
结合排序向量SVM 的视频跟踪
2015-07-11 10:09于慧敏
浙江大学学报(工学版) 2015年6期
于慧敏,曾 雄
(浙江大学 信息与电子工程学系,浙江 杭州310027)
视频跟踪是计算机视觉领域一个关键性的研究课题,在智能视频监控、增强现实、人机交互、手势识别以及自动驾驶等方面具有广泛的应用前景.近20年来,尽管人们提出了非常多的跟踪算法,但是这依然是一个非常具有挑战性的课题.高效的视频跟踪算法需要处理真实视频场景中的目标尺度变化、光照变化、部分遮挡、3D旋转以及目标变形等问题.
根据对目标外观建模所用方法的不同,可以将跟踪算法分为2 类:基于判别模型的目标跟踪算法[1-7]和基于生成模型的目标跟踪算法[8-12].基于判别模型的跟踪算法将目标跟踪问题看作是一个二元分类问题,通过在线学习一个分类器将目标和背景分开.典型的基于判别模型的视频跟踪算法有OAB算 法[1]、SemiBoost算 法[2]、CT 算 法[3]、WMIL 算法[4]、MIL算法[5]、PROST 算法[6]和RSVT 算法[7]等.基于生成模型的跟踪算法首先学习被跟踪目标的外观,得到被跟踪目标外观的描述性模型,然后在下一帧图像上搜索最接近该目标模型的物体位置.基于生成模型的目标跟踪算法有Mean-Shift算法[8]、L1算 法[9]、Frag 算 法[10]、VTD 算 法[11]以 及IVT 算法[12]等.
一个典型的视频跟踪系统包括3个部分:目标表示、动态建模以及搜索策略.不同的部分能够处理复杂环境下的不同挑战.首先考虑如何表示目标和背景,使其对光照、遮挡以及3D 旋转等具有不变性.目标和背景常用一个特征序列来表示,可以是颜色特征、形状特征、纹理特征以及局部关键点特征.本文采用的是一种压缩特征,它与Harr-like特征相似,是基于压缩感知理论,从高维多尺度图像特征空间压缩得到的[3].接下来考虑动态建模,这是整个视频跟踪系统的核心,它决定了视频跟踪的性能和计算效率.目前流行的做法是基于在线学习的方法.采用在线学习建模方法是为了使系统对于真实场景中目标的各种变化具有适应性.本文采用排序向量SVM(ranking vector SVM,RV-SVM)算 法[13]作为在线学习方法,它本身是一种排序学习算法,在信息检索领域得到了广泛应用.而在本文中,它充当一个在线分类器,用于将目标和背景分开.最后考虑搜索策略问题,文献[14]采用Coarse-to-Fine搜索机制以加快CT 算法的目标检测过程,降低了计算复杂度.虽然SFCT 算法[14]加入搜索机制取得了较好的效果,但是还可以采用更加简单的方法,即加入预测器.因此,本研究采用Median-Flow 算法[15]作为预测器,它的功能主要包括2个方面:一是粗略估计目标在下一帧中的位置,减少搜索范围,加快目标检测速度;二是用来构建训练样本集.
本研究将多尺度压缩特征提取、RV-SVM 分类器以及Median-Flow 跟踪算法有机结合,建立一个鲁棒的视频跟踪系统.该系统仅适用于单目标跟踪.本文提出结合RV-SVM 的视频跟踪算法,并对比本文算法与最新的跟踪算法的性能.
1 相关工作
近年来,国内外很多学者在视频跟踪领域做了许多研究工作,这些工作对于解决视频跟踪中的问题提供了许多思路.Santner等[6]提出了PROST 高性能跟踪系统.该系统级联了3个跟踪器:基于归一化互相关的简单模板跟踪、基于Mean-Shift的光流跟踪和在线随机森林跟踪.Kalal等[15]首次提出了Median-Flow 跟踪算法.Kalal等[16]提出了一个典型的半监督学习跟踪算法,称之为TLD 算法.该算法是Median-Flow 跟踪、随机蕨检测器及P-N 学习算法的结合.Zhang等[3,14]利用一个稀疏测量矩阵有效地从多尺度图像特征空间中抽取特征.
CT 跟踪算法[3,14]采用分类器为朴素贝叶斯分类器,该分类器比较简单,分类效果一般.TLD 跟踪算法[16]的跟踪模块采用的算法为Median-Flow 算法,而Median-Flow 算法的鲁棒性并不十分理想,并不适合用作主要的跟踪算法.因此,综合考虑CT算法和TLD 算法的优缺点,提出本文算法.
1.1 多尺度压缩特征提取
为了处理跟踪过程中目标的尺度变化,需要提取多尺度图像特征.本研究参考文献[3]和[16],通过一定的宽松规则,生成一个稀疏的投影矩阵,然后提取样本图像的压缩特征.
首先,将每个样本图像与一系列多尺度矩形滤波器进行卷积

