
基于遗传算法-支持向量机模型在热带气旋强度预报中的应用
2011-12-23 08:45顾锦荣刘华强刘向陪吕庆平
海洋预报 2011年3期
顾锦荣,刘华强,刘向陪,吕庆平
(1.解放军理工大学气象学院,江苏南京211101;2.94816部队气象中心,福建福州 350002)
基于遗传算法-支持向量机模型在热带气旋强度预报中的应用
顾锦荣1,2,刘华强1,刘向陪1,吕庆平1
(1.解放军理工大学气象学院,江苏南京211101;2.94816部队气象中心,福建福州 350002)
利用遗传算法对支持向量机(SVM)模型参数进行寻优,找到最优参数组合后代入SVM模型中,得到基于遗传算法的支持向量机模型(GA-SVM),利用此模型对热带气旋强度进行预报实验。该模型对热带气旋强度12 h、24 h和48 h的预报平均绝对误差分别为3.01 m/s、4.46 m/s和6.57 m/s;比最小二乘回归法的预报精度分别提高了12%、11%、14%。
支持向量机;遗传算法;热带气旋;强度预报
1 引言
当前热带气旋(Tropical Cyclone,简称TC)强度的预报方法主要有动力方法、统计方法、动力与统计相结合的方法。动力方法主要基于数值预报,在此基础上,结合预报员的主观经验来做出预报。传统的统计方法,比如逐步回归、最优子集回归、卡尔曼滤波方法等,建立因子与对象之间关系的基础是它们之间的显著线性相关,而大气环流变化中的复杂性和非线性,决定了预报因子与预报对象之间的非线性相关。因此传统的方法在处理本质上具有非线性关系的问题时,往往难以达到期望的结果。
支持向量机(Support Vector Machine,简称SVM)是基于统计学习理论的VC维理论和结构风险最小化原则的新型学习机器[1-2]。国内外专家、学者己逐步将其应用于(超)文本分类、语音识别、生物序列分析和生物数据挖掘、手写字符识别、人脸识别、指纹识别、遥感图像分析等诸多方面。国内陈永义、冯汉中等[3-4]首先将该方法应用在气象领域,取得了良好效果。作为一种新的机器学习方法,SVM还有很多待完善的地方,比如关于其惩罚系数C、核函数以及对应的参数选择问题,这些在SVM理论上没有完全解决,传统的做法都是根据不同的实际问题进行参数试凑。参数试凑法效率低,对不同的实际问题没有通用性、耗时长。
遗传算法(Genetic Algorithm,简称GA)是模拟生物进化过程中的自然选择和遗传变异的一种全局优化算法,具有并行性和很强的搜索能力。本文用遗传算法对SVM参数寻优,把建立的遗传算法-支持向量机(GA-SVM)模型应用在TC强度的预测上,实现了SVM模型参数的自动选取,TC强度预测取得了较好的效果。
2 支持向量机和遗传算法简介
2.1 SVM回归算法简介
