
一种基于KNMF的非线性故障诊断方法
2015-01-15 00:32冉永清杨煜普屈卫东
化工自动化及仪表 2015年2期
冉永清 杨煜普 屈卫东
(上海交通大学电子信息与电气工程学院自动化系系统控制与信息处理教育部重点实验室,上海 200240)
随着工业过程控制系统的复杂化和智能化,工业过程产生的数据维数越来越高,非线性增强,传统的基于数据驱动的线性方法(如PCA)的故障检测方法表现明显不如非线性故障检测方法(如KPCA[1,2])。这些方法在过程检测时提取全局信息表征数据特征,然而在一些情况下,数据的局部信息具有更好的表现性能,比如部分数据丢失时,采用局部信息表示数据具有更好的鲁棒性。非负矩阵分解(NMF)是近几年发展起来针对非负数据处理的多元统计分析方法[3],具有天然的稀疏性,能够很好地提取数据的局部特征。但是由于NMF方法在处理非线性数据方面具有明显不足,因此笔者引进核非负矩阵分解方法(KNMF)[4],结合NMF方法的特点和核方法的优点,建立在线故障诊断模型,克服了线性方法处理非线性数据性能低的不足,同时解决了传统核方法表现性能不佳、内存消耗大的问题,实现高效和准确的故障诊断。
1 核非负矩阵分解①
1.1 算法描述
KNMF通过核函数将非线性输入空间的数据映射到线性特征空间,在特征空间内,运用NMF进行特征提取和分析。令输入空间的数据X=[X1,X2,…,Xn]∈Rm×n,通过映射函数Φ(·):Rm→F将数据映射到一个高维的特征空间F内,令特征空间数据矩阵Φ(X)=[Φ(x1),Φ(x2),…,Φ(xn)]∈Rd×n,在特征空间F内进行NMF分解,即寻找一个基矩阵U和一个系数矩阵V,使得:
Φ(X)≈UVT
(1)
其中U∈Rd×r,d的数值非常大,r表示降维后的维数;V∈Rn×r。
假设基矩阵U的每一列满足下列等式:
uj=Φ(x1)W1j+Φ(x2)W2j+…+Φ(xn)Wnj
(2)
则基矩阵U是特征数据Φ(X)的凸组合,即:
U=Φ(X)W
(3)
其中W∈Rn×r,并且W的每一列之和等于1。
在特征空间F中,把特征数据分解成如下形式:
Φ(X)≈Φ(X)WVT
(4)
将原NMF分解算法需要找到基矩阵U和系数矩阵V,转化成寻找参数矩阵W和系数矩阵V。
在特征空间内,采用欧式距离来度量特征数据矩阵Φ(X)与Φ(X)、参数矩阵W、系数矩阵V三者乘积之间的误差,将KNMF问题转化为求取参数矩阵W和系数矩阵V,并使以下目标函数取得最小值:

