
基于Mask R-CNN和关键点提取的抓取位姿估计方法
2023-10-11 09:00金圣洁林晓琛
合肥工业大学学报(自然科学版) 2023年9期
吴 飞, 金圣洁, 林晓琛
(武汉理工大学 机电工程学院,湖北 武汉 430070)
在工件堆叠摆放的场景中,目标工件在空间中存在不同位姿、相互遮挡,增加了机器人抓取工件的难度。传统三维设备扫描目标的整体环境,生成的点云数量庞大,直接作为源点云与参考点云配准,会导致运算时间过长,难以满足机器人抓取所需的快速性。随着工业智能化的快速发展,快速、准确地获取目标工件的抓取位姿,对工业机器人的进一步发展有重要意义。
文献[1]通过ORB(oriented fast and rotated brief)算法和模板匹配进行目标识别,利用改进的迭代最近点(iterative closest point,ICP)算法进行点云配准与位姿估计,实现了放射源物体相对相机的位姿估计;文献[2]从图像中提取出仅有抓取目标的局部图像,运用卷积神经网络(convolutional neural network,CNN)进行目标识别分类,该方法具有识别精度高、抗干扰能力强的特点;文献[3]提出一种基于深度学习的机械臂最优抓取位置检测方法,该方法具有较强的泛化性和稳定性;文献[4]将抓取位姿转化为抓取位置回归与抓取角度分类的组合,实现了抓取位姿的单次预测,提升了检测速度;文献[5]提出一种基于级联卷积神经网络的平面抓取位姿快速检测方法,针对背景多样、光照不均、存在噪点的场景,能够快速准确地计算得到末端执行器位姿;文献[6]对图像的每个空间位置进行抓取检测,能够直接回归获得检测结果,但并不适用于多对象的图像数据;文献[7]将卷积神经网络与支持向量机(support vector machine,SVM)等传统机器学习算法相结合,进一步提高了位姿估计的准确率;文献[8]提出一种基于图像掩膜估计抓取位姿的方法,训练神经网络时不需要进行真实的位姿标注,保证了识别的效率,同时降低了系统的复杂度。
通过将更快速的区域卷积神经网络(faster region-based convolutional neural network,Faster R-CNN)[9]等目标检测网络引入到位姿估计问题中,对于平面简单放置的物体,实现了准确的位姿估计及抓取,但针对多个目标物体散乱堆叠的情况,难以达到抓取要求。基于上述问题以及工业现场中三通件和弯管件散乱堆叠、位姿任意的工况,本文提出一种基于掩膜区域卷积神经网络(mask region-based convolutional neural network,Mask R-CNN)[10]和关键点提取混合的位姿估计方法,并通过仿真实验分析了该方法的性能。位姿估计系统流程如图1所示。
1 Mask R-CNN实例分割
1.1 制作数据集
利用Realsense d435i深度相机采集200张三通、弯管工件图像,图像像素大小为848×480。图像采集环境如图2所示。

图2 图像采集环境
深度相机通过固定三脚架安装在固定高度,采用黑色吸光布作为拍摄背景,通过调节曝光参数和发光二极管的亮度,可采集到工件与背景对比明显的数据集图像。
图像中包含不同倾斜角度的工件,同时采集部分含有不可抓取工件位姿的图像,作为负样本进行训练,以模拟真实的散乱堆叠工件场景,提高模型的鲁棒性,数据集如图3所示。在机器人抓取过程中,将所有识别出的工件抓取后,通过振动装置再次改变被识别为不可抓取工件的位姿,进行二次抓取。

图3 数据集
由于采集的数据较少,直接进行训练容易出现过拟合现象,需要通过数据增广来提高实例分割模型的泛化能力。增广方式包括翻转、缩放、加噪、模糊、加减曝光等方式,但并非所有的增广方式都适用于工件数据集,需要根据数据集的特征选择合适的数据增广方式。
本次数据增广方式主要包括翻转、加噪、模糊及加减曝光,数据增广效果如图4所示。通过数据增广获得图像3 000张,其中2 400张作为训练集,600张用于验证集。

图4 数据增广效果
1.2 Mask R-CNN模型
Mask R-CNN是由Faster R-CNN逐渐改进而来的多任务卷积网络模型,可以完成目标检测、目标分类、像素级别的目标分割等多种任务,Mask R-CNN网络框架图如图5所示。

