
搜索引擎技术的研究*
——基于后缀数组的搜索技术
2011-10-18 07:53刘荷花
中国教育信息化 2011年4期
刘荷花
(太原大学,山西 太原 030009)
搜索引擎技术的研究*
——基于后缀数组的搜索技术
刘荷花
(太原大学,山西 太原 030009)
本文对搜索引擎Google的网页级别(PageRank)技术进行了研究,整合各种技术和方法,总结出PageRank的计算方法。对搜索引擎建立索引的技术加以改进,将数据挖掘中的数据分类技术、自动化中的用户负反馈技术、后缀数组引入搜索引擎,大大提高了搜索引擎的查准率。
搜索引擎;数据分类;负反馈;数据挖掘
目前,对网上信息的高效、智能检索机制已成为计算机网络领域的研究热点。搜索引擎是帮助互联网用户查询信息的搜索工具,它搜集、发现信息,对信息进行理解、提取、组织和处理,为用户提供检索服务。
一、搜索引擎的原理
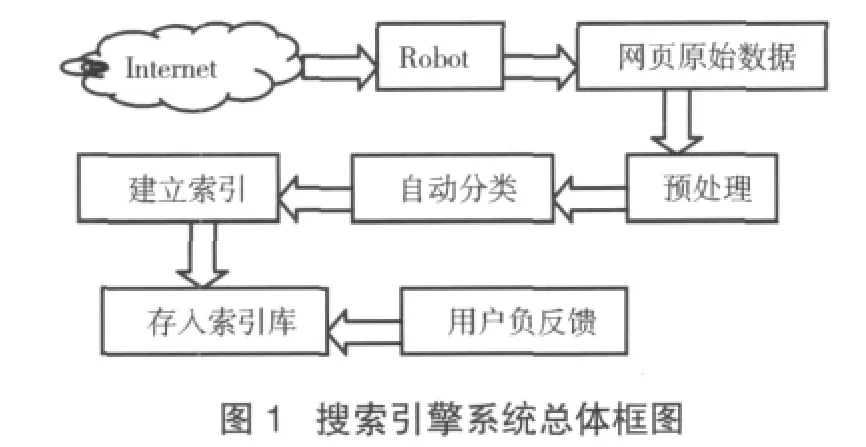
搜索引擎起源于传统的信息全文检索理论。搜索引擎包括全文检索系统、自动收集网页的数据搜集系统、检索结果的页面生成系统,利用网页收集程序 (被称为Robot, Spider, Crawler)自动访问 Web 站点,提取站点上的网页,并根据网页中的链接进一步提取其他网页,或转移到其他站点上。Crawler搜集的网页被加入到搜索引擎的数据库中,供用户查询使用。
二、搜索引擎系统
1.搜索引擎系统总体框图
与普通的搜索引擎相比,本文提出的这个搜索引擎多了两个模块:自动分类和用户反馈模块。这两个模块都是为了提高搜索引擎的查全率和查准率而引入的。
2.用户负反馈的实现
用户负反馈模块的设计思想是:在用户挑选查询结果的时候,搜索引擎记录下用户的挑选结果。与此同时,搜索引擎通过数据挖掘提取出用户所选结果的共性,搜索引擎在依据此共性修正自己的搜索策略,如果用户对搜索结果还不满意,就重复这个过程,从而给用户提供更精确的查询结果。

用户负反馈模块的算法如下:
(1)系统将用户输入的关键词String输入自动分类模块进行分类,检索器依据用户输入的关键词String作为初试条件开始搜索(如图2中过程①)。
(2)第i次搜索完成,将结果集Result_i返回给用户(如图2中过程②)。
(3)用户从第i次结果集Result_i中进行再次筛选,并形成用户选择集Select_i,其中包含的元素是{R1,R2, ……},R1,R2,……都是 Result_i中元素(如图2 中过程③)。
(4)系统从用户选择集Select_i中依据数据挖掘技术提取出用户感兴趣的类别集合Interest_i。其中包含着系统的类别信息。
(5)如果用户对结果进行刷新,将用户输入的关键词String和Interest_i同时作为初试条件重新转到第(2)步,再次搜索;如果用户不刷新结果,则退出。
搜索引擎加入用户负反馈模块后可以增加用户和搜索引擎之间的交互,搜索引擎可以更加清晰准确地了解用户的搜索需求,从而大大提高搜索引擎的性能。
3.文本的自动分类实现
文本的自动分类就是利用数据挖掘技术发现其中隐含的规则,实现搜索引擎的智能化。关键问题是如何构造一个分类函数或分类模型。本文的搜索引擎采用的是Navie Bayes模型。Navie Bayes分类模型是一种基于概率的分类方法,假设C是文本的集合,判断一个文档d是否属于某个类别Ci,可通过计算P(Ci/d)的概率来完成,即给定文档d属于文档类Ci的概率大小。Navie Bayes模型的判断原则是将d指定到使P(Ci/d)达到最大概率的Ci类中,即求解arg max P(Ci/d)。P(Ci/d)可根据文档的长度进行分解:

根据Bayes定律可得:

文本自动分类的步骤:
(1)每个网页数据用一个特征向量 X={x1,x2,Λ,xn}表示,其中x1,x2,Λ,xn表示网页中的关键词。在初试条件下,X中包含网页中所有的关键词,所以n的数值一般比较大,在实际应用中还需要进行特征集压缩。


(5)对每个网页数据 X,针对每个类 Ci计算 P(X|Ci)P(Ci)。 样本 X 被指派到类 Ci,当且仅当 P(X|Ci)P(Ci)>P(X|Cj)P(Cj),其中1≤j≤m,j≠i(2.7)
通过以上步骤,Robot模块收集来的每个网页数据都被指派到一个类中,这样就完成了网页数据的自动分类过程。
三、后缀数组技术的分析与设计
由于网络上传输的数据量太大,所以现在主流的压缩算法都要对压缩的数据进行排序,这个排序叫后缀排序,其中后缀是指从原字符串S中相应位出发直到字符串S结束的子字符串。如:原始字符串S=abcd,那么后缀S0=abcd,S1=bcd,S2=cd,S3=d,后缀排序就是对原始字符串S的所有的后缀进行排序。
1.快速后缀排序算法
qsufort(快速后缀排序)算法在众多的后缀数组算法中是主流算法,只占用8n字节的存储空间。它的主函数如下所示:


其中sort_split函数的源代码如下所示:


2.快速后缀排序算法的一般步骤
(1)对原字符串按第一个字母排序,结果保存在整数数组I中,让h=1。
(2)在整数数组V中设置组号。
(3)对每一个未排序组和排序组,在整数数组L中设置组的长度(未排序组用正数表示,排序组用负数表示)。
(4)用 ternary-split Quicksort处理每一个未排序组,使用V[i+h]为后缀i的关键字。
(5)在未排序组中标记不等于关键字的部分。
(6)将h加倍。对未排序组中不等于关键字的部分递归调用排序算法。
(7)如果I中只包含一个排序组,则停止。否则,转向(4)。
四、系统集成
本系统最终在Linux系统中开发完成。在Red Hat Linux9.0下,用C++语言编写完成,以MySQL数据库作为后台数据库,用于保存词典、文档索引库等。在测试阶段,我们建立分类目标,并以搜狐、雅虎、TOM和CSDN等网站的部分网页作为文档源,调整各种相关阈值后,本系统的搜索精度大大提高。将来的研究方向是逐步优化Robot网络机器人的搜索算法,并根据中文的特点,采用性能更好的分词算法。
[1]刘红泉.自动分类技术研究[J].江西图书馆学刊,2005(1):72~73.
[2]Jiawei Han,Micheline Kamber 著,范明,孟小峰等译.数据挖掘概念与技术[M].北京:机械工业出版社,2007.
[3]钟涛,陈新明,万钧,张世永.中文文本 Web搜索引擎的设计与实现[D].计算机工程与应用,2003.17.
(编辑:隗爽)
TP31
A
1673-8454(2011)07-0085-03
*该课题得到山西省软科学研究计划项目资助,项目编号:2007041023-04。
猜你喜欢
电脑报(2022年13期)2022-04-12
疯狂英语·新阅版(2020年11期)2020-12-21
电脑报(2020年24期)2020-07-15
电脑爱好者(2017年22期)2017-12-04
中国新通信(2016年17期)2016-11-17
电脑知识与技术·经验技巧(2016年1期)2016-03-14
辽金历史与考古(2016年0期)2016-02-02
中国卫生(2015年12期)2015-11-10
初中生之友·中旬刊(2015年4期)2015-06-10
科学导报·学术论坛(2013年5期)2013-06-26
