
基于深度学习的癫痫脑电通道选择与发作检测
2020-04-09 05:47曹玉珍高晨阳张力新
天津大学学报(自然科学与工程技术版) 2020年4期
曹玉珍,高晨阳,余 辉,张力新,王 江
(1. 天津大学精密仪器与光电子工程学院,天津 300072;2. 天津大学电气自动化与信息工程学院,天津 300072)
癫痫是一种常见的神经系统疾病.在癫痫发作期脑电信号(EEG)会呈现出快速剧烈的变化,与非发作期时有很大的不同[1].因此通过分析 EEG可以实现癫痫发作的检测.然而依靠人力从海量的 EEG记录中识别并分类异常片段是一项耗费大量时间精力的任务[2].因此对癫痫发作自动检测系统的研究有重要意义.
传统癫痫发作检测方法一般利用小波变换、形态学分析等方法提取样本的特征,然后通过随机森林、最邻近算法等方法对样本进行分类[3-4].随着深度学习理论不断完善,卷积神经网络(CNN)在癫痫脑电分类检测中也取得了很好的效果,对于不同数据集平均识别准确率保持在88.0%~99.1%之间[5-6].
研究中使用的多通道EEG数据一般包含了很多冗余信息,这可能会增加算法的复杂度并且会带来模型的过拟合[7].选择合适的通道子集可以对原始复杂数据进行过滤,有助于提升癫痫发作自动检测系统的性能[8].传统的通道选择方法可以分为过滤式方法和封装式方法.过滤式方法使用方差、方差差异、互信息等准则去评估候选的通道子集[8].Arvaneh等[9]基于最大方差准则筛选方差最大的 3个通道作为通道子集的方法取得了和人类神经生理学家选择的通道相近的检测效果.封装式选择方法一般包括特征提取和基于机器学习算法分类这两个过程.决策树算法、遗传算法等常被用于脑机接口应用中的最优通道子集的选择[10-11].以上的通道筛选方法均需要手动提取并选择特征,而且在面对差异巨大的不同个体的EEG信号时,提取的特征也往往不同,在实际应用中需要相当的精力去挑选合适的特征集合.
自编码器是神经网络的一种,对于复杂数据的降维和特征自学习非常有效[12].卷积自编码器(CAE)可以用于癫痫患者 EEG的特征提取,最终平均识别准确率可以达到88.1%[13],相比于传统方法效果提升不显著,且不能充分发挥深度网络的优势.
针对以上方法的不足,本文提出一种把基于CAE和费舍尔准则(FC)的 EEG通道选择方法与基于参数迁移的一维卷积神经网络(1D-CNN)分类器相结合的组合模型以实现癫痫发作通道筛选与检测.
1 基于卷积自编码器和费舍尔准则的 EEG通道筛选
1.1 卷积自编码器
自编码器一般包含输入层、输出层以及隐含层,隐含层的输出是原始数据的特征编码表示.原始数据经过自编码网络输出的编码表示可以被看作特征向量.传统的自编码器在面对类似 EEG这样的复杂高维的非线性数据时,模型性能往往较差,很难从中提取出有效的特征表示[14].在自编码器结构中引入卷积层可以实现对 EEG数据特征的有效提取.CAE模型结构与参数示意如图 1所示,其中 CONV、POOL、FC、DePOOL和 DeCONV分别表示卷积层、池化层、全连接层、逆池化层和逆卷积层,M 表示特征向量维数.
在编码层,单通道输入数据反复经过卷积层、池化层得到一定形状的特征映射,然后经过“压平”操作把多维的特征映射变为一维向量,得到的一维向量经过全连接层后变为长度为 M 的一维特征向量输出.在解码层,特征向量经过全连接层,然后被“拉伸”成为编码层所得特征映射相同大小的多维张量.再经过对应数目的逆池化层与逆卷积层后得到与原始数据相同大小的重构数据.
模型一共由 3对卷积层(逆卷积)、3对池化(逆池化)层和 4个全连接层构成.卷积层和池化层的步长分别设置为 1和 2,其核的大小分别为 5和 2,使用最大池化函数进行下采样.3层卷积操作中卷积核的个数分别为 16、32、64,3层逆卷积操作中卷积核的个数分别为 32、16、1.在卷积过程中对样本边缘进行补零填充,使得经过卷积层的特征映射输出与输入尺寸相同.经过卷积编码原始数据实现了时域上降维和特征域的升维.
1.2 费舍尔准则
FC是一种评价特征相关性的方法,它采用极小化类内方差-极大化类间距离的思想来计算特征与分类任务的相关性,具有快速方便的优点[15-16].每一通道的 EEG数据经过 CAE提取的特征向量可以当作一个特征子集.首先计算不同特征子集与分类任务的相关性iF,然后选择iF较高的前Nch个通道的EEG数据进行后续分类识别任务的模型训练.对于第i个特征子集 fi,它分别属于 K个类,所有样本一共被分成了发作期和非发作期两类信号.定义类间散度矩阵SB和类内散度矩阵SW,SB和SW分别代表不同类特征子集的可区分程度和同类特征子集之间的可区分程度.求出SB和SW的迹(trace),然后计算二者的比值,可以得到特征子集的评价指标.SW、SB和iF的计算公式分别为