SVM方法是基于1909年Mercer核展开定理,通过非线性映射ϕ,把样本空间映射到一个高维乃至于无穷维的特征空间(Hilbert空间),使在特征空间中可以应用线性学习机的方法解决样本空间中的高度非线性分类和回归等问题[1-3]。
对于非线性问题,引入了非线性映射ϕ,在特征空间中用φ(xi)代替样本空间的xi,得特征空间中的最优线性回归超平面的解析式:
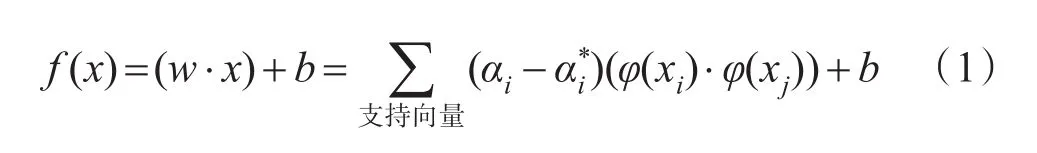
由于内积实际上是一个Mercer核,将核函数K(x,y)=φ(x)·φ(y)代入上式消去非线性映射的显式表达式,最后得到:
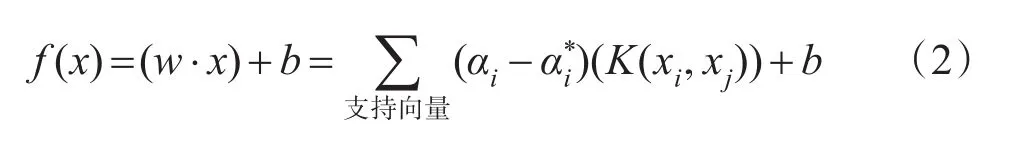
这就是在特征空间中所求得的基于核方法的非线性支持向量机回归学习的最后表达式,也就是非线性支持向量学习机的最优回归函数。虽然用到了特征空间及非线性映像,但实际计算中并不需要知道它们的显式表达。只需要求出支持向量对应得系数α和b的值,通过核函数的计算,即可得到原来样本空间中的非线性回归函数。这样就通过核函数和线性SVM回归方法解决了非线性SVM回归问题。
2.2 GA算法简介
遗传算法作为一种高度非线性映射、自适应和自组织功能的人工智能优化方法,它通过仿效生物遗传和进化过程中选择、交叉、变异机理,来完成对问题最优解的自适应搜索过程。遗传算法首先将问题求解表示成基因型(如二进制编码串),从而构成染色体群。根据适者生存的原则,从中选取适应环境的个体,淘汰较差的个体,并把保留下来的个体通过交叉、变异等遗传算子产生新一代染色体种群。依据某种收敛条件,一代一代不断进化,最后收敛到最适应环境个体上,求得问题最优解[5]。
3 资料和方法
3.1 资料来源
本文使用的TC资料取自中国气象局上海台风研究所编制出版的《热带气旋年鉴》,主要包括TC的编号、各时刻(资料每6 h输出一次)TC所在位置的经度、纬度、中心最大风速、中心气压、大风半径以及TC的移动方向、移动速度等要素。以西北太平洋区域影响我国的热带气旋为研究对象,个例的选取标准是1980—1999年间进入115°—140°E,15°—35°N之间的或在上述区域生成的热带气旋,TC强度以近中心最大风速来表示。
3.2 气候持续性因子的构造
气候持续法[6]是目前在国内外日常的TC路径及强度预报中较为常用的方法之一,它是从上世纪60年代末Hope和Neumann设计的HURRAN[7]基础上发展起来的。气候持续法的基本原理是根据TC本身前期位置状态与后期位置状态的关系,同时结合气候变化的规律,采用回归分析预报热带气旋路径或强度,而不仅仅是外推的问题。因此本文采用气候持续法构造预报因子。具体构造如下[8]:
起报时刻TC中心最大风速V0,TC中心最大风速前6 h、12 h、18 h变化分别为VC6、VC12、VC18; 类 似 的 有 经 纬 度 因 子 E0、 EC6、 EC12、EC18、NC0、NC6、NC12、NC18(V表示风速,E表示经度,N表示纬度,C为变化量,下标表示前6×i(i=0,1,2,3)小时变化);另外,构造6 h和12 h加速率因子:

上式中下标表示前某个时刻的值。类似的还有TC中心纬度加速率因子,不再赘述。
鉴于气候性规律,TC强度的变化在不同年的相同月份、季节有类似情况。因此,根据TC一年内发生的频次规律,把全年分为21个时间段(1—4月为一时间段,5、6、11、12月每半月为一时间段,7、8、9、10月每旬为一时间段),计算每个时间段TC路径、强度变化规律。具体做法如下:把研究区域(115°—125°E,20°—35°N范围) 按2.5°×2.5°网格划分,共划分为24个网格,然后计算每个网格内不同时间段预报因子的历史气候变化平均值。由于TC样本数在不同区域分布有差异,有的网格内样本数甚至为0,因此做如下处理:若某时间段进入某网格的TC样本数少于5个,采用滑动网格统计,按从东到西,由北向南的顺序扩大网格范围,直至进入网格的样本数满足要求。本文构造的气候性因子为TC未来12 h、24 h、36 h和48 h中心最大风速、经纬度历史气候变化平均值:Vave、Eave、Nave(其中:V为中心最大风速、E为纬度,N为经度,下标ave表示平均气候因子)。
根据上述方法,共设计出气候持续性因子24个,表1列出了部分预报因子与TC强度的相关系数。建模时,利用因子与预报对象间相关系数大小作为挑选标准,挑选出相关系数高的部分因子作为SVM的输入。
3.3 遗传算法对支持向量机参数的优化选择
基本的遗传算法解决实际问题是从把对象编码开始,通过某种编码机制(如二进制码、浮点码等)把对象抽象为特定符号按一定顺序排成的串。遗传算法对一个个体(解)的好坏用适应度函数值来评价。适应度函数是遗传算法进化过程的驱动力,也是进行自然选择的唯一标准,它的设计结合求解问题本身的要求而定。使用选择运算来实现对群体中的个体进行优胜劣汰操作:适应度高的个体被遗传到下一代群体中的概率大,适应度低的个体,被遗传到下一代群体中的概率小;交叉运算是遗传算法区别于其他进化算法的重要特征,它在遗传算法中起关键作用,是产生新个体的主要方法,它是指对两个相互配对的染色体依据交叉概率按某种方式相互交换其部分基因,从而形成两个新的个体;变异运算是产生新个体的辅助方法,它决定了遗传算法的局部搜索能力,同时保持种群的多样性,变异运算是指依据变异概率将个体编码串中的某些基因值用其它基因值来替换,从而形成一个新的个体。交叉运算和变异运算的相互配合,共同完成对搜索空间的全局搜索和局部搜索。用遗传算法对支持向量机进行参数优化,就是寻找最优的惩罚因子C和核函数参数的组合。主要的实现步骤如下:
