点。语言数据治理是将语言数据作为治理对象的数据治理,目标是为国家或组织发展提供基础性和战略性语言资源,促进语言数据资产的价值创造,提升语言服务和语言治理能力。语言数据治理涉及元数据构建、语言数据标准制定、语言数据安全建设、语言数据存储及语言智能服务等多方面。实现全流程的语言数据治理是个极其复杂、系统和长期的工程,本文重点关注语言数据治理中数据到知识的治理环节,未涉及安全、经济、控制与管理等内容。
(二)语言数据赋能语言智能技术的重要任务
语言智能的核心目标是研究人类语言与机器语言之间的同构关系,当前语言数据已赋能多种语言智能技术的应用场景。每次技术革新都带来专利申请曲线的波动,随后为社会带来更优质的语言智能服务,本节围绕机器翻译、智能客服、网络舆情、多语言资源建设等4个语言数据服务展开技术发展的趋势分析。
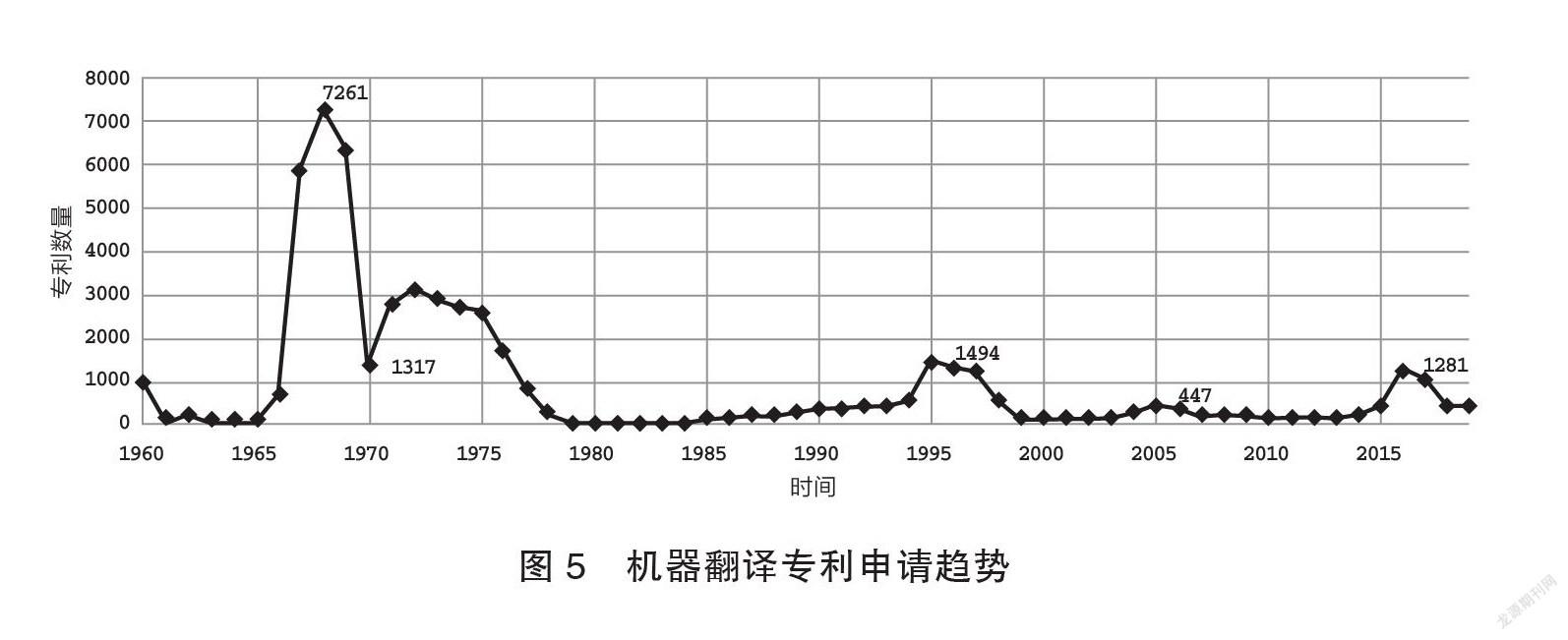
由图5可知,20世纪90年代前,机器翻译技术利用词典匹配技术(Blazevic 1977)实现,1968年出现申请峰值。而后是词典结合语言学知识的规则翻译(陈肇雄1997),1995年出现申请峰值。基于语料库的统计机器翻译(宋金平2004)取得较大进步,2005年出现了申请峰值。随着运算能力提高和多语资源的增长,神经网络文本翻译(Li & Liu 2020)取得了明显成效,2016年出现了申请峰值。但实时语音翻译或自动同声传译还面临很大挑战,语篇如论文、小说等文体翻译时,术语一致性问题对模型可理解性提出了更高要求。
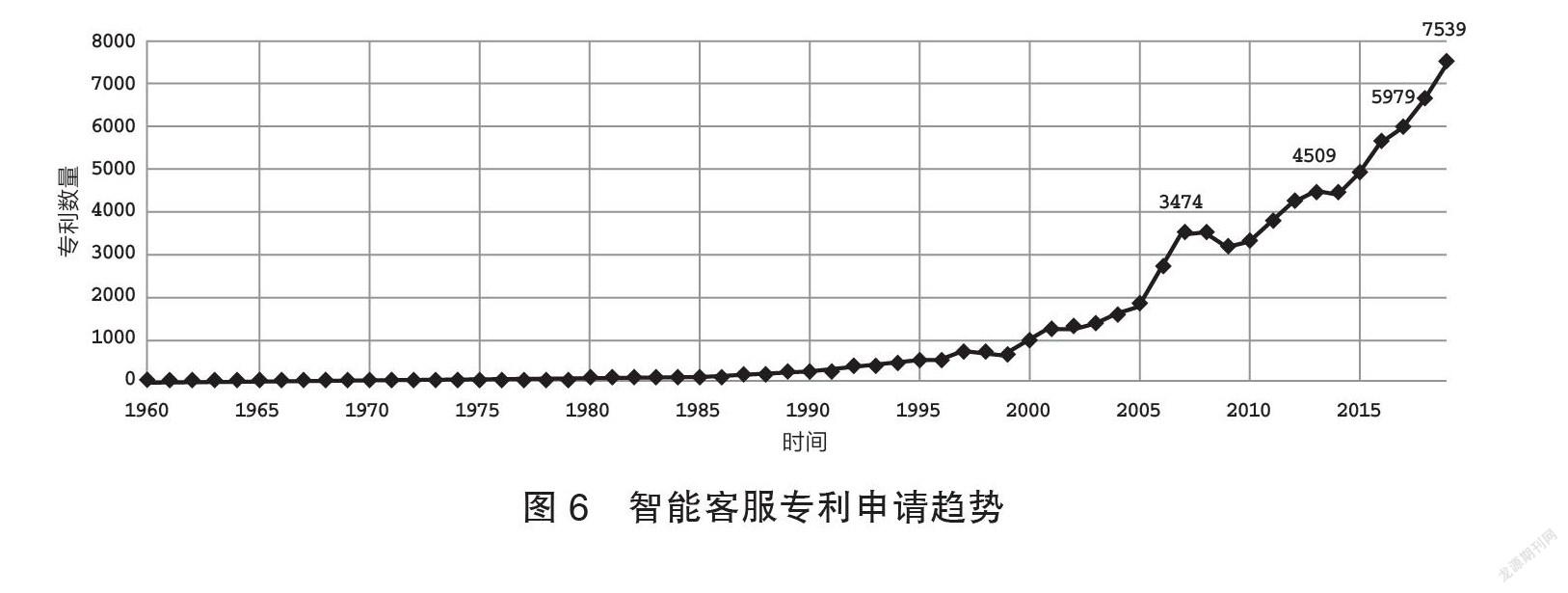
由圖6可知,智能客服技术起步较晚但呈现申请量快速增长趋势。其应用形式上有聊天(Miyashita 2002;杨敏,等2008)、问答(Horvitz 2002;杨海松,等2006)、任务式对话(田春霖,王翔2019;赵丙来,许文轩2021)等,涉及语音识别、语义理解、对话状态追踪、语言生成、对话心理等技术,因对话生成缺乏源语言语义约束,涉及问题的复杂程度没有任何限制。闲聊对话和以领域性知识图谱为中心的跨领域、跨交互形式的知性会话系统(黄民烈,马文畅2021)成为当前热点。
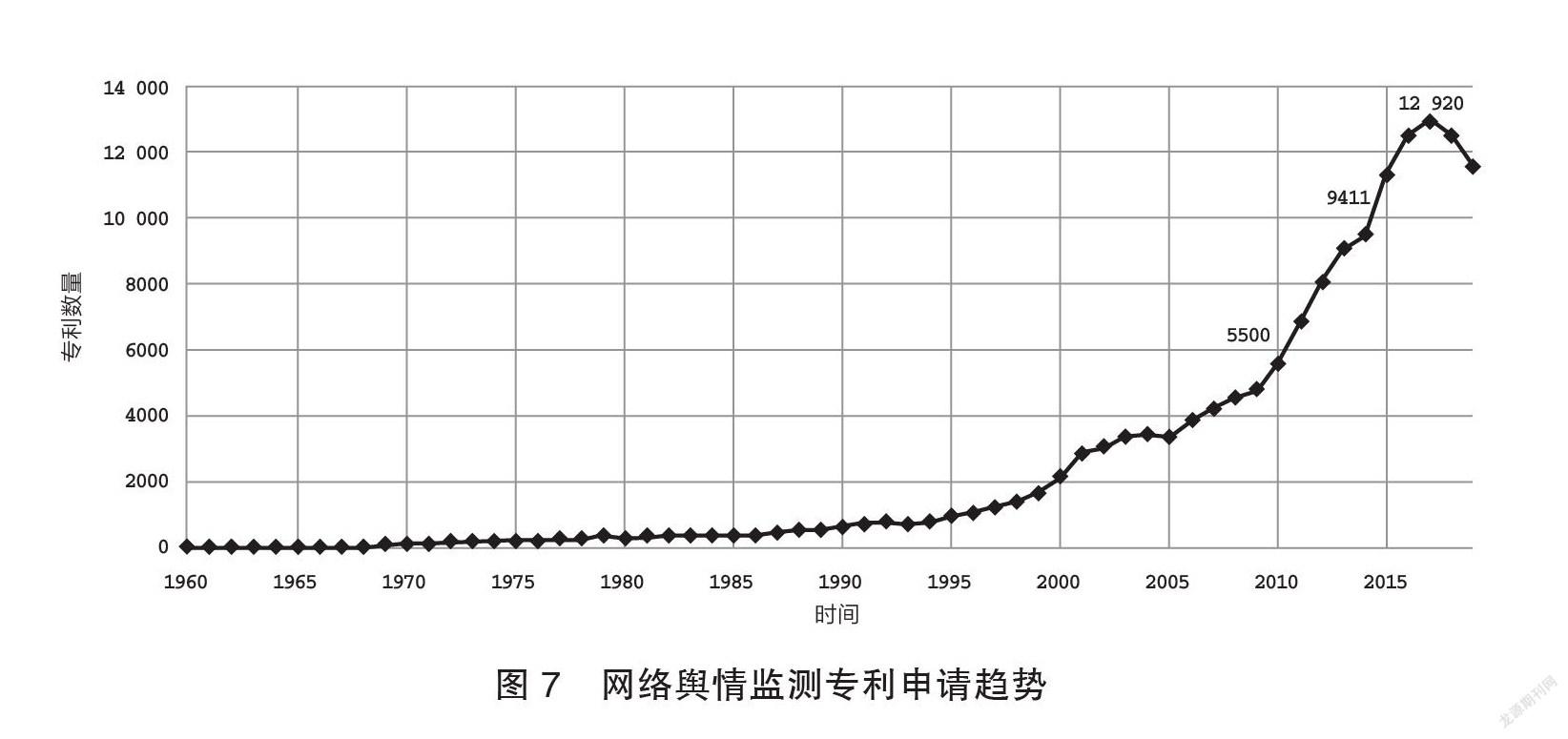
由图7可知,网络舆情监测相较其他语言服务专利申请规模更大,体现出各国对这方面的高度重视。早期监测策略通常由“关键词”搭配基本逻辑符号进行语言数据检索(Belagodu et al. 2013),往往需要辅以大量的人工,对语言数据进行二次处理。语言智能技术则让舆情监测从信息检索走向内容多维度识别(张黎娜,等2020),并通过情感分析(仁庆道尔吉,等2021)获取明确情感、立场、观点、态度、意图等敏感信息,提高了语言数据背后隐含意图和倾向信息理解的准确性。网络舆情监测正在通过事理图谱、热点聚类、文本分类等方法,向舆情事件延展、事件特征、风险等级等智能分析阶段发展。
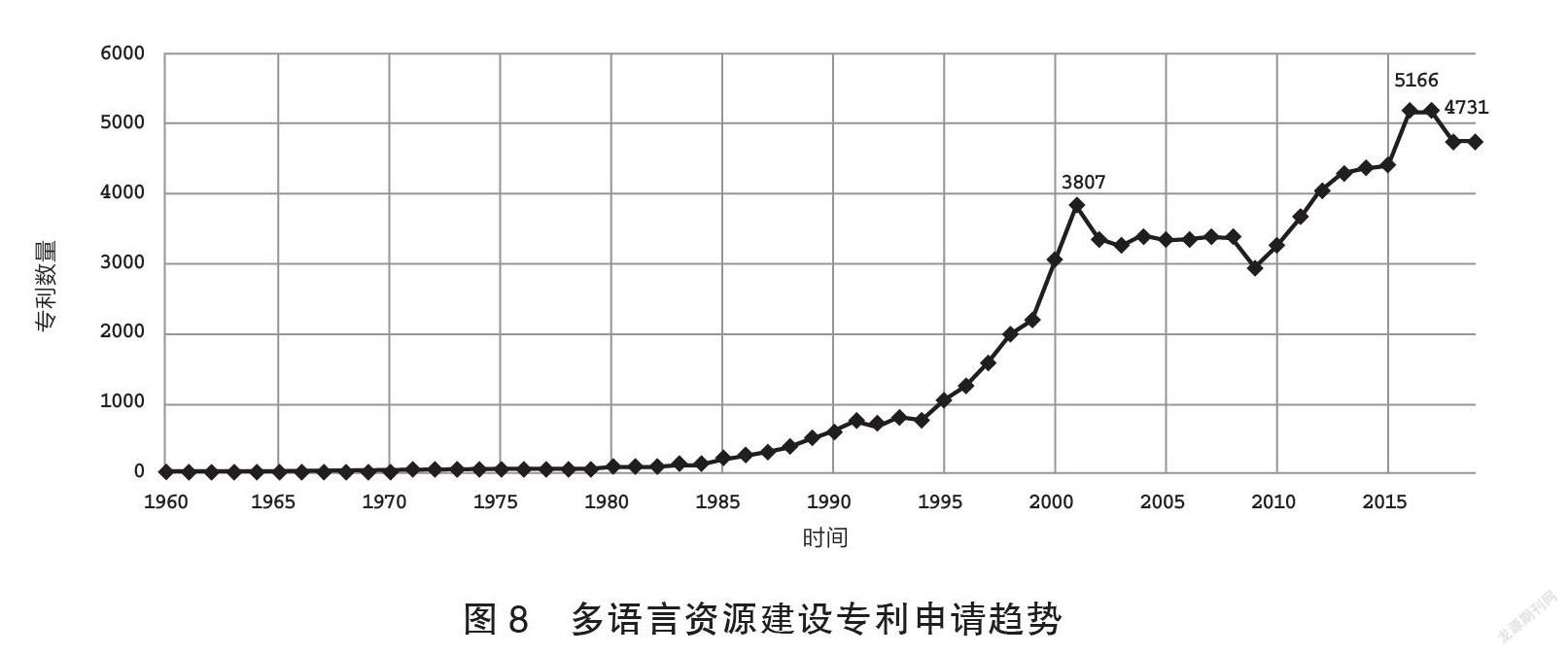