式中:Ck为第k类样本的下标集;nk为每一类的样本数;xi为第i个通道的特征子集fi的向量;kμ为第k类样本所有特征子集的平均向量;μ为所有样本所有特征子集的平均向量;trace(⋅)为求矩阵的迹,即矩阵主对角线元素之和[17].

图1 CAE的结构与参数示意Fig.1 Schematic of structure and parameters of CAE
2 基于参数迁移的1D-CNN分类器
迁移学习是一种机器学习技术,旨在从已有机器学习任务中获取通用知识表示,然后将其应用到其他任务之中以优化模型、加速收敛[18-19].其中参数迁移是把部分层网络中节点的权重从一个训练好的网络迁移到一个未经训练的相同结构网络里,而不是从头开始为特定的任务训练一个模型.基于迁移过的模型参数对新模型进行训练与微调,最终得到一个 1DCNN模型进行癫痫发作信号的识别.
研究表明,组合权重的模型有助于加速收敛过程,使得模型获得更好的泛化效果[18].1D-CNN 模型的结构与参数迁移的过程如图2所示.1D-CNN由结构与 CAE相同的 3层卷积层与池化层、2层全连接层和Softmax层组成.使用训练好的CAE的平均权重初始化卷积层和全连接层,然后适当降低学习率进行模型的细化训练.其中分类器使用二值交叉熵作为损失函数进行优化训练.

图2 1D-CNN模型结构以及迁移过程示意Fig. 2 Schematic of 1D-CNN model and parameters transferring
3 实验与结果
3.1 数据来源与预处理
实验使用的EEG数据来源于PhysioNet网站中的CHB-MIT数据库[20].数据库中的数据记录了若干患有癫痫的受试者在撤去抗痫药物后连续几天内监测采集到的头皮 EEG差动信号.其中数据分辨率为16位,采样频率为256Hz,通道数目为23[21].
选取发作持续时间较长的8名患者的EEG数据用于研究,其编号分别为 1、3、5、8、10、11、15、23.依据癫痫发作起止时间标注信息,将患者的 EEG数据以2s的时间长度(样本长度为512点)划分为发作期与非发作期两类样本.分割样本时重叠窗口长度为 1s以实现数据增强.数据标准化处理有助于加快深度学习模型的训练与收敛[2],因此对各 EEG样本进行Z-score标准化处理.
3.2 模型训练与测试
卷积自编码器和分类器均采用反向传播算法训练,使用自适应优化方法Adagrad对损失函数进行优化.在网络最后的全连接层引入随机失活以预防过拟合.在训练过程中全局学习率设置为 0.003~0.008之间的随机数,执行多次训练过程用于测试,以规避训练过程中的随机误差.模型测试主要针对分类器进行测试,通过分类器的性能表现来衡量卷积自编码器所提取特征以及通道选择的优劣.
分类器在每一次全数据集上的迭代优化完成之后,都用测试集的数据进行验证,其中测试集占全数据集的20%.
3.3 结果与评价
模型的训练过程在一台处理器为 Intel Core i7-7700 CPU@3.60GHz,图形处理器为 GeForce GTX 1060,RAM 为 8G 的主机上实现,其中编程环境为Python 3.5,深度学习框架为keras 2.2.2.
以病患 10为例,经过样本分割与预处理,全通道两类样本各10051个.表1为筛选通道数Nch不同时,基于卷积自编码器和费舍尔准则(CAE+FC)、方差和方差差异性筛选的通道编号对比.不同方法筛选出的通道除了顺序有差异之外结果基本一致,说明基于CAE+FC的通道筛选方法具有可行性.

表1 各个方法筛选的通道编号对比Tab.1 Comparison of channel number set filtered by each method
对不同筛选方法都使用相同结构的 1D-CNN分类器进行评估,作为实验组,基于 CAE+FC方法进行参数迁移.图3是基于CAE+FC、方差、方差差异性和随机选择的筛选方法的最终模型预测真阳性率(TPR)、假阳性率(FPR)的比较,以及经过 CAE+FC筛选后的模型与全通道数据的模型 TPR和训练时间的对比,其中筛选的通道数 Nch=5,特征向量维数M=128.

