
基于随机游走的密度峰值聚类算法
2022-07-18 06:02占志文刘君
南昌大学学报(工科版) 2022年2期
占志文,刘君
(南昌大学数学与计算机学院,江西 南昌 330031)
聚类的主要目的是对一组对象进行分类,使得同一类对象尽可能相似,异类之间的对象尽量不相似[1]。聚类算法在模式识别、图像处理、风险管理和生物信息学等领域中得到了广泛的应用[2-3]。聚类算法一般可以分为:基于划分的方法、基于密度的方法、基于层次的方法、基于图论的方法、基于网格的方法[4-8]。K-means[9]是一种经典的划分聚类算法,该算法只适用于球状簇,且聚类结果易受初始聚类中心的影响。基于密度的噪声应用空间聚类(DBSCAN)算法[10],可以找到任意形状的簇,但其聚类结果易受阈值和邻域半径这两个参数的影响。
Rodriguez等[11]提出了密度峰值聚类(density peaks clustering,DPC)算法,该算法认为聚类中心的密度高于其周围数据点的密度,且与其他高密度的数据点距离较远。但是该算法仅根据数据点之间的欧氏距离计算局部密度以及相对距离,不适用于形状、密度复杂的数据集;在基于距离分配数据点时,算法鲁棒性低,而且聚类结果对于截断距离较敏感。
针对DPC存在的问题,Liu等[1]基于共享最近邻计算数据点之间的局部密度和相对距离,可以对复杂密度的数据集进行有效聚类;Hou等[12]根据数据点之间的密度与距离关系计算数据点之间的从属关系来计算数据点的局部密度;Xu等[13]基于数据点之间的最短距离重新构建数据点之间的距离,然后再根据新的距离对数据点进行聚类分析;Cheng等[14]基于自然k最近邻来计算数据点之间的局部密度。
为了解决DPC算法的问题,本文提出了一种基于随机游走的密度峰值聚类算法。假设数据点会向其最近K个数据点进行概率转移,通过到达概率来计算数据点的局部密度,并且利用首次到达概率来计算数据点之间的相对距离。同时本文设计了一种逐步分配数据点的分配方法,使得算法的鲁棒性更强。进行了多次的实验,其结果表明本文所提的算法有较好的聚类性能。
1 DPC算法及其分析
1.1 DPC算法
