
改进DeepLabV3+下的轻量化烟雾分割算法
2023-10-26 06:50侯青山张吉康
西安工程大学学报 2023年4期
陈 鑫,侯青山,付 艳,张吉康
(1.西安工程大学 电子信息学院,陕西 西安 710048;2.西北工业大学 自动化学院,陕西 西安 710129; 3.陕西省现代建筑设计研究院,陕西 西安 710048)
0 引 言
加强楼宇建筑的安全防护是重中之重,早期楼宇烟雾监测方法依赖于感温、感烟等火灾传感器,但感烟、感温传感器在范围较大、复杂多样或灵敏度要求高的环境中具有一定滞后性,火灾误报率比较高[1]。大型建筑楼宇自控系统的应用能够让建筑的智能化水平大幅度提升,通过其可快速监测并由专业人员进行处理和解决。烟雾监测系统是建筑楼宇预防火灾不可或缺的一个环节,因为火灾极易引发且后果严重,所以如何防止火灾是一项重要的研究。
火灾发生初期,由于燃烧不充分会产生大量烟雾,烟雾遮挡火焰并影响火焰的监测,导致错过最佳的扑灭时间,因此研究人员提出多种基于烟雾的火灾检测算法[2-3]。视频烟雾序列拥有丰富的图像信息,涉及纹理、颜色、小波和运动等诸多特征,传统的视频烟雾检测方法主要基于这些特征去完成对火灾烟雾的检测[4]。文献[5]利用烟雾的多种特征,在背景建模融入视频像素点的空间与时间信息,最后提出3种高鲁棒性的纹理特征,利用支持向量机进行分类。文献[6]在YOLOv3的基础上新增了Decoupled Head和Anchor-free结构,算法精确度显著提升,但不能适应多类场景,检测准确率降低。文献[7]采用YOLOv2网络进行烟雾检测,但面对小目标烟雾时准确率不高。文献[8]提出基于YOLOv4的火灾烟雾检测算法,在网络中加入通道注意力,可有效提取烟雾特征,最终实现烟雾检测。文献[9]在特征提取前通过混合高斯算法提取疑似烟雾区域,并将使用的YOLOv5的金字塔结构中融入自适应注意力,交叉熵损失函数替换为Focal Loss函数,结果表明其烟雾检测适用于多种场景。
在实际中需要监测到火灾的发生及地点,而烟雾分割算法可以为使用者快速寻找火灾位置。烟雾分割比烟雾检测更加困难,其需要将烟雾从背景中剥离出来。早期研究者使用传统的方法,通过手工设计特征将烟雾分割出来,如基于颜色空间衍生出的灰度直方图的阈值分割算法[10]和基于种子生长的阈值分割方法[11-13]。单张图像的分割已经不能满足实际生活中的需求,文献[14]通过图像增强和运动能量对视频烟雾进行分割,其对森林火灾的分割精度高达99%,但在其他场景中表现较差。传统的特征具有难设计、局限性大、鲁棒性差的缺点。随着分割要求的不断提高,深度学习[15-17]因其可以自主学习特征,且适用于多场景等优点,逐渐成为研究者们的首选。文献[18]首先提出了一种基于FCN的深度学习的烟雾分割算法,实现了对烟雾图像的训练和分割,但其数据集是合成图像,且由于FCN网络本身的局限性,使其结果不具有泛化性。烟雾具有半透明性,导致背景和烟雾高度复杂,文献[19]提出了一种CGA-Net进行视频烟雾分割,构建一个基于条件生成的对抗网络,可以自动建立视频帧与分割结果的映射模型,提升对淡烟雾的感知度,该方法在不明显烟雾和类烟雾图像上表现优异。文献[20]在文献[18]的基础上增加了一个多尺度对比上下文结构模块,用以区分云、水雾和烟雾的不同,加强对不明显烟雾的分割效果。以上3种算法虽然对烟雾进行分割,但其算法复杂度高,且在追求烟雾与类烟雾物体区分的过程中舍弃了部分精度,无法满足研究者对火灾的实时分割需求。DeepLabV3+算法的主干提取特征网络Xception网络[21],文献[22]的EfficientNet网络代替DeepLabV3+编码模块中的Xception网络,而EfficientNet在精度、网络深度和复杂度之间提供了很好的平衡,实验结果表明,其在森林火灾烟雾上的分割效果取得显著提升,但在细颗粒烟雾分割上表现不理想。
