
基于位标识的可擦写高效过滤器算法与实现
2022-08-25 09:56肖文超高佳宁廖雪花
软件导刊 2022年8期
雷 蒙,肖文超,高佳宁,廖雪花
(1.四川师范大学计算机科学学院;2.四川师范大学物理与电子工程学院,四川成都 610101)
0 引言
传统应用开发会直接从数据库读取数据,大数据环境下,高并发请求频繁地访问磁盘操作数据[1],会导致系统卡顿等严重问题,成为整个应用系统的性能瓶颈。为缓解数据库访问压力,减少频繁地读写操作,通常会选择在业务与数据库之间加入一层缓存。
高并发场景下,若某个无效key 被高并发访问且没有命中,出于对容错性的考虑,会去数据库中获取,导致数据库执行了大量不必要的查询操作,从而带给数据库巨大冲击与压力。解决此类缓存击穿问题的传统思路为利用HashTable[2],但需要耗费大量资源,成本太高。目前流行的解决方式是采用布隆过滤器(Bloom Filter,BF)[3-4]。通常对于数据库中数据的key 值,可以将其预先存储在布隆过滤器中,然后在布隆过滤器中进行过滤。如果发现布隆过滤器中没有,就去缓存服务(如redis)中查询,如果缓存服务(如redis)中也没有数据,就再去数据库查询,这样可以避免不存在的数据信息也到存储库中进行查询的情况。

Table 1 Test environment configuration表1 测试环境配置
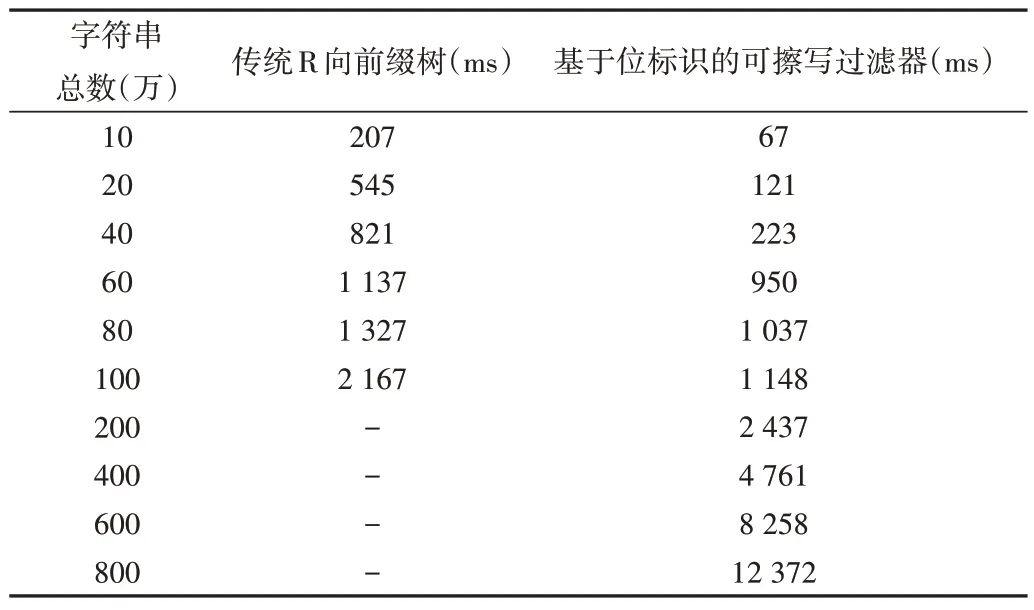
Table 2 Comparison of construction(insertion)time of different numbers of strings表2 不同数目字符串构建(插入)时间比较

Table 3 Comparison of index time of different numbers of strings表3 不同数目字符串索引时间比较
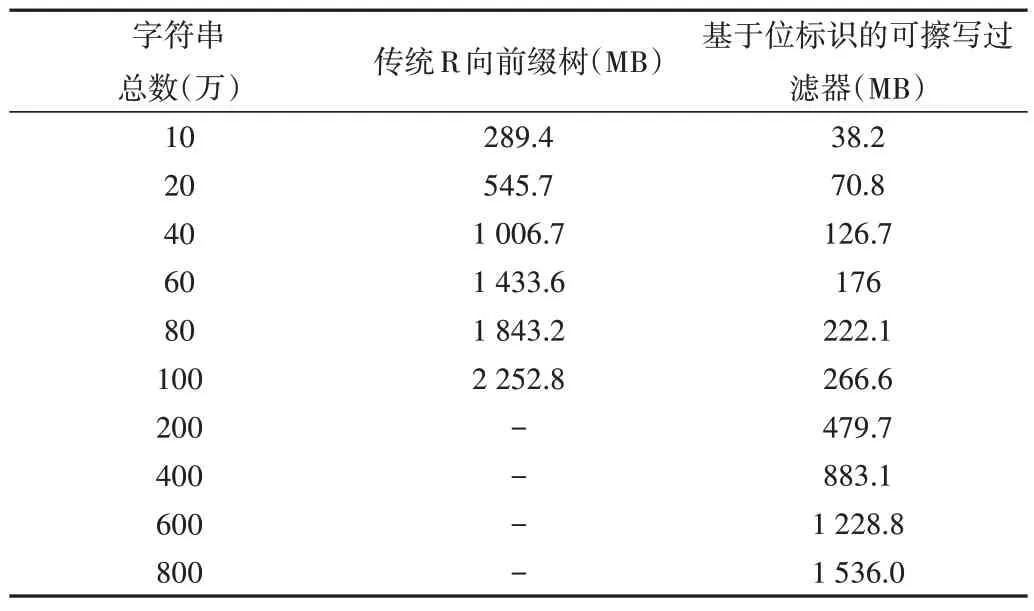
Table 4 Comparison of memory space of different numbers of strings表4 不同数目字符串内存空间比较