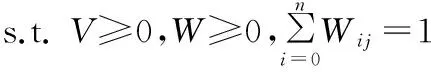
(5)
其中K为核矩阵,K=Φ(X)TΦ(X)。
对于上述目标函数,分别以W或V为变量的最小化问题的时候是凸函数,但是同时以W和V为变量是非凸函数,因此要找到两个优化问题的全局最优解是不可能的,只能给出局部最优解。
[KWVTV-KV]⊙W=0
(6)
[VWTKW-KW]⊙V=0
(7)
根据式(6)、(7)得出参数矩阵W和系数矩阵V的更新规则:
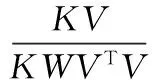
(8)
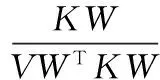
(9)
1.2 几何意义
KNMF算法的目标是在特征空间内寻找一个凸包尽可能地把所有数据都包含在内,那么就可以根据凸包性质,所有在凸包内的点都可以通过所有凸包边界的一个凸组合表示,故KNMF算法训练的目标就是寻找到特征空间数据内的所有凸包边界点,即特征数据点,构成这个凸包。特征空间内的数据点和特征数据点如图1所示。
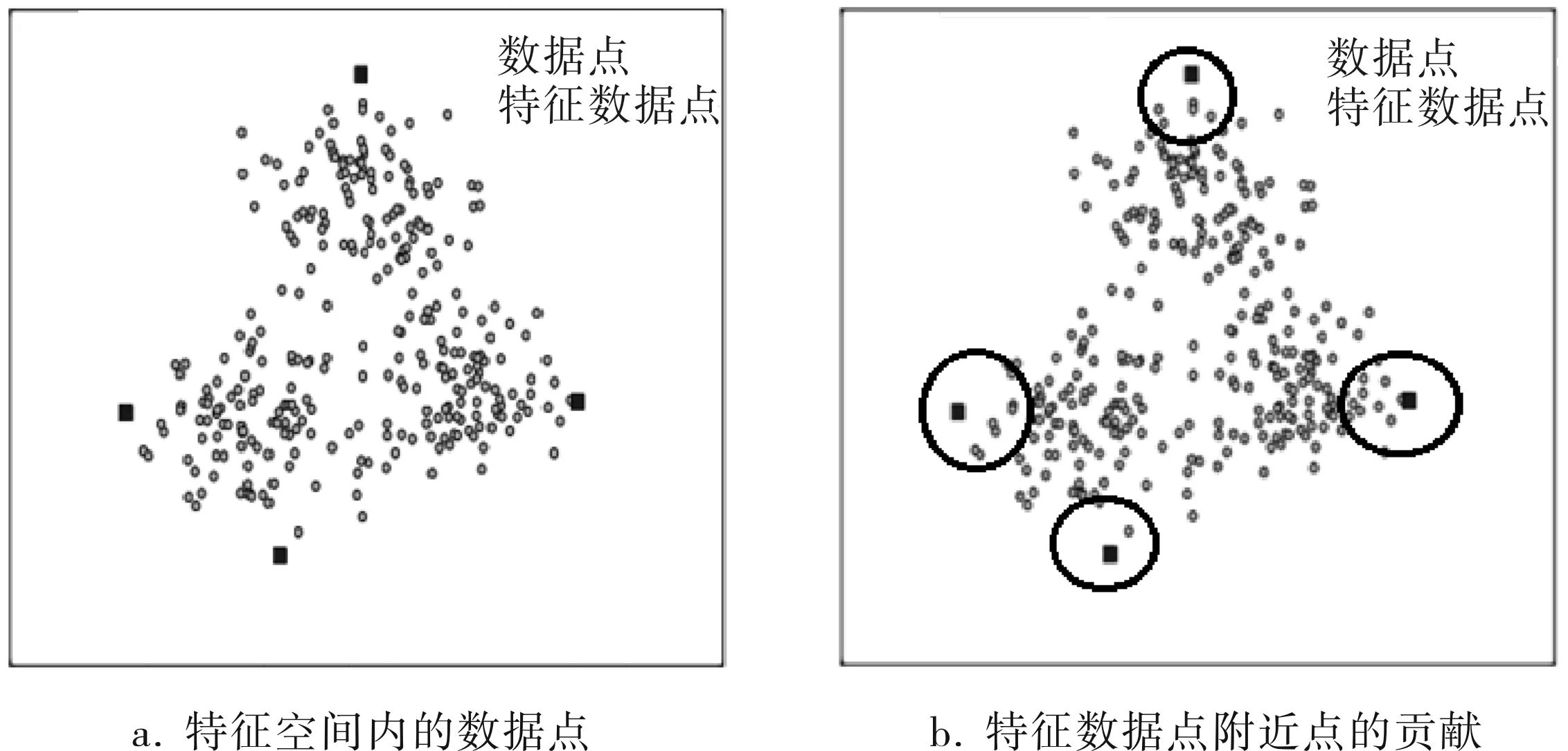
图1 特征空间内的数据点和特征数据点
从式(3)得出,基矩阵U是特征数据Φ(X)的一个凸组合,展开式(3),得到:
(10)
其中参数矩阵W的每一列之和为1。寻找的凸包能够包含所有的特征数据点,并且每一个特征数据点是所有数据点的一个凸组合,所以离特征数据点越近的点,对于构成特征数据点的影响就越大,那么对应参数矩阵W中的数值就越大。在图1b中圆圈内的点对构成特征数据点的系数影响最大,在参数矩阵W中数值相对较大。这个性质使得训练出来的参数矩阵W具有很好的稀疏性[5],即在矩阵中有很多元素都是0,只有少数元素不是0。
2 基于KNMF的故障检测模型
首先获取实际工况中产生的正常数据Y,Y∈Rm×n,其中m为变量个数,n为采样点数。由于每一个变量的量纲不同,先对数据做标准化处理,设处理后的数据为X,X∈Rm×n,对X运用KNMF算法进行训练,得到参数矩阵W和系数矩阵V。当用于在线检测时,设某一次的采样数据为x,x∈Rm,则:
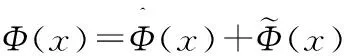
(11)
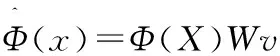
(12)