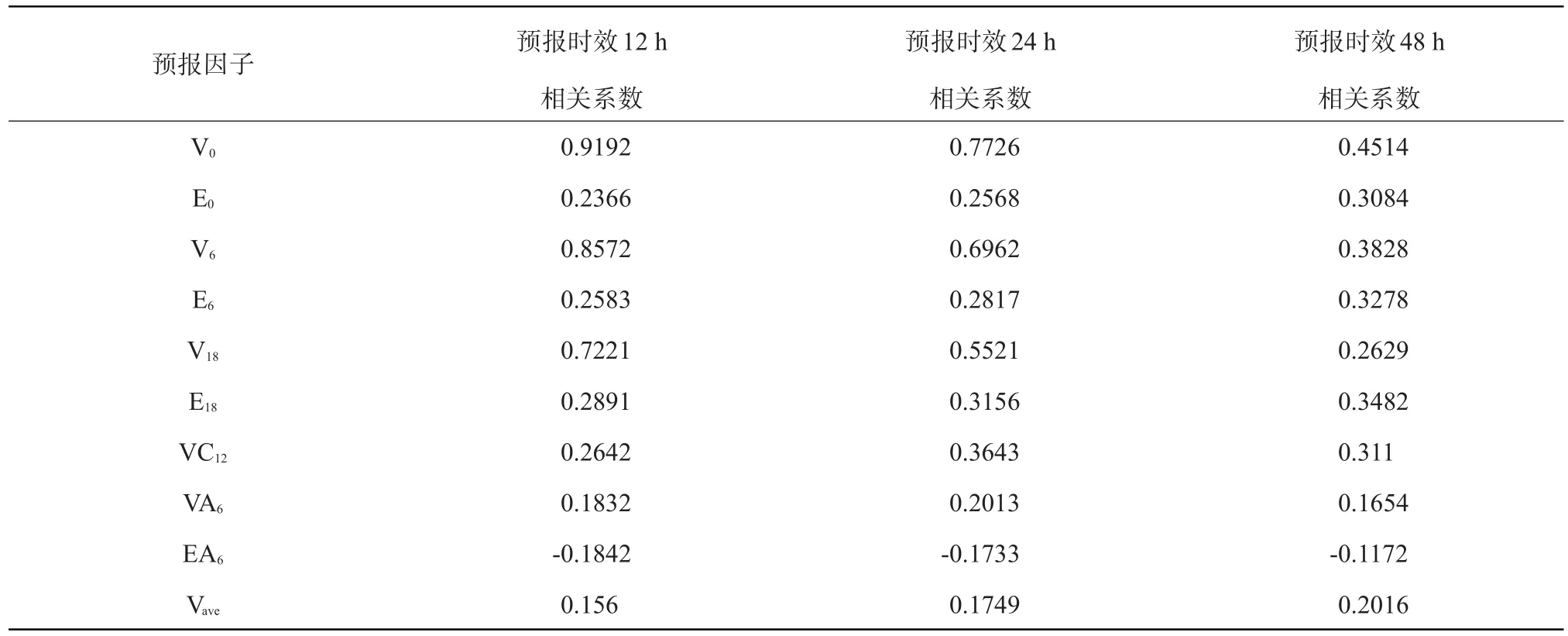
表1 气候持续性因子与不同预报时效TC强度相关系数
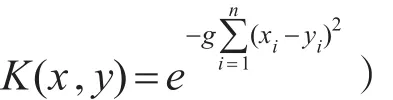
(2)构造适应度函数,这是遗传算法与SVM的接口,通过判断适应度函数的大小来决定是否终止参数寻优。如果适应度值满足了要求,则代表SVM模型中训练样本的真实值与预测值之间的的误差达到要求,此时程序结束,解码并返回最优的C、g值。用得到的参数训练SVM模型,并用测试样本来检验;如果适应度值没有满足了要求,则转到第(4)步。对于本文的实际问题,采用均方误差作为适应度函数:
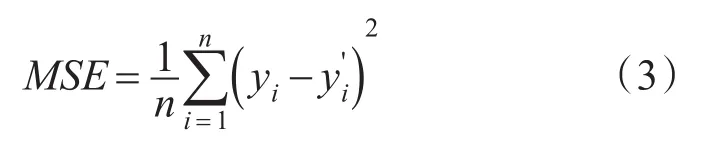
式中 yi为实际值, y'i为预测值,n为样本个数。适应度值为训练SVM模型时预测值与真实值的均方根误差大小,误差越小选择进化的概率越大,即最终的结果为SVM模型训练出的预测值最接近真实值时对应的SVM参数。
(3)对本文的实际问题,设定种群规模M=20;终止进化代数T=60;交叉概率Pc=0.85;变异概率Pm=0.001。遗传算子中的选择运算是根据每个个体的适应度大小来确定的,本文试验中适应度值小的个体有大的概率被选择到下一代。
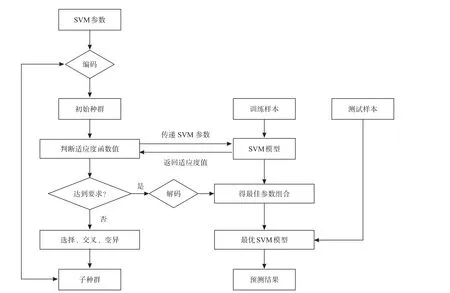
图1GA-SVM运算流程图
(4)应用遗传算子选择、交叉、变异运算来产生下一代种群,然后转到(2)来判断适应度值大小。
整个流程如下图所示:
4 TC强度预报实验
4.1TC强度预测GA-SVM模型的建立与检验
选取1980—1999年共20年的TC资料,剔除没有TC强度记录的样本,再根据预报对象的不同挑选生命史符合要求的TC个例,例如:预报对象为未来12 h TC强度,则该次TC生命史至少为36 h,这是因为要构造预报起始时刻的前18 h的预报因子加上预报对象未来12 h的时效。同理,预报对象为未来24 h TC强度,TC生命史至少为48 h;预报未来48 h TC强度,TC生命史至少为72 h。根据TC生命史和研究区域,选出预报对象为未来12 h、24 h、48 hTC强度的样本数分别为5964个、5672个、4859个。
若所有样本进入程序,计算量很大、机时较长,不利于试验(样本越多精度并不一定越高)。以预报对象为12 hTC强度为例,选取5964个样本中的前1000个样本作为训练样本,剩下的挑选连续的200个样本作为独立测试样本;其他预报时效下样本挑选做法类似。训练前首先将数据归一化到(0,1)之间,保正程序运行收敛加快。表2为寻出的最佳参数及对应的训练样本数据归一化后的均方根误差mse,需要说明的是,均方根误差相同时对应的参数组合并不唯一,这里只列出其中一组。

