
Improved target detection algorithm based on Faster-RCNN
2024-01-08 09:12BAIChenshuaiWUKaijunWANGDicongHUANGTaoTAOXiaomiao
BAI Chenshuai,WU Kaijun,WANG Dicong,2,HUANG Tao,TAO Xiaomiao
(1.School of Electronic and Information Engineering,Lanzhou Jiaotong University,Lanzhou 730070,China; 2.College of Intelligence and Computing,Tianjin University,Tianjin 300350,China)
Abstract:Asymmetric convolution block network is introduced into the Faster-RCNN network model,and it is defined as improved target detection algorithm based on Faster-RCNN.In this algorithm,the convolution kernel of 3×3 in the network model is replaced by the asymmetric convolution block of 1×3+3×1+3×3.Firstly,the residual network ResNet is used as the backbone of the algorithm to extract the feature map of the image.The feature map passes through the convolution kernel block of 1×3+3×1+3×3 and then passes through two convolution kernels of 1×1.Secondly,the regional proposal network (RPN) is used to obtain the suggestion box of shared feature layer,and the suggestion box is mapped to the last feature map of convolution,and the anchor box of different sizes are unified by region of interest (RoI).Finally,the detection classification probability (Softmax loss) and detection border regression (Smooth L1 loss) are used for training.PASCAL_VOC data set is used.The results of mean average precision (mAP) show that the mAP value is increased by 0.38% compared with the original Faster-RCNN algorithm,the mAP value is increased by 2.68% compared with the RetinaNet algorithm,and the mAP value is increased by 3.41% compared with the YOLOv4 algorithm.
Key words:Faster-RCNN; target detection algorithm; asymmetric convolution block; regional proposal network; regional pooling layer
0 Introduction
As one of the basic tasks in the fields of unmanned driving,video monitoring and early warning safety,target detection plays an important role in many researches.Especially in the densely populated places such as railway station,high-speed railway station and airport,the target detection technology is closely related to unmanned driving,video monitoring and security detection,and it is one of the most important research directions in 5G and artificial intelligence.With the rapid development of artificial intelligence and 5G technology,the research direction of using deep learning as target detection has attracted the interests of researchers,which makes deep learning be further developed in the direction of target detection.
The traditional target detection method is divided into two kinds.One is the sliding window method,which needs to consider the aspect ratio of the object in the design of the window.It increases the complexity of the design,and the robustness and efficiency of hand-designed features are poor.The second target recognition method is based on selective search,which uses image segmentation method to connect the two most similar regions each time (depending on the overlapping degree of color,texture,size and shape),and uses the search box to locate the target in each iteration.In a word,the biggest disadvantage of sliding window is the redundancy of selection box,and selective search can effectively remove the redundant candidate box,greatly reduce the amount of calculation.Now,there are two types of object detection methods based on deep learning.The first one is a two-stage target detection method based on R-CNN,Fast-RCNN,Faster-RCNN,and Mask-RCNN,in which Faster-RCNN firstly generates a series of candidate frames,and then uses convolutional neural network to classify the samples.The second is a one-stage target detection algorithm based on regression represented by SSD,YOLOv3,and YOLOv4,which directly transforms the problem of target frame location into a regression problem instead of generating candidate frames.Because of the difference between the two methods,the performance is also different.The two-stage target detection method has advantages in detection accuracy and positioning accuracy,while the one-stage target detection algorithm has advantages in speed.
