
基于Kettle的数据转换同步方法研究
2022-08-25 09:56韦亚军张文文李冬青
软件导刊 2022年8期
韦亚军,张文文,李冬青
(南京国图信息产业有限公司,江苏南京 210000)
0 引言
随着自然资源信息化体系的完善,各机构改革逐步落实到位。如何更加高效、安全、灵活地实现各部门、各应用系统之间的数据转换、同步及迁移工作成为当前自然资源信息化建设面临的重要难题[1-3]。目前数据转换、同步工作一般采用两种方法[4-7]:一种是借助专业的抽取—转换—加载(Extract-Transform-Load,ETL)工具实现,如Oracle数据库的OWB、SQL Server 2000 的DTS、达梦数据库DTS等,该方法通常要求目标数据库必须是指定类型,因此缺乏灵活性;另一种是通过SQL 编程的方式实现,可有效提高ETL 运行效率,但编码复杂,难以快速构建ETL 工作环境,具有一定的应用局限性。
针对上述问题,结合自然资源信息化体系建设过程中数据多源、数据量大、结构复杂等特点,本文基于开源ETL工具Kettle 构建源数据库转换同步环境,并提出一种新的数据转换同步方法。该方法充分融合集成了传统ETL 工具与SQL 编程二者的优势,解决了ETL 工具目标数据库需指定类型的不足以及SQL 编程方法的局限性问题,提高了开发速度和工作效率,有效解决了自然资源信息化建设过程中多源数据到目标数据的转换与同步难题,同时也为企业的数据集成工作提供了更多思路。
1 Kettle简介
Kettle 是一款强大、开源的ETL 工具,又名“水壶”,意为将各种数据放到一个壶中,然后以一种指定的格式流出。Kettle 支持可视化的图形用户界面(Graphics User Interface,GUI),以工作流的形式流转,无需安装即可在Windows、Linux 及Unix 系统上运行,数据抽取、转换、同步、过滤功能高效稳定[8-11]。
Kettle 的数据集成功能主要由转换(Transformation)和作业(Job)两个核心组件完成,其中转换组件为进行数据操作的容器,数据操作即数据从输入到输出的过程,每一个转换表示对一个或多个数据流进行特定的数据操作;作业组件负责将一个或多个转换组织在一起,根据事先设定的工作流模式,协调数据源并执行转换活动,从而完成一项特定的数据处理任务。通常情况下,一项大型任务会被分解为多个逻辑上隔离的作业,作业完成即代表该数据处理任务完成[12-15]。Kettle 的概念模型如图1所示。
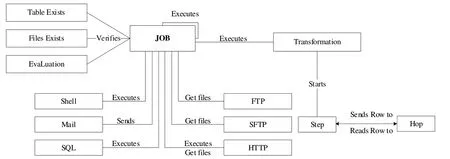
Fig.1 Kettle conceptual model diagram图1 Kettle概念模型图
2 应用场景