以上烟雾分割算法虽然在大目标烟雾的场景上表现较好,但还存在以下问题。
1) 对于大目标烟雾来说,烟雾的内部与边缘的特征存在不同,内部的烟雾更浓、颜色更深,而边缘的部分更加清淡,边界难以如同内部一样轻易分割,甚至会将烟雾边缘的背景误分割进去,从而导致烟雾分割的精度下降。
2) 由于火灾检测的特殊性,分割小目标烟雾才具有实际意义,而现有的研究大多数应用于大型火灾。由于小目标烟雾与大目标烟雾存在着颜色以及形态特征的差距,所以针对大目标烟雾训练出的网络对小目标烟雾的感知能力不够,且本文参考的公共数据集中也缺乏小目标烟雾,这会让训练出的网络缺乏对小目标烟雾的感知能力。
3) 现有的烟雾分割算法在追求分割精度的研究中大都没有考虑大型网络在实际中的训练时长和模型大小。
针对上述问题,本文提出了一种改进的轻量化DeepLabV3+烟雾分割算法。该算法不仅可以提高烟雾的分割精度,还有效地降低了权重大小。
1 基本原理
1.1 改进的DeepLabV3+算法
本文采用DeepLabV3+[23]作为烟雾语义分割的深度学习算法。DeepLabV3+算法模型分为编码和解码2个部分,通过特征提取网络Xception提取烟雾特征,用空洞空间卷积池化金字塔(atrous spatial pyramid pooling,ASPP)获得烟雾的高层语义特征,用解码器获得烟雾的低层边界特征。经编码器编码后,图像分辨率降为原来的1/16,因此,对高层语义特征进行4倍上采样,将分辨率恢复到原图的1/4;通过1×1卷积对低层边界特征进行压缩,并与高层语义特征进行融合;再通过3×3卷积和4倍上采样,输出与原图大小相等的预测图像。
传统的DeepLabV3+的优点表现在其可以很好地应对多次下采样所带来的分辨率降低的问题。因为烟雾具有模糊以及透明的特点,且大小目标的烟雾特征具有差异性,不适合将DeepLabV3+算法直接应用于烟雾分割,所以本文对该网络做出改进。改进的DeepLabV3+算法结构如图1所示。

图1 改进的DeepLabV3+算法结构Fig.1 Network structure of the improved DeepLabV3+ model
图1的具体改进如下:①在编码器中用MobileNetV2[24]轻量化网络替换Xception网络实现特征提取,确保特征提取更加细致、准确,同时使模型参数量减少和训练时间变短;②从小目标烟雾上来看,烟雾刚起时具有透明的特点,这会使得背景与烟雾杂糅在一起,对网络提取烟雾的特征产生干扰,本文引入CBAM[25],增加通道与样本之间的相关性。
1.2 MobileNetV2
目前大多数主流网络在分类上面表现出卓越的性能,但是应用在分割上时,其精度和速度就会下降,如果使用一个大型网络来提升其精度,那么其计算量也会随之增加。而烟雾图像需要多次提取其特征,使用的卷积核变多,那么其计算量也会呈指数型增加。MobileNetV2是一个轻量级网络,其核心思想是深度可分离卷积和倒置残差网络。MobileNetV2网络与DeepLabV3+的主干网络Xception相比,其核心都是深度可分离卷积,但Xception通过增加网络参数量来比对效果,而MobileNetV2则是通过压缩通道数和提速,即倒置残差模块,使网络参数量明显减少。倒置残差结构如图2所示。