DPC算法通过快速搜索和密度峰值查找,构造决策图来人工选择聚类中心,采用一种跟随策略对数据进行聚类,能够快速发现任意形状数据集的密度峰值点,是一种快速的、高效的聚类算法。DPC算法基于两个假设:聚类中心的局部密度高于其周围的数据点的局部密度;不同的聚类中心之间有较大的距离。基于这两个假设,DPC算法的精髓之处就是在定义样本点xi的局部密度ρi的基础上,进一步定义样本点xi到局部密度比它大且距离它最近的样本xj的距离δi,其定义如下所示:
(1)
(2)
式中:dij为数据对象之间的距离;dc为截断距离,由人工确定,通常是所有的数据对象之间的距离按升序排列后取2%位置处的数值作为截断距离。当数据集较小时式(1) 局部密度ρi的定义对于截断距离dc非常敏感,因此会采用式(2)的局部密度定义。相对距离δi的定义如下:
(3)
由式(3)看出,δi是比数据点xi局部密度更大且离它最近数据点的距离,当数据点为所有数据点中局部密度最大时,将拥有最大的相对距离。为了简化聚类中心的选择,DPC算法计算每个数据点的决策值γi,式(4)给出了定义:
γi=ρi·δi
(4)
DPC算法聚类过程主要分为两个步骤。第1步:对于每个数据点xi首先需要计算其二维数组(ρi,δi),画出二维决策图,决策图中低ρ高δ将其看作为噪声点,对于决策图上高ρ高δ视为聚类中心;第2步:数据点分配,将剩余的数据分配给比其局部密度大的最近的数据点所在的类簇。
1.2 DPC算法分析
虽然文献[11]用了很多的实验结果来证明DPC算法在许多的情况下都能取得很好的效果,但是它的缺点也很明显。
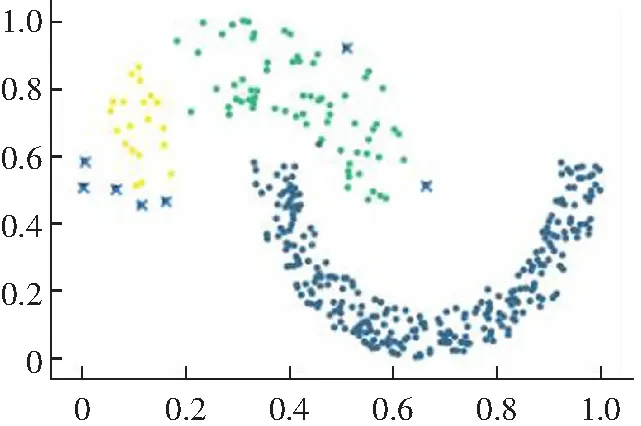
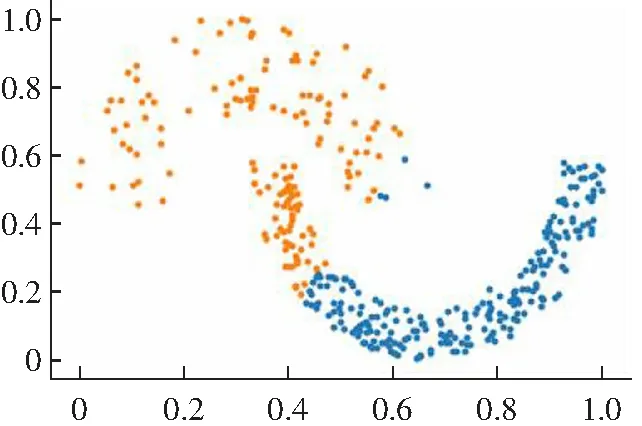
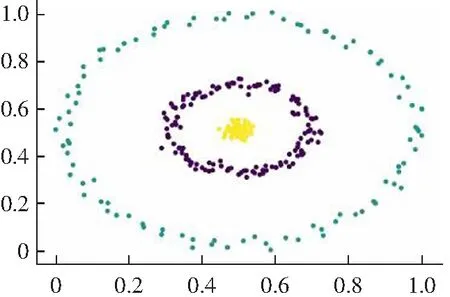
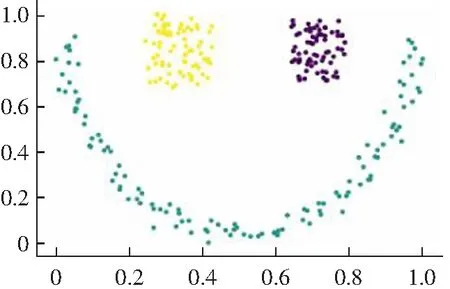
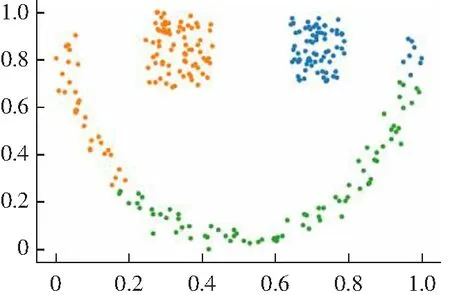
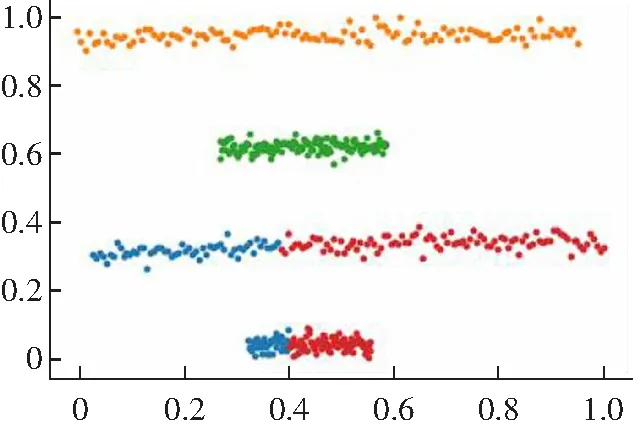
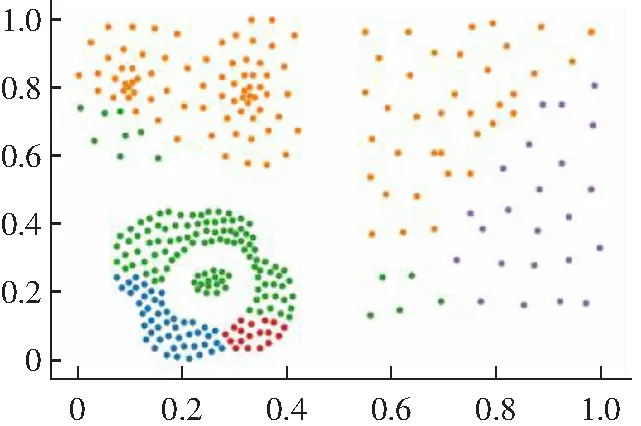
