
基于社交网络的BA无标度演化模型的研究
2017-07-19 10:08王筱蕾
三门峡职业技术学院学报 2017年2期
◎王筱蕾
(西北政法大学 图书馆,西安 710122)
基于社交网络的BA无标度演化模型的研究
◎王筱蕾
(西北政法大学 图书馆,西安 710122)
针对社交网络中用户间好友关系的特殊性,结合重启特征和稀疏网络平滑特征,提出了PageRank改进算法PRS;针对BA网络模型的缺陷以及实际社交网络的连接特性,将改进算法PRS作为择优连边考量因素之一,加入随机连边机制,构建了一种适合社交网络的BA无标度网络的改进模型。实验证明,改进模型具有更优的网络特性,适合构建与描述社交网络。
PageRank算法;BA无标度网络;社交网络;改进模型
近年来,社交网络因其发展迅速、用户量巨大已成为最有影响力的信息交互平台。掌握社交网络的内部结构以及生长模式,对社交网站的建立与维护有着重要的理论指导意义。社交网络作为复杂网络的一个典型代表,其内部结构与生长特征都符合复杂网络的特点。目前,多数研究者使用复杂网络中的经典模型——BA无标度模型来描述社交网络。然而,社交网络因其自身特殊性,其节点具有多重连接方式且网络特征参数多变。使用具有单一节点连接方式和网络特征参数的BA无标度模型无法全面描述社交网络[1]。针对这一问题,本文将借鉴BA无标度模型的构造算法以及网页影响力排名算法PageRank,使用回顾性模拟的网络建模方法,对传统BA无标度模型进行,以期更全面准确的描述实际社交网络的特征。
1 BA无标度模型算法介绍及缺陷分析
1.1 BA无标度模型算法
BA无标度网络模型的构造算法[2]如下:
(1)增长:在一个具有m0个节点的网络中,依次连入新节点,直到新节点被连接到已存在的m个节点上,这里m≤m0。
(2)择优连接:单个已存在的节点i和单个新节点,它们能被连接到一起的概率∏(ki)与j节点的度kj以及i节点的度ki之间满足以下关系:
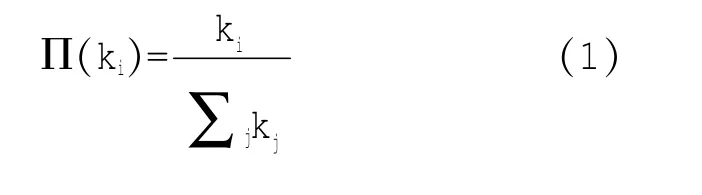
1.2 缺陷分析
首先,连接机制选择。BA无标度网络模型的连接机制考虑的是择优连接,然而在实际网络中节点之间的连接机制不仅仅为择优连接,还存在随机连接,例如,在社交网络中,用户在添加好友时除了会优先选择一些好友以外,还会随机添加一些感兴趣的陌生人,因此在构造社交网络模型时必须考虑到随机连接这一条件。