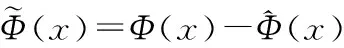
(13)
其中式(12)中的v为对应采样数据的重构系数,即:
v=(WTKW)-1WTKx
K=Φ(X)TΦ(X)
(14)
Kx=Φ(X)TΦ(x)
式(12)表示特征数据在主空间的投影,式(13)表示特征数据在残差空间的投影。
根据式(12)、(13)定义两个统计量K2和SPE,分别为:
K2=vTv
(15)
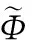
(16)
在特征空间F内,K2反映了训练得到的模型空间内的能量波动情况,SPE反映一个测量数据到模型空间的距离,反映测量值的偏离程度。
由于构造的统计量不满足高斯过程数据特征,所以不能运用常用方法确定其控制限,笔者采用核密度估计方法[6],并选取了99%的置信水平确定控制限。
3 基于KNMF的故障辨识
将上述基于KNMF的故障检测模型运用到实际工况中进行在线检测,当检测计算结果小于控制限时,认为过程是正常状态,当超过控制限时,认为过程是故障状态。当过程发生故障的时候,需要快速并准确地找到故障所在,确定故障变量,从而可以快速排除故障,避免故障带来的灾难。
当运用K2统计量和SPE统计量检测到故障时,笔者采用贡献图[7]的方式,确定故障变量。对应K2和SPE每一个变量所做贡献值的计算如下:
(17)
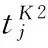
(18)
其中,下标j表示第j个变量,j=1,2,…,m;δj表示m×m单位矩阵的第j列。
通过式(17)、(18)可以确定发生故障时每一个变量对于此次故障的贡献值,变量贡献值越大越有可能发生故障,那么就越有可能就是故障发生的位置所在,在排除故障时,应该首先检查此位置。
4 仿真实验
TE过程是基于实际工业过程的仿真案例[7]。它由连续搅拌式反应釜及气液分离塔等多个设备组成。训练集包含500个样本数据,测试集由前160个正常数据和后800个故障数据构成。图2是TE过程结构图,表1是KNMF算法与传统算法故障检测率的比较。
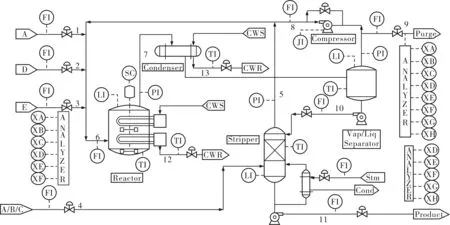
图2 TE过程结构
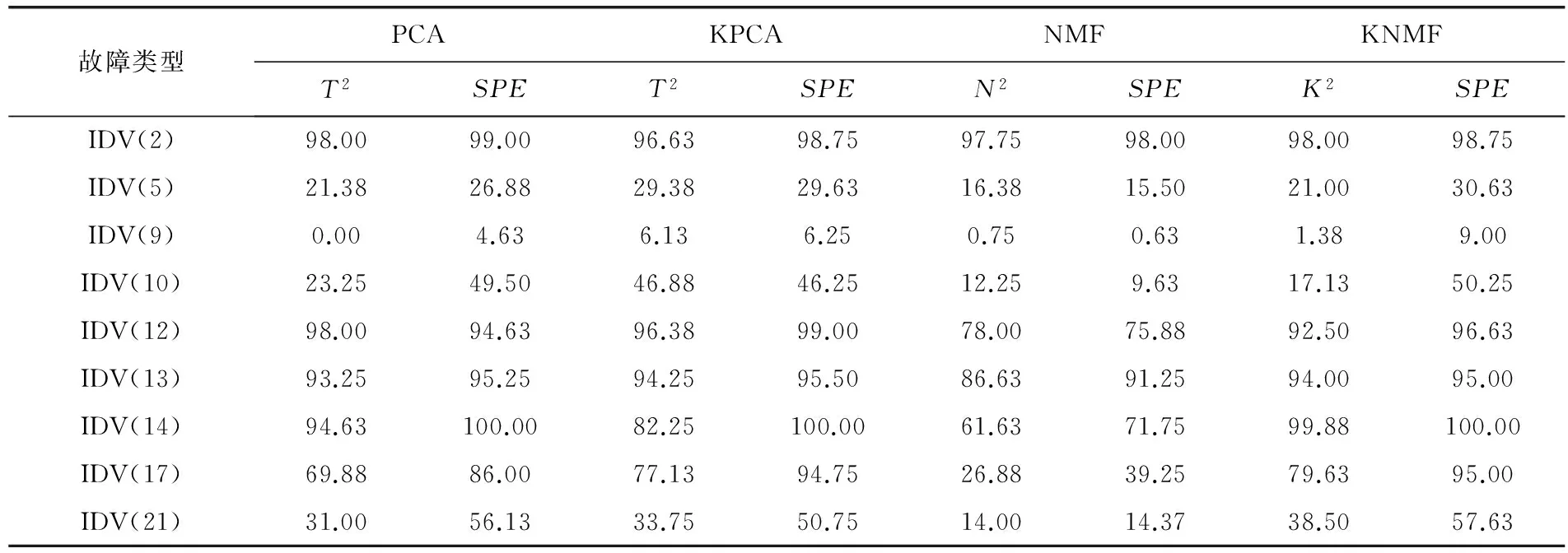
表1 KNMF算法与PCA、KPCA和NMF的故障检测率比较 %