由图8可知,在2000年前的资源构建中多以语言本体数据为对象,构建各语种知识本体、叙词本体词网等(Torrence 1979),之后围绕民族语言资源(姚聪,等2015)、话题发现和舆论导向(曾倬颖,张权2017)等方面的研究成为一种趋势。2015年后,围绕语义标注、资源保护、语言模型和智能评测(胡韧奋,等2021)等技术研发成为新方向。近年来,以古文字为对象的专利开始出现,如多特征融合技术的拓片资源保护(陈善雄,等2019;高未泽,等2020;肖旭东,等2021)、古籍汉字可视化识别、文本挖掘的古籍数字化(毛建军2006)、古籍汉字图像质量提升(宋传鸣,等2021;李邦,等2021)、古籍词语发现(杨存耿,等2016;谢昱,等2019)和古籍知识库构建(徐小力,等2016)。
(三)语言数据治理面临的挑战
“语言文字智治现代化”(王春辉2020)将语言智能技术与语言数据治理密切关联,充分运用语言信息化手段,发展和运用语言智能,利用语言智能来集成信息、发布信息、共享信息、保证信息安全等(李宇明,王海兰2020),是进行语言数据治理的必经之路。优质、安全和高效的语言数据应用及服务是语言数据治理的目标,治理工作的开展受到政策、经济、文化、技术等多方面因素影响,本节从数据质量本身及其数据治理模式两方面总结语言治理工作面临的突出难题。
1.语言数据的偏见现象
机器学习的基本原理是根据已有的训练数据推导出能够描述出“经验”的模型,并根据得出的模型实现对未知的测试数据的最优预测。受机器学习原理和技术特征的影响,其决策结果会产生一定偏见,如简历筛选系统会依据应聘者无法控制的特质(性别、种族等)做出带有歧视的筛选。语言数据偏见产生的原因较为复杂,在机器学习的生命周期中包含了数据采集、算法训练、人机交互等多个环节,这其中每个阶段都会存在一定的偏见。
第一,来源于语言数据本身的偏见。包括:(1)地域偏见,不同的地域文化和社会习俗等会渗透到语言数据中,影响机器决策并产生偏见。(2)群体偏见,语言数据采集者容易主观性代表部分群体的特征属性,而此特征属性与应用目标群体存在的差异,容易产生偏见现象。这类型偏见同时会产生观察者偏差和联想偏差,即无意间在语言数据标注时加强了研究者本身的主观意见,造成数据噪音(Suresh &Guttag 2019)。(3)测量偏差,当前机器学习算法都基于大量语言数据进行运算,在收集数据时,使用不同的数据采集工具或者使用观点不统一的语言数据标记规范,最终会导致数据产生大量噪音,测量产生偏差(Olteanu et al. 2019)。(4)表示偏见,当数据采集时没有充分覆盖目标群体的特征,某些样本的特性并未得到充分表示,这种代表性不足的数据表征在运算中也会加剧偏见现象。