图5 Mask R-CNN网络框架图
本文目标是实现工件分割与位姿估计,检测分割场景中含有许多同类的不同工件个体,无法采用语义分割模型。同时工件摆放位姿任意,存在堆叠遮挡的情况,难以从单一或者几个有限的角度分析出有意义的物体特征,也不可能穷举描述每一个特征,因此传统物体识别方法难以在该问题中发挥作用,故采用Mask R-CNN实例分割模型对目标工件的不同个体进行分割。
1.3 Mask R-CNN训练与验证
基于迁移学习的方式,加快训练的过程,以COCO(common objects in context)数据集的训练权重作为初始化权重,在AMD 2600X @3.6 GHz,内存32 GiB,GPU NVDIA GTX-2070的Windows10平台TensorFlow1.8.0环境下进行Mask R-CNN的训练。模型训练参数设置见表1所列。

表1 模型训练参数
输出掩膜结果如图6所示,Mask R-CNN实例分割网络能够准确地识别出待抓取的目标工件以及位姿偏差过大的工件,同时能够识别出部分被遮挡的工件。
1.4 表面点云的构建
通过Mask R-CNN对彩色图进行分割,获得的掩膜mask可对深度图进行分割并提取深度信息,如图7所示。

图7 分割工件深度
利用深度相机的内参可建立工件表面点云,点云中每个点的坐标(X,Y,Z)的计算公式如下:
(1)
其中:u0、v0为相机光圈X、Y方向的中心点位置;fx、fy分别为x、y轴上的焦距;s为深度图里的数据与实际距离的比例。
根据式(1)计算结果分割出待抓取工件表面点云,如图8所示。

图8 分割工件点云图
2 点云配准方法
2.1 特征关键点对比
由于点云数据是三维坐标系中采样点的数据集,且实际获得的点云数据往往数量级较大,对不同坐标系下的所有点迭代计算刚性变换矩阵,不仅需要较长的运算时间,也极易造成局部收敛。因此,可采用点云的关键点去描述一个点邻域内的点云,不但减少点云数量,还提高配准效率和配准精度。常用的点云关键点提取算子有三维尺度不变特征变换(3D scale invariant feature transform,3D SIFT)算子[11]、三维角点(3D Harris)检测算子[12]等。
本文依次在体素下采样后三通工件的计算机辅助设计(computer aided design,CAD)模板点云、无遮挡工件表面点云以及有遮挡工件表面点云测试3D Harris、3D SIFT 2种算子,CAD模板点云数量为6 621个,无遮挡工件表面点云数量为3 033个,遮挡工件表面点云数量为2 849个,关键点提取结果对比如图9所示。

图9 关键点提取结果对比
根据上述关键点提取结果,针对CAD模板点云,3D Harris关键点分布较为均匀,能够描述整体点云的特征,符合关键点提取要求,3D SIFT关键点主要分布在工件边缘处,不利于后续与表面点云的配准。针对工件的表面点云,存在无遮挡表面点云和有遮挡情况下表面点云2种情况,如图9结果所示,3D Harris关键点相较于3D SIFT关键点主要集中在工件边缘处,且关键点数量相对较少,难以体现表面点云的整体特征。关键点提取数量见表2所列,关键点提取时间见表3所列,配准时间以关键点提取10次的平均时间为准。

表2 关键点提取数量 单位:个

表3 关键点提取时间 单位:s
由统计结果可知,3D Harris算子相比3D SIFT算子在关键点提取上所需时间更短,结合图9关键点提取结果可知,由于CAD模板点云数量较多,可选用3D Harris提取算法,减少计算时间。针对分割工件表面点云,3D SIFT关键点提取时间与3D Harris相差1 s左右,但关键点提取更均匀,故可选用3D SIFT提取算法。
2.2 初步位姿估计
本文采用采样一致性初始配准算法(sample consensus initial alignment,SAC-IA)[13]对模板点云和目标工件表面点云进行初始位姿配准,该算法以点云的快速点特征直方图(fast point feature histogram,FPFH)作为输入,通过计算特征之间的对应关系,完成初始配准。算法主要流程如下所述。
设定最小距离阈值ds,从模板点云P中选取n个采样点,每个采样点之间的距离需大于阈值ds,确保采样点具有不同的FPFH。同理,计算目标点云Q的FPFH,查找与点云P中采样点具有相似FPFH的1个或多个点,将其作为模板点云P中采样点在目标点云Q中的对应点。计算对应点之间旋转、平移变换矩阵,求解对应点变换后的配准误差来判断当前配准变换的性能。采用Huber公式计算配准误差Es,即
(2)
(3)
其中:lm为预先设定的距离阈值;li为第i组对应点变换后的距离差。重复上述操作直至误差函数的值最小,即可求得所需的最佳变换矩阵。
SAC-IA求得的变换矩阵并不准确,因此只能用于粗配准,初始点云如图10所示,无关键点提取粗配准效果如图11所示。