图2 倒置残差结构Fig.2 Inverted residual structure
图2中,输入特征图高为H,宽为W,通道数为C,倒置残差结构先通过维度扩张将输入的特征图升维到原来的6倍大小,通过3×3深度可分离卷积采取信息,最后再通过映射层降维。
倒置残差具体分为3个步骤。
1) 特征提取网络在获取特征图的过程中,通常对高维度做卷积,同时深度可分离卷积在低维度上采样效果表现很差,所以MobileNetV2中先通过1×1卷积升维。
2) 在高维度中通过深度可分离卷积采样,这样既能减少计算量又能获取更多的信息。
3) 在卷积运算中,一般使用ReLU6作为激活函数。由于ReLU6激活函数在做高维运算时会丢失很多信息,所以倒置残差结构的最后一层使用线性激活函数替换ReLU6激活函数;最后再通过1×1卷积还原采集的特征图。
通过倒置残差结构可以使MobileNetV2网络在提取烟雾图像的特征时,具有提升特征提取能力和减少参数量的优点,该算法在提取高分辨率烟雾图像上的表现更为明显。在实际发生火灾的过程中,网络对烟雾需要有极快的反应速度,故本文将参数量较多的Xception网络替换为更为轻型的MobileNetV2网络。
1.3 卷积注意力模块(CBAM)
小目标烟雾由于颜色清淡和模糊抽象的特性,使其与背景黏合在一起,使得原本就不明显的特征在背景的干扰下更加难以提取。本文通过添加CBAM,增加算法对小目标烟雾的特征提取能力,同时本文的数据训练图像来源于烟雾视频的连续单帧图像,空间注意力可以增加烟雾样本图像之间的相关性,增强网络提取特征的能力。CBAM结构如图3所示。

图3 CBAM结构Fig.3 Structure of the CBAM
特征图F顺序经过通道注意力模块和空间注意力模块得到新的特征图Fm,具体流程如下。
1) 通道注意力模块。通道注意力的计算公式如式(1)所示:
Mc(F)=σ(MLP(FAP)+MLP(FMP))
(1)
式中:Mc(F)为通道注意力特征图;σ为sigmoid操作;MLP()为共享神经网络函数;FAP为经过平均池化操作的特征图;FMP为经过最大池化操作的特征图。
首先,将输入的特征图F,分别经过基于宽和高的全局最大池化和全局平均池化,得到2个特征图;其次,将其分别送入共享神经网络并对输出的特征进行基于点对点的加和操作;然后经过激活函数激活,生成最终的通道注意力特征图,即Mc;最后,将Mc和输入特征图F做基于点乘法操作,生成空间模块需要的输入特征。该模块将网络中提取到的烟雾不同特征融合起来,以解决烟雾特征复杂的问题。通道注意力结构如图4所示。
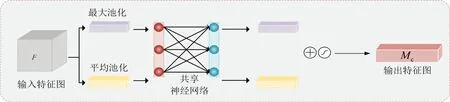
图4 通道注意力模块结构Fig.4 Structure of the channel attention module
2) 空间注意力模块。通道注意力的计算公式如式(2)所示:
Ms(F)=σ(f7×7([FAP;FMP]))
(2)
式中:Ms(F)为空间注意力特征图;σ为sigmoid操作;f7×7为大小为7×7的卷积核;FAP为经过平均池化操作的特征图;FMP为经过最大池化操作。
将通道注意力模块输出的特征图Mc作为本模块的输入特征图。首先,对输入特征图进行基于全局最大池化和全局平均池化的处理,得到2个特征图;其次,将这2个特征图基于通道做拼接操作;然后经过一个7×7卷积操作,降维为1个通道,再经过激活函数激活生成空间特征图,即Ms;最后将该特征图和该模块的输入特征图做乘法,得到最终生成的特征Fm。空间注意力可以加强不同烟雾样本之间的关联性。空间注意力结构如图5所示。