第二是来源于智能技术的偏见。包括:(1)算法偏见,机器学习的特性就是捕捉大数据中的经验规律,同时也会极大程度上忽略少数群体在训练过程中的权重,导致其不能完全代表目标群体,由此产生算法决策偏见。(2)排名偏见,基于协同过滤技术的智能推荐系统,其背后利用了人类的认知架构,对用户语言属性(历史行为、相关偏好等)进行挖掘,并且依据使用者习惯和喜好进行优先级排序,排名靠前则会极大程度上吸引关注度(Buolamwini&Gebru 2018)。(3)变量偏差,当进行模型设计时未能完整考虑到影响模型的重要变量,模型预测会产生一定偏差(Schmitz et al. 2022)。
第三是来源于人机交互的偏见。包括:(1)交互偏见,在不同社交平台和应用场下不同群体的交互行为会存在偏差,如“微信”和“淘宝”这两类软件的交互手段存在差异。此外,信息呈现的方式也同样影响交互效果(Olteanu et al. 2019)。(2)内容偏见,一个人居住在不同地域、处于不同群体、担当不同角色所使用的语言内容都具有本质的差别,当进行一定语言习惯转换时所产生的内容结构、语法、语义等误差,被认为是内容偏见(Olteanu et al. 2019)。
本节对语言数据偏见现象产生原因进行了粗略归纳,以期了解在语言智能技术发展的环境下所产生的偏见现象。存在偏差的语言数据影响语言数据质量,不良数据将持续加重智能技术的不公平现象。
2.经典语言治理模型的短板
数据挖掘的目的是从大数据中发现“有趣知识”,根据任务不同可分为概念描述、关联相关、分类和预测、聚类分析、离群点和演变分析等经典数据挖掘模式(图2及表1中含有相关的基础技术)。经典模式下,首先会将待解决的数据治理问题转化成正确的数据挖掘任务,然后根据任务选择某种或几种挖掘模式(Han et al. 2012)。經典挖掘模式具有一定的普遍性,在行业应用中受到广泛关注,但在服务于语言数据治理时,将会面临如下难题。
第一,传统方法不适用。以业务为导向的数据挖掘标准体系忽视了语言数据自身的特性。经典数据挖掘模式已在金融、医疗、司法、零售、制造、保险等行业广泛应用,其中也多有语言数据参与,但其核心目标是为领域业务服务。语言数据除具备一般数据特征外,还有其自身的内涵与规律。当传统数据挖掘方法面临特殊的语言数据信息,以业务为导向的治理模式并不能适用。
第二,知识获取不充分。语言数据仅是知识获取的渠道之一,但在网络空间中,语言信息资源、语种语类资源的建设、管理和利用都很不充分。社交网络源生语言资源粗放杂乱,不仅造成了数据冗余,而且导致语言优质资源的通行度下降,降低了信息检索的服务质量,以致产生了现在“语言数据丰富,但语言知识贫乏”的现象。
经典数据挖掘模式能力不足、语言智能技术仍存在瓶颈、语言数据对资源依赖性更高,决定了若要在语言数据治理的国际竞争中取得主动权,必须双管齐下:既要关注语言数据的数量与质量(降低对其他资源过度依赖和知识挖掘难度),也要重视治理模式的优化与创新(提升语言知识获取和治理模式通用的能力)。在当前信息基础设施相对完善而算法工具不变的条件下,模式问题已成为矛盾的主要方面,也是世界各国面临的普遍难题。
三、语言数据治理的技术模式