表2 TC不同预报时效对应的SVM最佳参数及训练时的均方根误差
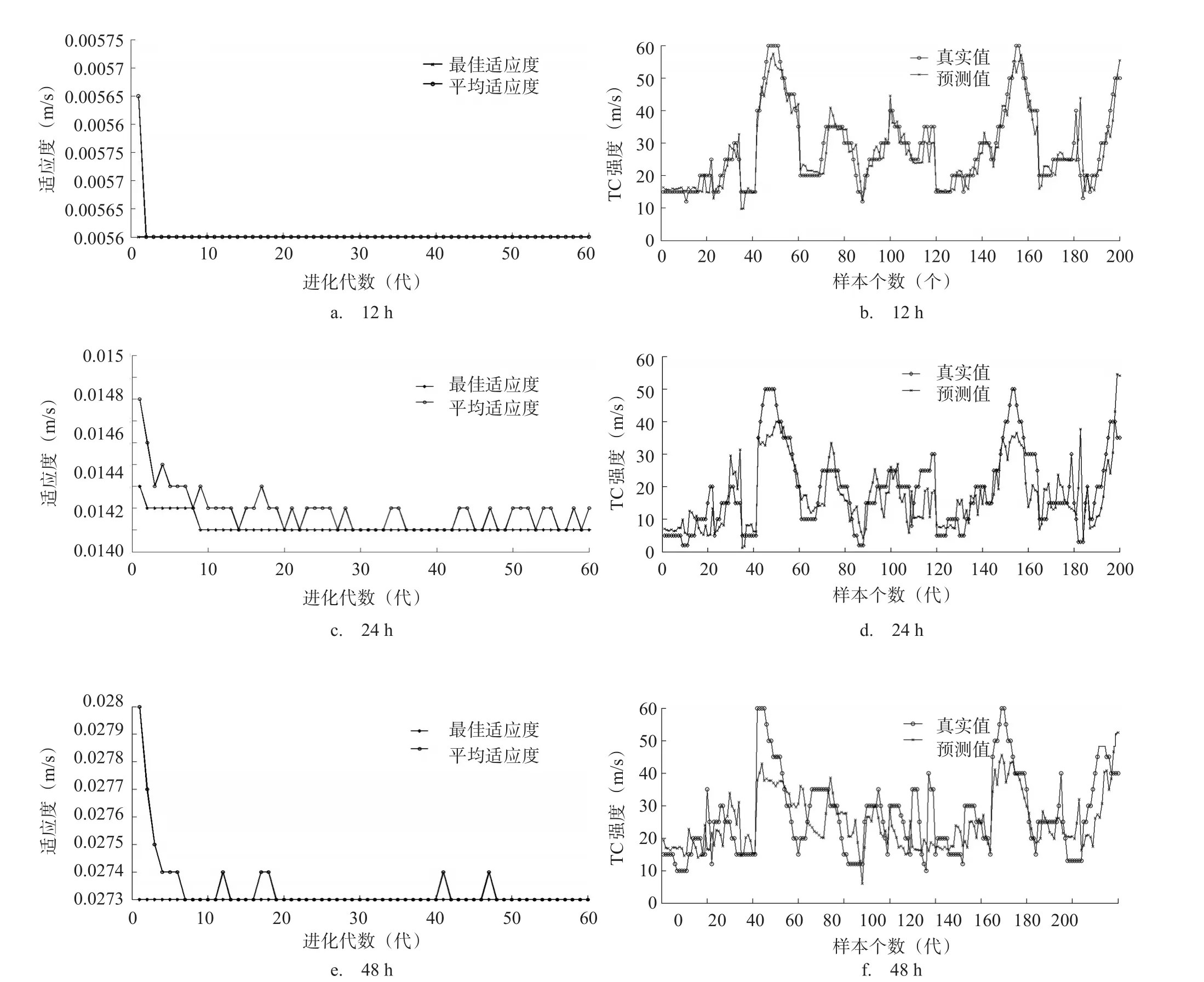
图2 TC强度不同预报时效适应度收敛图和测试样本预测结果

4.2 GA-SVM方法与最小二乘回归方法在TC强度预测上的比较
采用最小二乘回归建立预测TC强度12 h、24 h、48 h预测模型,使用样本方法与建立GA-SVM模型时类似,只是训练样本个数有所区别且事先不进行归一化处理,测试样本与GA-SVM模型使用的完全相同。建立预报方程:Y=α0+α1x1+α2x2+……+αnx8,其中,Y为预报值,x1、x2、……、x8为所选取的因子。经计算,TC强度12 h、24 h、48 h模型的回归方程系数见表3:
从上述两种方法建立的12 h、24 h和48 h TC强度预报模型的平均绝对差(见图3)可以看出:GA-SVM方法较最小二乘回归法有一定优势,预报时效较短时不明显,12 h和24 h的预报误差分别减小了0.44 m/s和0.56 m/s,12 h的预报水平提高了12%,24 h预报水平提高了11%。随着预报时效延长,预报效果有明显提高,48 h的预报误差减小了1.12 m/s,预报水平提高了14%。
5 小结与讨论
(1)SVM方法使用了统计学习理论中的结构风险最小化原则,具有良好的泛化能力和抗过敏能力,在处理非线性特征的气象问题中有明显的优势。利用SVM方法建立TC强度预测模型,是TC强度预测的一种新尝试,与传统的统计方法相比,解决非线性及高维模式识别问题能力更强;

表3 回归方程系数表
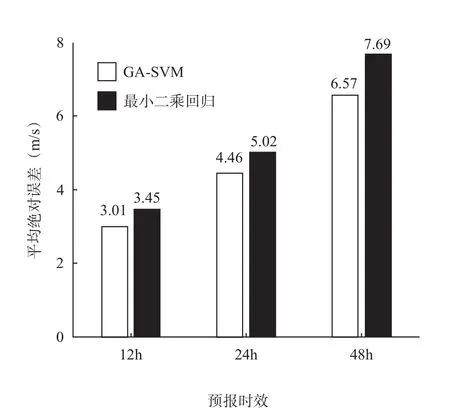
图3 两种方法的预报平均绝对差对比
(2)SVM的参数选取对模型的建立至关重要,但SVM理论对参数如何选择并未完全解决,这也是目前SVM理论研究的热点之一。通过实际问题不断试验得来的SVM参数耗时量大,比如本文的C、g两个参数,假如设范围均为0—100,如果靠“试凑”,则要进行10000次。用遗传算法对SVM参数进行寻优,不仅减少SVM模型建立的人为因素而且耗时大大减少;
(3)本文只考虑了气候持续性因子,没有考虑大气环流因子,若考虑,还有提升预报精度的可能;另外还可扩大核函数的选择范围(文中只用了径向基核函数),进行建模效果的比较。
[1]Vapnik V N.Statistical Learning Theory[M].New York:John Wiley&Sons,Inc,1998:375-570.