其次,择优连接的条件。BA无标度网络模型的择优连接机制中考虑的是节点的度数,即度越大,被选择连接的可能性越大,在社交网络中,每个节点就是用户,节点的度就是用户的好友数目,因此,BA无标度网络模型的连接条件在社交网络背景下就是用户倾向于与好友数目较多的用户建立连接,显然这一观点是片面的,在实际的社交网络中,用户除了会选择好友数目多的用户建立连接外,用户的影响力也是十分重要的因素,如新浪微博中有一个名人影响力排名,通过一定的算法算出网络上的名人影响力,并对其排名,一般用户会根据影响力的大小选择与其建立连接。因此,在构造社交网络模型时,择优连接中应当考虑到影响力因素。
2 基于社交网络的BA无标度演化模型
2.1 PageRank算法介绍及改进
经典网页排名PageRank算法为每个网页设定PR值为网页的影响力分数,借鉴PageRank算法的思想来对社交网络中每个用户进行影响力估算[3],为了更准确地计算用户的影响力,笔者对原PageRank算法进行改进,使用改进的PageRank算法来计算社交网络中用户的影响力大小。
2.1.1 PageRank算法介绍
PageRank算法[4]又称网页排名算法,是Google搜索引擎中的重要算法。算法思想是:当网页A有一个链接指向网页B时,就认为网页B获得了一定的分数,该分值的多少取决于网页A的重要程度,即网页A的重要性越大,网页B获得的分数就越高。由于网页上的链接相互指向的复杂程度,该分值的计算过程是一个迭代过程,最终网页将依照所得的分数进行排序并将结果送交给用户,这个量化了的分数就是PageRank值。
要计算网页A的PR值,就得利用指向它的网页Ti的PR值,这就导致要求解一个巨大的方程组,然而复杂网络中的结点是非常多的,求解这个方程组往往不现实的[5]。针对这一问题,笔者引入马尔科夫假设,结合重启特征与平滑特征,给出经典PageRank算法的求解方法:
Step1.由网络邻接矩阵A经过行归一化得到矩阵W;
Step2.确定PageRank初始向量p0的值;
Step3.反复迭代经典PageRank算法计算公式pt+1,直到pt和pt+1的夹角余弦小于某一个小的阈值ε时停止;
Step4.pt即是各个结点的重要性向量,对其按照从大到小的顺序排序,就可以得到节点重要性的排序结果。
2.1.2 PageRank算法改进
传统的PageRank算法存在以下两个问题:
(1)实际中存在用户回退浏览不同页面的情况,这个因素不应该被忽略,而上面原始的计算PR值公式并没有考虑到这一点。
针对这一问题,笔者将引入一个较小的系数d,作为重置系数,并结合经典PageRank算法给出计算公式。用户在网上浏览网页时,可能会以某个概率跳转到下一个页面,当然也可能会回到上一个页面。不妨假设用户在每一次浏览网页时都可能会以一定的概率去浏览当前页面的邻居,还会有一定的概率回到初始浏览的网页,所以对于向量p,改为如下定义:

其中,d是一个介于0到1之间的常数,叫做重启系数,即冲浪者以d的概率回到原点,并且d∈(0,1];p0表示初始向量。从上式可以看出,用户每次跳转网页时都会以概率d回到原始的网页,或者按照概率去跳转到其他网页。对于复杂网络而言,重启特征会使得PageRank算法更加精准。
(2)网页之间的链接的数量相比互联网的规模非常稀疏,因此计算网页的网页排名也需要对零概率或者小概率事件进行平滑处理。
针对这一问题,笔者将引入一个很小的系数c,作为平滑处理系数。对于互联网网络而言,网页结点之间链接的数量相比互联网节点的规模比较稀疏,社交网络中,用户的连接关系数目较网络节点规模也十分稀疏。因此计算网页的网页排名也需要对零概率或者小概率事件进行平滑处理。由于网页的排名是个一维向量,对它的平滑处理可以利用一个小的常数c,表达如下:
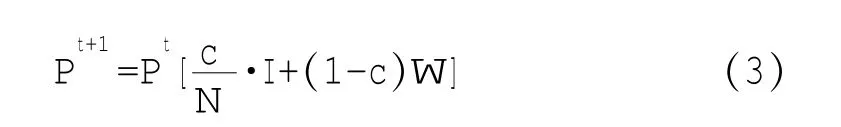
其中,N表示互联网网页的数量,c是一个介于0到1之间的常数,称为平滑系数,I是单位矩阵。上式通过平滑系数c,来对零概率或者小概率事件进行平滑。
综合以上两个特征,笔者将以上改进算法PRS计算过程总结如下:
Step1.由网络邻接矩阵A经过行归一化得到矩阵W;
Step2.确定PRS初始向量p0的值;
Step4.pt即是各个结点的重要性向量,对其按照从大到小的顺序排序,就可以得到结点重要性的排序结果。
2.2 演化模型构建思想
前面介绍了BA无标度网络模型的算法,并分析了该算法应用到社交网络中的缺陷,针对该缺陷以及社交网络的实际特征来构建适合描述社交网络的演化模型。
首先,BA无标度网络模型的连接机制是择优连接,然而在实际的社交网络中,用户选择好友并不总是择优选择[6,7],除了有选择性的添加好友以外还会随机的添加一些陌生人作为好友,也就是存在一定概率的随机选择,因此应当设置一个参数p(0≤p≤1),p表示用户择优选择的概率,那么1-p则表示用户随机选择的概率,p=0时表示网络中所有用户的连接全部都为随机连接,p=1则表示网络中所有用户的连接全部都为择优连接。