科学合理构建语言数据治理模式可有效应对挑战,对语言数据资源和智能技术的发展均有裨益。其一,语言数据作为重要的生产要素,开展治理研究对于确保数据准确(解决语言符号的知识表达问题)、知识发现(解决语言符号的知识计算问题)、适度分享和保护(解决语言符号的知识传播与保护问题)至关重要。其二,清晰、有效的语言数据治理需求和场景,可推动语言智能技术良性发展,不断积累的语言数据治理经验要求技术模式的规范化和标准化。本节重点探讨并设计语言数据治理的点状聚合、线性组合和多层事态语言模式。
有效的语言数据治理框架会通过优化模式、缩减计算成本、降低舆情风险和提高安全合规等方式,将语言数据(知识)价值优质、高效回馈于应用,最终服务于语言文字事业发展。本节在语言智能技术的背景下,以经典数据挖掘模式为基础,就现有语言数据治理模式组织归纳,提出点状聚合模式、线性组合模式和多层事态等语言模式。3类语言数据治理的模式对应不同的场景或语言数据任务,分别围绕语言数据不同层次展开技术构建。
点状聚合模式(单点)以语言符号中的词性(如名词)为关注点,围绕实体词,以属性为桥梁,通过实体点聚合,构建一个空间知识体系,目标是构成结构化的语义知识库。计算机数据结构上对应的是有向图结构,呈现<实体,关系,实体>的点状聚合特点,其中实体由<属性,值>构成,实体间通过属性关系进行关联。该模式围绕实体点构成语言符号的知识结构,存储于图数据库中。点状聚合模式的知识结构是对现有语义网的扩充,对语言数据做行业细分,以单个术语为实体,在经典数据挖掘模式基础上,结合语言资源特点可以构建出细分行业语义库。该模式体现出语言数据“基因”的存储性和规律的蕴含性特征。
线性组合模式(交互)以语言符号中事件关系为关注点(如谓词逻辑),目标是构建出结构化的事件组合场景,该模式的中心点持续围绕谓词变化而转移,通过场景切换形成具有一定概率的事件组合库。计算机数据结构上对应的是具有概率属性的有向图结构,呈现出<事件,关系,事件>的线性组合特点,其中事件由<属性,概率>构成,事件间通过事件关系进行关联。该模式围绕事件序列构成语言符号的知识结构并存储于图数据库中,模式的发展通过事件转移矩阵确定趋势方向。该模式体现出语言数据的趋势预测性。
多层事态模式(事态)以语言符号整体为着眼点,化形于现实世界,通过追踪语言符号的事态变化,形成具有特定场景的、具有语义完备性的多层事态模式,该模式的目标是形成个体化语义场景描述的数据结构。计算机数据结构上对应复杂网络结构,形成<实体,知识图谱,事态,事件,事理图谱>结构的多层形态,其中事态即事件的状态,指表示事件发生与否、出现与否、存在与否。事态与动态两者着眼点不同,动态关注的是谓词所表示的动作变化,通过时态或状态体现,事态关注的是句子所表示的事件状态,由事态语气或时间状态体现。多层事态模式体现出语言数据的时序和空间的延展性。
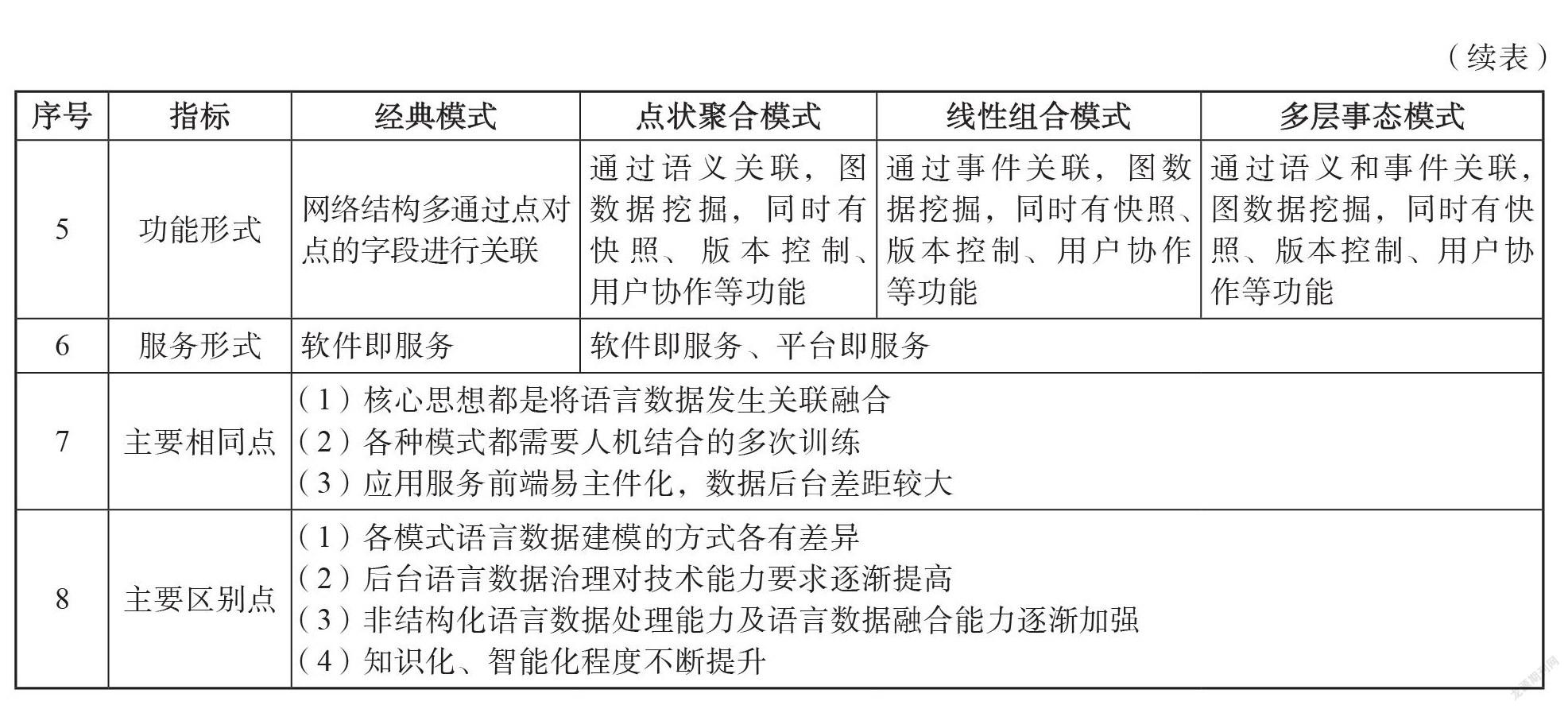
结合经典数据挖掘模式,我们对点状聚合、线性组合和多层事态治理模式的各自特点分别进行多维度对照分析,详见表3。在具体的语言数据治理任务中,可根据不同的治理目标采取某种或几种模式。
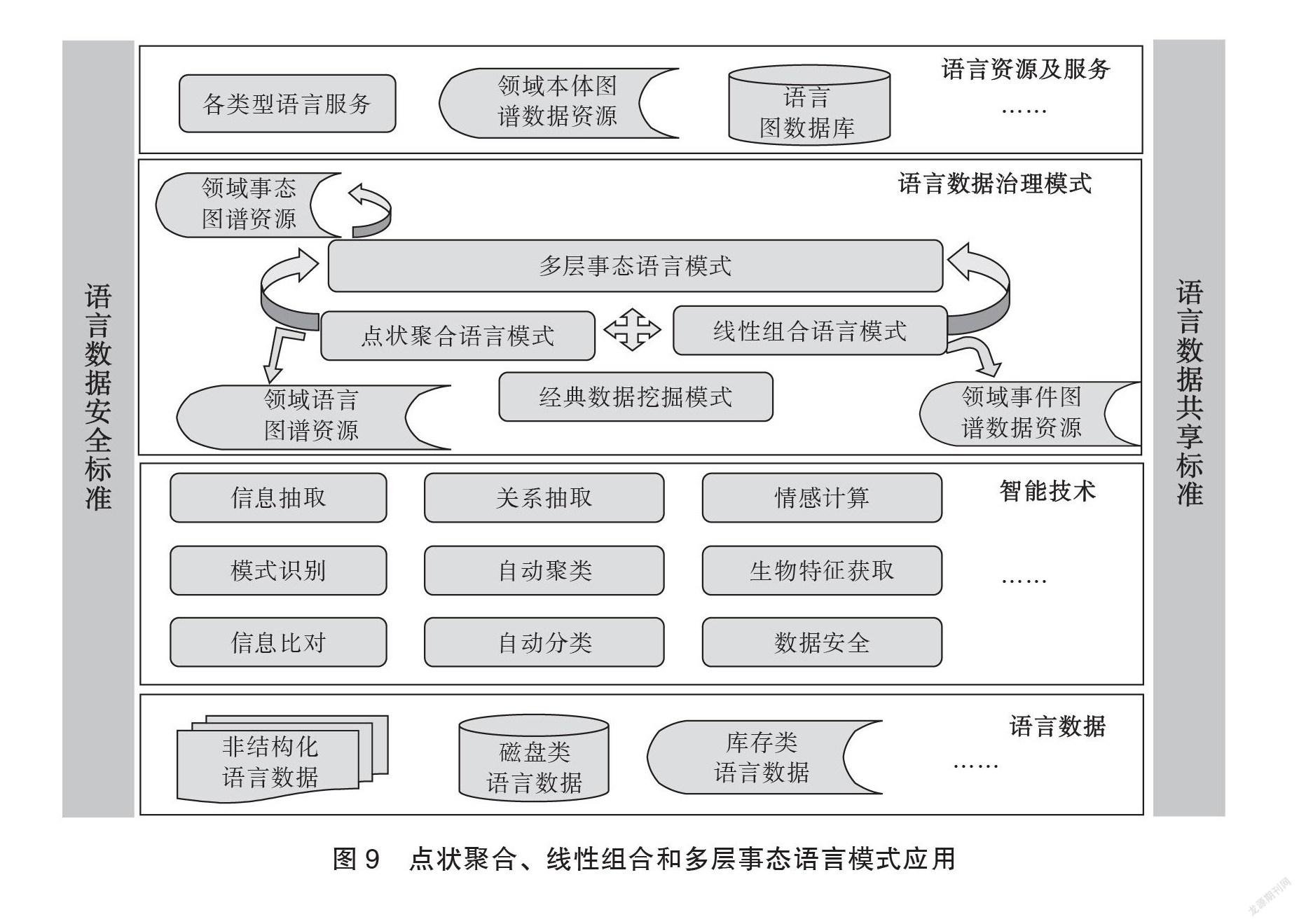