Aiming at the field of driverless vehicle,the pedestrian,bicycle,battery car,pet,traffic signal,road sign and obstacle are studied.Considering the demand of high precision in the driving of unmanned vehicles,two-stage target detection method is more suitable,the original target detection method has been improved and optimized in this paper.Liu et al.[1]proposed a method to accurately learn and extract the characteristics of the rotating region and locate the rotating target.R-RCNN has three important new components,including the rotating RoI pool layer,the rotation regression model and the non maximum suppression (NMS) multitasking method among different classes.Girshick[2]proposed a method based on fast region for convolutional neural network (Fast-RCNN) for target detection.Fast-RCNN can use neural network to classify objects effectively.Ren et al.[3]proposed a Fast-RCNN,a region recommendation network based on candidate regions,which shared complete image features with detection networks[4-10].RPN is a network of regional recommendations,which can predict the target boundary and target score at each location at the same time.After end-to-end training,RPN generates high-quality region suggestion box,which is used in fast RCNN target detection model.RPN is trained from end to end,and high quality area suggestion box is generated,which is used in target detection model Faster-RCNN.Jeremiah et al.[11]proposed a Mask-RCNN target detection algorithm,which was the latest target detection algorithm for natural image target detection,location and instance segmentation.Lu et al.[12]proposed a new Grid-RCNN target detection algorithm.Grid guided positioning mechanism is used to achieve accurate target detection by the framework.Unlike the traditional target detection method based on regression,Grid-RCNN algorithm can capture spatial information clearly and has the position sensitive property of complete convolution structure.Liu et al.[13]proposed a method of SSD to detect the target in image by using a single convolutional neural network.The output space of the boundary frame is discretized into a set of default boxes,which has different aspect ratio and the ratio of each feature map location.Joseph et al.[14]proposed to predict the target score of each bounding box by using logical regression.Alexey et al.[15]used new functions to combine some of excellent algorithms to achieve relatively good results.
A target detection algorithm is proposed based on the improved target detection algorithm based on faster RCNN.A structure neutral asymmetric convolution block[16]is used as the construction block of convolution kernel,and one-dimensional asymmetric convolution is used to enhance the square convolution kernel.The 3×3 convolution kernel of the basic network structure of the Faster-RCNN algorithm is modified into a (3×3+1×3+3×1) asymmetric convolution block,and the anchor parameters are optimized to improve the coincidence degree between the prior frame and the data set.Although the speed of the algorithm is slowed down,the target detection accuracy of the algorithm is improved.
1 Target detection of ACBNet+Faster-RCNN
1.1 ResNet network
He et al.[17]proposed the residual network ResNet to solve the degradation problem.The basic idea is to provide the residuals of the previous layer to adapt it to the residual mapping,rather than provide an alternative structure[18-19].It is considered that the display of residuals is relatively easy to optimize.And it is easy to set the residuals of the previous layer to zero if the same display is the best compared with the non-linear layer simulation group in extreme cases.A simple execution tag is displayed and added to the stack output as shown in Fig.1.Fast connection can be obtained without any additional parameters or complex calculations.The whole network propagates back through SGD.
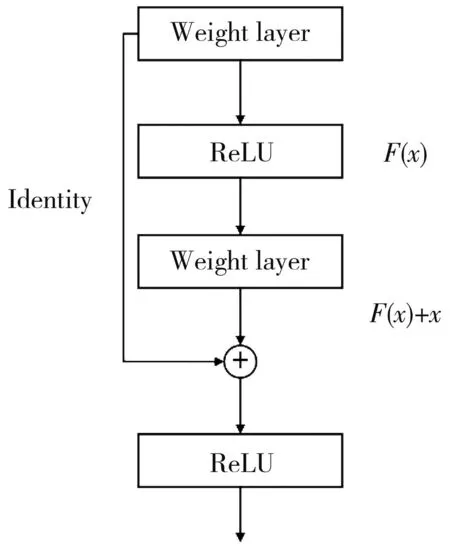
Fig.1 Building block of residual learning
A reference valuexis established for the input of each layer,and a residual function is formed,which is easier to optimize and can greatly deepen the network layer.In the residual blocks above,there are two layers,as shown in Eq.(1).W1,W2,Wiall represent weight,σrepresents the rectified linear unit (ReLU).Then,outputyis obtained through a shortcut and REeLU as shown in Eq.(2).
F=W2σ(W1x),
(1)
y=F(x,{Wi})+x.
(2)
When the dimensions of the input and output need to be changed (such as changing the number of channels),a linear transformationWsofxcan be performed in the shortcut,as shown in Eq.(3).
y=F(x,{Wi})+Wsx.