其次,在BA无标度网络模型的择优连接中是以节点的度作为衡量标准,节点的度越大,越容易与其他节点建立连接,在社交网络中就是指一个用户倾向于选择好友数多的用户来建立好友关系,客观地说,这一观点是片面的,实际上用户选择好友的标准不仅仅看一个用户的人气,影响力也是不容忽视的一个因素,用户倾向于选择人气高或者影响力大的用户来建立好友关系。在考虑影响力时,这里利用改进的PageRank算法PRS,将社交网络中的每个用户视为因特网中的每个网页,像对每个网页投票一样为每个用户投票,并设置PRS值,PRS值越高表示该用户的影响力越大。算法开始时,为每个用户分配一个相同的PRS值,然后进行迭代计算,每个用户把自己的PRS值平均的分配给与其有连接关系的好友,然后每个用户根据所得的权值进行求和,以此来对每个用户的PRS值进行更新,在每一轮计算中用户的PRS值都会更新,直到算法结束。因此,设置参数a(0≤a≤1),a表示用户选择人气高即好友数多的用户来建立好友关系,1-a表示用户选择影响力大的即PRS值高的用户来建立好友关系。当a=0时表示网络中的用户在择优选择时只以影响力作为衡量标准,只选择影响力大的用户来建立好友关系。当a=1时表示网络中的用户在择优选择时只选择人气高的用户来建立好友关系,也就是BA无标度网络中的择优连接思想。
另外,在实际的社交网络中存在不同的社群,同一社群中的用户联系相对比较紧密,具有较大的聚类系数以及较小的平均路径长度,而没在社群中的用户则可能互相联系较少、聚类系数较小且平均路径长度较大。然而普通的BA无标度网络模型的聚类系数以及平均路径长度是固定的,无法综合的描述实际社交网络的多种情况,因此需要一种具有可变聚类系数和可变平均路径长度的模型来描述实际的社交网络。通过调节参数p,a,我们可以控制随机连接和择优连接,以及择优连接中度数和影响力的比例。
2.3 演化模型构建算法
(1)增长:在一个具有m0个节点的网络中,依次连入新节点,直到新节点被连接到已存在的m个节点上,这里m≤m0。
(2)择优选择:一个新节点与网络中已有的节点相连接,且选择节点i概率与节点度成正比,即

选择这种操作的概率为a,这里将a记为度指数;
新节点与网络中已有的节点相连接,且选择节点i概率与节点的影响力(PRS值)成正比,即