从表1可以看出,基于核方法(KPCA和KNMF)的检测效果在某些故障检测方面优于线性方法(PCA和NMF),而KNMF方法与KPCA方法在故障检测方面各有优势。
图3给出了故障IDV(14)各个方法的故障检测图。

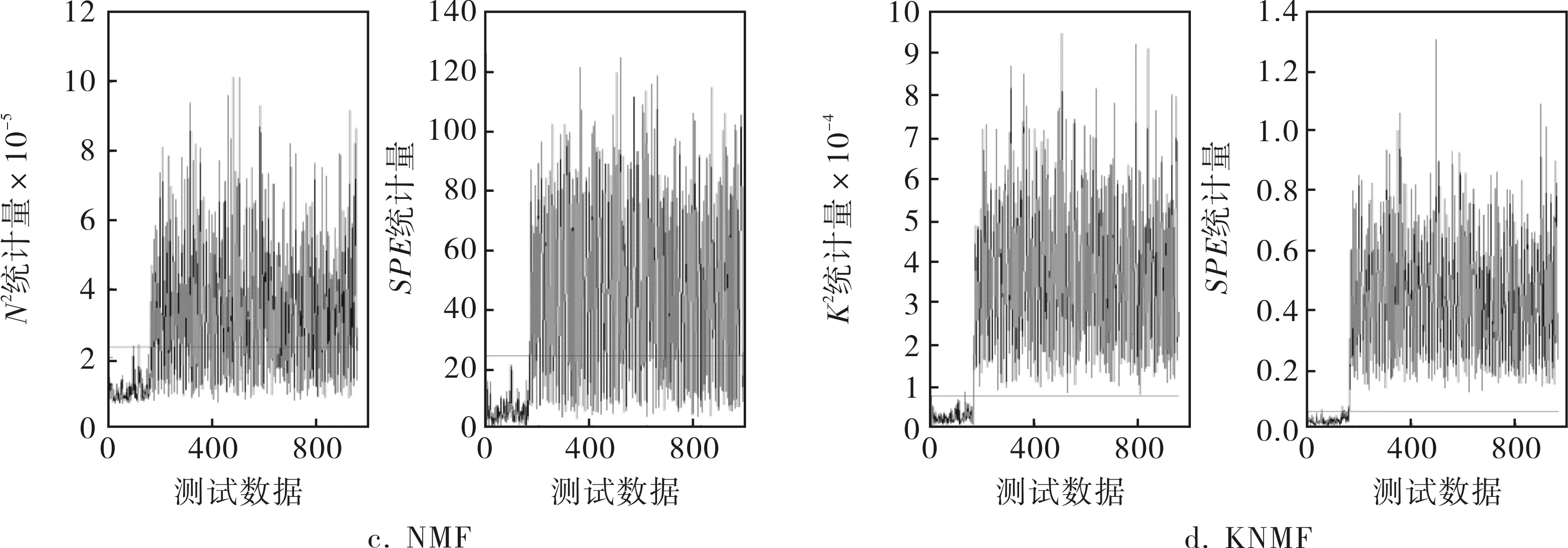
图3 故障IDV(14)发生时,KNMF与PCA、KPCA和NMF的检测率对比
IDV(14)表示的是反应器冷却水阀门的变化情况,当故障IDV(14)发生时,那些与反应器相关的变量都会产生影响,如反应器中的温度(变量9)、冷却水的流速(变量32)和反应器冷却水出口温度(变量21)。当故障IDV(14)发生的时候,各个变量的贡献值如图4所示。从贡献图来看,这3个变量的贡献值明显很大,而其他变量贡献值相比之下基本可以忽略,这与分析结果完全相符,这就验证了该方法的有效性。
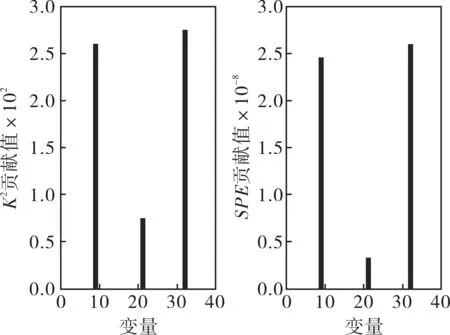
图4 IDV(14)发生时,受影响的主要变量和所有变量的贡献值
5 结束语
笔者提出的基于核非负矩阵分解方法(KNMF)的故障检测方法,解决了传统方法处理非线性方法的不足,同时得到的W或V具有天然稀疏性,减少内存消耗,克服了其他核方法消耗内存大的不足,在一定程度上能够加快运算速度。设计了监控统计量K2和SPE,适用于在线故障检测,并且建立了完整的故障诊断模型。当检测到故障的同时,给出可能引起此故障的变量。最后将KNMF算法运用于TE平台进行仿真,仿真结果表明了基于KNMF的方法在故障检测方面的可行性和有效性。在今后的工作中,可进一步完善故障诊断模型,提高故障检测速度和精度,提高故障辨识的准确性。
[1] Fan L P,Yu H B,Yuan D C.Monitoring of SBR Process Using Kernel Principal Component Analysis[J].Chinese Journal of Scientific Instrument,2006,27(3):249~253.
[2] 范玉刚,李平,宋执环.基于特征样本的KPCA在故障诊断中的应用[J].控制与决策,2005,20(12):1415~1418,1422.