在语言数据安全和共享标准支持下,我们结合语言数据资源构建流程,展示本文设计的3种语言模式的联系,共同为语言资源和服务建设提供支撑,详见图9。智能化条件下语言数据治理的核心思想是语言数据间的关联融合,所有模式均需要进行“人-机”结合的多次模型训练,以期达到最佳的治理效果。虽然语言数据由于自身蕴含特征规律的表现形式不同,造成语言数据治理模式的差异化,但建立在治理模式上的语言数据应用服务却容易形成相对稳定的结构。随着上述模式结构的复杂性增加,对语言数据治理的基础技术能力要求也逐渐提高。
四、结 语
语言智能技术是科技创新的重要动力和源泉,围绕语音识别、人机对话、机器翻译、多模态语义分析技术所衍生的新兴业态,已由实验阶段走向市场应用。本文通过对近60年语言智能技术专利文献进行挖掘,就技术发展趋势及布局变迁进行总结,探索了技术发展的规律和成熟度,为展开语言数据治理提供技术储备。依据专利热点分析技术赋能语言数据服务的最新趋势并归纳语言数据治理面临的技术挑战。为应对技术挑战,弥补经典数据挖掘模式的不足,本文提出了语言数据治理的3种语言模式并展开应用分析。语言数据是对象,语言智能技术是手段,语言模式是方法,语言治理是目的,本文厘清语言智能技术整体发展和未来趋势,探讨了语言数据治理中存在的技术难题并探索性地提出语言数据治理模式,以期为智能化数据治理提供参考。
参考文献
陈善雄,莫伯峰,高未泽,等 2019 一种基于局部CNN框架的甲骨拓片分類方法,中国:CN201910917806.X,2019-09-26。
陈肇雄 1997 机器翻译中的复杂上下文相关处理方法,中国:CN97111944.9,1997-07-02。
高未泽,田瑶琳,陈善雄,等 2020 基于曲线轮廓匹配的甲骨拓片缀合方法,中国:CN202010191701.3,2020-03-18。
胡韧奋,王予沛,彭一平,等 2021 一种汉语二语作文自动评分方法,中国:CN202110896135.0,2021-08-05。
黄民烈,马文畅 2021 基于知识图谱的智能对话推荐方法及装置,中国:CN202110426610.8,2021-04-20。
李 邦,张 展,郭 安,等 2021 基于生成对抗网络的甲骨片轮廓与字符痕迹自动提取方法,中国:CN202110888155.3,2021-11-02。
李宇明 2020 《语言数据是信息时代的生产要素》,《光明日报》7月4日第12版。
李宇明,王春辉 2022 《从数据到语言数据》,《语言战略研究》第4期。
李宇明,王海兰 2020 《粤港澳大湾区的四大基本语言建设》,《语言战略研究》第5期。
毛建军 2006 《古籍数字化概念的形成过程探析》,《科技情报开发与经济》第22期。
潘云鹤 2019 《“人工智能2.0”与数字经济》,《杭州科技》第5期。
仁庆道尔吉,尹玉娟,麻泽蕊,等 2021 一种基于多尺寸CNN和LSTM模型的蒙古语文本情感分析方法,中国:CN202110533016.9,2021-05-17。