根据操作系统网络环境的不同,Kettle 的应用场景可分为3 种[16],分别为表视图、前置机和文件模式,具体如图2 所示。其中,表视图模式是数据集成处理中经常遇到的场景,即在同一网络环境下需要对多种数据源进行抽取、筛选、转换和加载等,如历史数据同步、异构系统数据交互、数据对称发布或备份;前置机模式是一种典型的数据交换模式,数据交互双方A 和B 在网络不通的情况下可以通过前置机C 实现连接,此时双方可以约定好前置机C 的数据库结构标准,通过开发应用接口将数据组织成标准结构并推送至前置机;文件模式是指当数据交互双方A 和B完全物理隔离时,只能通过指定格式文件的方式实现数据交互,如XML 格式。该模式在应用A 中开发应用接口用于生成标准格式的文件,然后通过移动硬盘等介质在某一时间拷贝文件接入应用B,应用B 按照标准接口规范接收数据。以上3 种应用场景若均从系统层面实现数据同步转换,无疑工作量巨大,同时涉及到一些复杂的业务和逻辑,还会产生一定的程序错误,增加了项目投入成本。而利用Kettle 完成数据同步转换工作可有效减少研发工作量,提高工作效率。
3 数据同步方法
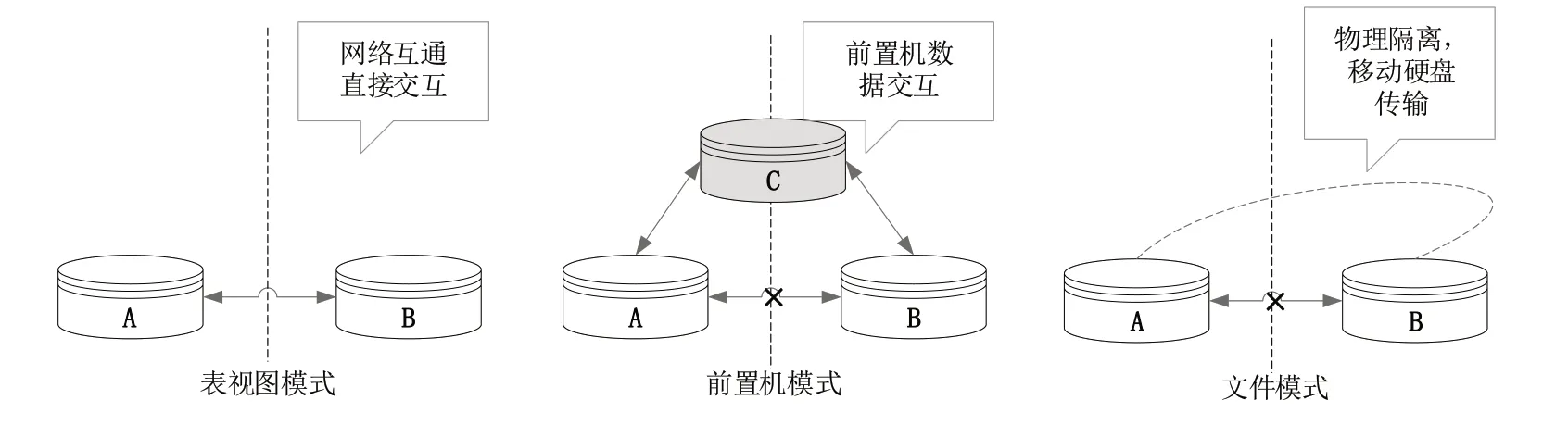
Fig.2 Kettle application scenario图2 Kettle应用场景
基于Kettle 的数据转换同步方法是通过Kettle 制定数据抽取、筛选、转换规则,并以工作流的形式执行作业任务,从而实现数据转换、同步工作。主要步骤为首先在数据同步工作前对业务需求进行分析,制定一套详细且专业的数据同步流程和策略;然后将该同步流程和策略转化为Kettle 可识别的转换脚本和作业流程;最后形成基于Kettle的源数据库转换同步环境,实现源数据到目标数据的高效持续更新机制[17]。
3.1 业务需求分析
某自然资源与规划局的自然资源一体化业务审批系统(以下简称审批系统)由我司研发并已上线运行,档案管理系统则由另一家公司研发,两个系统分布在不同的网络环境中,无法直接进行交互,但可以通过前置机完成连接。现局方要求我司协助完成业务审批数据归档工作,每天定时将审批系统已办结的业务数据同步至前置机数据库(以下简称目标数据库),该目标数据库由档案管理系统研发公司设计,档案管理系统获取目标数据库中的数据进行归档操作。
上述业务场景为典型的前置机模式,要求归档的数据包括土地、矿产、林业、综合事务等,涉及审批系统中的多个数据源(以下简称源数据库)。由于系统已经上线运行,除需完成新的业务数据同步外,还需要实现历史数据的归档工作。
3.2 同步流程
结合业务需求分析,本次数据同步除需完成日常增量数据同步外,还应完成历史数据全量同步。为防止重复全量同步操作,本文设计了增量和全量数据同步流程,在启动定时作业任务后,首先判断目标数据库的记录数,确定是否已经存在历史业务数据,若不存在,则可以先进行全量数据同步,确保历史数据同步到目标数据库,防止数据丢失[18-19]。数据同步流程如图3所示。