[3] An S, Yun J M, Choi S. Multiple Kernel Nonnegative Matrix Factorization[C].2011 IEEE International Conference on Acoustics,Speech and Signal Processing(ICASSP).Prague:IEEE,2011:1976~1979.
[4] Lee H,Cichocki A,Choi S.Kernel Nonnegative Matrix Factorization for Spectral EEG Feature Extraction[J].Neurocomputing,2009,72(13):3182~3190.
[5] Hoyer P O.Non-negative Matrix Factorization with Sparseness Constraints[J].The Journal of Machine Learning Research,2004,5:1457~1469.
[6] Botev Z I,Kroese D P.The Generalized cross Entropy Method, with Applications to Probability Density Estimation[J].Methodology and Computing in Applied Probability,2011,13(1):1~27.
[7] Yoon S,MacGregor J F.Fault Diagnosis with Multivariate Statistical Models Part I: Using Steady State Fault Signatures[J].Journal of Process Control,2001,11(4):387~400.
猜你喜欢
小学生学习指导(高年级)(2021年4期)2021-04-29
河北理科教学研究(2020年2期)2020-09-11
中学生数理化·七年级数学人教版(2018年11期)2019-01-31
娃娃乐园·综合智能(2018年23期)2018-12-26
娃娃乐园·综合智能(2018年3期)2018-03-22
中央民族大学学报(自然科学版)(2016年3期)2016-06-27
中国照明(2016年6期)2016-06-15
南都周刊(2015年4期)2015-09-10
南都周刊(2015年3期)2015-09-10
南都周刊(2015年1期)2015-09-10