布隆过滤器可以高效查询元素是否在指定集合中,目前已广泛应用于元素查询[5-7]。利用布隆过滤器可以快速过滤不相干的数据,减少不必要的I/O 开销,提高系统读取性能。布隆过滤器在识别邮件黑名单、过滤重复资源的效率上有一定优势,同时因其在同等数量级下占用内存小、查找效率高而得以广泛应用。
本文提出一种新型的基于位标识的可擦写高效过滤器算法,采用改进后的前缀树[8-9]作为基本结构,将传统树结构中的字符改进为位(bit)数组存储,并动态构建过滤器。相较于传统的布隆过滤器,在保证查询效率以及占用尽可能少的内存空间基础上,具备了可擦写特性,由于前缀树自身结构支持删除操作,因此改进后的布隆过滤器可以便捷地完成删除操作从而实现0 误判率,能够更好地应用于高并发场景下的系统开发。
1 相关工作
布隆过滤器自巴顿布隆于1970 年提出以来[10-11],被广泛应用于各种计算机系统以表示庞大数据并提高查找效率[12]。布隆过滤器是一种通过多个哈希函数的映射对参数存储空间进行压缩的数据结构[13],由于其自身结构特性,布隆过滤器存在无法删除及假阳性等缺陷,大量研究工作者提出了一些改进方案并将其应用于各类应用系统。
王乾等[14]提出将布隆过滤器改为双向量的结构使其适合硬件,实现并行过滤,降低了查找延迟,提高了端口吞吐率。为了支持元素的删除,Fan 等[15]提出计数布隆过滤器(Counting Bloom filter,CBF),其本质上是一个计数数组,每个计数器大小为d位,与传统布隆过滤器相比,会产生d倍的存储开销,并且在判断集合成员时需要同时判断k个哈希地址对应计数器的值;Fan 等[16]提出支持删除操作的布谷鸟过滤器(Cuckoo filter,CF),其本质上是由m个桶组成的数组,每个桶包含b个基本存储单元,每个存储单元被称为槽。王飞越[17]采用“两种选择的力量”策略改进布谷鸟布隆过滤器并将其应用于实际;Yu 等[18]提出一种基于单哈希函数的新型布隆过滤器,提高了布隆过滤器的查询效率,假阳性与传统布隆过滤器近似相同;耿宏等[19]提出一种动态布隆计数树(DBCT)型数据结构存储元素集合,通过对每个字节增加计数器记录对应字节被置位的次数以完成删除操作。虽然这些研究工作在对布隆过滤器进行一定改进后都满足了特定需求,但整体上存在以下几点问题:
(1)误算率(假阳性)问题。随着布隆过滤器中元素数量的增加,误算率随之增加,难以消除。