选择这种操作的概率为1-a。
这里假设择优选择的选择概率为p,将p记为择优指数。
(3)随机选择:在已有网络中随机选择一个节点与新节点连接。随机选择的选择概率为1-p。
在改进模型构造算法中,任意两点之间的距离为1,且连边总是由老节点指向新节点,所以改进模型为有向无权网络。所引入的两个参数p和a都是可以调节的,当p=1且a=1时,改进模型退化为基本的BA无标度网络模型。
在改进模型中,新节点以概率a随机选择网络中的已有节点进行连接,以概率1-a进行择优选择,在择优选择中,以概率p选择度数大的节点进行连接,以概率1-p选择影响力高(即PRS值大)的节点进行连接。
3 .仿真结果
采用Matlab R2013a在Windows7环境下模拟仿真改进模型的网络生成过程,并编程得出模拟网络的度分布示意图,并调整参数得出不同条件下的平均路径长度、聚类系数变化图。
3.1 度分布
对于改进模型的度分布,我们设计了三组不同的实验,当参数取不同值时,来验证生成网络的度分布是否符合幂律分布。每组实验的设计思想是,固定一个参数,使另外两个参数两两变化,观察度分布图形,然后改变固定的参数,再观察度分布图形。在第一组实验中,分别设置d=0.2和d=0.6得到图1、图2中的双对数坐标下的改进模型度分布图。在两个图中使用符号“*”表示a=0.1,p=0.2时的度分布图,命名为A分布;使用符号“+”表示a=0.5,p=0.2时的度分布图,命名为B分布;使用符号“o”表示a= 0.1,p=0.6时的度分布图,命名为C分布。
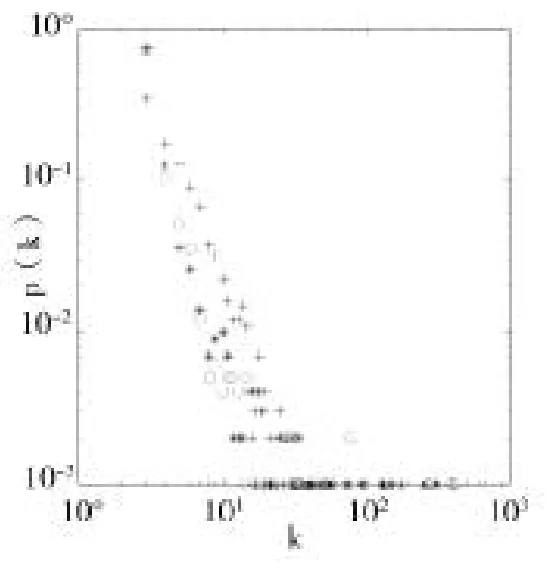
图1 d=0.2时改进模型度分布
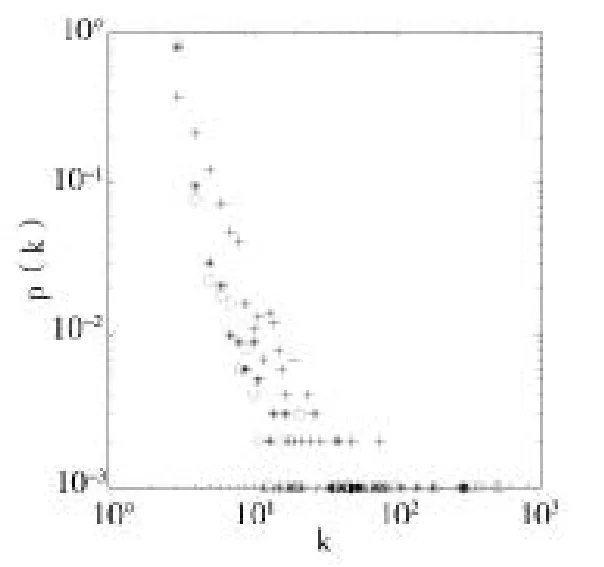
图2 d=0.6时改进模型度分布
在这组实验中,以上两图中B分布与A、C分布稍有差异,也就是说,当a取0.1时,度较大的节点数较多,当a取0.6时,度较小的节点数较多。
在第二组实验中,分别设置a=0.2和a=0.6得到图3、图4中的双对数坐标下的改进模型度分布图。在两个图中使用符号“*”表示d=0.1,p=0.2时的度分布图,使用符号“+”表示d=0.5,p=0.2时的度分布图,使用符号“o”表示d=0.1,p=0.6时的度分布图。
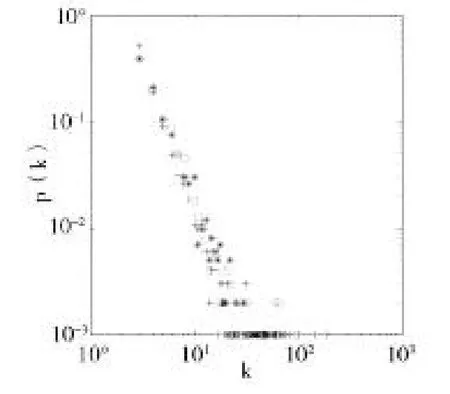
图3 a=0.2时改进模型的度分布
