
基于大数据深度神经网络与Agent的大规模任务处理方法
2021-01-06 19:41黄婕
计算技术与自动化 2021年4期
黄婕


摘 要:因大规模任务处理模型在处理实际任务请求通常是基于历史数据的,若总依据经验和以往知识判断,会出现许多无法识别并处理的任务,以及出现模型过拟合等问题。提出了一种基于深度神经网络的计算模型进行大规模任务部署,并引用Agent强化学习效用进行评价,实现最佳虚拟网络映射方案。实验结果表明,这种BDTard方法法能满足大规模任务请求,稳定系统长期收益,保障了大数据环境下大规模任务处理的高效执行。
关键词:深度神经网络;强化学习;虚拟网络映射
中图分类号:TP319 文献标识码:A
Abstract:Since the large-scale task processing model is usually based on historical data in the processing of actual task requests, if the model is always judged based on experience and previous knowledge, there will be many tasks that cannot be recognized and processed, as well as problems such as model overfitting. A computing model based on deep neural network is proposed for large-scale task deployment, and the Agent reinforcement learning utility is evaluated to realize the optimal virtual network mapping scheme. The experimental results show that the BDTard method can meet the requirements of large-scale task, stabilize the long-term benefits of the system, and ensure the efficient execution of large-scale task processing in the big data environment.
Key words:deep neural network; reinforcement learning agent; virtual network mapping
大數据环境下的大规模任务处理是时下数据分析热门问题之一[1],而依靠历史数据进行任务识别的方法,在进行分析、处理的大规模任务部署时,会引起负载不均衡、造成资源浪费等问题。为了改进负载不均衡、资源浪费的问题,将大规模任务部署到各节点高效执行,且有一定的性能收益。且利用大数据环境下深度神经网络[2]与Agent[3]结合,能使得在大规模任务在识别、技术及处理过程中有明显改观,效率提升明显。
但由于数据的训练模型是基于历史数据的,依据经验对处理任务识别,容易出现过拟合现象,计算模型出现偏差。为了提高效率,探索最优解,利用大数据环境下的深度神经网络与Agent结合的方式,实现虚拟节点的最优映射方案,这种改进的大规模任务处理方法能有效防止模型过拟合[4],提高效率。
1 问题的提出
针对系统的长期收益,利用传统方法结合最新的人工智能方案[5],而一种基于Dropout自适应的深度学习和强化学习相结合的方法有较好的效果。可实际这种方法容易增加用户行为多样性的学习难度,使得学习模型复杂化,导致网络模型过拟合[6]。因深度模型中存储的是部分标签数据,当用户有虚拟请求时,利用经验知识难以识别、处理,使得大数据的海量任务请求无法有效识别、及时处理。因此,提出一种有效且合理的大数据环境下部署任务的方法[7]迫在眉睫,此方法主要能最小化计算模型的过拟合,优化泛化能力 [8]。