宋传鸣,王一琦,何熠辉,等 2021 LM滤波器组引导纹理特征自主学习的甲骨文字检测方法,中国:CN202110900543.9,2021-11-19。
宋金平 2004 基于语言知识库的机器翻译方法与装置,中国:CN200410001187.3,2004-02-04。
田春霖,王 翔 2019 面向任务式对话系统意图识别的语料库生成方法和装置,中国:CN201910163098.5,2019-03-05。
王春辉 2020 《关于语言文字治理现代化的若干思考》,《语言战略研究》第6期。
肖旭东,李 勇,乔 丹,等 2021 一种喷丸覆盖率的拓印测量方法,中国:CN202110864413.4,2021-11-12。
谢 昱,江 路,林金瑞,等 2019 一种多功能信息化古籍书影管理平台及方法,中国:CN201910509035.0,2019-06-13。
徐小力,吴国新,王红军,等 2016 一种东巴经典古籍数字化释读库的建立方法,中国:CN201610304529.1,2016-05-10。
杨存耿,谢术清,杨晓强,等 2016 一种SaaS古籍知识服务云平台,中国:CN201621020211.2,2016-08-31。
杨尔弘,刘鹏远,韩林涛,等 2018 《语言智能那些事儿》,载国家语言文字工作委员会组编《中国语言生活状况报告(2018)》,北京:商务印书馆。
杨海松,邓大付,余祥鑫,等 2006 自动问答方法及系统,中国:CN200610059919.3,2006-02-28。
杨 敏,迟长燕,肖文鹏,等 2008 保持聊天记录和聊天内容的对应关系的设备和方法,中国:CN200810127448.4,2008-06-30。
杨文珍,吴新丽,宣建强,等 2017 一种汉文到盲文的自动高效翻译转换方法,中国:CN201710550659.8,2017-07-07。
姚 聪,周舒畅,周昕宇,等 2015 基于图像的语种识别方法及装置,中国: CN201510520119.6,2015-08-21。
张黎娜,钱 婧,袁 磊,等 2020 文本内容识别和违规广告识别方法、装置及电子设备,中国:CN202011044853.7,2020-09-28。
张 引,陈琴菲 2019 一种多特征融合的古今汉语自动翻译方法,中国:CN201910033155.8,2019-01-14。
趙丙来,许文轩 2021 基于语义规则的心理知识与方法推荐系统,中国:CN202110882966.2,2021-08-02。
曾倬穎,张 权 2017 网络舆情态势的安全评估方法、终端及计算机存储介质,中国:CN201710595532.8,2017-07-20。
周建设 2020 《加快科技创新 攻关语言智能》,《人民日报》12月21日第19版。
周建设,吕学强,史金生,等 2017 《语言智能研究渐成热点》,《中国社会科学报》2月7日第003版。
周建设,彭 琰,张 跃,等 2014 《基于大数据的汉语表达智能模型及其理论基础》,《首都师范大学学报(社会科学版)》第5期。