图3 不同模型的性能对比Fig.3 Performance comparison of different models
由图 3(a)可见,组合模型在最后的分类中 TPR和 FPR指标好于基于方差和基于方差差异的筛选方法,远优于随机选择的方法.图3(b)说明与不经筛选的全通道相比,模型的真阳性率更高,且平均训练时长只有前者的22.30%,更具实用性.
图 4为 Nch=5时,不同筛选方法检测模型的训练损失值的下降趋势.基于CAE+FC的组合模型的收敛速度显著快于其他方法,尤其当损失值为1.2时组合模型迭代 12次就可达到其他两种方法迭代约200次时的收敛状况.
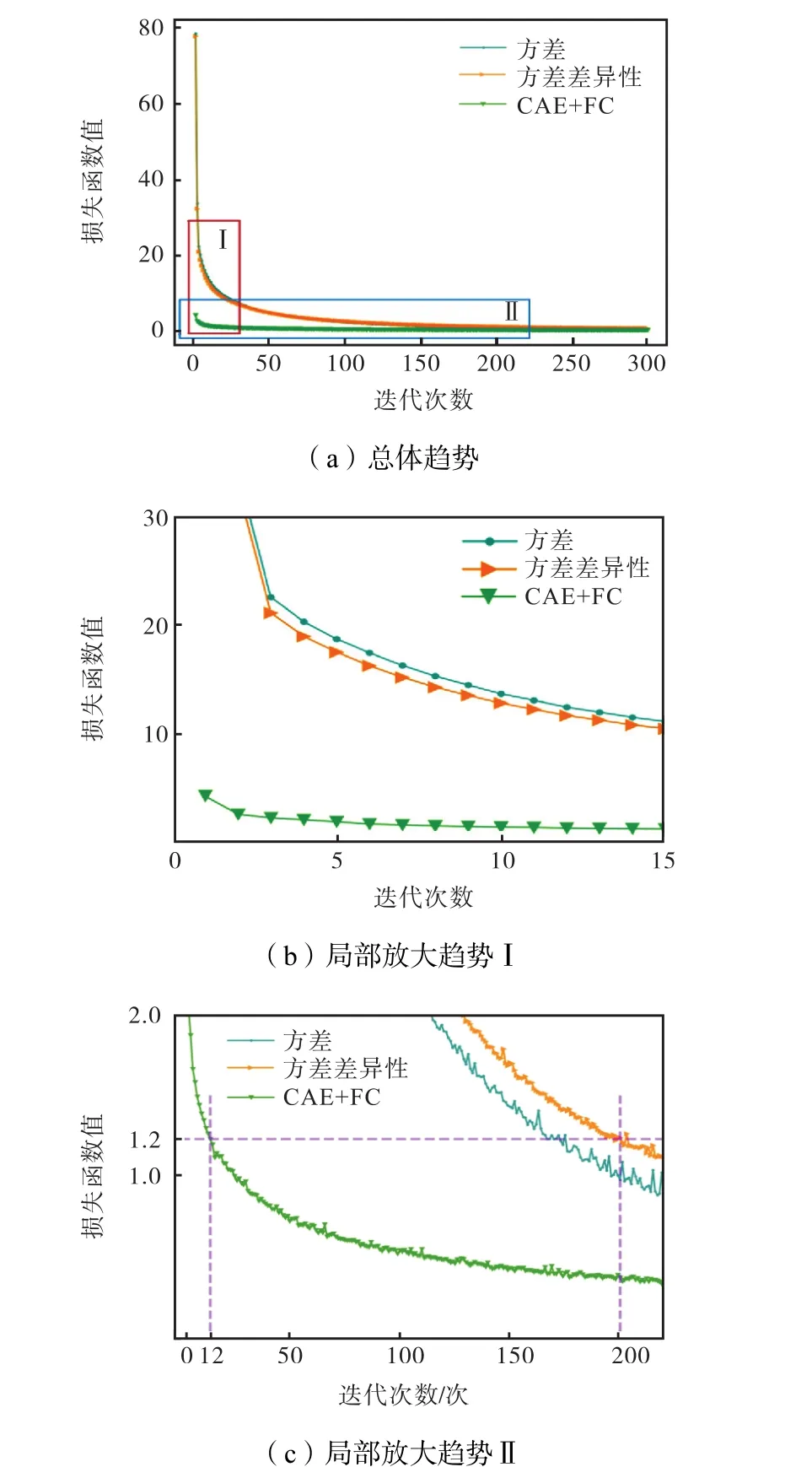
图4 不同筛选方法下检测模型的损失函数下降趋势Fig.4 Declining trend of the loss function value of the detection model under different selection methods
4 讨论与分析
特征向量维数 M和筛选后的通道数 Nch值对组合模型的性能有一定的影响.通过分析组合模型的性能与计算复杂度,探究模型在最优性能时的参数选择情况.
4.1 M值
M值会影响CAE和1D-CNN分类器的结构,进而影响组合模型的效果.选择 M∈{2,4,8,16,32,64,128}时的实验结果进行讨论.
使用神经网络训练过程中无法收敛情况所占比(记为 R)来描述分类器的稳定性.统计不同 M 值下Nch不同时模型的平均准确率、最佳准确率均值、假阳性率均值(记为 FPR均值)和 R值,结果如表 2所示,其中R值的统计基数为621.可以发现随着M变大,准确率指标逐渐提升,FPR指标和 R值逐渐变小,模型稳定性得到提升.当 M=64时,平均准确率均值和最佳准确率均值最大,分别达到了 0.8795和0.9121,同时模型 R 值降为 0.M∈{32,64,128}时模型FPR均值基本都维持在0.1以下,同时R值也更低,组合模型的平均性能都在较高水准.