式中:*为卷积运算符,对像素点的坐标x 和y 进行操作.s(x,y)为样本图像,其宽度为,高度为,即s(x,y)∈R.多尺度的矩形滤波器定义为

其 中,i 和j 为 矩 形 滤 波 器 标 号,i=1,…,,j=1,…,.li,j(x,y)∈R,表 示 滤 波 后 的 图像矩阵.
将图像矩阵li,j(x,y)展开成一个列向量lk,lk∈R,k=1,…,,并将这些列向量连接成一个非常高维的多尺度图像特征向量:
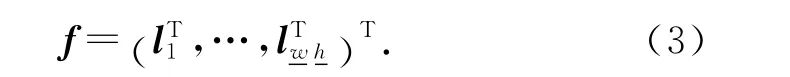
式中:f∈Rm,m=()2.特征向量f 的维度m为106~1010.
由于多尺度图像特征向量f 的维度太高,需要对它进行数据压缩.为了使压缩之后的数据保留原有数据的大部分信息且压缩过程的计算量小,需要用到压缩感知算法.根据压缩感知理论可知,若通过一个满足约束等矩性(restricted isometry property,RIP)条件的非常稀疏的测量矩阵对原图像特征空间进行投影,就可以得到一个低维压缩子空间,该子空间很好地保留了高维图像特征空间的信息.
利用压缩感知理论提取压缩特征,其公式如下:

式中:R∈Rn×m(n≪m)是一个非常稀疏的随机测量矩阵;f∈Rm×1为原始数据;x∈Rn×1为压缩后的数据.测量矩阵R 的产生非常重要,它必须满足RIP条件,而且,不同的R 产生的特征不同.文献[3]将测量矩阵R 的元素ri,j定义如下:

其中,s通过平均概率在2.0~4.0中随机选取,p 为产生概率.实际上,低维特征x 的每一个元素xi是不同尺度的空间分布特征的线性组合,表现为几块区域的加权和,如图1 所示.压缩特征与Harr-like特征相似,保留了原有图像的绝大部分信息,可以直接对它进行分类,避免维数灾难.

图1 特征生成示意图Fig.1 Graphical representation of feature extraction
1.2 Median-Flow跟踪算法
采用Median-Flow 跟踪算法[15]粗略估计目标在下一帧图像中的位置,这里称之为弱跟踪器,工作框图如图2所示.Median-Flow 算法将被跟踪目标表示成一系列的特征点,通过估计相邻图像帧之间特征点的偏移量来达到跟踪目的.对于被跟踪目标,用一个10×10网格的所有顶点表示该目标.采用金字塔Lucas-Canada光流算法[17]对相邻图像帧之间的特征点的偏移量进行估计.本文所用金字塔层数为5层,特征点用4×4图像块来表示.
Median-Flow 算法提出了一种新的特征点跟踪误差计算方法,即特征点跟踪轨迹前向-后向误差,其定义如下:


图2 Median-Flow跟踪算法框图Fig.2 Block diagram of Median-Flow tracker
Median-Flow 算法通过计算剩余特征点的x 坐标和y 坐标的平均值来估算目标的位置.Median-Flow 跟踪算法跟踪效果良好、计算量小,适合用作弱跟踪器,提供目标位置的粗略估计,减少搜索范围.
2 基于排序向量SVM 的视频跟踪算法
2.1 排序学习与视频跟踪
排序学习算法在信息检索领域得到了广泛应用,如文本检索、产品评级以及语义分析等.经典的排 序 学 习 算 法 有RankSVM[18]、RankBoost[19]和RankNet[20]等.近年来,排序学习算法被用于计算机视觉领域,Yang 等[21]提出了基于l1正则化的RankBoost改进算法,用于人脸识别和密度估计.Bai等[7,22]首 次 将 排 序 学 习 算 法——排 序SVM 引入了视频跟踪领域.