(1) DPC算法有两种不同的局部密度定义公式,对于比较大的数据集采用式(1)cut-off kernel来定义,计算领域内的数据点的个数作为局部密度,对截断距离依赖性较强。而对于较小的数据集则采用Gaussian kernel来定义,计算公式如式(2)所示,这种方式考虑了每个点与其他点的距离,计算量偏大,并且不能完全体现出每个点的局部密度信息。而且对于数据集的大小没有一个客观的判断标准,需要主观意识来判断。局部密度定义的方法选择不一样,得出来的聚类结果就会不同,如图1所示。
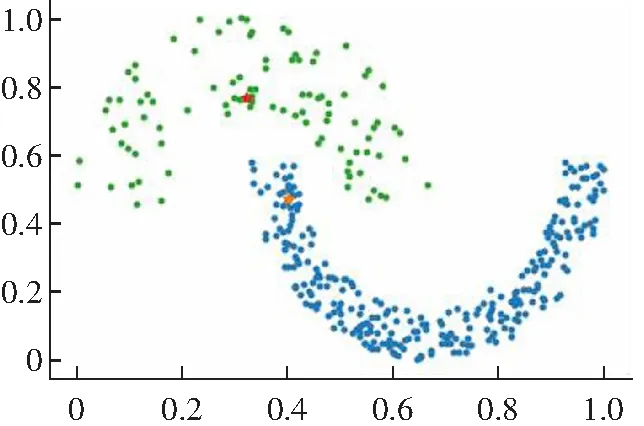
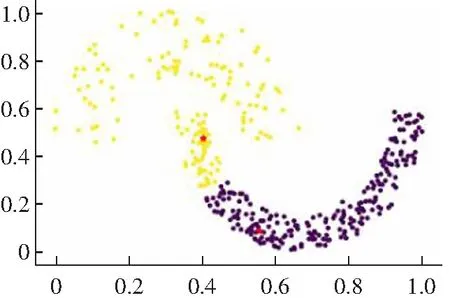
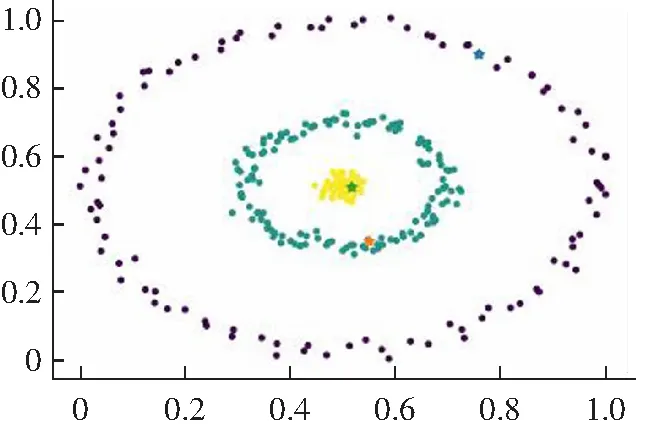
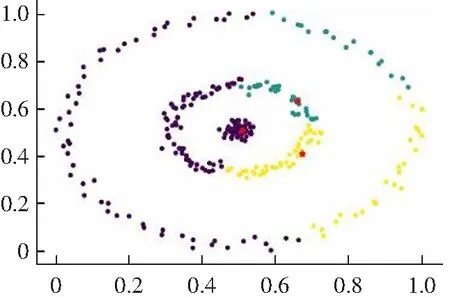
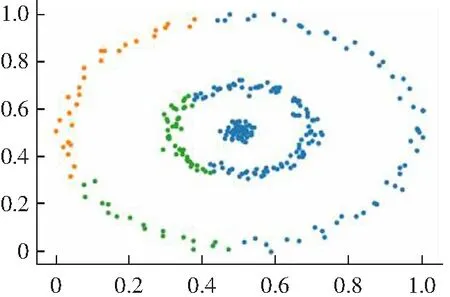
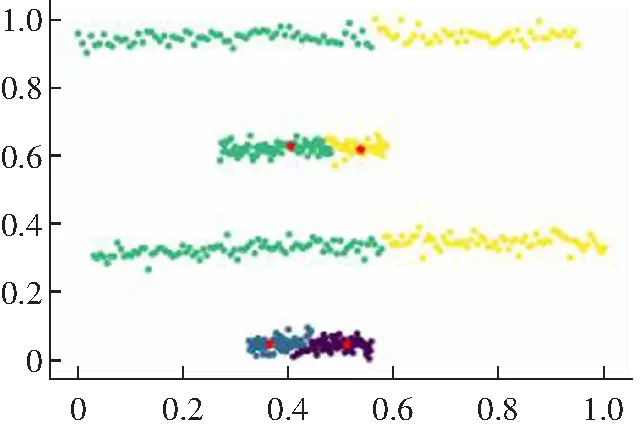
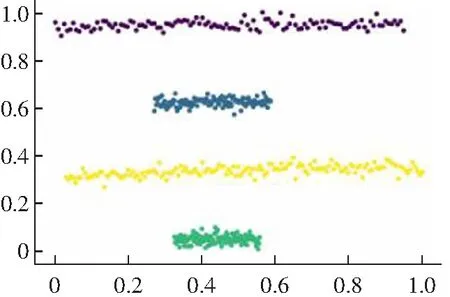
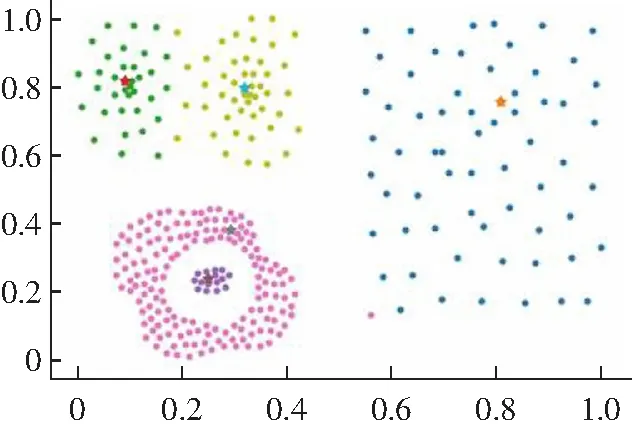
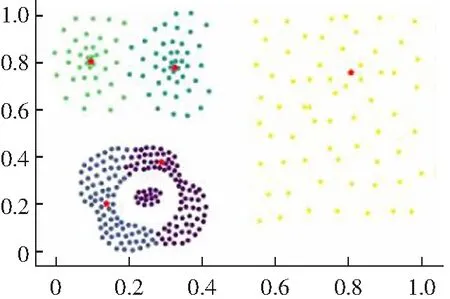
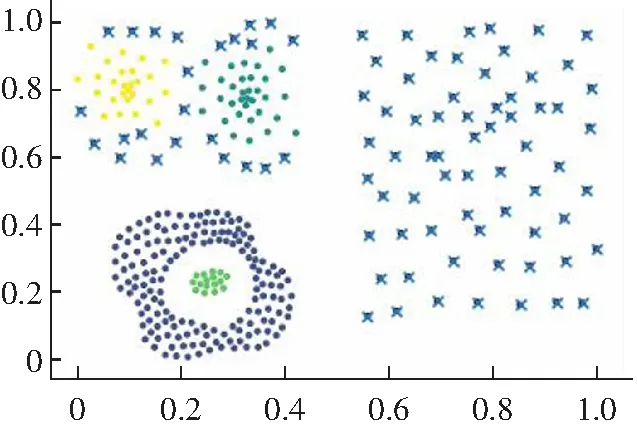
(2) 对于一些弧形较大较长以及稀疏差别较大的类簇不能很好地进行聚类,如图2所示。其原因是DPC算法在计算相对距离时直接采用了欧式距离,采用欧式距离定义相对距离并不能准确度量出数据点的差异性。
(3) DPC算法在分配策略上没有很强的鲁棒性,有时会因为1个数据点的分配错误而造成后续很多数据点的分配错误,并且没有考虑数据点局部分布情况。
2 基于随机游走的密度峰值聚类
2.1 相关定义
设样本数据集X={x1,x2,…,xn},其中每样本点xi有p个属性。
(a) Guass kernel

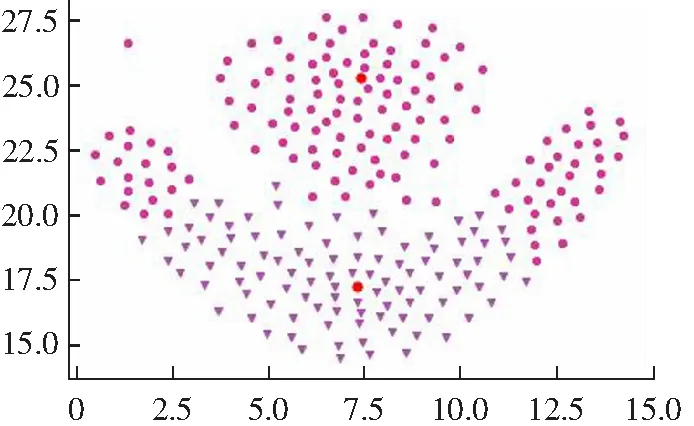