图10 初始点云

图11 无关键点提取的SAC-IA粗配准效果
2.3 精配准位姿估计
通过粗配准两点云大致重合到一起,为ICP算法[14]提供了良好的初始位姿。将粗配准后的两点云P′和Q作为ICP的初始点云集,算法实现的主要流程如下所述。
对于模板点云P′中的每个采样点矢量pi,在目标工件表面点云Q中寻找距离最近点矢量qi,确定初始最近对应点对(pi,qi)。计算对应点对之间旋转、平移变换矩阵R、T,使得对应点集之间的均方误差最小,均方误差计算公式如下:
(4)
将求解得到的R、T变换矩阵作用于模板点云P′,得到变换后的点云P″。设定阈值ε=dk-dk-1和最大迭代次数Nmax,计算变换后的模板点云P″和目标工件点云Q的均方误差,若误差小于阈值ε或者当前迭代次数超出最大迭代次数Nmax,则停止计算;否则将粗配准获得的模板点云更新为P″,继续重复上述步骤,直至满足收敛条件。
以SAC-IA的输出结果作为ICP精配准初始点云位姿,配准结果如图12所示。

图12 无关键点提取的ICP精配准效果
相较于图11b中粗配准效果,通过ICP精配准可以获得更为准确的位姿估计。
3 配准结果与分析
为了验证本文所提出方法的性能,对比分析了无关键点提取、3D Harris关键点提取、3D SIFT关键点提取、本文3D Harris-3D SIFT关键点提取混合的点云配准效率以及配准结果,点云实验的硬件环境为Intel(R)Core(TM)i5-9400 CPU@2.90 GHz处理器,16 GiB内存。
以体素下采样后的三通件和弯管件点云作为算法对比的输入点云,无关键点提取精配准结果如图11、图12所示,关键点提取算法的相关粗、精配准结果如图13~图18所示。
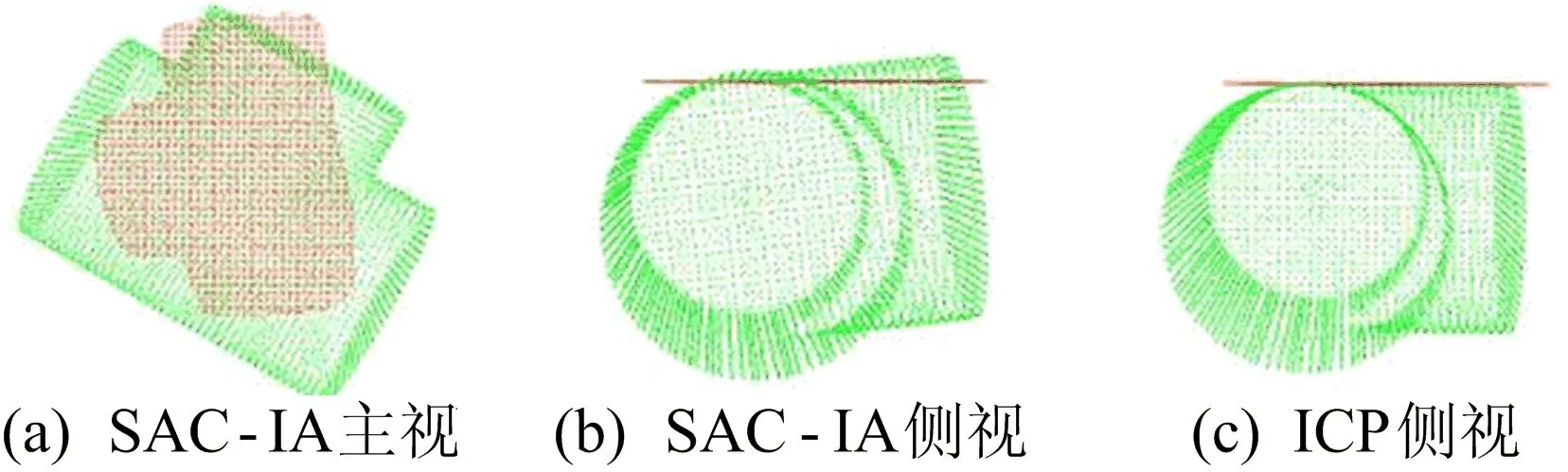
图13 三通件3D Harris关键点提取结果