图3 基于排序学习的视频跟踪原理图Fig.3 Schematic diagram of visual tracking based on learning to rank
基于排序学习理论,给出基于排序的跟踪算法[22]的原理图.在此基础上,总结出基于排序学习的跟踪算法原理图,如图3所示.算法首先构建2个训练样本集,并设定其中一个样本集的排序高于另外一个样本集.一般而言,抽取第一帧以及最近Δt帧中靠近目标的图像块为排序高的样本集,抽取最近Δt帧中远离目标的图像块为排序低的样本集.在训练排序函数F(x)时,先从排序高的样本集中取一个数据,再从排序低的样本集中取一个数据,构成一个有序数据对.利用这一系列有序数据对去训练排序函数F(x),如图3(a)所示.在第t帧时,采用一定的搜索策略或弱跟踪器估计目标在第t+1帧时的位置,然后抽取该位置附近的图像块作为目标候选位置集.在第t+1帧进行目标定位的过程相当于对候选位置集进行排序,得分最高的图像块的位置即为目标的新位置,如图3(b)所示.
2.2 排序向量SVM
采用RV-SVM 算法充当在线分类器,RVSVM[13]是RankSVM[18]的快速学习算法.这里先介绍RankSVM,再从中推导出RV-SVM.假设有2个特征向量集X1和X0,分别表示为

式中:xi∈Rn,xj∈Rn.对于任意的i和j,均有xi≻xj,即特征向量xi的排序高于特征向量xj.RV-SVM 的目标是学习排序函数F,使其满足以下条件:

式中:w 为权重向量,φ(x)为作用在特征向量x 上的隐式映射函数.因此,学习排序函数F 等同于计算权重向量w,对于任意特征向量对{(xi,xj):xi∈X1,xj∈X0},有

排序SVM 的训练过程需要求解一个二次规划问题,其原始形式如下:

式中:参数C 为边界大小与训练误差之间的折中参数,i=1,2,…,N1,j=N1+1,N1+2,…,N1+N0,为松弛变量.可以通过求解该二次规划问题的对偶问题得到最优解,其对偶形式如下:

式中:u=1,2,…,N1,v=N1+1,N1+2,…,N1+N0;αij为有序数据对(xi,xj)映射空间的向量差φ(xi)-φ(xj)的系数;K(·)为核函数,对于线性核,K(x,y)=〈x,y〉.由于式(13)的计算复杂度太高,为了减少排序SVM 的训练时间,首先引入排序SVM 的变种——l1范数权重排序SVM[13],其目标函数为

从式(15)可知,l1范数权重排序SVM 的训练过程是求解一个线性规划问题.

RV-SVM 通过减少核函数计算时间降低训练时间.式(16)为一个线性规划问题,可以采用Matlab和CPLEX 科学计算工具来求解.得到最优解α*之后,排序函数可以用下式表示:

式中:i=1,2,…,N1.
2.3 算法实现流程
为了实现视频跟踪,需要将t+1帧的目标和背景分开,通过式(16)、(17)学习排序函数F 来达到这个目的.首先创建3 个标记训练样本集、和.为从初始帧和最近Δt帧中抽取的目标图像块集,称为正标记样本集,用公式表示如下:

式中:ls(x)表示第s帧图像中,图像块x的位置;表示目标的真实位置;ε为采样半径,ε=4;Δt为最近帧图像的数目,Δt=2;ls(x)-≤ε表示图像块x 的位置与目标真实位置之间的欧氏距离小于ε.为背景图像块集,称为负标记样本集,仅从最近Δt帧图像中提取,可用如下公式表示:


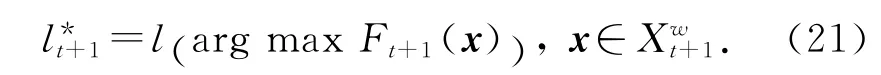
算法的详细过程如下:
1)初始化目标位置(手工选取跟踪目标);
3)读取新一帧图像,利用1.2节介绍的Medain-Flow跟踪算法粗略估算目标在这帧图像中的位置;
6)利用式(21)更新目标在这帧图像的位置;
7)跳转到2)进行下一帧的处理.
3 实验结果
本文所提算法采用Matlab与C++混合编程实现.其中,Median-Flow 算法部分采用C++实现,并调用了计算机视觉开源库OpenCV 2.3.1,其余部分采用Matlab 实现,代码未进行任何优化,算法处理速度(平均帧率).实验所用计算机的配置为Intel(R)Core(TM)i3-2100处理器,主频3.10 GHz,内存2.00GB,Windows 7操作系统.
本文算法与4种视频跟踪算法在6个具有挑战性的图片序列上进行对比实验,6 个图片序列由Babenko等[5]提供.4种对比算法分别是Frag跟踪算法[10]、多实例学习跟踪算法(MIL)[5]、压缩跟踪算法(CT)[3],以及L1跟踪算法[9].这些算法的源代码均已公开,参数采用默认值并已调到最优.
为了在不同条件下对算法的鲁棒性进行量化评估,需要人工标记所有图片序列每一帧的目标位置,这个位置被称为标准位置.评价准则与文献[23]所用的方法相同,采用平均中心位置误差:

式中:n为图片序列的帧数, Ci-为算法跟踪到的目标的中心位置Ci与标准中心位置之间的欧氏距离.对比实验的量化结果如表1所示,表中σc为中心位置误差,η为平均帧率,上标[1]表示最优,上标[2]表示次优.如图4所示为不同算法在不同视频上的中心位置误差曲线.
图片序列Tiger 1和Tiger 2呈现了玩具老虎的各种姿态,跟踪这2个序列会遇到各种挑战,如光照变化、重度遮挡、3D 旋转、运动模糊以及目标快速移动.根据图4(a)、(b)的中心位置误差曲线可以看出,Frag算法、MIL算法、CT算法和L1跟踪算法在许多帧上均出现漂移,本文算法则提供了一个比它们更为稳定和精确的结果.
图片序列Coupon Book 是用来测试跟踪算法是否严重依赖于初始帧目标的位置.该图片序列中的券书在第50帧左右会出现折叠,同时出现一个一模一样的券书来干扰跟踪.序列Coupon Book的中心位置误差曲线见图4(c).从图中可看出,本文算法优于其他对比算法.虽然MIL算法、CT 算法和L1算法能够正确区分出干扰物体,但其跟踪结果的中心位置存在一定程度的偏移,而Frag算法却不能正确地区分干扰物体.

表1 平均中心位置误差与平均帧率Tab.1 Average center location errors and average frame per second