(b) cut-off kernel图1 DPC算法在Flame数据集上的聚类效果Fig.1 Clustering results of DPC algorithm on Flame data set
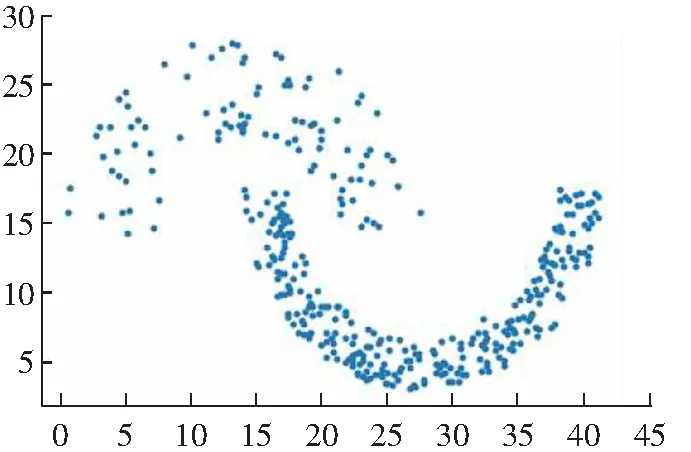
(a) 原始数据分布
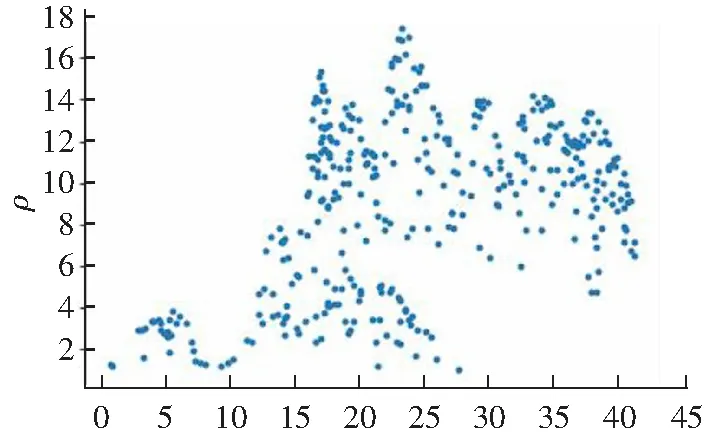
x(b) Guass kernel 局部密度
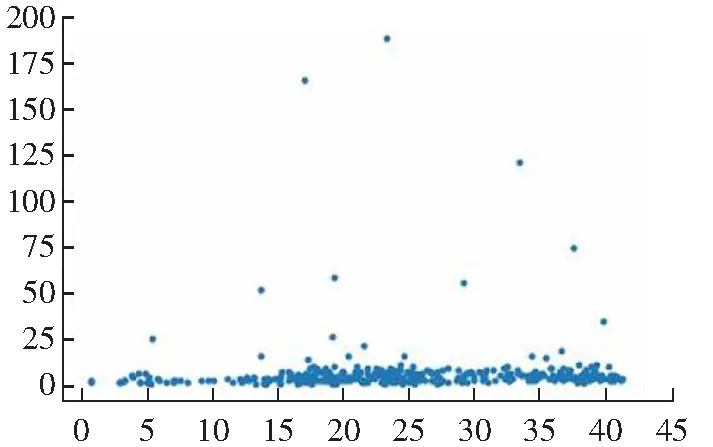
(c) Guass kernel相对距离
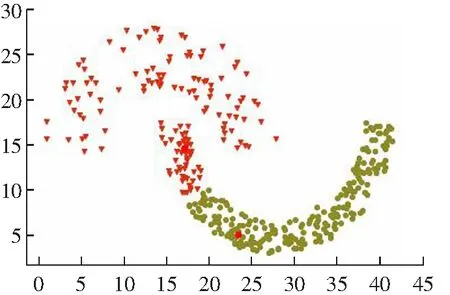
(d) Guass kernel聚类结果图2 DPC算法在Jain数据集上的聚类效果Fig.2 Clustering results of DPC algorithm on Jain data set
定义1由K近邻来定义一步转移概率矩阵P
(5)
式中:dij为数据点xi与数据点xj之间的欧氏距离,而KNN(i)表示离数据点xi最近的K个数据点的集合。并且设定pii=0即数据点xi不会在本身停留。由此可得到数据点之间的n阶随机游走矩阵:
P(n)=P(n-1)P(1)
(6)
当任意数据点不再游走到达新的数据点时,则停止随机游走并记为Pn0。
定义2(首次转移到达概率矩阵)假设n阶随机游走矩阵为任意两个数据点之间的首次转移到达概率矩阵S:
(7)
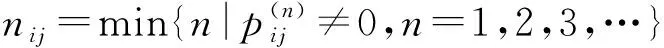
定义3(不相似矩阵)由首次到达概率矩阵得到任意两个数据点之间的不相似矩阵M,其定义如下:
(8)
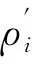
(9)
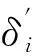
(10)
定义6数据点的决策值:
(11)
根据定义4和定义5求得局部密度和相对距离后,画出其决策二维图,选取聚类中心。
2.2 数据点分配方法
DPC算法的数据点分配策略采用的是一步分配归类,其鲁棒性较差并且容错率较低。本章考虑一种新的数据点分配方法。