(3)
Fig.2 shows the network structure of resnet50.It is divided into five stages.In practical application,considering the computational cost,the remaining residual blocks are optimized,that is,the two convolution kernels (3×3) are replaced by asymmetric convolution blocks (1×1+3×3+1×1).
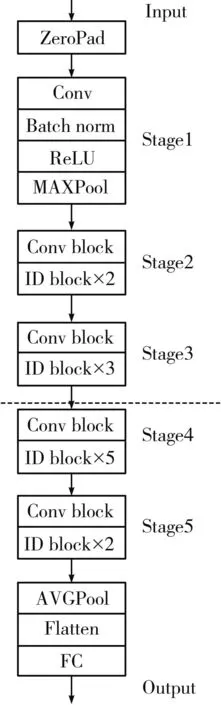
Fig.2 ResNet network architecture
In the new structure,the middle convolution layer (3×3) first reduces the computational complexity to the convolution layer (1×1),and then reverts to another convolution layer (1×1).The accuracy of the precision is maintained and the computational complexity is reduced.The first 1×1 convolution kernel compresses the channel of 256 into 64,which is then restored by 1×1 convolution.
Tears came to my eyes as I realized what I had been a fool to judge Al as a failure. He had not left any material possessions behind. But he had been a kind loving father, and left behind his best love.
1.2 Region proposal network
After inputting the feature map into the network,a series of convolution kernels and ReLU×39×256-dimensional feature map are used to get the anchor points,and then used to select the scheme[20-23].Anchor points are generated,and the anchor point is a fixed size.Each point of the feature map is mapped back to the center point of the receptive field of the original image as the reference point,and thenKanchor points of different sizes and proportions around the reference points are selected.As shown in Fig.3,K=9 anchor points are generated at each slide position by using 3 ratios and 3 aspect ratios.Multiple region suggestions can be predicted by each feature point on the feature map.For example,the number of pixels of 51×51 is generated on the feature graph of 39×39×9 candidate boxes.
As shown in Fig.3,nine candidate boxes are generated for a pixel at a certain position in the feature map.There are 256 channel feature mappings in the input RPN,and different 3×3 sliding windows are used to obtain the convolution value of the pixels in each channel at the same time.Finally,the convolution values of the pixels in each channel are added to obtain a new feature value.The 256-dimensional vector corresponds to two branches.One branch is the classification of the target and the background.The number of candidate boxes of 2K×18 and 256×18Kobtained through the 1×1 convolution kernel is 9.If the candidate frame is the target area,the position of the candidate frame in the target area needs to be determined.The other branch uses the 1×1 convolution kernel to get coordinates of 4K×1×256×36.Each box contains four coordinates (x,y,w,h),which is specific position.If the candidate frame is not the target area,the candidate frame is directly deleted without judging the subsequent position information.
Classification branch:All anchor points of each image in the training set (including manual calibration) are divided into positive samples and negative samples.
1) For each calibrated area,the anchor point with the largest overlap rate is recorded as a positive sample to ensure that each anchor point corresponds to at least one positive sample.
2) For the remaining anchors,if the overlap ratio with the calibration area exceeds 0.7,it is recorded as a positive sample (each can correspond to multiple positive sample anchors).If the overlap ratio of any calibration is less than 0.3,it is recorded as a negative sample.
Regression branch is shown in Eqs.(4)-(7).
(4)
(5)
(6)
(7)
wherex,y,w,hrepresent the center coordinates and width and height of the box;x,xa,x*represent predicted box,anchor box and ground truth box;y,ya,y*represent predicted box,anchor box and ground truth box;w,wa,w*represent predicted box,anchor box and ground truth box;h,ha,h*represent predicted box,anchor box and ground truth box;trepresents the offset of the predict box relative to the anchor box;t*represents the offset of the ground true box relative to the anchor box.The learning goal is to make the former close to the value of the latter.
In the middle of RPN,“cls” and “reg” respectively perform various calculations on these anchor points as shown in Eqs.(8)-(11).At the end of RPN,the initial screening (first remove the out-of-bounds anchor points,and then remove the duplication through the non-maximum suppression algorithm based on the classification results) and the initial offset (according to the regression result) of anchor points are realized by summarizing the results of the two branches.At this point,the output of box becomes proposal.