图5 空间注意力模块结构Fig.5 Structure of the spatial attention module
通过卷积注意力机制,小目标烟雾图像在提取特征的过程中,降低背景对特征提取的影响,增强网络对烟雾的感知力,从而提升模型的表现力。
2 实验结果和分析
2.1 火灾烟雾数据集的建立
目前最常使用的火灾烟雾数据集有2个。①中国科学技术大学火灾科学国家实验室的烟雾数据集(http://staff.ustc.edu.cn/~yfn-/vsd.html)。该数据集包含有各种颜色的烟雾图像以及非烟雾图像,但该数据集包含的图像分辨率低,烟雾目标几乎占据整幅图像,对于分割算法来说不具有实际意义。②韩国启明大学CVPR Lab-KMU火灾烟雾数据集(https://cvpr.kmu.ac.kr/)。该数据集加入了白色灯光和白雾等负样本,但烟雾视频和非烟雾视频的分辨率低,且场景单一,不利于提升算法泛化能力,很难训练出具有较强泛化能力的网络。
数据集的建立应包含图像信息和多场景覆盖2个方面,因此本文创建了一个新的数据集,该数据集包含81个烟雾视频,对这81个视频每隔100帧提取一次图像,抽取2 000张烟雾图像,并使用Labelme软件对2 000张图像进行标注,格式为VOC格式。该数据集包含城镇、工厂、学校、森林等19种场景,数据集中的部分烟雾场景图像如图6所示。

图6 数据集中的部分烟雾场景图像 Fig.6 Smoke images of some scenes in the data set
数据集中的烟雾大致分为小目标烟雾和大目标烟雾。大目标烟雾又细分为2种常见颜色的烟雾,分别为白色烟雾和黑色烟雾,以此提高模型的泛化能力以及应对复杂场景的能力。数据集具体情况如表1所示。

表1 实验数据集
2.2 评价指标
本文采用烟雾交并比(sIoU)、平均交并比(mIoU)和类别平均像素准确率(mPA)作为衡量分割烟雾任务优劣的评价指标[26]。sIoU指模型对烟雾这一单独类别预测结果和真实值的交集与并集的比值。mIoU指模型对每一类预测的结果和真实值的交集与并集的比值,求和再平均的结果。mPA指分别计算每个类中被正确分类像素数的比例,最后累加求平均。
2.3 实验配置及模型训练
本系统在Ubantu20.4系统下运行,CPU配置为Intel(R) Xeon(R) Platinum 8255C CPU @ 2.50 GHz,使用NVIDIA RTX 3080显卡进行运算,显存大小为10 GiB,网络框架使用Pytorch 1.10.0搭建,CUDA版本为11.3,Python语言环境的版本为3.8.10实验采用交叉熵损失函数,并使用随机梯度下降(stochastic gradient descent, SGD)的方法优化网络模型,最大学习率为0.007,最小学习率为最大学习率的0.01,训练轮次为100轮,批大小处理为8,输入图像调整为512×512。
2.4 烟雾图像分割结果及分析
改进后的DeepLabV3+算法火灾烟雾数据集上训练100轮。损失值曲线如图7所示。

图7 改进前后的DeepLabV3+算法 Loss值曲线Fig.7 Loss value curve of DeepLabV3+ algorithm before and after improvement
从图7可以看出,2种算法的损失值随着网络训练不断降低,且逐渐趋于平稳,最后收敛。MobileNetV2相比于Xception提取的特征信息更多且更快,所以红色曲线下降速度更快。对比实验表明,改进的算法收敛时间更早,且损失值更低,后期的波动也更小,不存在过拟合的情况。