2 利用Dropout神经网络建模Agent强化学习的BDTard方法
2.1 系统架构设计
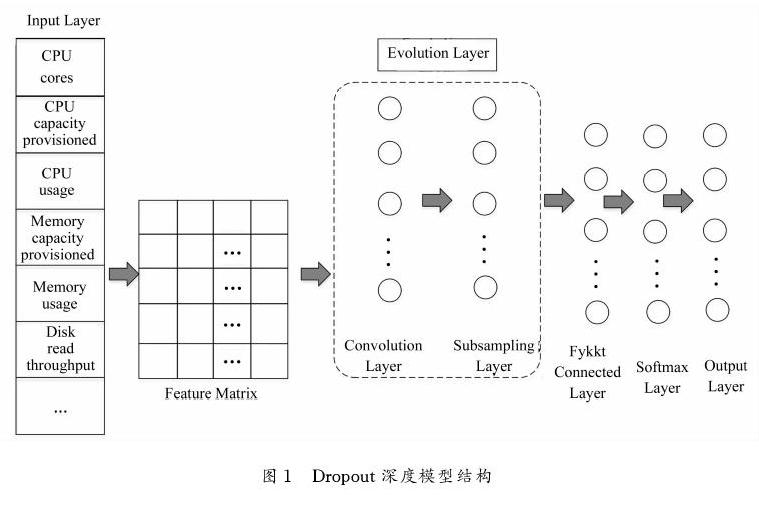
在大规模任务处理方法BDTard中,在大数据技术的支撑下,利用深度神经网络建模来均衡节点的映射。如图1所示,该计算模型共有五层,包括Input Layer输入层、Evolution Layer进化层(包含Convolutional Layer卷积层和Subsampling Layer池化层)、Fully Connected Layer全连接层、Softmax Layout函数层、Output Layer输出层。
如1图中,输入层Input Layer用于将Feature Matrix特征矩阵输入到深度计算模型中。再将特征矩阵输送到卷积层中计算,生成具有抽象特征的特征图。在Subsampling Layer池化层中建模,目的是减少全连接层Fully Connected Layer中的节点个数。通过函数层而输出最终结果。而为了提升计算模型的泛化能力,减少过拟合现象,将引入深度计算模型的进化层结构,把固有模型平均分成子模型,这种较小数据集的“新”模型实现了模型与自我进化相结合,目的是探索最优网络映射策略。
然后在全连接层输出的结果传输到函数层,用来求出每个物理节点的分布概率,最后云计算数据中心将接收虚拟节点映射策略,将虚拟数据请求分配到底层物理节点,以实现基于大数据的大规模任务处理。
2.2 方法主要思想
基于大数据的深度神经网络与Agent的大规模任务处理方法,是把大规模的任务部署利用计算模型的虚拟网络进行映射。该方法把训练和应用中的历史请求数据分开,叫做训练集和测试集。再依据之前工作求出底层网路物理节点的状态、特征和模型的输入,使得数据集的维度降低。而自适应Dropout深度计算模型主要目的是寻求合理的虚拟节点映射策略,当训练样本较少时,Dropout对大规模网络模型策略非常有效。当网络结构改变,依据深度模型去建模,再利用类似隐藏去噪法将数据的神经元的权重归零。网络层的参数概率变化,网络模型中神经元丢弃,需要从物理节点、任务请求数据中的特征作为模型输入,将映射概率设为输出(虚拟节点到物理节点的映射),再利用Agent强化学习来实现虚拟链路映射。若训练集中数据不具备对应标签,则利用反向传播和策略梯度,并结合历史数据请求进行深度计算模型训练,利用一种贪婪策略评估Agent强化学习的有效性,将大量的任务请求在进行大数据分析处理中分配到有效的物理节点,实现了能并行处理的最优虚拟网络映射方案。
2.3 BDTard方法设计
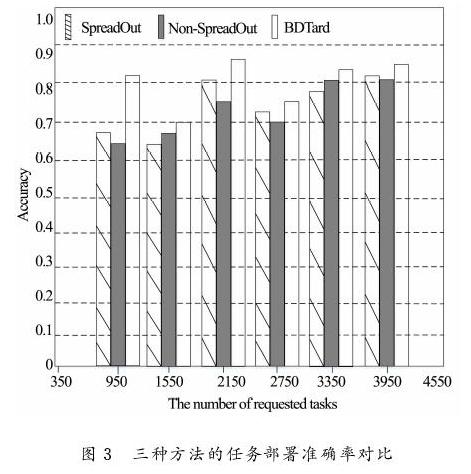
如上图3所示,任务量从950到3950中,BDTard方法在950、2150、3350和3950的准确率都达到了80%。而SpreadOut和Non-SpreadOut只在少部分达到80%。可见BDTard方法能更加准确地在目标节点部署任务,是一种实现系统利益最大化的最优任务部署方案。
3.3 系统收益对比
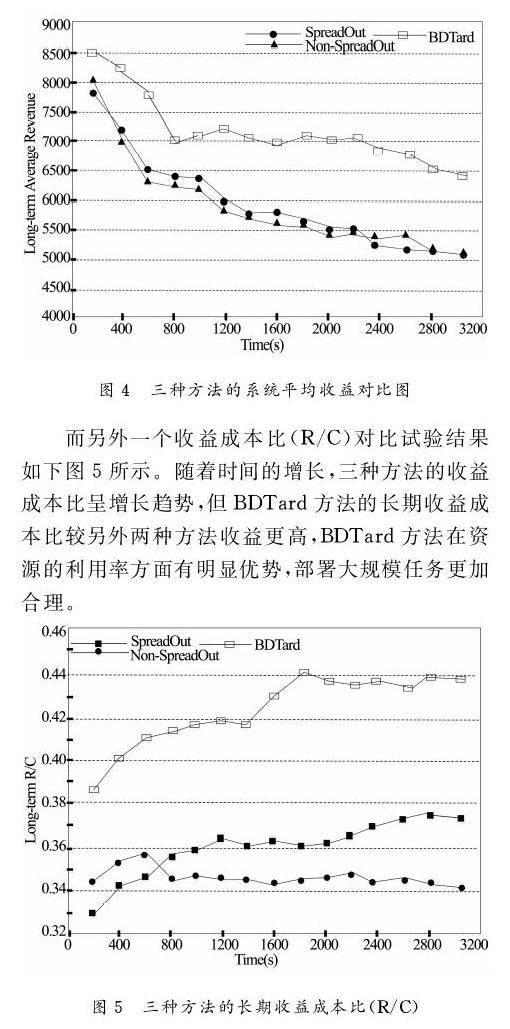
此实验通过在BDTard、SpreadOut和Non-SpreadOut三种方法上进行系统平均收益和收益成本比(R/C)的对比试验。如下图4所示,三种方法的长期平均收益值初期是快速下降的,中后期相对平稳。整个过程中BDTard方法的收益都是高于SpreadOut和Non-SpreadOut方法的,且另外两个方法的收益值相差无几。因此,相对系统长期平均收益BDTard方法具有明显优势。