经过选取出c个聚类中心,将每个聚类中心的最近的K个数据点划分到其类簇中形成c个集合S1,S2,…,Sc。然后构建一个矩阵,其行数为所有数据点的数量,列数为聚类中心的数量。
步骤1计算R中的数值rij,即
(12)
步骤2若max(rij)=K,将数值为K的行数所代表的数据点分配给列数代表的类簇,返回步骤1;
若0 若max(rij)=0,结束数据点的分配。 本算法的具体实现步骤如下。 输入数据集D,类簇数目c。 输出聚类结果S1,S2,…,Sc。 步骤1根据式(5)计算得到数据点的一阶概率转移矩阵P。 步骤2根据式(6)及式(7)得到各数据点的首次到达概率矩阵S。 步骤3根据式(8)得到数据点之间的转移距离矩阵M。 步骤4根据式(9)及式(10)计算出各数据点局部密度ρ′以及相对距离δ′。 步骤5根据式(11)计算出数据点的决策值γ′。 步骤6将步骤5得到的γ′按大到小选取前面的c个数据点作为聚类中心点。 步骤7将剩余的数据点按照2.2小节中的分配方法进行分配。 步骤8返回聚类结果S1,S2,…,Sc。 本文RW-DPC算法保留了DPC算法寻找密度峰值的核心思想,通过随机游走来刻画数据点之间的距离,适用于任意规模的数据集。 DPC算法由于主要存储了距离矩阵,因此它的空间复杂度为o(n2)(n为数据集中样本数)。RW-DPC算法主要是存储随机游走矩阵,因此它的空间复杂度为o(n0·n2)(n0≪n),而它的时间复杂度由以下几部分决定:计算不相似矩阵、局部密度值ρ′、相对距离值δ′、样本点分配。 对样本数为n的数据集:得到样本点不相似矩阵,时间复杂度为o(n2);计算样本点的局部密度ρ′,时间复杂度为o(n2);计算每个样本点的相对距离δ′,时间复杂度为o(n2);样本点分配,考虑样本点的k近邻,因此单个数据点的时间复杂度为o(kn),总的时间复杂度为o(kn2);因此RW-DPC算法的时间复杂度量级为o(n2)与DPC算法同一级别。 实验选择6个人工合成数据集和4个来自UCI上的真实数据集以及1个人脸数据集进行实验,数据集的具体属性如表1所示。 表1 实验数据集Tab.1 Experimental data set 在所有基准数据集上比较聚类算法的精确度(ACC)、调整兰德尔系数(ARI)、调整互信息(AMI)标准来衡量聚类结果的好坏。