为充分探究本文提出的多个改进模块对烟雾分割任务的有效性,针对特征提取网络和注意力机制进行消融实验,特征提取网络和注意力机制的消融实验结果如表2所示。其中“—”代表无任何改动。

表2 特征提取网络和注意力机制的消融实验结果Tab.2 Results of ablation experiments for feature extraction network and attention mechanism
表2中,模型1是主干网络为Xception的传统DeepLabV3+模型,其sIoU为84.12%,mIoU为89.54%,mPA为94.93%,训练时间为1.79 h。模型2是主干网络为MobileNetV2的DeepLabV3+模型,其sIoU和mIoU较模型1分别提高了5.38%和3.49%。MobileNetV2与Xception都使用了深度可分离卷积,大大地减小了参数量,使得训练时间减少,但不同之处在于MobileNetV2在通道数上更少,在参数量减小的同时不会影响网络的特征提取。在倒置残差的最后使用线性激活函数代替ReLU6作为激活函数,减小还原特征图过程中损失的特征,使得模型2的分割精度提升。模型3在模型2的基础上引入CBAM,其中sIoU与mIoU较模型2提升了1.08%与0.79%,训练时间几乎没有增加,说明CBAM可以捕获到通道之间的关联性。另一方面本文的数据集来自多个视频的连续分帧图像,所以CBAM可以集中注意力关注输入图像的重要语义信息,也验证了本文多个改进模块对烟雾图像分割任务的有效性。
为证明本文添加注意力的优势,通过添加SE、Channel和Coord来对比其对DeepLabv3+烟雾分割算法的提升效果。不同注意力评价指标对比实验结果数据如表3所示。

表3 不同注意力评价指标对比实验结果Tab.3 Performance comparison of DeepLabV3+ model segmentation using different evaluation indicators 单位:%
表3中,这3种注意力在sIoU的提升分别为0.57%、0.44%和0.9%,mIoU上的提升分别为0.51%、0.41%和0.7%。3种注意力对烟雾分割算法都有一定的提升,但CBAM可以联合通道注意力与空间注意力,为特征图分配更加合理的权重比,所以添加CBAM的算法的mPA最高,为96.65%,均超过其他3种注意力的数据。所以,CBAM相对于其他注意力更适合烟雾分割任务。
为了进一步验证本文改进DeepLabV3+对烟雾图像的分割性能,选用FCN模型、PSPNet模型[27]、主干网络为VGG[28]和ResNet50[29]的UNet模型、主干网络为Xception的DeepLabV3+模型和本文方法做对比实验。6个网络模型的性能对比数据如表4所示,表中“—”代表无数值。本文方法的sIoU为90.58%,mIoU为93.82%,mPA为96.65%,权重大小为23.1 MB。
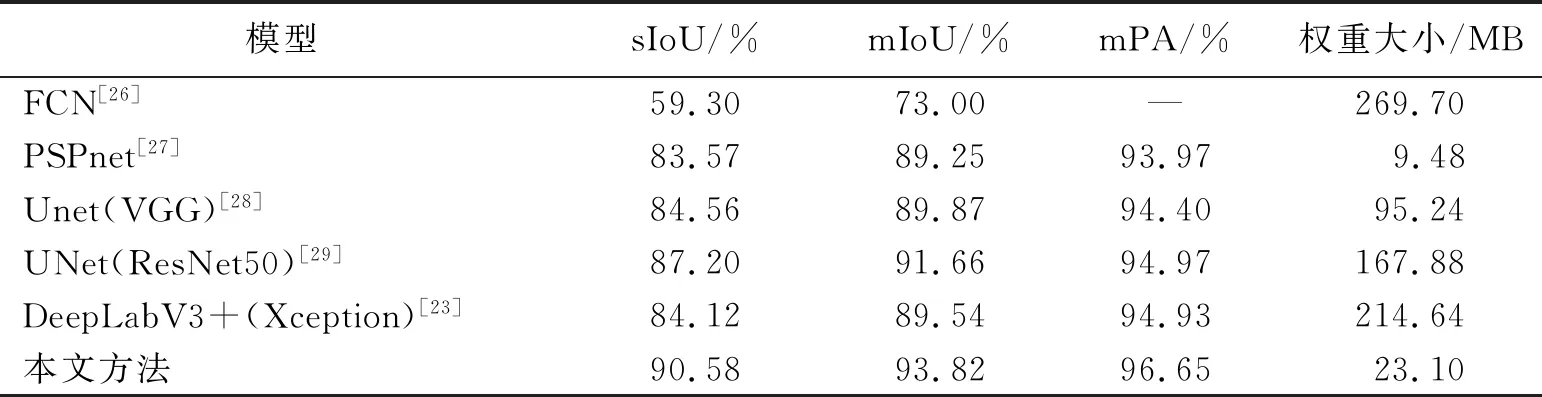
表4 6个网络模型的性能对比Tab.4 Performance comparisons of six network models