(2)删除问题。由于布隆过滤器中的每位都被多个元素共享,因此不支持删除操作。改进版的计数型布隆过滤器虽然可以提供删除功能,但代价是将原有空间增大d倍(计数器占用空间)且在某种程度上降低了系统性能。
2 基本原理
2.1 前缀树结构
前缀树又称单词查找树,它是由链接结点组成的数据结构,这些链接可能为空,也可能指向其他结点[20]。传统单词查找树的每个结点都有R 条链接,其中R 为字母表大小,结构如图1 所示。单词查找树的构建效率及查询效率均为O(k),k为字符串长度,与单词查找树中存储的元素总数无关,因此,其查询效率通常比二叉搜索树及哈希树更快。此外,根据其自身结构特性,单词查找树可通过将某节点设置为空(null)来完成删除操作,以及在查询时不存在误判率。因此,本文提出选用前缀树结构对传统布隆过滤器进行改进研究。

Fig.1 An example of the traditional R-direction word search tree structure图1 传统R向单词查找树结构示例
由于传统R 向单词查找树的很多结点都为空结点,稀疏现象严重,因此其空间利用率较低[13],属于典型的“空间换时间”策略。为了避免R 向单词查找树在空间上的过度消耗,本文算法采用改进的前缀树,即动态构建有效结点,避免大量无效空节点占用内存,降低了内存空间消耗,改进的动态构建树结构如图2所示。

Fig.2 An example of an improved dynamic tree structure图2 改进的动态构建树结构示例
对比传统R 向单词查找树中每个非空链接隐式地表示其对应字符,改进后的动态单词查找树是显式地保存在每个结点中。
通过对常用的前缀树进行结构分析,本文设计了一种新型的基于位标识的动态前缀树结构,并将其用于实现可擦写的高效过滤器算法中,解决传统布隆过滤器难以删除的问题及避免出现误判率的情况。基于位标识的可擦写过滤器基本结构如图3 所示,将传统结点中存储的字符用一系列二进制向量即位(bit)数组代替。使用占用空间更小的比特位标识字符,能够有效减少空间占用率。假设存储1 亿个char 类型(占2 字节)的字符,大约需占用1.8GB存储空间,而存储1 亿个位数据只需大约119MB,即约为0.11GB,所占空间是其1/16 倍。由此可见,选用位数组优化可以极大降低存储空间,更适用于系统应用。