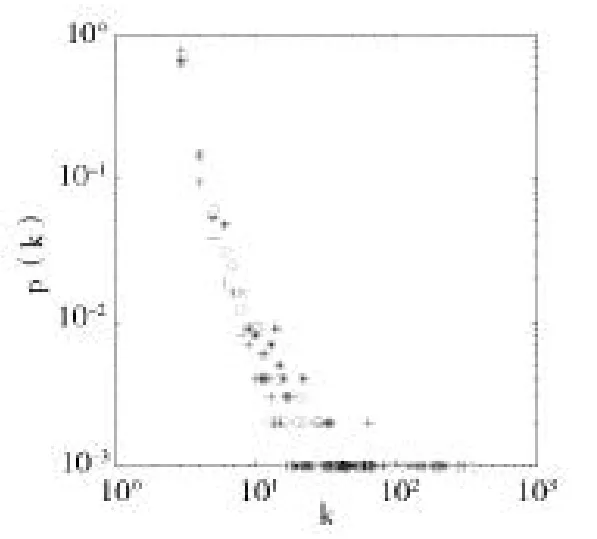
图4 a=0.6时改进模型的度分布
在这组实验中,从以上两个图可以看到改变a值的大小,度分布图的形状有变化,a取0.2时三种不同情况的度分布可拟合的直线斜率略大于a取0.6时。
在第三组实验中,分别设置p=0.2和p=0.6得到图5、图6中的双对数坐标下的改进模型度分布图。在两个图中使用符号“*”表示d=0.1,a=0.2时的度分布图,使用符号“+”表示d=0.5,a=0.2时的度分布图,使用符号“o”表示d=0.1,a=0.6时的度分布图。
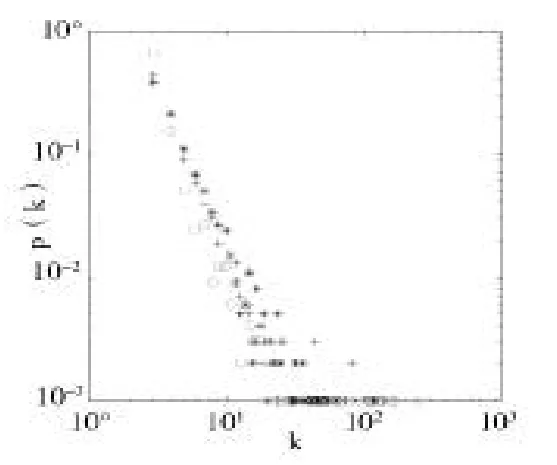
图5 p=0.2时改进模型的度分布
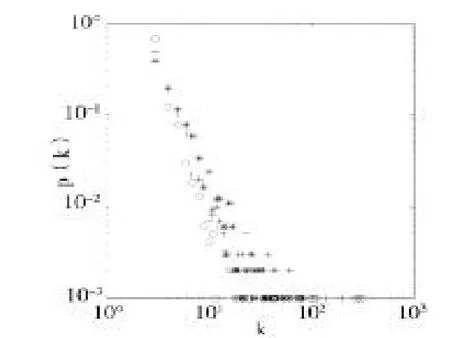
图6 p=0.6时改进模型的度分布
在这组实验中,由以上两图的度分布可以看到,p值取0.6时,度分布较为均匀,度数小的节点出现的概率较p取0.2时多一些,度数大的节点出现的概率较p取0.2时少一些。
由以上的6张图可以看到,在取不同的参数下,改进模型都呈现出幂律分布,与BA模型一样具有“胖尾”特征,不同之处在于,度数的大小与出现的概率大小不一致。也就是说,在改进模型中,随机选择与择优选择的比重以及择优选择采用哪种方式均不会影响模型的度分布特征。
3.2 聚类系数与平均路径长度
以上的节点度分布图说明了改进模型与BA模型一样具有幂律特征,为了进一步分析改进模型的网络特征,我们还对该网络模型的聚类系数以及平均路径长度进行了仿真,分别设置不同的参数取值来对比分析。由于d、a、p的值均在0到1之间,这里d和p我们分别去三个值:0.1、0.5、0.9,a从0.1取到0.9,得到不同的聚类系数与平均路径长度。
分别选取d和p值为0.1、0.5、0.9,a从0.1取到0.9,作出不同参数取值时改进模型的聚类系数和平均路径长度。图7到图9分别为d取0.1、0.5、0.9时改进模型的聚类系数变化图。
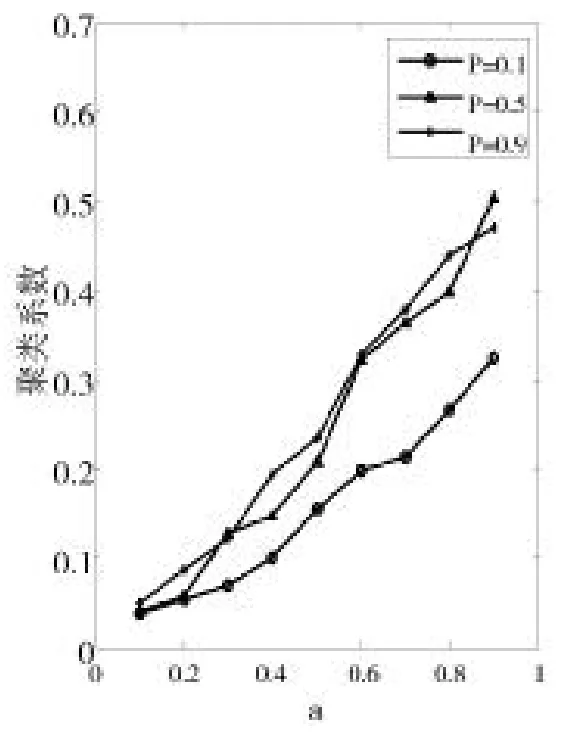
图7 聚类系数(d=0.1)

图8 聚类系数(d=0.5)
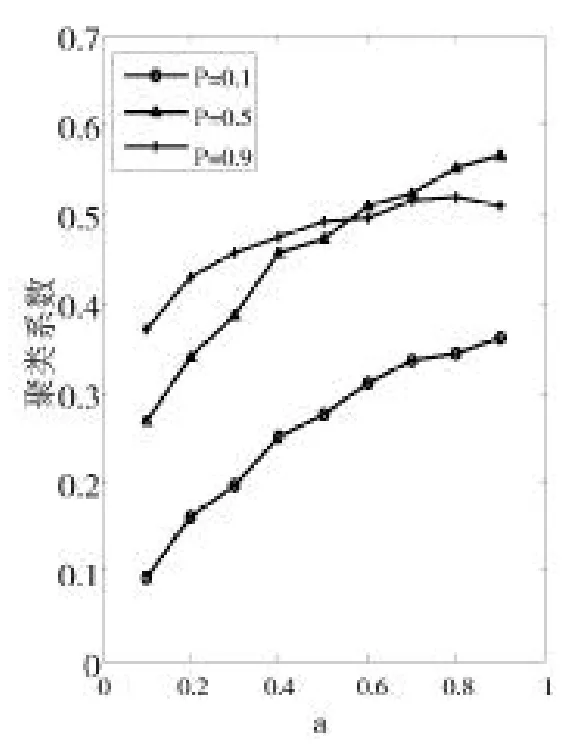
图9 聚类系数(d=0.9)