ACC标准的范围为[0,1],ARI 和AMI的范围都是[-1,1],这3个指标其值越大表示聚类结果越好。 在上述数据集本章算法将与K-means、DPC、DBSCAN算法进行比较。其中DPC算法中需要确定dc的值,所有的数据对象之间的距离按升序排列后取2%位置处的数值作为dc,而DBSCAN算法的参数是根据实验聚类效果调到最优,并且其会将数据点划分为噪声点,所以在聚类指标只是用精确度(ACC)一个指标。对于近邻参数K的选取,如果K较小则会出现每个数据点都是独立的簇,取值较大的话就会将一些类簇归为一类中,因此我们一般选取的范围为[7,50]。经过多次的实验验证其最优取值为8。 3.2.1 人工数据聚类结果可视化以及分析 根据各算法在人工数据集上的可视化结果图3~图8以及人工数据集的各算法的聚类指标表2可得结论如下:由于K-means算法只能发现球状的簇以及难以识别相近的类簇,K-means 算法在给出的数据集其聚类效果不佳;而DBSCAN算法在对分布稀疏的数据集会将其识别为噪声点,因此DBSCAN算法除了在Jain以及Compound数据集上聚类效果不佳,在其他数据集上能够很好识别;DPC算法对于分布疏密程度差异大以及分布跨度大的类簇的聚类效果不佳,所以在类簇分布跨度大的数据集,例如Threecircles、LineBlob、Sticks、Compound数据集以及分布疏密程度差异大的Jain数据集上聚类效果不佳;而RW-DPC算法能够在分布疏密程度差异大以及分布跨度大的类簇进行很好地识别。 由上述可得,在给出的人工数据集,RW-DPC算法优于其他算法。 表2 人工数据集上各聚类算法的聚类评价指标值Tab.2 Clustering evaluation index value of each clustering algorithm on manual data set (a) RW-DPC (b) DPC (c) DBSCAN (d) K-means (a) RW-DPC (b) DPC (c) DBSCAN (d) K-means (a) RW-DPC (b) DPC (c) DBSCAN (d) K-means (a) RW-DPC (b) DPC (c) DBSCAN (d) K-means (a) RW-DPC (b) DPC (c) DBSCAN (d) K-means (a) RW-DPC (b) DPC (c) DBSCAN (d) K-means 3.2.2 真实数据聚类结果可视化以及分析 真实实验数据集采用的是测试机器学习算法和数据挖掘算法性能的UCI数据库中具有代表性的Iris数据集、Wine数据集、Seed数据集、Ionosphere数据集。从表3可以看出本文RW-DPC算法在4个真实数据集上的各个性能指标都是优于其他算法的,并且在Ionosphere数据集上其聚类效果显著。 3.2.3 人脸数据聚类结果可视化以及分析 在对人脸数据集进行聚类中,画出本文RW-DPC以及DPC算法的决策值(γ)图,如图9所示,则本文算法确定的聚类类簇数为8以及DPC算法确定的类簇数为7。而K-means算法则是将其按照10个类簇进行聚类,DBSCAN是进行多次调参之后的最优结果。从图10可以看出对于人脸数据集聚类效果,本文RW-DPC算法最优,其次是DPC算法、K-means算法以及DBSCAN算法。 表3 真实数据集上各聚类算法的聚类评价指标值Tab.3 Clustering evaluation index value of each clustering algorithm on real data set n(a) RW-DPC决策值 n(b) DPC决策值 (a) RW-DPC (b) DPC (c) DBSCAN (d) K-means 针对DPC算法在数据集的数据分布密度以及分布结构复杂时的聚类结果不够理想的问题,本文提出一种基于随机游走的密度峰值聚类算法。引入随机游走性能够更加准确体现出数据集数据分布结构复杂时数据点之间的距离。通过游走概率使得数据点之间的转移只和数据点的局部数据分布密度相关,消除不同类簇数据点分布疏密不同的问题。另外,在对数据点进行分配时,考虑数据点周围数据点的分布与类簇的关系,使得算法有更强的鲁棒性。