图4 中心位置误差曲线图Fig.4 Plots of center location error
图片序列Twinings中的目标存在大尺度变化和3D 旋转.从图4(d)的中心位置误差曲线可看出,Frag算法、CT 算法以及L1 算法存在轻微漂移.由于利用了多尺度图像特征,当目标尺度和表面发生变化时,本文算法和MIL 算法都能很好地适应这些变化.
图片序列Occluded Face的主要问题是重度遮挡.在这次实验中,Frag算法性能最好,因为它是专门为解决遮挡问题而设计的.L1 算法同样具有很好的性能,而MIL 算法、CT 算法和本文所提算法则表现一般,中心位置误差曲线见图4(e).
在图片序列David Indoor中,出现的主要问题有光照变化、3D 旋转和大尺度变化.Frag 算法和L1算法完全不能适应这些变化,跟踪结果出现严重漂移.MIL算法与本文所提算法也会出现轻微的漂移,CT 算法的性能最佳,中心位置误差曲线如图4(f)所示.
4 结 语
本文提出了一种新的单目标视频跟踪算法,该算法是一种基于RV-SVM 理论的在线学习跟踪算法.该算法利用稀疏测量矩阵提取样本的多尺度特征,通过Median-Flow 跟踪算法估计目标在下一帧中的位置并构建训练样本集,最后,在线训练RVSVM 算法,将目标和背景分开.对不同视频序列中的目标跟踪结果表明,本文算法在目标快速移动、部分遮挡以及3D 旋转时跟踪稳定性有所提高.
实验结果虽然证实了本文算法的有效性,但依然存在很多问题.比如:跟踪目标框是固定的,不会随着目标的尺度变化而变化.当目标大小发生变化时,可采用跟踪窗口自适应的方法来提高跟踪的稳定性,但这些方法的引入必然会导致计算量的增加.本文算法用多尺度压缩特征来表示目标和背景,但不排除还有更加有效的表示方法.此外,本文算法的计算效率偏低,还可对算法进行优化.总之,如何更好地解决这些问题是后续研究的重点.
(
):
[1]GRABNER H,GRABNER M,BISCHOF H.Real-time tracking via on-line boosting [C]∥ Proceedings of British Machine Vision Conference.Edinburgh:BMVC,2006,1(5):6.
[2]GRABNER H,LEISTNER C,BISCHOF H.Semi-supervised on-line boosting for robust tracking[M]∥Proceedings of European Conference on Computer Vision.Berlin Heidelberg:Springer,2008:234-247.
[3]ZHANG K,ZHANG L,YANG M H.Real-time compressive tracking[M]∥Proceedings of European Conference on Computer Vision.Berlin Heidelberg:Springer,2012:864-877.
[4]ZHANG K,SONG H.Real-time visual tracking via online weighted multiple instance learning [J].Pattern Recognition,2013,46(1):397-411.
[5]BABENKO B,YANG M H,BELONGIE S.Robust object tracking with online multiple instance learning[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2011,33(8):1619-1632.
[6]SANTNER J,LEISTNER C,SAFFARI A,et al.PROST:parallel robust online simple tracking[C]∥Proceedings of IEEE Conference on Computer Vision and Pattern Recognition.San Francisco:IEEE,2010:723-730.
[7]BAI Y,TANG M.Robust visual tracking with ranking SVM [C]∥Proceedings of IEEE Conference on Image Processing.Brussels:IEEE,2011:517-520.
[8]COMANICIU D,RAMESH V,MEER P.Real-time tracking of non-rigid objects using mean shift[C]∥Proceedings of IEEE Conference on Computer Vision and Pattern Recognition.Hilton Head:IEEE,2000,2:142-149.
[9]MEI X,LING H.Robust visual tracking and vehicle classification via sparse representation[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2011,33(11):2259-2272.
[10]ADAM A,RIVLIN E,SHIMSHONI I.Robust fragments-based tracking using the integral histogram [C]∥Proceedings of IEEE Conference on Computer Vision and Pattern Recognition.New York:IEEE,2006:798-805.
[11]KWON J,LEE K M.Visual tracking decomposition[C]∥Proceedings of IEEE Conference on Computer Vision and Pattern Recognition.San Froncisco:IEEE,2010:1269-1276.
[12]ROSS D,LIM J,LIN R S,et al.Incremental learning for robust visual tracking[J].International Journal of Computer Vision,2008,77(1-3):125-141.
[13]YU H,KIM J,KIM Y,et al.An efficient method for learning nonlinear ranking SVM functions[J].Information Sciences,2012,209(20):37-48.
[14]ZHANG K,ZHANG L,YANG M H.Fast compressive tracking[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2014,36(10):2002-2015.
[15]KALAL Z,MIKOLAJCZYK K,MATAS J.Forwardbackward error:automatic detection of tracking failures[C]∥Proceedings of IEEE Conference on Pattern Recognition.San Froncisco:IEEE,2010:2756-2759.
[16]KALAL Z,MIKOLAJCZYK K,MATAS J.Tracking-learning-detection[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2012,34(7):1409-1422.
[17]BOUGUET J Y.Pyramidal implementation of the Lucas Kanade feature tracker description of the algorithm,openCV documetation[R].Santa Clara,CA:Intel Corporation,Intel Microprocessor Research Labs.1999.
[18]HERBRICH R,GRAEPEL T,OBERMAYER K.Support vector learning for ordinal regression[C]∥Proceedings of International Conference on Artificial Neural Networks.Edinburgh:ICANN,1999:97-102.
[19]FREUND Y,IYER R,SCHAPIRE R E.An efficient boosting algorithm for combining preferences [J].Journal of Machine Learning Research,2003,4:933-969.
[20]BURGES C,SHAKED T,RENSHAW E,et al.Learning to rank using gradient descent[C]∥Proceedings of International Conference on Machine Learning.Bonn:ICML,2005:89-96.
[21]YANG P,LIU Q,METAXAS D N.RankBoost with L1regularization for facial expression recognition and intensity estimation[C]∥Proceedings of IEEE International Conference on Computer Vision.Kyoto:IEEE,2009:1018-1025.
[22]BAI Y,TANG M.Robust visual tracking via weakly supervised ranking SVM [C]∥Proceedings of IEEE Conference on Computer Vision and Pattern Recognition.Providence:IEEE,2012:1854-1861.
[23]GU S,ZHENG Y,TOMASI C.Efficient visual object tracking with online nearest neighbor classifier[C]∥Proceedings of Asian Conference on Computer Vision.Queenstown:ACCV,2010:271-282.
猜你喜欢
名家名作(2021年4期)2021-05-12
哈尔滨轴承(2020年2期)2020-11-06
内蒙古民族大学学报(社会科学版)(2020年2期)2020-11-06
今日中国·法文版(2020年7期)2020-07-04
科普童话·学霸日记(2020年1期)2020-05-08
中国特种设备安全(2019年1期)2019-03-13
小天使·一年级语数英综合(2019年2期)2019-01-10
太空探索(2016年5期)2016-07-12
山东青年(2016年2期)2016-02-28
时代英语·高三(2014年5期)2014-08-26