而另外一个收益成本比(R/C)对比试验结果如下图5所示。随着时间的增长,三种方法的收益成本比呈增长趋势,但BDTard方法的长期收益成本比较另外两种方法收益更高,BDTard方法在资源的利用率方面有明显优势,部署大规模任务更加合理。
从以上两个对比实验看出,BDTard方法从系统长远利益考虑,分析任务请求的需求,利用Dropout自适应深度计算模型和Agent强化学习对底层物理节点合理分配资源,最大限度降低了资源消耗成本,使得任务部署方案在长期获得更高收益,提高了资源利用率,实现了高效分析、处理大数据。
3.4 部署失败数据对比
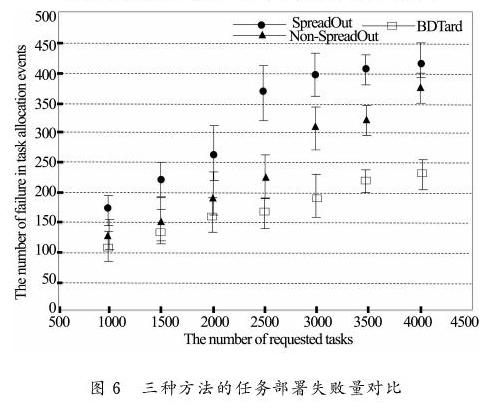
在实际处理大规模任务部署工作中,因某些网络故障等原因,有可能导致任务部署不成功。这组实验通过对比BDTard、SpreadOut和Non-SpreadOut方法在任务部署的失败数据量,进行多组实验,借助误差条显示结果分布。
如下图6所示,随着任务数量的增加,三种方法任务部署失败量也逐渐增加。但是BDTard方法的失败数据都少于另外两种方法,且任务数据的增加导致失败部署的数据增长在速度上也慢于其他两种方法。整个实验过程中,当部署任务较小时,三中方法差距不大,但任务数据达到3000以上时,差距就拉大了。当达到4000任务量时,BDTard方法的失败率就远小于其他两种方法了。
从上图6中还发现,相对于SpreadOut和Non-SpreadOut方法,BDTard方法随着时间、任务量的增加,任务部署的成功率呈相对稳定的趋势。BDTard方法保障了大规模任务部署的可靠性、稳定性,也是从系统利益考虑,利用Dropout深度模型和Agent方法来完成任务部署,有效地提高了部署的成功率和大规模任务处理能力。
4 结 论
提出的BDTard方法是一种针对大数据环境下的任务处理方法。主要利用Dropout深度计算模型虚拟映射部署任务,从系统长远利益出发,利用Agent强化学习对底层物理节点合理分配资源,避免了计算模型过拟合产生。通过对比任务部署的有效性、系統收益和任务部署失败数据,进行实验比对分析,结果表明BDTard方法能满足大规模任务请求,稳定系统长期收益,有效地提高了部署的成功率和大规模任务识别、计算及处理能力。
参考文献
[1]MAKKIE M, LI X, QUINN S, et al. A distributed computing platform for fMRI big data analytics[J]. IEEE Transactions on Big Data,2018, 1-1.
[2]邹锋.基于深度神经网络和改进相似性度量的推算方法[J]. 计算机应用与软件,2019 (11):286-293,300.
[3]王欣,王芳. 基于强化学习的动态定价策略研究综述[J]. 计算机应用与软件,2019 (12):1-6.
[4]SUN C, MA M, ZHAO Z, et al. Sparse deep stacking network for fault diagnosis of motor[J]. IEEE Transactions on Industrial Informatics, 2018, 14(7): 3261-3270.
[5]ZENG G, LIU W. An iso-time scaling method for big data tasks executing on parallel computing systems[J]. The Journal of Supercomputing, 2017, 73(3):4493-4516.
[6]QIU X, LUO L, DAI Y. Reliability-performance-energy joint modeling and optimization for a big data task[C]. Proceedings of IEEE International Conference on Software Quality, Reliability and Security Companion (QRS-C). Vienna, Austria: August 1-3, 2016.