Han, J. W., M. Kamber& J. Pei. 2012. 《数据挖掘概念与技术》,范明,孟小峰译,北京:机械工业出版社。
Belagodu, A., N. Dittakavi& V. Ganti. Data retrieval system. USA: US14010477, 2013-08-26.
Blazevic, M. 1977. Device for automatically recording, reproducing and translating, a magnetic transducer. USA: US05/768563, 1977-02-14.
Buolamwini, J. & T. Gebru. 2018. Gender shades: Intersectional accuracy disparities in commercial gender classification. , 77–91.
Horvitz, E. J. 2002. System and methods for inferring informational goals and preferred level of detail of results in response to questions posed to an automated information-retrieval or question-answering service. USA: US10185150, 2002-06-28.
Li, Y. H. & B. Y. Liu. 2020. Method and apparatus for processing word vector of neural machine translation model, and non-transitory computer-readable recording medium. USA: US16809844, 2020-03-05.
Miyashita, K. 2002. Chat system displaying a link arrow directed from a hyperlink to content of an associated attachment file. USA: US10314226, 2002-12-09.
Olteanu, A., C. Castillo, F. Diaz, et al. 2019. Social data: Biases, methodological pitfalls, and ethical boundaries. 2. Accessed at https://www.microsoft.com/en-us/research/wp-content/uploads/2017/03/SSRN-id2886526.pdf.