图14 三通件3D SIFT关键点提取结果

图15 三通件3D Harris-3D SIFT关键点提取结果

图16 三通件遮挡点云3D Harris-3D SIFT关键点提取结果

图17 弯管件3D Harris-3D SIFT关键点提取结果

图18 弯管件遮挡点云3D Harris-3D SIFT关键点提取结果
三通件配准数据统计结果见表4所列,配准对比分析结果见表5所列,配准时间以10次运行结果的平均值为准。由对比分析结果可知,无关键点提取输入的点云数量较大,配准时间长,不符合机器人抓取动作所要求的快速性;仅使用3D Harris关键点提取,针对模板点云,关键点提取较为均匀,而工件表面点云关键点提取数量少,粗配准效果差,但3D Harris关键点提取时间短,相较于无关键点提取,计算时间有明显的下降;仅使用3D SIFT关键点提取,针对模板点云,关键点主要集中在工件的边缘处,而工件表面点云提取较为均匀,导致配准结果出现在工件边缘处,位姿估计错误;而本文所提出的混合算法能够同时兼顾2种关键点提取算法的优点,点云特征明显,虽然比仅使用3D Harris关键点提取算法的配准时间略有上升,但点云的配准精度有显著提升,相较于仅使用3D SIFT关键点提取算法,配准时间更短,配准效果更好。

表4 三通件配准点云数量 单位:个
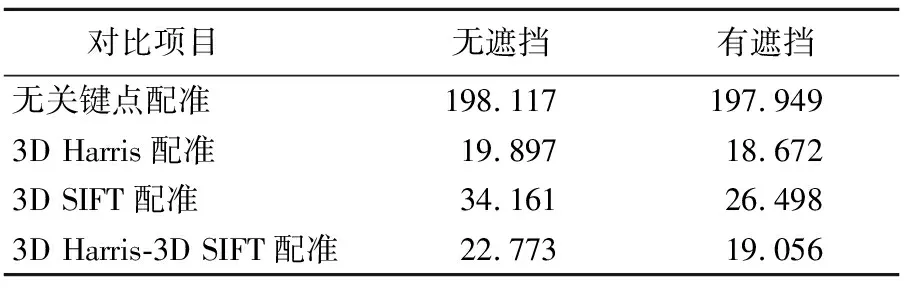
表5 三通件配准时间 单位:s
4 结 论
针对工业现场中散乱工件的检测和位姿估计问题,本文提出了一种基于Mask R-CNN和关键点提取混合的位姿估计算法。通过Mask R-CNN能够准确地识别出待抓取的目标工件以及位姿偏差过大的不可抓取工件。通过对模板点云进行3D Harris关键点提取,目标工件表面点云进行3D SIFT关键点提取,将模板点云与目标工件表面点云缩至特征点集,既保留了点云的主要特征,又能够提高点云配准效率。以三通和弯管工件为实验对象,实验对比分析了无关键点提取、3D Harris关键点提取、3D SIFT关键点提取以及本文关键点提取混合算法,结果表明,本文算法能够显著降低点云配准时间,提高配准精度,为后续的机器人抓取提供更加快速准确的位姿估计。
猜你喜欢
中学生数理化·中考版(2022年12期)2022-02-16
今日农业(2021年8期)2021-11-28
西夏研究(2017年4期)2017-08-17
光学精密工程(2016年5期)2016-11-07
光学精密工程(2016年4期)2016-11-07
新闻传播(2016年4期)2016-07-18
小学教学研究(2016年13期)2016-04-16
湖北工业大学学报(2016年5期)2016-02-27
中国卫生(2014年2期)2014-11-12
组合机床与自动化加工技术(2014年12期)2014-03-01