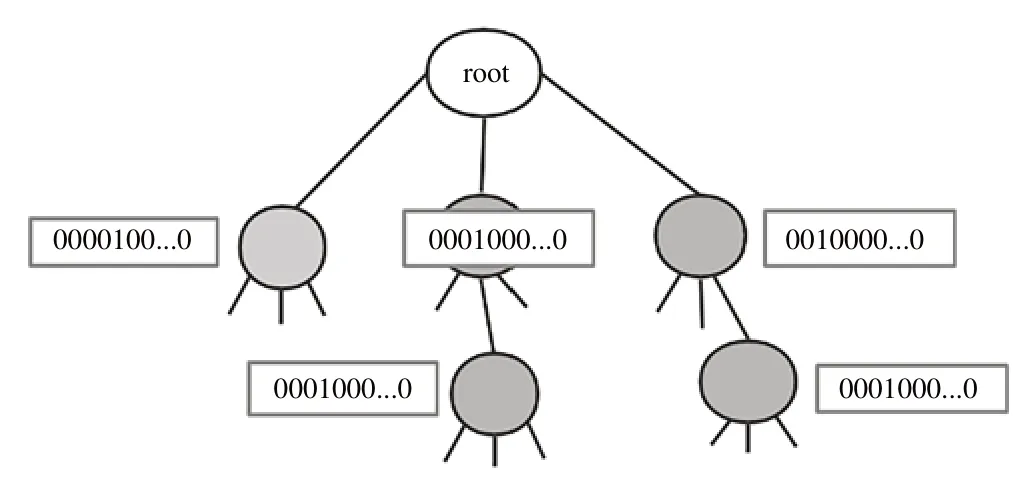
Fig.3 An example of the structure of erasable filter based on bit identification图3 基于位标识的可擦写过滤器结构示例
2.2 构建流程
基于位标识的可擦写过滤器构建流程如图4 所示,具体步骤如下:
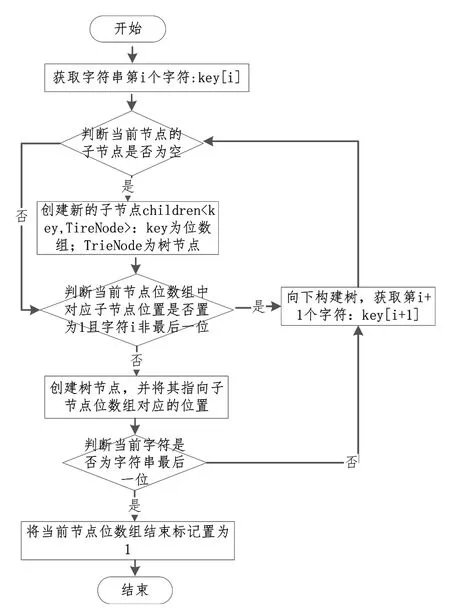
Fig.4 Construction flow chart图4 构建流程
Step1:获取字符串Key 的第i个字符,判断子结点是否为空,从根结点开始:若当前结点的子结点为空,执行Step2;若当前结点的子结点不为空,执行Step3。
Step2:创建新的子结点children
Step3:判断当前结点的子节点记录
Step4:判断当前字符是否为字符串最后一位:若是,则将当前节点结束标记置为1,执行Step5;若否,则向下构建树,获取第(i+1)个字符:Key[i+1],执行Step1。
Step5:结束。
3 实现过程
3.1 索引过程
基于位标识的可擦写过滤器索引元素流程如图5 所示,具体步骤如下:
Step1:获取字符串Key 的第i 位元素,从根结点(root)开始:若当前结点的子节点为空(null),则返回false,表示未命中;否则,执行Step2。

Fig.5 Index flow chart图5 索引流程
Step2:判断子节点
Step3:判断当前Key[i]是否为字符串最后一位元素:若是,执行Step4;否则,继续索引Key[i+1]位元素,执行Step1。
Step4:判断当前节点的结束标记是否为1:若是,表示字符串存在,返回true;否则,未命中,返回false。
Step5:结束。
3.2 删除过程
本文设计的基于位标识的过滤器存储结构本质上是前缀树Trie,因此具有可擦写特性,可以很便捷地支持元素的删除功能。由于应用场景不同,可擦除过滤器算法在删除元素时,只需将元素(字符串key)对应结点中的位数组全部置为0 即可。在删除过程中,若遇到某个结点含有其余子结点,则无须继续进行操作;若该结点的所有链接均为空,即:对应结点的位数组中没有置位1 的位数,则可将其从数据结构中删除;若删除该结点后,其父结点无任何链接,此时应继续将父结点删除。删除流程如图6 所示,具体步骤如下:
Syep1:获取字符串Key的第i个字符元素。
Step2:判断子节点
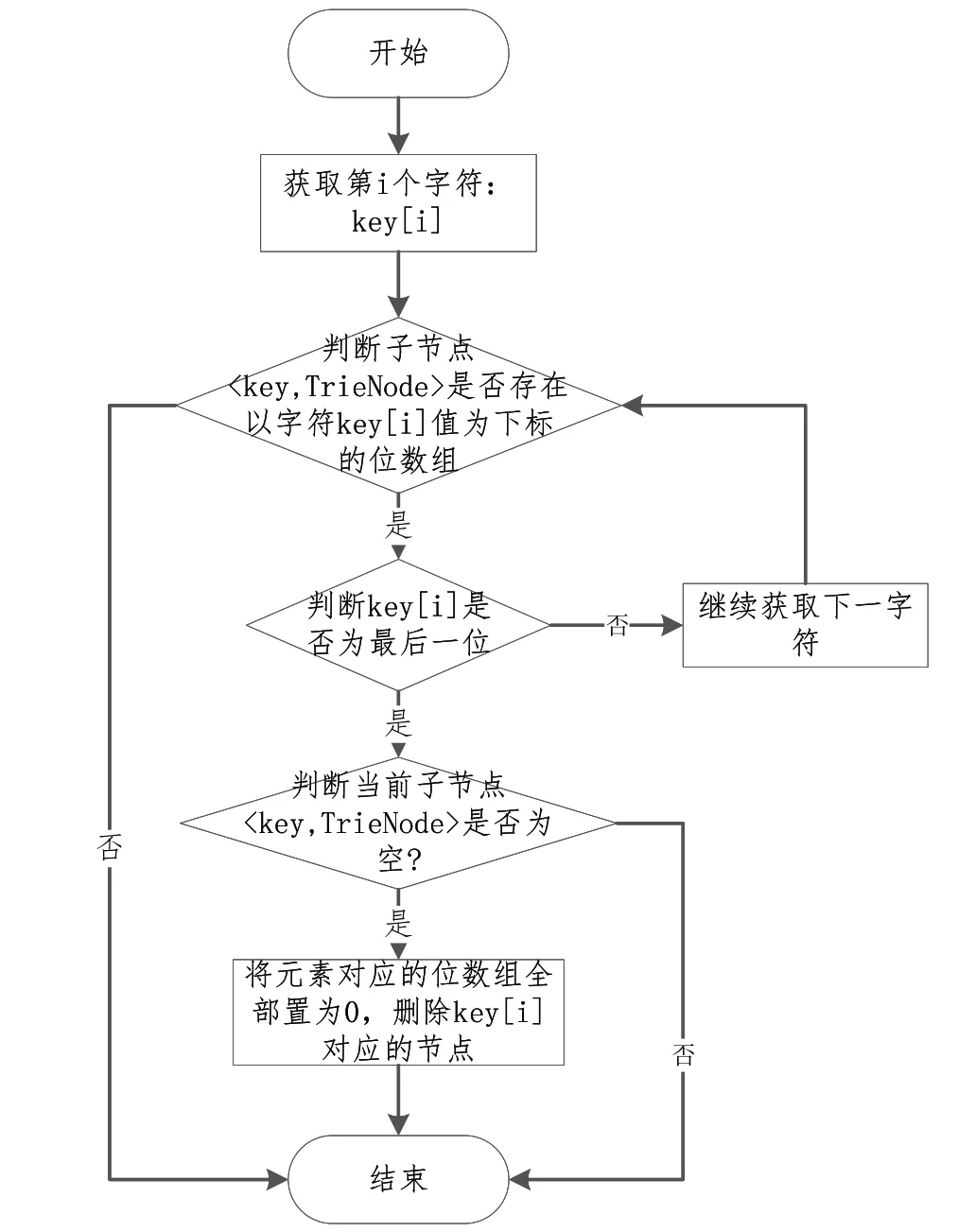
Fig.6 Example of deletion process图6 删除流程示例
Step3:判断当前元素Key[i]是否为字符串最后一位:若为最后一位,执行Step4;若不为最后一位,继续读取下一字符元素,执行Step2。
Step4:判断当前子节点
Step5:结束。
4 实验对比与分析
4.1 环境配置说明
测试环境配置如表1所示。
4.2 数据测试分析
4.2.1 时间性能测试分析
(1)不同数目字符串(定长)构建时间比较。使用定长的字符串,测试不同数目(万级)字符串构建传统前缀树及可擦写高效过滤器的时间性能。字符串定长为5 时的具体测试数据如表2所示。
可以看出,随着字符串数据10(万)、20(万)、40(万)、60(万)……递增,基于位标识的可擦写过滤器能够快速响应,正确处理数据并完成构建;而传统的前缀树方式消耗的构建时间更多,且当数据量增加至200(万)及以上时,由于内存溢出问题,系统无法正常响应,完成构建。图7 直观地反映了两种方式下不同数目字符串的构建时间情况。由此可知,本文提出的基于位标识的可擦写高效过滤器是可行的。
(2)不同数目字符串(定长)索引时间比较。使用定长的字符串,测试不同数目(万级)字符串索引时间。字符串定长为5的具体测试数据如表3所示。
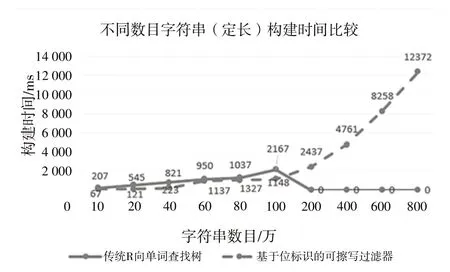
Fig.7 Comparison of the construction(insertion)time of different numbers of strings图7 不同数目字符串构建(插入)时间比较
由表3 可以看出,随着字符串数据10(万)、20(万)、40(万)、60(万)……递增,基于位标识的可擦写过滤器与传统前缀树方式在索引时间上的差异并不显著,两者的索引差值仅占很小一部分,性能相当。图8 直观地反映了测试环境下两种方式的索引时间情况。由此可知,本文提出的新型的基于位标识的可擦写过滤器可应用于高并发场景下。
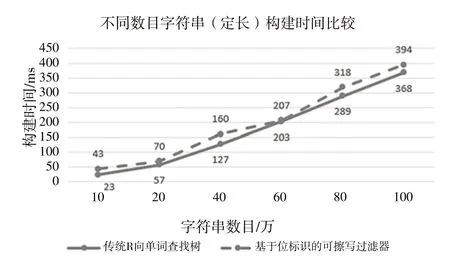