The offset formulas are shown as Eqs.(8)-(11).
(8)
(9)
(10)
(11)
Because anchor points usually overlap,suggestions for the same object will also overlap.In order to solve the problem of overlapping solutions,the NMS algorithm is adopted.If the intersection over union (IoU) between the two solutions is greater than a preset threshold,the solution with a lower score will be discarded.
If the IoU value is too small,some objects may be lost.If the IoU value is too large,many objects may appear.The typical value of IoU is 0.6.After NMS treatment,the firstnrecommendations are sorted.
1.3 Asymmetric convolution block
Three parallel cores are used to replace the original cores by asymmetric convolution (AC) net,as shown in Fig.4.

Fig.4 Overview of ACNet[16]
Given a network,each squared convolution kernel is replaced by an ACB module and trained to convergence.Then the weights of the asymmetric core in each ACB are added to the corresponding position of the square core,and ACNet is transformed into the equivalent structure of the original network.ACNet can improve the performance of the benchmark model and has obvious advantages in PASCAL_VOC 2007 data.In addition,ACNet introduces 0 parameter,which can be combined with different CNN structures without adjusting the parameters carefully,and it is easy to implement on the mainstream CNN framework without additional inference time overhead.
1.4 Improved Faster-RCNN algorithm
An improved target detection algorithm based on Faster-RCNN is proposed.
Step 1:Use the backbone feature of the backbone network ResNet to extract the Network and obtain a shared feature map.
Step 2:Pass the shared feature map through an asymmetric convolution block,and then pass two (1×1 convolution kernel).
Step 3:Use RPN to generate a bunch of anchor frames first,cut and filter,and then use SoftMax to determine whether the anchor is the foreground or the background.
Step 4:Map the recommendation window to the convolution feature map of the last layer of the convolution kernel,and generate a fixed-size feature map for each RoI through the RoI pooling layer.
Step 5:Use softmax loss function andL1smooth loss function for classification and regression,respectively.
2 Experiment
2.1 Experimental environment and datasets
The experimental environment platform built in this paper has computer configuration i5-8250CPU,8 GRAM,64 bit windows 10 operating system and server configuration GeforceRTX2080×4.This algorithm is implemented on the basis of Faster-RCNN.The data is from PASCAL_VOC 2007,and 5 011 photos of different time,place and light are selected.Labelimg software is used to label the target in the image,and the XML file in VOC format is obtained as the label of the target detection datasets.
2.2 ACBNet+Faster-RCNN target detection algorithm
The model training process is divided into two iterations.In the first iteration,the parameter value of Batch_Size is 2,the parameter value of initial learning rate is 0.000 1,and the parameter value of epoch is 50.In the second iteration,the Batch_Size is set to 2,the initial learning rate is 0.000 01 and the epoch is set to 50.
2.2.1 Mean average precision value
For deep learning target detection algorithm,the detection accuracy of detection algorithm is very important.The mean average precision (mAP) is selected as the evaluation index.AP actually refers to the area under the curve drawn by using the combination of different precision and recall points.When different confidence levels are taken,different precision and recall are gotten.When enough confidence levels dense is obtained,a lot of precision and recall can be gotten.mAP is the average of AP values of all classes.The experimental results of mAP value are shown in Fig.5.