表2 不同M值时模型的平均性能Tab.2 Average performance of the model at different M values
4.2 Nch值
研究表明,当 Nch在[2,6]区间时,模型拥有较好的性能[9].选择模型准确率最高时筛选通道数目 Nch的取值和准确率排名前 5的模型对应的 Nch取值集合,结果如表 3所示.统计结果基本与已有研究的结论相符.
依据表 3选取相应 Nch值对应的模型绘制经验ROC曲线.比较 ROC曲线,不难发现 M 取32、64、128时,相应地Nch分别等于 2、6、5时,ROC曲线最靠近左上角,ROC曲线下面积(AUC)均为最大.观察图5,M=128时模型的最低TPR水平稍高于其他模型,且M=128,Nch=5时,AUC最大,模型拥有最好的 ROC曲线.使用单次全数据集迭代用时描述模型的计算复杂度,M∈{32,64,128}时模型的单次数据集迭代用时分别为 0.0602s,0.0635s,0.0522s.随着 Nch增加,模型单次数据集迭代用时线性增加.综上,不同 M 值时,最佳 Nch值落在[2,6]区间.当 M=128时模型的稳定性和计算耗时得到平衡,在相同 Nch下模型训练耗时最短,当 Nch=5时模型训练集单次迭代耗时 0.2555s,组合模型对 10号病患癫痫发作检测的准确率、真阳性预测率、假阳性预测率分别为93.49%、94.77%、4.17%.

表3 不同M值时准确率较高的模型对应的NchTab.3 Values of Nch corresponding to the model with higher accuracy when M values are different

图5 M∈{32,64,128}时组合模型在不同 Nch下的经验ROC曲线Fig.5 Empirical ROC curves of the combined model under different Nch for M∈{32,64,128}
4.3 模型评价
经过8名病患脑电数据的验证,本文组合模型对癫痫发作检测的准确率、真阳性预测率、假阳性预测率的平均值分别达到了 92.79%、93.07%和 5.16%;基于方差的筛选方法的检测模型最终 3个指标分别为 89.53%、90.45%、8.69%;基于方差差异性的筛选方法的检测模型最终 3个指标分别为 88.23%、88.97%、9.73%;基于随机筛选的检测模型最终 3个指标分别 65.72%、66.53%、39.85%.基于 CAE+FC的筛选方法优于基于方差和方差差异性的筛选方法,远优于随机筛选,且组合模型的收敛所需的迭代次数平均仅为其他模型(基于方差和方差差异性的筛选方法对应的检测模型)的1/10.
5 结 语
本文提出了一种基于深度学习方法的癫痫脑电通道选择与发作检测组合模型.首先通过卷积自编码器对脑电信号进行特征提取;然后依据费舍尔准则进行通道选择;最后用经过参数迁移的一维卷积神经网络实现癫痫发作检测.该组合模型在进行脑电通道筛选时不需要手动提取、选择特征,提升了通道选择与发作检测的效果并且大大降低了模型训练成本.此外当病患的 EEG数据库得到更新时,可以用新加入的数据对现有模型进行增量学习,微调更新参数以实现更准确的判断.该方法的研究思路亦可推广用于阿尔兹海默症等其他脑部疾病个性化检测模型的建立.
猜你喜欢
电子产品世界(2022年4期)2022-04-21
中学生数理化(高中版.高一使用)(2021年9期)2021-12-02
安庆师范大学学报(自然科学版)(2021年1期)2021-11-28
中学生数理化(高中版.高考数学)(2021年3期)2021-06-09
计算机系统应用(2021年2期)2021-02-23
南京大学学报(数学半年刊)(2020年1期)2020-03-19
计算机应用与软件(2020年1期)2020-01-14
计算机测量与控制(2019年4期)2019-05-08
初中生世界·九年级(2017年10期)2017-11-08
中学生数理化·八年级数学人教版(2016年5期)2016-08-23