从表4可知,改进的DeepLabV3+算法在前3项指标中均高于其他模型,其中sIoU、mIoU和mPA较数据最优的UNet (ResNet50)分别高出3.38%、2.16%和1.68%,由此证明本文方法不仅在整体的精度上高于其他模型,在sIoU上也有较大提升。MobileNetV2作为主干网络,其特殊的倒置残差结构可以在低参数的情况下拥有比其他主干网络更强的特征提取能力,添加CBAM可以做到无参化增强目标特征,有助于提高分割质量,所以本文方法的模型权重也相对较小,只有原模型权重大小的10.76%,但mIoU与原算法相比提升了4.38%。虽然PSPNet的权重最小,但PSPNet的其他3项指标都较低,本文模型与其相比在精度与轻量化之间做出很好的平衡。综上所述,本文改进的DeepLabV3+算法在烟雾分割上与原算法相比有明显提升。
为了直观地感受本文的分割效果,通过选取6张不同场景的烟雾图像,并使用表4中的6种烟雾分割算法对其进行分割,不同算法的实际烟雾分割结果如图8所示。由于FCN效果较其他模型相比分割效果差距较大,失去对比意义,所以在图8中并未放置FCN的分割效果图。

图8 烟雾分割结果Fig.8 Segmentation results of smoke
图8中,第1、2行为小目标烟雾图像,3~6行为大目标烟雾图像。第1行中,当烟雾较小时,其他算法不能完整地将烟雾分割出来,本文方法提取到的烟雾更多。而在第2行中,其他方法会将黑色阴影误判为黑色烟雾,导致分割出现错误,本文方法不仅区别烟雾与阴影,其分割图更贴近标注图。这是因为CBAM更倾向于抓取目标信息,加强算法提取小目标烟雾的能力。在第3、4、5行中,其标注图的烟雾轮廓曲线不再平滑,其他算法的烟雾在分割图边缘是大致拟合标注图,所以曲线更加平滑,造成分割精度下降。本文方法在分割烟雾边缘部分时,更加细致。在第6行中,PSPNet较为粗略地分割出了烟雾图像,但边缘界定较为模糊,而其他3种方法将天空分割到烟雾中,从而产生错误。本文方法区别烟雾与天空的表现更佳。MobileNetV2作为主干网络,通过对特征图升维降维的方法,使算法对烟雾图像信息的提取程度更深,对于前景与目标的差异性学习更强,抑制背景对目标分割所产生的影响,使算法更适用于烟雾分割任务。通过多种形式对比,本文算法在大目标烟雾边缘和小目标烟雾分割上表现更优,改进的DeepLabV3+算法优于原DeepLabV3+算法以及其他烟雾分割算法。
3 结 语
本文提出一种改进的DeepLabV3+烟雾分割算法,该算法通过替换主干特征提取网络和添加CBAM,提升网络提取小目标信息的能力,减少背景对目标的干扰,有效地缓解了烟雾边缘模糊化的问题。实验结果表明,改进的DeepLabV3+算法在测试集上的sIoU提升了6.46%,mIoU提升了4.28%,训练时间减少了26.82%,权重大小降低为原来的10.76%,烟雾分割效果远超其他分割算法,相比于基础模型具有更好的应用价值,对提高火灾预防能力具有重要的意义。在后续工作中将继续改进算法,扩充及改善火灾烟雾数据集,进一步提高烟雾分割效果。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09
小学阅读指南·低年级版(2021年3期)2021-03-19
华人时刊(2019年13期)2019-11-26
电子制作(2018年19期)2018-11-14
当代陕西(2017年12期)2018-01-19
传媒评论(2017年3期)2017-06-13
自动化学报(2017年11期)2017-04-04
第二课堂(课外活动版)(2016年2期)2016-10-21
噪声与振动控制(2015年4期)2015-01-01
科学启蒙(2014年12期)2014-12-09