3.3 同步策略
结合实际需求及数据同步流程,本文制定了数据结构分析、数据筛选、数据组合、数据规范、数据清理和数据校验6个同步策略。
3.3.1 数据结构分析
数据结构分析策略主要针对源数据库和目标数据库的表结构、E-R 图进行分析,形成源数据库和目标数据库表与表、字段与字段之间的对应关系,利用Excel 表格、思维导图等形式整理记录各数据库表、字段的对应关系,具体示例如图4所示。
3.3.2 数据筛选
根据实际业务需求,从源数据库中筛选满足要求的基础数据信息,剔除目标数据库不需要的表和字段,获得满足实际要求的各类业务数据信息,解决无效数据同步到目标数据库的问题。利用Kettle 工具输入组件完成源数据筛选,具体操作如图5所示。
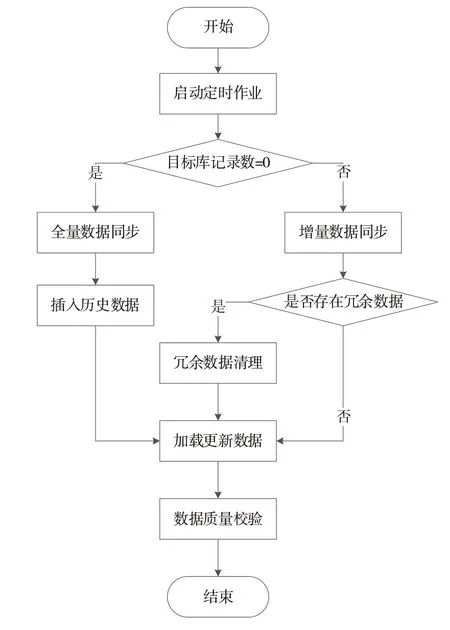
Fig.3 Data synchronization process图3 数据同步流程
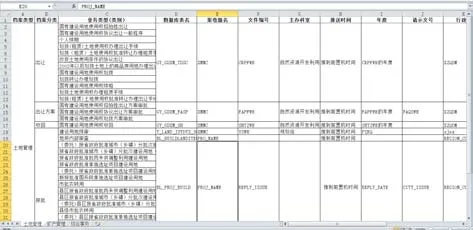
Fig.4 Data structure analysis example图4 数据结构分析示例

Fig.5 Data screening process图5 数据筛选操作
3.3.3 数据组合
在源数据筛选过程中建立统一的业务主键,建立各表之间的组合关系,完成源数据基础数据重组,解决数据同步过程中业务缺失、关键信息不全等问题。
3.3.4 数据规范
根据目标数据库标准要求,对筛选的基础数据进行规范化处理,建立同步数据标准,解决数据规范不一致、格式不统一等问题。
3.3.5 数据清理
进行增量数据同步前,检查并清理目标数据库中已经存在的冗余数据,以保证目标数据库数据的实时性、准确性。
3.3.6 数据校验
针对目标数据库的数据业务逻辑关系进行校验,剔除不符合校验规则的数据,完成数据质检工作,解决数据质量不符合要求的问题。
根据以上数据同步策略,结合实际需求分析,本文设计了如图6 所示的数据同步架构,构建了基于Kettle 的源数据库转换同步环境,形成了由源数据库到目标数据库的自动持续更新机制。
4 业务应用
利用基于Kettle 的数据转换同步方法,结合源数据库转换同步环境,设计了本次数据转换同步的转换脚本和作业任务,使审批系统各项业务数据转换为可供档案管理系统使用、分析、决策的目标数据,并对其进行校验。同时,开发了定时触发脚本文件,以完成对作业任务的定时调度,实现源数据到目标数据的自动持续更新。

Fig.6 Data synchronization architecture图6 数据同步架构
4.1 基于Kettle的作业任务