观察以上三图,图7和图8中聚类系数总体会随着a值的增加呈上升趋势,而图9中聚类系数的变化趋势与前面两图有所不同,红色折线(p=0.9)在a=0.5之后趋于平稳,说明在d和p取得较大值0.9的情况下,当a取值大于0.5时,聚类系数不再逐渐增加而是趋于一个相对平稳的值。因为当d,p,a同时取得较大值时,用户之间进行连接时,随机因素削弱,用户影响力得分逐渐取决于固定的旧好友的PRS值,这使得连接方式趋于固定,因此,聚类系数逐渐趋于平稳。
图10到图12分别为d取0.1、0.5、0.9时改进模型的平均路径长度变化图。
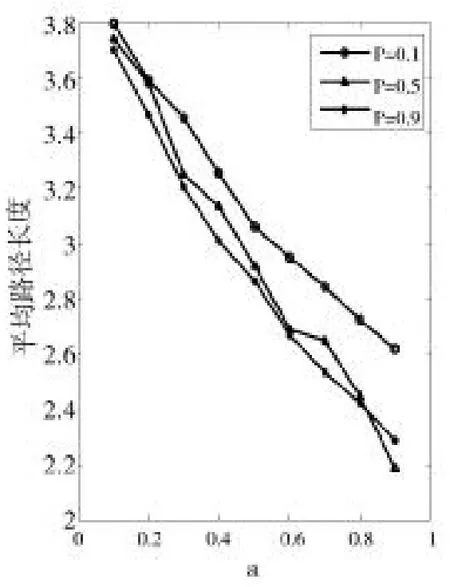
图10 平均路径长度(d=0.1)
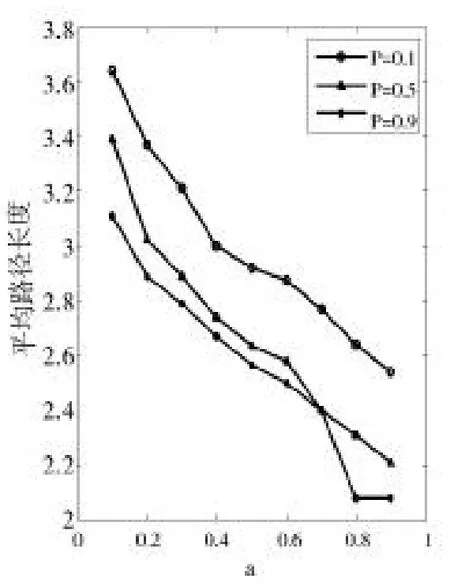
图11 平均路径长度(d=0.5)
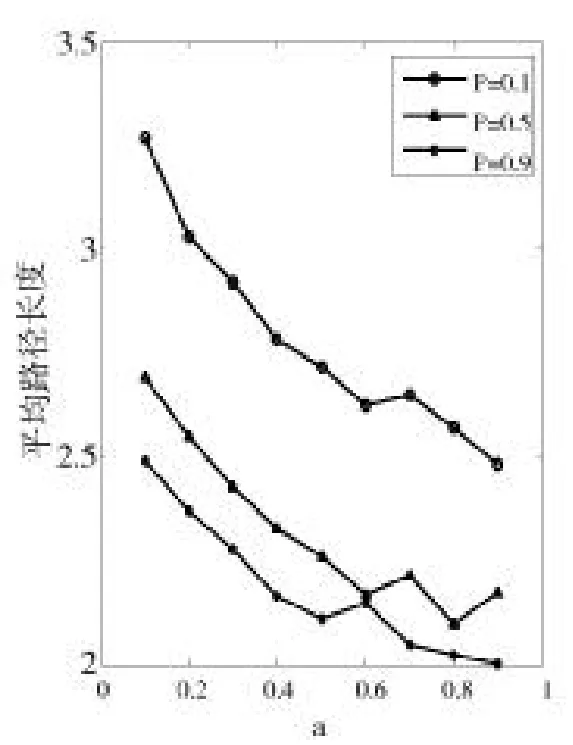
图12 平均路径长度(d=0.9)
3.3 实验结果分析
(1)笔者改进BA模型聚类系数和平均路径长度可调控范围较大。聚类系数随着可变参数d、a、p的增大成增大趋势,而平均路径长度成减小趋势,这是目前的一些BA改进模型所不及的。笔者的模型更能满足现实社交网络的需求,因为在实际社交网络中存在社群,当我们在研究不同范围内的网络特征时,其中的社群规模及数目也不同,有的网络中社群规模较大,则它的聚类系数相对较大,平均路径长度相对较小。
(2)笔者改进BA模型的平均路径长度与原始BA模型相比总体偏小,而聚类系数偏大。在社交网络中,从聚类系数的大小可以看出社团朋友圈的聚集程度,聚类系数越大表示聚集程度越高,越适合描述熟人网络。在熟人网络中,人们之间的信任度相对较强,传播信息可信度较高。正是因为改进模型的聚类系数增大,因此它的平均路径长度也减小到了合理的范围之内,符合复杂网络理论中的小世界网络特征。
4 结束语
笔者针对BA无标度网络模型的缺陷以及实际社交网络的连接特性,提出了一种适合社交网络的BA无标度网络的改进模型,该模型基于多因素且具有混合连边方式,考量节点连接概率方面,在择优连接的基础上增加了随机连接,择优连接的因素不仅只是节点的度还由节点的影响力来决定。仿真结果显示,该模型的度分布呈幂律分布,通过调节参数值可大范围调节聚类系数及平均路径长度,比原始BA模型具有更优的统计特性,适合构建与描述具有大聚类系数特性的社交网络,为构建不同需求的网络提供了一种较为灵活的方案,具有普适性。