[2]Vapnik V N.The Nature Of Statistical Learning Theory[M].New York:Springer Verlag,2000:123-266.
[3]陈永义,俞小鼎,高学浩等.处理非线性分类和回归问题的一种新方法(I)—支持向量机方法简介[J].应用气象学报,2004,15(3):345-353.
[4]冯汉中,陈永义.处理非线性分类和回归问题的一种新方法(II)—支持向量机方法在天气预报中的应用[J].应用气象学报,2004,15(3):355-365.
[5]雷英杰,张善文,李续武,等.MATLAB遗传算法工具箱及应用[M].西安电子科技大学出版社,2004.
[6]Sim D.Aberson and Charles R.Sampson,On the Predictability of Tropical Cyslone Tracks in the Northwest Pacific Basin[J],Monthly Weather Review,2003,131(7):1491-1497.
[7]Charles J,Neumann and wind John R.Hope,Performance analysis of the HURRAN tropical cyclone system[J],Mon.Wea.Rev.,1972,100(4):244-255.
[8]吕庆平,罗坚,朱坤等.基于SVM的气候持续法在热带气旋路径预报中的应用试验[J].海洋预报,2009,26(1):76-83.
[9]姚才,金龙,黄明策等.遗传算法与神经网络相结合的热带气旋强度预报方法试验[J].海洋学报,2007,29(4):11-18.
Application of GeneticAlgorithm-Support Vector Machine model in tropical cyclone intensity forecast
GU Jinrong1,2,LIU Huaqiang1,LIU Xiangpei1,LV Qingping1
(1.Institute of Meteorology,PLA Univ.of Sci.&Tech.,Nanjing 211101,China;2.Meteorology Center,No.94816 Unit of PLA,Fuzhou 350002,China)
Abstract:The parameters for SVM model were pretreated through genetic algorithm to get the optimum parameter values,and these parameter values were used in the SVM model.Genetic algorithm-support vector machine(GA-SVM)model was obtained,which was used to make Tropical Cyclone intensity forecasting.The Mean Absolute Difference of 12 h、24 h、48 h forecasting model is 3.01 m/s、4.46 m/s、6.57 m/s.The results show the superiority of the GA-SVM compare with least square regression method(LS).For example,its forecasting level of 12 hour and 24 hours has improved 12%and 11%than LS,but the number of 48 hour has became 14%.
Support Vector Machine(SVM);GeneticAlgorithm(GA);tropical cyclone; intensity forecast
P457
A
1003-0239(2011)03-0008-07
2010-06-10
顾锦荣(1983-),男,硕士,主要从事热带气旋预测研究。E-mail:comeon_123@163.com
猜你喜欢
计算机仿真(2022年8期)2022-09-28
中国海洋大学学报(自然科学版)(2022年3期)2022-02-24
能源工程(2021年1期)2021-04-13
郑州大学学报(工学版)(2018年2期)2018-04-13
石油地球物理勘探(2017年2期)2017-11-23
中央民族大学学报(自然科学版)(2017年1期)2017-06-11
统计与决策(2017年2期)2017-03-20
中国海洋大学学报(自然科学版)(2017年1期)2017-01-06
中国塑料(2016年11期)2016-04-16
海洋气象学报(2016年3期)2016-02-28