基于实际业务需求,对审批系统土地、矿产、林业、综合事务等业务数据进行筛选、拼接,并与附件材料数据关联、合并,对其中的非标准数据进行规范化处理,部分数据处理示例如图7 所示。应用数据筛选、数据组合、数据规范及数据清理4 个同步策略构建审批系统业务数据转换流程,见图8。同时建立作业任务,集成所有转换流程,实现对整个审批系统从源数据到目标数据同步的集成控制,维护数据同步的流程秩序。

Fig.7 Data processing example图7 数据处理示例
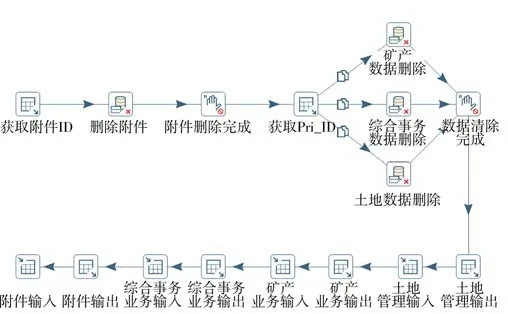
Fig.8 Data transformation flow图8 数据转换流程
数据转换、同步工作完成后需对结果进行数据校验,校验内容主要包括目标数据库表之间的逻辑关系是否符号要求,数据库表总数、记录总数是否与源数据一致等。对目标数据库部分表记录总数进行统计校验,结果见图9。校验结果表明,利用基于Kettle 的数据转换同步方法可顺利完成数据转换、同步工作,数据转换率、有效率、正确率均高达98%以上。
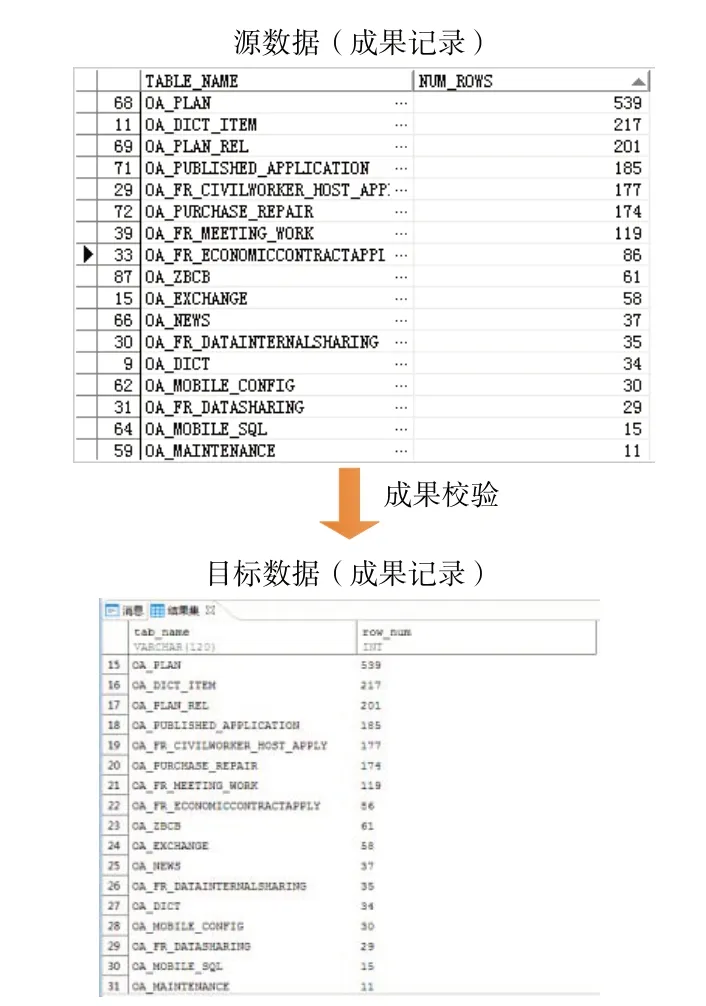
Fig.9 Data validation example图9 数据校验示例
4.2 定时触发任务
定时触发任务主要利用Kitchen 命令行控制工具编写.bat 脚本文件,并与Kettle 工具相结合,实现系统对作业任务的定时调度,完成源数据到目标数据的持续更新工作。.bat脚本文件代码为:


5 结语
本文针对实际业务需求,基于ETL 工具Kettle 制定了数据同步流程与策略,并在此基础上构建了基于Kettle 的源数据库转换同步环境,提出新的数据转换同步方法,利用该方法可实现对审批系统土地、矿产、林业、综合事务等数据的高效抽取、筛选、转换和同步。校验结果表明,该方法数据转换率、有效率、正确率均高达98%以上,满足了档案管理系统对目标数据库的查询、分析和决策需求。同时制定了定时触发任务,解决了系统后台对作业任务的定时调度问题,最终实现了源数据库到目标数据库的高效自动持续更新。未来将不断完善数据规范和校验过程,提高数据质量,优化转换作业流程,提升数据同步效率,为企业的数据转换、同步及迁移工作提供更多思路。
猜你喜欢
今日农业(2021年10期)2021-07-28
中国生殖健康(2020年5期)2021-01-18
教书育人(2020年11期)2020-11-26
当代陕西(2020年13期)2020-08-24
中国生殖健康(2018年5期)2018-11-06
中国铸造装备与技术(2017年6期)2018-01-22
国际医学放射学杂志(2016年4期)2016-08-22
办公自动化(2016年18期)2016-08-20
电测与仪表(2015年1期)2015-04-09
电测与仪表(2015年19期)2015-04-09