Fig.8 Comparison of indexing time of different numbers of strings图8 不同数目字符串索引时间比较
4.2.2 空间性能测试分析
使用定长的字符串,测试不同数目(万级)字符串构建后传统前缀树与可擦写过滤器的内存空间使用情况。字符串定长为5时的具体测试数据如表4所示。
表4 给出了存储10 万~800 万定长字符串时两种算法的内存空间使用情况。可以看出,新型的基于位的可擦写高效过滤器的内存空间使用最少。为进一步分析这两种结构的空间性能,绘制图9,用来显示字符串数目从10 万增至800 万时传统R 向前缀树与基于位的可擦写过滤器的空间差值变化情况。
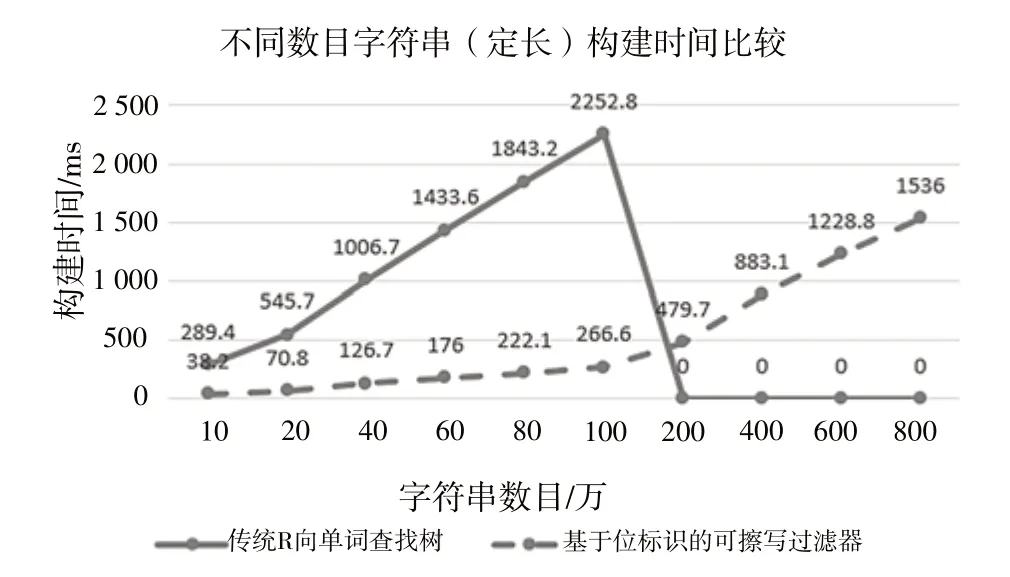
Fig.9 Comparison of memory space of different numbers of strings图9 不同数目字符串内存空间比较
从图9 可知,随着字符串数量的增加,传统R 向前缀树与基于位的可擦写过滤器之间的内存使用差值不断增加。当测试数目增至100 万时,传统R 向前缀树所使用的空间比基于位的可擦写过滤器多了大约1.9GB,当数目增至200 万及以上时,系统内存溢出。由此可知,本文提出的新型基于位的可擦写过滤器较传统前缀树在内存使用上有极大优势,更适用于高并发场景下的系统应用。
5 结语
本文提出新型的基于位标识的可擦写高效过滤器算法,利用前缀树自身结构支持元素删除的特性,解决传统布隆过滤器中元素删除困难问题及实现0 误判率,并通过改进传统的前缀树存储结构,将字符替换为占用空间更少的位(bit)数组,动态构建树结构,减少大量无效的空节点,在保持索引时间复杂度的前提下,极大降低了内存空间消耗,更适用于高并发下的系统开发。
猜你喜欢
电脑报(2022年13期)2022-04-12
文萃报·周二版(2020年32期)2020-09-02
电脑报(2020年24期)2020-07-15
林业调查规划(2017年6期)2017-03-27
初中生之友·中旬刊(2015年4期)2015-06-10
燕山大学学报(2014年1期)2014-03-11
测绘科学与工程(2013年6期)2013-03-11
网络安全与数据管理(2011年17期)2011-07-25