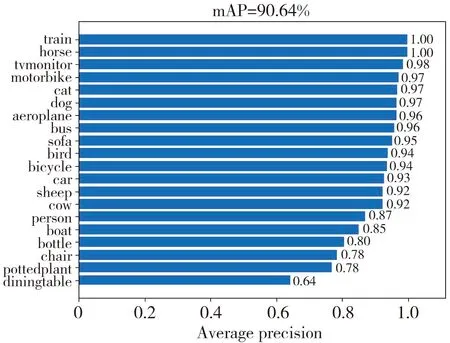
(a) Faster-RCNN algorithm
As shown in Fig.5,the experimental results of mAP of numerical indicators obtained by all methods are presented.The abscissa in Fig.5 is the AP value of a single class.There are 20 classes tested in this experiment.The ordinate is all the classes corresponding to this target detection.The top of each sub graph is the mAP value of each algorithm.From the mAP value at the top of each graph,it can be seen that the mAP numerical results obtained by proposed method are excellent compared with the other three algorithms.The most special one is that the mAP value is increased by 0.38% on the basis of the original Faster-RCNN algorithm.Compared with the RetinaNet algorithm,the mAP value of proposed method is increased by 3.02%.Compared with the YOLOv4 algorithm,the mAP value of proposed method is increased by 3.75%.It further shows that the proposed algorithm plays a good role in the process of target detection.
2.2.2 Log average miss rate (LAMR)
The target detection algorithms of deep learning are generally evaluated by the relationship curve between miss rate (MR) and average false positive per image (FPPI).In this paper,the logarithm mean value of MR when the logarithm of FPPI in the interval[0.01,100]is used as the evaluation standard of data,which is called LAMR for short.The experimental results of LAMR value are shown in Fig.6.
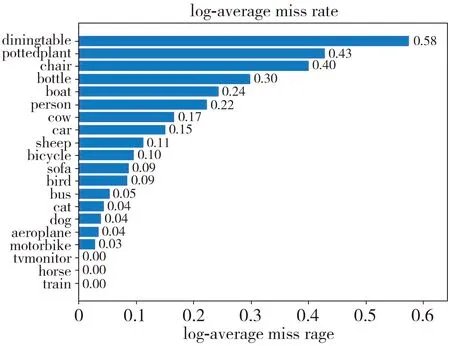
(a) Faster-RCNN algorithm
As shown in Fig.6,the experimental results of numerical index LAMR obtained by all methods are presented.The abscissa in Fig.6 is the MR value of a single class,and the ordinate is all the classes corresponding to this target detection.There are 20 classes in this experiment.LAMR refers to the logarithm average miss detection rate.So the smaller the experimental result of each class,the better the algorithm performance.The LAMR value of miss detection rate shown in Fig.6(a) is less than that of the comparison algorithm in Fig.6(b) and 6(c) among the 20 classes detected,especially the proposed algorithm is improved on the basis of the original algorithm.In the 20 experimental classes,the value of miss detection rate shown in Fig.6(d) is less than that of the original algorithm shown in Fig.6(a),which shows that the proposed algorithm has achieved good results in the process of target detection once again.
3 Conclusions
An asymmetric network block is proposed,which is further combined with the algorithm of Faster-RCNN,so that the 3×3 convolution core is replaced by (1×3+3×1+3×3) convolution core.Without adding any model parameters,the mAP value of the algorithm target detection is improved,the LAMR value of the algorithm target detection is reduced,the detection rate is improved and the stability of the algorithm is enhanced compared the improved algorithm with the original algorithm.
Although relatively good results has been achieved in VOC2007 dataset,there are still two shortcomings in the application of this algorithm in target detection.Firstly,this algorithm is modified on the basis of Faster-RCNN algorithm,which makes the complexity of the algorithm model increase.Secondly,the applicability of this algorithm is very weak.If the model is applied to remote sensing images,railway images or high real-time scenes,its effect is not good.It can be considered to optimize the model,analyze the application scenarios of the target detection algorithm,eliminate the redundancy of the model,adjust the training parameters,and improve the performance of the target detection algorithm,so as to further improve the object detection algorithm based on deep learning in the next step.
 Journal of Measurement Science and Instrumentation2023年4期
Journal of Measurement Science and Instrumentation2023年4期
- Journal of Measurement Science and Instrumentation的其它文章
- A synchronous scanning measurement method for resistive sensor arrays based on Hilbert-Huang transform
- A covert communication method based on imitating bird calls
- Remote sensing images change detection based on PCA information entropy feature fusion
- An image dehazing method combining adaptive dual transmissions and scene depth variation
- Research on restraint of human arm tremor by ball-type dynamic vibration absorber
- Drive structure and path tracking strategy of omnidirectional AGV