同时,本文进行了多次实验,在6个人工数据集和4个真实数据集以及1个人脸数据集上,针对K-means、DPC、DBSCAN算法进行了实验比较,实验表明本文RW-DPC算法在多个数据集上的聚类结果都是优于其他算法的。 对于数据集最优近邻参数K,本文是通过多次的实验来确定的。未来的工作将进一步研究如何能够自动地确定数据集的最优近邻参数K,使得算法具有更强的鲁棒性。2.3 算法流程
2.4 算法复杂度分析
3 实验与结果分析
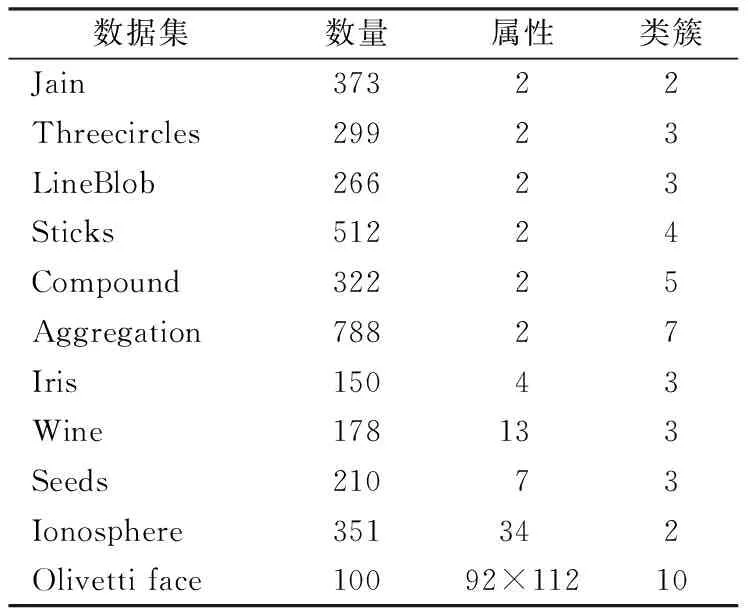
3.1 实验数据集与评价指标
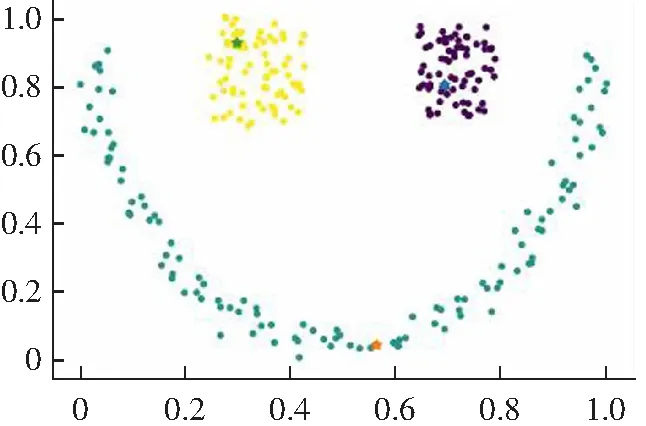
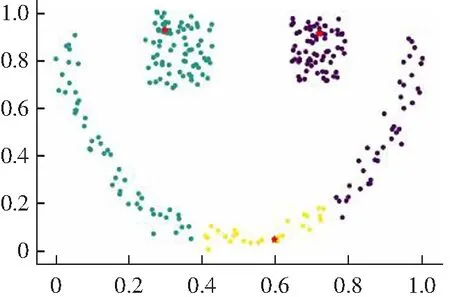
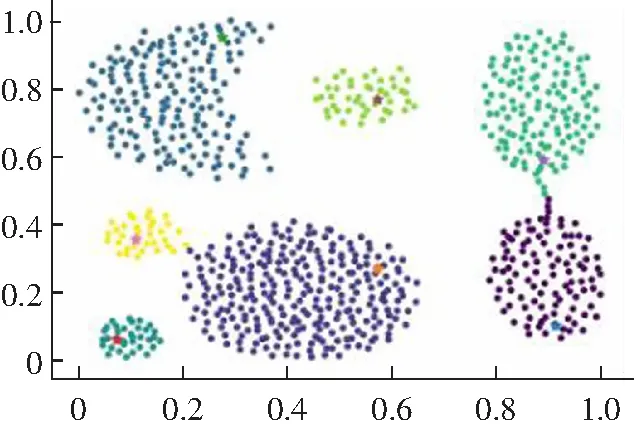
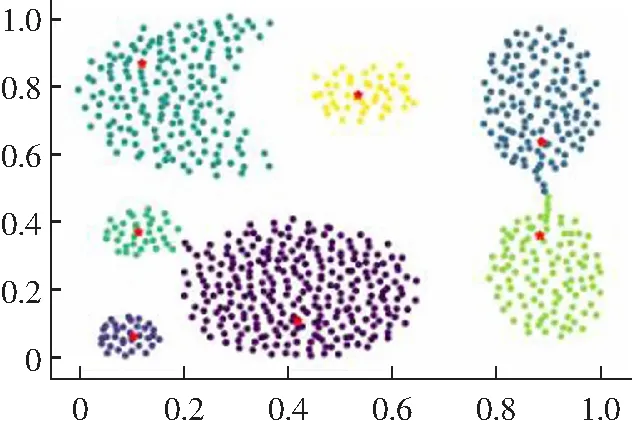
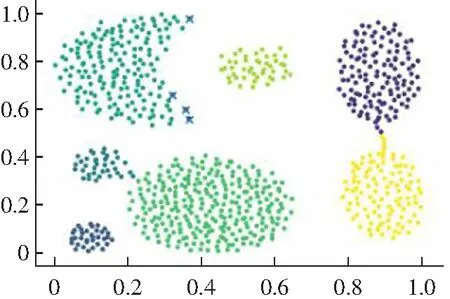
3.2 算法实验结果分析
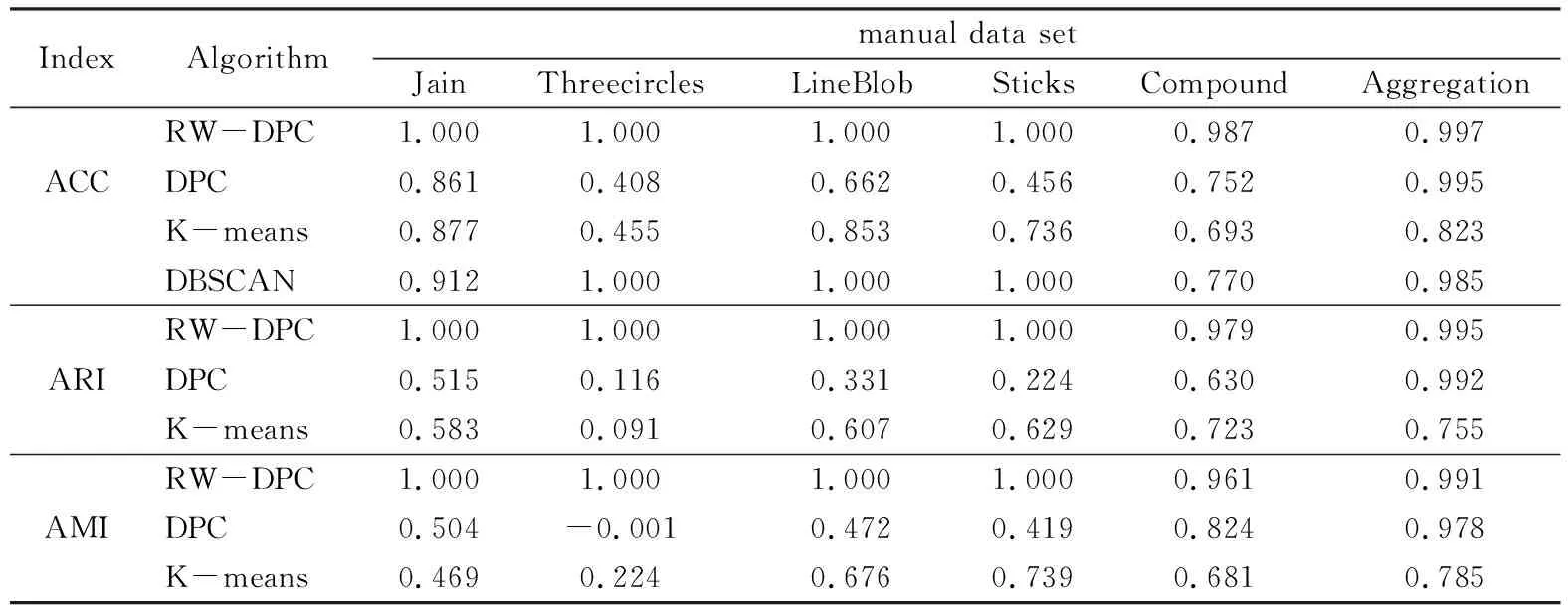

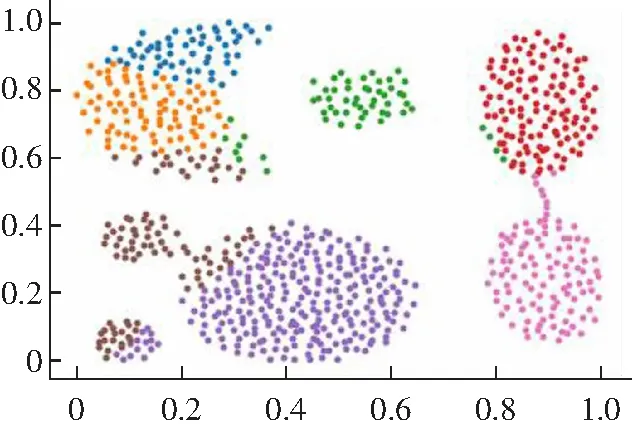
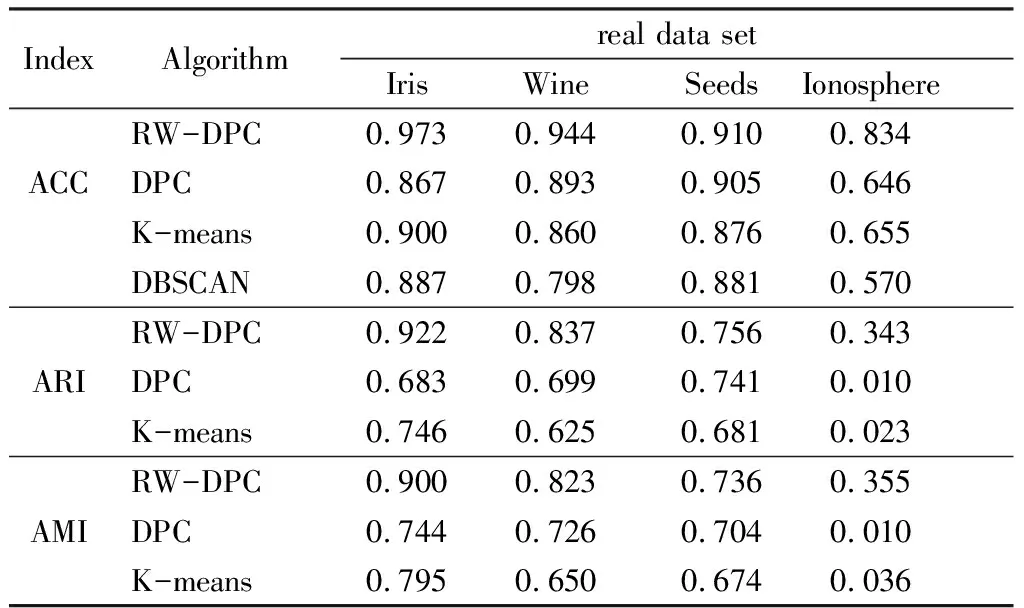
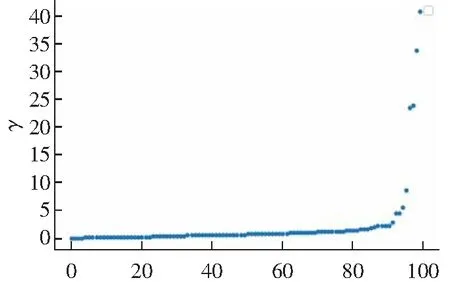
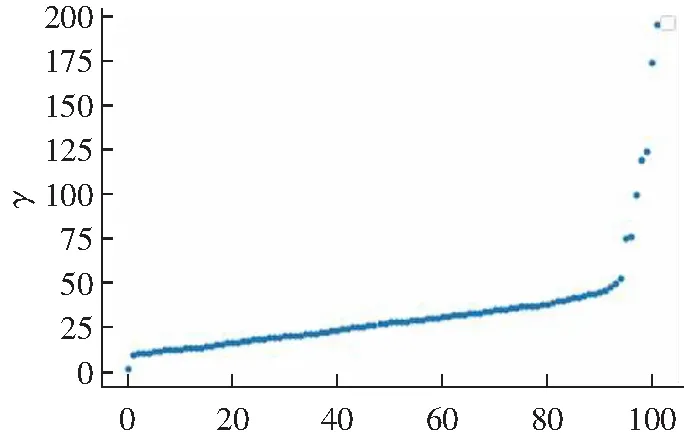




4 结语
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
山花(2022年5期)2022-05-12
汽车实用技术(2022年4期)2022-03-07
计算机研究与发展(2022年1期)2022-01-19
散文诗(2020年1期)2020-07-20
华东师范大学学报(自然科学版)(2019年5期)2019-11-11
东方艺术·国画(2016年3期)2017-02-08
文苑(2015年9期)2015-09-10
新课程学习·中(2013年3期)2013-06-14
学生天地·初中(2009年5期)2009-06-29