Schmitz, M., R. Ahmed & J. Cao. 2022. Bias and fairness on multimodal emotion detection algorithms. arXiv preprint arXiv: 2205.08383.
Suresh, H. & J. V. Guttag. 2019. A framework for understanding unintended consequences of machine learning. arXiv preprint arXiv: 1901.10002.
Torrence, K. R. 1979. Method and apparatus for compensation during ultrasound examination. USA: US06/072717, 1979-09-04.
责任编辑:韩 畅
各国专利文献主要包括专利申请书、说明书、公报、文摘、索引等各种官方文件和官方出版物,既包含与发明创造的研究、设计、开发和试验成果相关的技术性资料,也包含与权利授予、权利变更、权利保护相关的法律性资料,本文分析中以专利文件和技术性资料为主。
因专利文献公开有条件限制,在准备本文时,部分文献未公开,或因本文设计查询分析中存在一定技术性遗漏,所以实际文献数可能大于分析文献数,但对文中各统计结果与整体趋势分析影响不大。
本文专利数据收集范围包括中国(CN)、美国(US)、日本(JP)、德国(DE)、英国(GB)、法国(FR)、瑞士(CH)、韩国(KR)、欧洲专利局(EP)和世界知识产权局(WIPO)等100多个国家或地区、机构的专利文摘数据,辅以其他非专利文献资料。
Inspiro是国内首个整合了全球及中国专利、商标、版权、地理标志、植物新品种、集成电路、知识产权法律文书、标准、科技期刊和企业商情等知识产权大数据资源的创新情报平台,最新嵌入外观设计和商标图像智能检索功能。incoPat是全球首个面向华语研发创新人员的专利情报平台,提供及时、全面、准确的情报信息,帮助跟踪最新的技术发展,规避专利侵权风险,掌握竞争对手的研发动态,实现知识产权的商业价值。
G06K9/00分类与语言数据处理相关,是表示用于阅读、识别印刷、书写字符或识别图形的国际专利分类号。
这里采纳李宇明、王春辉(2022)中语言数据的5种分类。
参见《2020年抖音数据分析报告》,https://wenku.baidu.com/view/78c448881937f111f18583d049649b6648d70988.html。
參见中华人民共和国国家标准《信息技术服务 治理 第5部分:数据治理规范》(GB/T 34960.5—2018)。
不局限于常规语种,出现了如汉语到盲文(杨文珍,等2017)、古今汉语(张引,陈琴菲2019)等互译。
“语言文字智治现代化”涉及两个层面:其一,提升针对语言数据的治理体系和治理能力现代化;其二,利用数字化和智能化的便利条件来提升语言治理的现代化水平。参见王春辉(2020)。
见二(一)中有关语言数据的特性分析。