[7]SUN Y, YEN G G, YI Z. Evolving unsupervised deep neural networks for learning meaningful representations[J]. IEEE Transactions on Evolutionary Computation, 2018, 23(1): 89-103.
[8]ZHANG Q, YANG L T, CHEN Z. Deep computation model for unsupervised feature learning on big data[J]. IEEE Transactions on Services Computing, 2015, 9(1): 161-171.
[9]KIM J, BUKHARI W, LEE M. Feature analysis of unsupervised learning for multi-task classification using convolutional neural network[J].Neural Processing Letters, 2017, 47(3): 783-797.
[10]CHENG D, ZHOU X, LAMA P, et al. Cross-platform resource scheduling for spark and mapReduce on YARN[J]. IEEE Transactions on Computers, 2017, 66(8): 1341-1353.
[11]NOU R, MIRANDA A, SIQUIR M, et al. Improving openstack swift interaction with the I/O stack to enable software defined storage[C]. Proceedings ;of IEEE International Symposium on Cloud & Service Computing. Kanazawa, Japan: November 22-25, 2018.
[12]SOPAOGLU U, Abul O. A top-down k-anonymization implementation for apache spark[C]. Proceedings of IEEE International Conference on Big Data. Boston, MA, USA: December 11-14, 2017.
[13]TAQI A M, AWAD A, ALAZZO F, et al. The impact of multi-optimizers and data augmentation on tensorflow convolutional neural network performance[C]. Proceedings of IEEE Conference on Multimedia Information Processing & Retrieval. IEEE. Miami, FL, USA: April 10-12, 2018.
[14]WILSON C, VEERAVALLI V V, NEDICH A. Adaptive sequential stochastic optimization[J]. IEEE Transactions on Automatic Control, 2018, 64(2): 496-509.