[1]侯丽芳.无标度网络的演化模型研究及应用[D].秦皇岛:燕山大学,2016.
[2]DL Wang,Z G Yu,Anh V.Multifractal analysis of complex networks[J].Chinese Physics B,2012(8): 89-99.
[3]李志宏,庄云蓓.基于PageRank算法的双维度微博用户影响力实时度量模型[J].系统工程,2016(2):128-137.
[4]Page L,Brin S,Motwani R,et al.The PageRank citation ranking:bringing order to the web[EB/OL].http: //ilpubs.stanford.edu:8090/422/.2012-05-13.
[5]张琨,李配配,朱保平,等.基于PageRank的有向加权复杂网络节点重要性评估方法[J].南京航空航天大学学报,2013(3):429-434.
[6]王金龙.在线社交网络模型演化及传播机制研究[D].济南:山东师范大学,2016.
[7]许进,杨扬,蒋飞,等.社交网络结构特性分析及建模研究进展[J].中国科学院院刊,2015(2):216-228.
(责任编辑 卞建宁)
Study on BA Scare-free Evolving Model Based on Social Network
WANG Xiaolei
(Northwest University of Political Science and Law Library,Xi’an,710122,China)
TP311
B
1671-9123(2017)02-0133-07
2017-03-30
王筱蕾(1989-),女,陕西眉县人,西北政法大学图书馆助理馆员。
猜你喜欢
中国建材科技(2020年6期)2020-03-23
铁道通信信号(2019年6期)2019-10-08
电子制作(2018年10期)2018-08-04
魅力中国(2018年5期)2018-07-30
电子制作(2017年2期)2017-05-17
雷达学报(2017年6期)2017-03-26
河北工业大学学报(2016年6期)2016-04-16
电子测试(2015年18期)2016-01-14
系统工程学报(2015年5期)2015-02-28
电子设计工程(2015年6期)2015-02-27
